







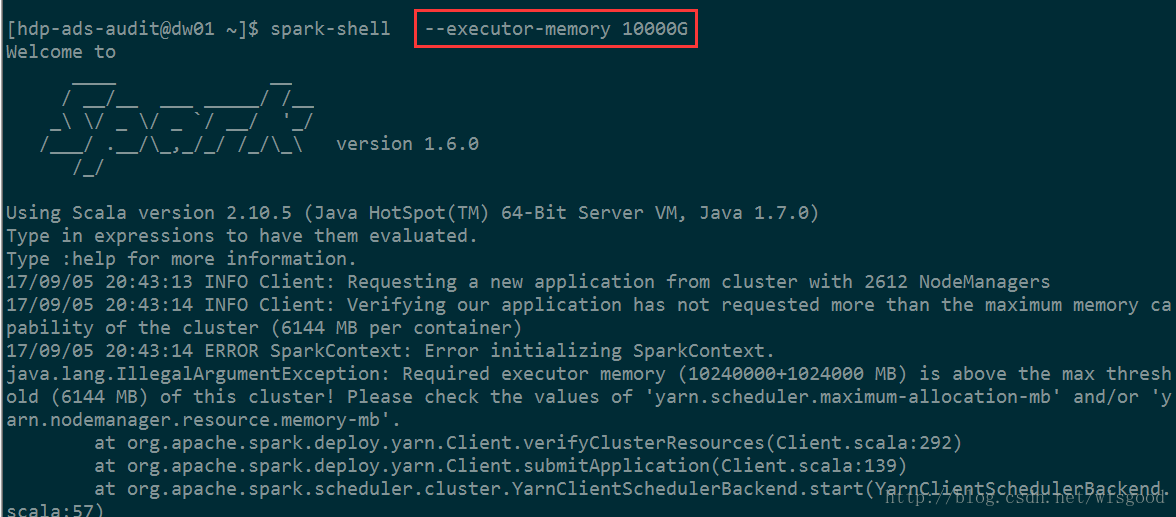
我们知道,spark执行的时候,可以通过 --executor-memory 来设置executor执行时所需的memory。但如果设置的过大,程序是会报错的,如下
那么这个值最大能设置多少呢?本文来分析一下。
文中安装的是Spark1.6.1,安装在hadoop2.7上。
1、相关的2个参数
1.1 yarn.scheduler.maximum-allocation-mb
这个参数表示每个container能够申请到的最大内存,一般是集群统一配置。Spark中的executor进程是跑在container中,所以container的最大内存会直接影响到executor的最大可用内存。当你设置一个比较大的内存时,日志中会报错,同时会打印这个参数的值。如下图 ,6144MB,即6G。

1.2 spark.yarn.executor.memoryOverhead
executor执行的时候,用的内存可能会超过executor-memoy,所以会为executor额外预留一部分内存。spark.yarn.executor.memoryOverhead代表了这部分内存。这个参数如果没有设置,会有一个自动计算公式(位于ClientArguments.scala中),代码如下:

其中,MEMORY_OVERHEAD_FACTOR默认为0.1,executorMemory为设置的executor-memory, MEMORY_OVERHEAD_MIN默认为384m。参数MEMORY_OVERHEAD_FACTOR和MEMORY_OVERHEAD_MIN一般不能直接修改,是Spark代码中直接写死的。
2、executor-memory计算
计算公式:
val executorMem = args.executorMemory + executorMemoryOverhead假设executor-为X(整数,单位为M),即
1) 如果没有设置spark.yarn.executor.memoryOverhead,
executorMem= X+max(X*0.1,384)2)如果设置了spark.yarn.executor.memoryOverhead(整数,单位是M)
executorMem=X +spark.yarn.executor.memoryOverhead 需要满足的条件:
executorMem< yarn.scheduler.maximum-allocation-mb 注意:以上代码位于Client.scala中。
本例中 :
6144=X+max(X*0.1,384)
X=5585.45 向上取整为5586M,即最大能设置5586M内存。

















 2622
2622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









