







本文整理自JerryLead的博文“《K-means聚类算法》 ”,“《(EM算法)The EM Algorithm 》”,“《混合高斯模型(Mixtures of Gaussians)和EM算法 》”,以及自己编写的关于GMM的Matlab实现。
好的博文还有:
pluskid的《漫谈 Clustering (3): Gaussian Mixture Model》和《漫谈 Clustering (番外篇): Expectation Maximization》。
K-means和EM
K-means是聚类算法中最简单的一种,但是里面包含的思想却是不一般。聚类属于无监督学习,朴素贝叶斯、SVM等都是有类别标签
y
的,即已经给出了样本的分类。而聚类的样本中却没有给定
在聚类问题中,给定训练样本
K-means算法是将样本聚类成
1、随机选取 K 个聚类质心点为
{μk}Kk=1,μk∈Rn 。
2、重复下面过程直到收敛{
对于每一个样例 i ,计算其应该属于的类
zi=argminj||xi−μj||2
对于每一个类 j ,重新计算该类的质心
μj=∑Ni=11{zi=j}xi∑Ni=11{zi=j}
}
其中,
K
是事先给定的聚类数,
K-means如何保证收敛?
K-means算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面定性的描述一下收敛性,定义畸变函数:
函数 J 表示每个样本点到其质心的距离平方和。K-means就是要将
K-means与EM的关系
K-means算法目的是将样本分成 K 个类,即求每个样例
这个过程有几个难点:第一,怎么假定
这可以采用EM的思想解决,E步就是估计隐含类别 y 的期望值,M步调整其他参数使得在给定类别
对应于K-means,最开始对于每个样例
EM算法
下面介绍EM的整个推导过程:
Jensen不等式
设
f
是定义域为实数的函数,如果对于所有的实数
Jensen不等式表述如下:如果
特别地,如果 f 是严格凸函数,那么
如果用图表示会很清晰:

图中实线
当 f 是(严格)凹函数当且仅当
Jensen不等式应用于凹函数时,不等号方向反向,即 E[f(x)]≤f(E[X]) 。
EM算法
给定独立同分布训练样本
{xi}Ni=1
,寻找到每个样例隐含的类别
z
,能使得
该式直接求 θ 一般比较困难,因为有隐藏变量 z 存在,但是一般确定了
EM是一种解决存在隐含变量优化问题的有效方法。既然不能直接最大化 L(θ) ,那么就不断地建立 L(θ) 的下界(E步),然后优化下界(M步)。即对于每一个样例 i ,让
其中, log(x) 是凹函数且 ∑ziQ(zi)p(xi,zi;θ)Q(zi)
是 [p(xi,zi;θ)/Q(zi)] 的期望。
这个过程可以看作是对 L(θ) 求了下界。对于 Q 的选择,有多种可能,那种更好的?假设
其中, c 为常数,不依赖于
至此,导出了在固定其他参数 θ 后, Q(zi) 就是后验概率,解决了 Q(zi) 如何选择的问题。这一步就是E步,建立 L(θ) 的下界。
接下来的M步,就是在给定 Q(zi) 后,调整 θ ,去极大化 L(θ) 的下界。那么一般的EM算法的步骤如下:
循环重复直到收敛 {
(E步)对于每一个 i ,计算
Q(zi)=p(zi|xi;θ)
(M步)计算
θ=argmaxθ∑i=1N∑ziQ(zi)logp(xi,zi;θ)Q(zi)
那么究竟怎么确保EM收敛?假定
θt
和
θt+1
是EM第
t
次和第
固定
θt
后,E步
该步保证了在给定 θt 时,Jensen不等式中的等式成立,即
固定 Qt(zi) ,M步:
将 θt 视作变量,对 L(θt) 求导等于零可得到 θt+1 ,则下式成立:
证毕。
如果定义
则 J(Q,θ) 是 L(θ) 的下界。EM可以看作是 J 的坐标上升法,E步固定
EM和GMM
给定训练样本
{xi}Ni=1
,隐含类别标签用
zi
表示。与K-means硬指定不同,GMM认为
zi∈{1,2,...,K}
满足多项式分布
zi∼M(ϕ)
,其中
p(zi=j)=ϕj
,
ϕj≥0
,
∑Kj=1ϕj=1
。假定在给定
zi
的条件下
xi
满足多值高斯分布,即
(xi|zi=j)∼N(μj,σj)
,则联合分布
p(xi,zi)=p(xi|zi)p(zi)
。
GMM:
对于每个样例 xi ,先从 K 个类别中按多项式分布抽取一个
该式不存在闭合解。考虑EM的思想,第一步是猜测隐含类别变量 ,第二步是更新其他参数,以获得最大的最大似然估计。
E步:固定
θ=(ϕj,μj,σj)
,求
即每个样例
xi
的隐含类别
zi
为
j
的概率可以通过后验概率计算得到。对比K-means发现,每个样例分配的类别
M步:固定
wi(j)
,最大化
求参数
θ=(ϕj,μj,σj)
。
对
μj,σj
求导,得
令其等于0,解得:
同时,由于 ϕj≥0 ,且 ∑Kj=1ϕj=1 ,故建立拉格朗日函数
其中, ϕj 相关的常数被省略了。对 ϕj 求导等于0,结合 ∑Kj=1ϕj=1 可解得:
即:
算法过程如下:
循环下面步骤,直到收敛:{
(E步)对于每一个 i 和j 计算
wi(j)=12π√σjexp(−(xi−μj)22σ2j)⋅ϕj∑k=1K12π√σkexp(−(xi−μk)22σ2k)⋅ϕk
(M步),更新参数:
ϕj=1N∑i=1Nwi(j)μj=∑Ni=1wi(j)xi∑Ni=1wi(j)σ2j=∑Ni=1wi(j)(xi−μj)2∑Ni=1wi(j)
}
E步中,将其他参数 ϕ,μ,σ 看作常量,计算 zi 的后验概率,也就是估计隐含类别变量。估计好后,利用上面的公式重新计算其他参数,计算好后发现最大化最大似然估计时, wi(j) 值又不对了,需要重新计算,周而复始,直至收敛。
GMM示例
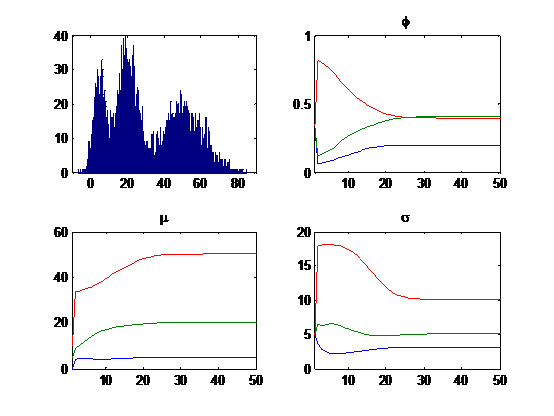
给定由三个高斯的组成的混合模型(
K=3
),其中:第一个高斯的均值
μ1=5
、方差
σ1=3
,第二个高斯的均值
μ2=20
、方差
σ2=5
,第三个高斯的均值
μ3=50
、方差
σ3=10
,且三个高斯出现的概率为
ϕ1=0.2
、
ϕ1=0.4
、
ϕ1=0.4
。由该GMM生成10000个样本(
N=10000
),并根据样本和给定的初始参数
ϕ=[0.33,0.33,0.34]
、
μ=[0,5,10]
、
σ=[5,5,5]
,迭代学习50次结果后收敛到
ϕ=[0.1969,0.4082,0.3950]
、
μ=[4.9686,20.0338,50.0925]
、
σ=[3.0639,5.0977,10.1096]
。下图给出了10000个样本的分布和50次迭代学习参数变化情况。
Matlab代码:
% 生成过程
phi1 = 0.2; mu1 = 5; sigma1 = 3;
phi2 = 0.4; mu2 = 20; sigma2 = 5;
phi3 = 0.4; mu3 = 50; sigma3 = 10;
N = 10000;
x = zeros(N,1);
for i = 1 : N
rate = rand;
if rate <= phi1
x(i) = normrnd(mu1,sigma1);
elseif rate <= phi1+phi2
x(i) = normrnd(mu2,sigma2);
else
x(i) = normrnd(mu3,sigma3);
end
end
figure(1); subplot(2,2,1); hist(x,1000);
% 学习过程
mu = [0, 5, 10];
sigma = [5, 5, 5];
phi = [0.33, 0.33, 0.34];
w = zeros(N,3);
T = 50;
mu_ = zeros(T+1,3);
sigma_ = zeros(T+1,3);
phi_ = zeros(T+1,3);
mu_(1,:) = mu;
sigma_(1,:) = sigma;
phi_(1,:) = phi;
for t = 1 : T
% Expectation
for k = 1 : 3
w(:,k) = phi(k)*normpdf(x,mu(k),sigma(k));
end
w = w./repmat(sum(w,2),[1 3]);
% Maximization
for k = 1 : 3
mu(k) = w(:,k)'*x / sum(w(:,k));
sigma(k) = sqrt(w(:,k)'*((x-mu(k)).*(x-mu(k))) / sum(w(:,k)));
phi(k) = sum(w(:,k)) / N;
end
mu_(t+1,:) = mu;
sigma_(t+1,:) = sigma;
phi_(t+1,:) = phi;
end
figure(1); subplot(2,2,2); plot(phi_); title('\phi');
figure(1); subplot(2,2,3); plot(mu_); title('\mu');
figure(1); subplot(2,2,4); plot(sigma_); title('\sigma');














 283
283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









