







2014年ILSVRC竞赛的第二名为VGG Net,该网络结构继承了LeNet和AlexNet的框架,采用了19层的深度网络。VGGNet在分类成功率上要稍逊于GoogleNet,在多个迁移学习任务中的表现要优于GoogleNet。从图像中提取CNN特征,VGGNet是首选算法。VGGNet的缺点是存储空间太大,参数太多,参数量达到140M。总体来说,VGGNet没有过多创新,主要在以下方面进行改进:
(1)卷积层使用更小的filter尺寸和间隔。因为层叠很多小的滤波器的感受野和一个大的滤波器的感受野是相同的,还能减少参数。
(2)采用更深的网络进行堆叠,更深的模型的确可以提升效果。
VGGNet几种不同的配置(按列对应):
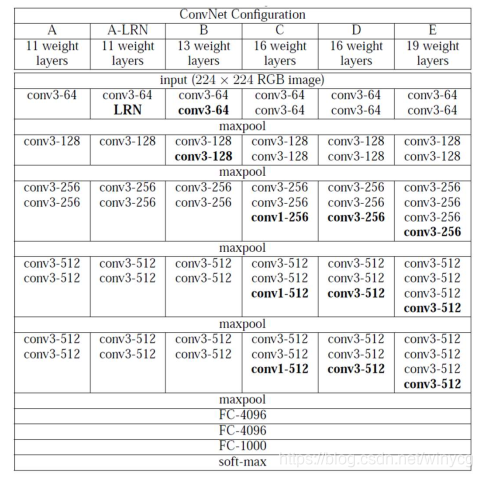
搭建全连接层之前卷积层和池化层:
import torch.nn as nn
cfg = {
'A': [64, 'M', 128, 'M', 256, 256, 'M',
512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M',
512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M',
512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256,
'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
class VGG(nn.Module):
def __init__(self, features, num_classes=1000,
init_weights=True):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_\
(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
生成VGG Net对象:
def vgg11(pretrained=False, **kwargs):
"""VGG 11-layer model (configuration "A")
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfg['A']), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg11']))
return model
附录:
*list:可以将列表拆分为多个元素
**dict:可以将字典分解为独立的元素。此时键值为变量名,对应的值就是变量的值。
def add(a, b):
return a - b
data = [4, 3]
print(add(*data)) # 1, 等价于add(4,3)
print(*data) # 4 3
data = {'a': 4, 'b': 3}
print(add(**data)) # 1,等价于add(a=4, b=3)
data = {'a': 3, 'b': 4}
print(add(**data)) # -1,等价于add(a=3,b=4)
print(**data) # 无法直接输出














 1391
1391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









