







一. 环境介绍
三台主机,主机名和ip分别为:
ubuntu1 10.3.19.171
ubuntu2 10.3.19.172
ubuntu3 10.3.19.173
三台主机的登录用户名是bigdata,home目录是/home/bigdata
现在三台主机上部署hadoop集群, ubuntu1作为namenode, ubuntu1 ubuntu2 ubuntu3作为datanode。
二. 安装部署
1. 配置各主机名和hosts, 安装JAVA
修改各主机名的配置, 例如ubuntu1的主机名配置为:
bigdata@ubuntu1:~$ cat /etc/hostname
ubuntu1
ubuntu2 和 ubuntu3分别配置为ubuntu2 和 ubuntu3
bigdata@ubuntu1:~$ cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 ubuntu
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
10.3.19.171 ubuntu1
10.3.19.172 ubuntu2
10.3.19.173 ubuntu3
安装配置java. 三台主机都需要安装java, ubuntu1下java安装路径如下, 其它两台主机,也是安装到~/usr/jdk1.8.0_25目录下
bigdata@ubuntu1:~/usr/jdk1.8.0_25$ pwd
/home/bigdata/usr/jdk1.8.0_25export JAVA_HOME=/home/bigdata/usr/jdk1.8.0_25
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/jt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH 2. 配置三台主机ssh免密码登录
step1: 分别在ubuntu1 ubuntu2 ubuntu3三台主机上,执行如下命令生成公钥/私钥对
bigdata@ubuntu1:~$ ssh-keygen -t rsa -P ''
step2: 拷贝公钥到各主机,使得各主机可以ssh免密码登录
查看.ssh/authorized_keys文件是否存在,如果不存在则创建
bigdata@ubuntu1:~$ ls .ssh/authorized_keys
.ssh/authorized_keysbigdata@ubuntu1:~$ chmod 600 .ssh/authorized_keysbigdata@ubuntu1:~$ cat .ssh/authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCrI0nqIW4P7mPbKytk/wo0d1utVQCIgDGQjUZDgVv1Ll9y6PoRtffTqDQ5cHLHnqapsdO/RAfDFUBPaDAHHwZeQ/sKP/c9GWbr9PxjH2dzzVcB6VOll3T0vTLAxMsIevtBj/fN5HRdZTasQeLtibY5CQvGF+owWCWtWp7cEdewL2fgPCFIVijFLqGLtAvLJrpcbnwoY0WgIivviK9QD2Ymm/kC5pAK/5/QljYldyOEiPbTeRLE94b4G7XWPDhIv/1SKLvnwQoy/Zs0HokG/jzW3VXSLJ9aecg8JfTp3q2Ngcm3hm/chfWvxfCRC5DnmTzlKg+HxsWp7M3ku3saR2Kv bigdata@ubuntu1
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC7E/gMzpHo4YXEmIBMau+H1Jw01UVEvUSWWy1zz6v0xXQbSQt2fKm1Iwm9XoijLWrv0PWZp44XdPNAP0o+2pK2y8G3t7qMMbAIu9LSe7No51Npz450HMbKlXtZ2ED3Zd/09SP+ekpd4z8IiMeZGUQNCsdRe0jgIbP8QtEkg7MO7WrI9d54dBMzjWPqrxYcSfP3yf65WXGwTcxbmbaFpuFSMvx2c+OsA1u1wemNk0r1/f1Q5Qu4GavOX0ZQojUjz1z2CJe9Hm+hNtpgrIrmnzPk3+4qw/8udUkDGYuZD0G9J2xPmD1qwu5oz29a9b/2eMqStQu7NWoDfCCpoa6ZrHuv bigdata@ubuntu2
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDMRgOi/sWQHXRgL24VqDgEncOxmoV9IlmjVhC9Mhbx1vpRWfLakGzxQdmyN6X7xJxZjc3O6CcJbVSZTBnAd45PpX5EhQ/QBa+ycz9Cfl44bVyEaeb2mAtcTbILlepNgvdT+MgVxDkkL+7bL9XMwkxptmQozTY7RTRd3MHiXOk+AoDMt9iJrpGyhjSpR5WEL7jG9TAakOlnBSyTPPnjPV+SerN3DEG/KSg3vAED9Pimzka7MM6syjMVypVt5AZhDmc5bTXPwq6+WTupspI6MdXkeKn6tTCZGhE1Qwvf8nP0Thope6fvrbVWTTOf4RGW8/f9zXyWy2PC9Pp2h5AIihZf bigdata@ubuntu3尝试在ubuntu1上无密码登录ubuntu2, 第一次可能需要输入密码,后续登录不需要。
bigdata@ubuntu1:~$ ssh ubuntu2
Welcome to Ubuntu 16.04 LTS (GNU/Linux 4.4.0-21-generic x86_64)
* Documentation: https://help.ubuntu.com/
Last login: Tue May 2 19:56:34 2017 from 10.3.19.171
bigdata@ubuntu2:~$ 3. 安装hadoop到一台主机ubuntu1上
我的hadoop部署在目录/home/bigdata/run目录下,在ubuntu1上部署hadoop先。操作部署如下:
step1. 解压hadoop-2.7.3.tar.gz,并将其拷贝到run目录下
bigdata@ubuntu1:~$ tar -zxvf hadoop-2.7.3.tar.gzbigdata@ubuntu1:~$ mv hadoop-2.7.3 /home/bigdata/run/step2: 配置core-site.xmlbigdata@ubuntu1:~$ ln -s /home/bigdata/run/hadoop-2.7.3 /home/bigdata/run/hadoop
bigdata@ubuntu1:~$ cd /home/bigdata/run/hadoop/etc/hadoop
bigdata@ubuntu1:~/run/hadoop/etc/hadoop$ bigdata@ubuntu1:~/run/hadoop/etc/hadoop$ cat core-site.xml
......
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ubuntu1:9000</value>
</property>
</configuration>step3: 配置hdfs-site.xml
bigdata@ubuntu1:~/run/hadoop/etc/hadoop$ cat hdfs-site.xml
.......
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/bigdata/run/hadoop/tmp/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/bigdata/run/hadoop/tmp/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>ubuntu1:50070</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>ubuntu1:50075</value>
</property>
</configuration>step4: 配置mapred-site.xml
bigdata@ubuntu1:~/run/hadoop/etc/hadoop$ cat mapred-site.xml
......
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>step5:配置yarn-site.xml
bigdata@ubuntu1:~/run/hadoop/etc/hadoop$ cat yarn-site.xml
......
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ubuntu1</value>
</property>
<property>
<name>yarn.nodemanager.hostname</name>
<value>ubuntu1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>step6: 配置hadoop-env.sh,红色部署,配置JAVA_HOME,即jdk的安装路径
bigdata@ubuntu1:~/run/hadoop/etc/hadoop$ cat hadoop-env.sh
......
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/home/bigdata/usr/jdk1.8.0_25
......
step7: 创建namenode和datanode数据所在目录
mkdir /home/bigdata/run/hadoop/tmp/name
mkdir /home/bigdata/run/hadoop/tmp/data这样在ubuntu1上部署hadoop已经完成了。接下来,将hadoop部署到ubuntu2和ubuntu3两台主机上。
4. 安装hadoop到ubuntu2和ubuntu3主机上
为了方便, 我们直接将ubuntu1上的/home/bigdata/run/hadoop-2.7.3目录打包,拷贝到ubuntu1和ubuntu2主机上。注意, ubuntu2和ubuntu3主机的目录结构,要同ubuntu1主机一样。我们同样将hadoop部署到/home/bigdata/run目录下
bigdata@ubuntu1:~/run$ tar -zcvf hadoop-2.7.3.tar.gz hadoop-2.7.3/scp hadoop-2.7.3.tar.gz ubuntu2:/run/
scp hadoop-2.7.3.tar.gz ubuntu3:/run/
在ubuntu2 ubuntu3主机上解压,并创建软链接,发下是ubuntu2上的操作,ubuntu3类似。
bigdata@ubuntu2:~/run$ tar -zxvf hadoop-2.7.3.tar.gzbigdata@ubuntu2:~$ ln -s /home/bigdata/run/hadoop-2.7.3 /home/bigdata/run/hadoop
step1. 修改hdfs-site.xml, 注释掉红色部署。
bigdata@ubuntu2:~/run/hadoop/etc/hadoop$ cat hdfs-site.xml
......
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/bigdata/run/hadoop/tmp/name</value>
</property>
-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/bigdata/run/hadoop/tmp/data</value>
</property>
<!--
<property>
<name>dfs.http.address</name>
<value>ubuntu1:50070</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>ubuntu1:50075</value>
</property>
-->
</configuration>step2: 修改mapred-site.xml, 注释掉红色部分
bigdata@ubuntu2:~/run/hadoop/etc/hadoop$ cat mapred-site.xml
......
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5. 启动hadoop集群
step0: 格式化namenode
bigdata@ubuntu1:~/run/hadoop/bin$ cd /home/bigdata/run/hadoop/bin
bigdata@ubuntu1:~/run/hadoop/bin$ ./hadoop namenode -formatbigdata@ubuntu1:~$ cd /home/bigdata/run/hadoop/sbin
bigdata@ubuntu1:~/run/hadoop/sbin$ ./start-all.shbigdata@ubuntu1:~/run/hadoop/sbin$ jps -l
1827 org.apache.hadoop.yarn.server.nodemanager.NodeManager
1494 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
1225 org.apache.hadoop.hdfs.server.namenode.NameNode
1707 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
2110 sun.tools.jps.Jps
1343 org.apache.hadoop.hdfs.server.datanode.DataNodebigdata@ubuntu2:~/run/hadoop/etc/hadoop$ jps -l
983 org.apache.hadoop.hdfs.server.datanode.DataNode
1166 sun.tools.jps.Jps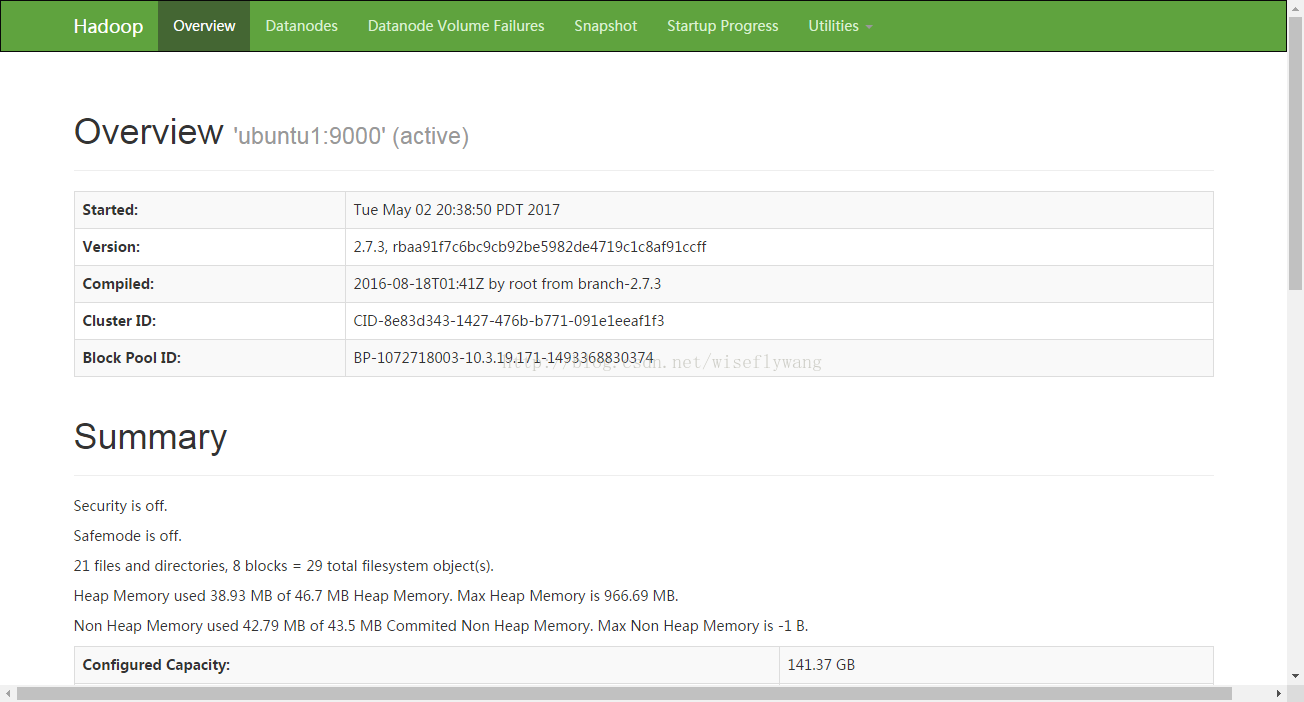
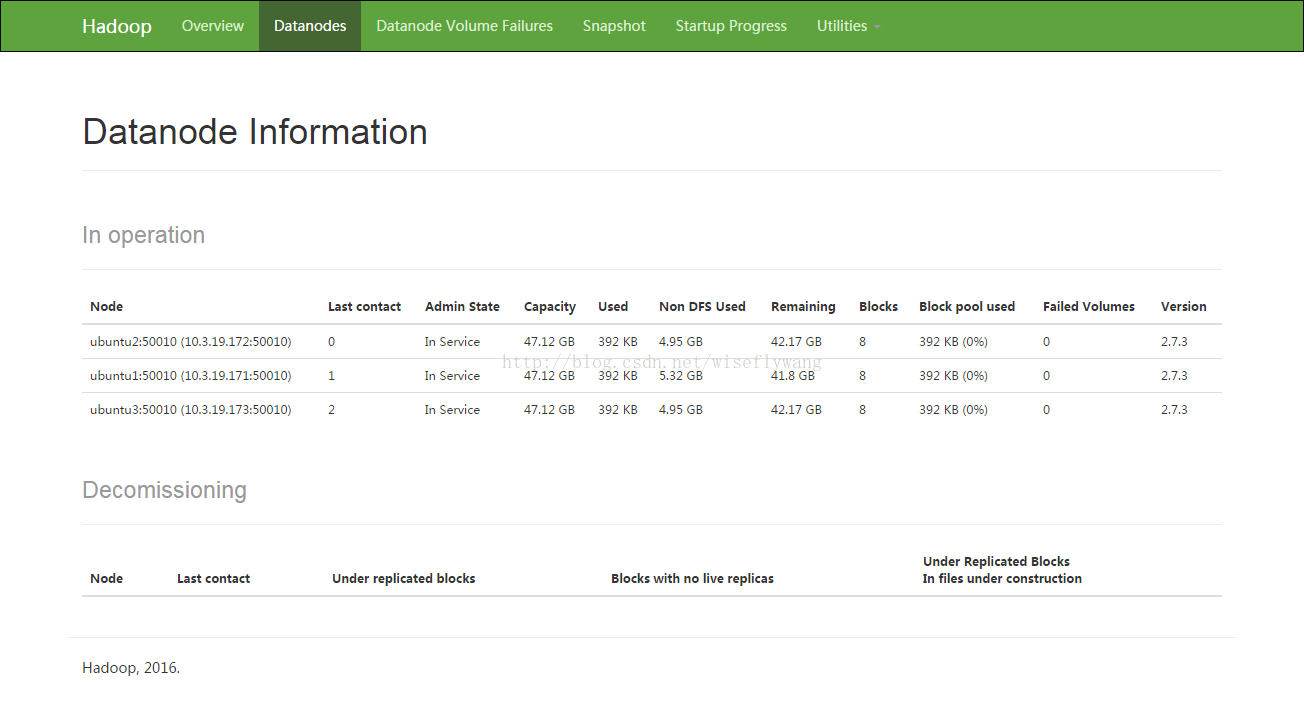
6. 测试hadoop
为了测试方便,设置环境变量如下:
export JAVA_HOME=/home/bigdata/usr/jdk1.8.0_25
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/jt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_PREFIX=/home/bigdata/run/hadoop
export HADOOP_HOME=$HADOOP_PREFIX
export HADOOP_COMMON_HOME=$HADOOP_PREFIX
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HADOOP_HDFS_HOME=$HADOOP_PREFIX
export HADOOP_MAPRED_HOME=$HADOOP_PREFIX
export HADOOP_YARN_HOME=$HADOOP_PREFIX
export PATH=$PATH:$HADOOP_PREFIX/sbin:$HADOOP_PREFIX/bin测试步骤如下:
a. 本地文件夹/home/bigdata/下创建文件test.txt
$ cat test.txt
hello world
b. hdfs上创建文件夹test:hdfs dfs -mkdir /test
c. 拷贝test.txt到test文件夹下:hdfs dfs -copyFromLocal /home/bigdata/test.txt /test/test.txt
d. 查看hdfs上的test.txt:hdfs dfs -cat /test/test.txt
e. 执行工具类wordcount,将结果输出到output:
hadoop jar /home/bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /test/test.txt /output
f. 在output下查看输出结果文件:hdfs dfs -ls /output
g. 查看统计结果 hdfs dfs -cat /output/part-r-00000















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









