







The function twoSum should return indices of the two numbers such that they add up to the target, where index1 must be less than index2. Please note that your returned answers (both index1 and index2) are not zero-based.
You may assume that each input would have exactly one solution.
Input: numbers={2, 7, 11, 15}, target=9
Output: index1=1, index2=2
最开始看到这道题,首先想到的就是暴力搜索:即先取第一个元素,然后再去遍历其后的元素,直到找到匹配的第二个元素;若没有找到,则再取第二个元素,重复之前的操作。这种算法的时间复杂度是o(n2)。提交了之后发现Runtime Error,看来用暴力搜索这种最简单的方式是过不了了。
后来想到了在选定第一个元素后,可以在第二个元素的查找方法上做文章。暴力搜索对第二个元素的查找方式是简单的遍历,复杂度是o(n),所以我马上想到了可以用二分查找,其复杂度是o(log n)。由于要想用二分查找,首先需要对数组进行排列,可以使用快速排序,其平均时间复杂度是o(n*log n)。故采取此种方法的总时间复杂度为o(n)*o(log n)+o(n*log n)=o(n*log n)。快速排序可以调用C语言标准库的qsort()函数,提交后成功AC。
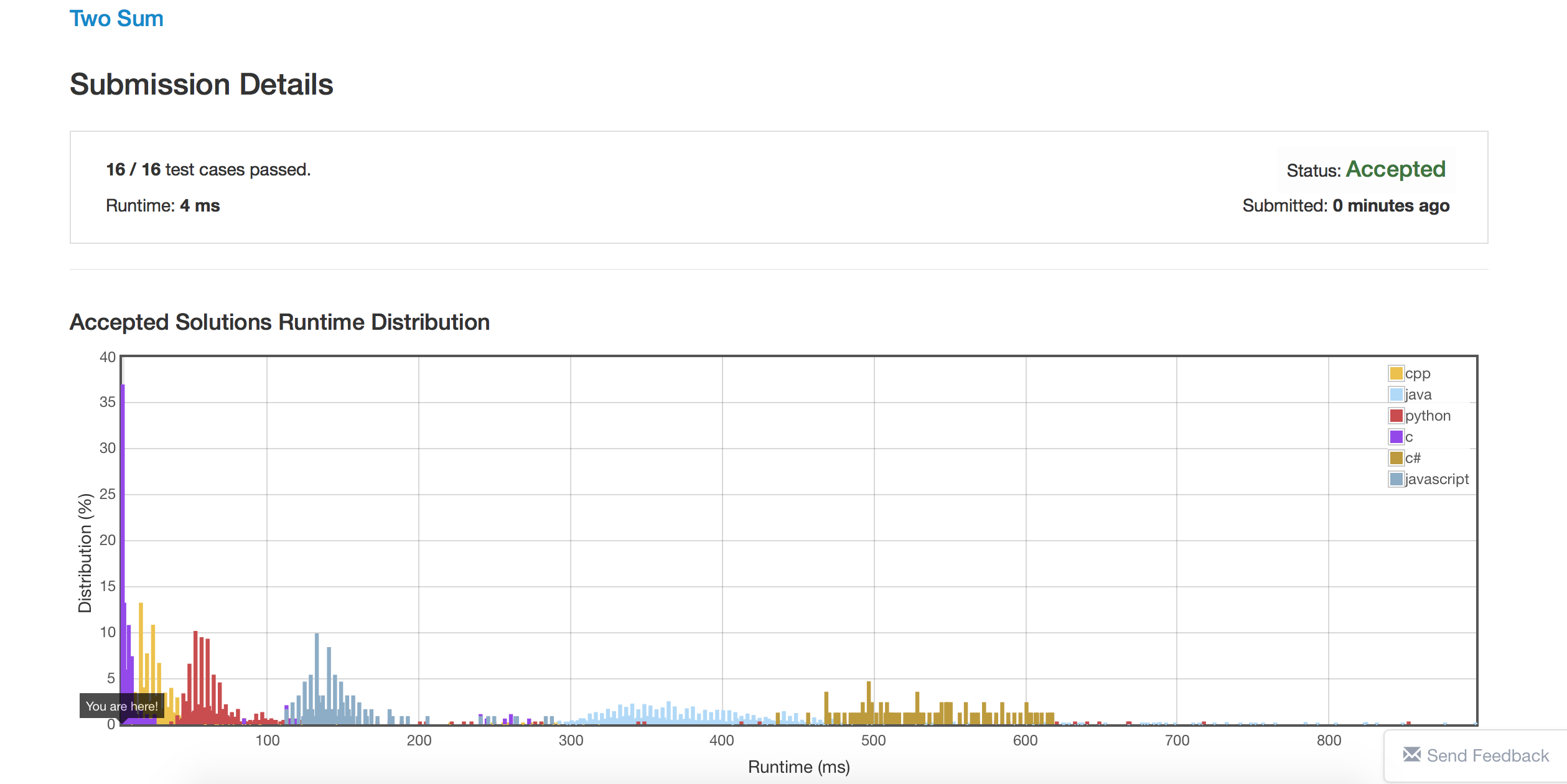
方法一:快速排序+二分查找。Runtime:4ms
struct indexStruct
{
int data;
int indice;
};
int cmp(const void *a,const void *b)
{
struct indexStruct *c=(struct indexStruct*)a;
struct indexStruct *d=(struct indexStruct*)b;
return c->data > d->data ? 1 : -1;
}
int *twoSum(int *nums,int numSize,int target)
{
int i,j,k,m;
int *indices=malloc(sizeof(int)*2);
struct indexStruct index_struct[numSize];
for(i=0;i<numSize;i++)
{
index_struct[i].data=nums[i];
index_struct[i].indice=i;
}
qsort(index_struct,numSize,sizeof(struct indexStruct),cmp);
for(i=0;i<numSize-1;i++)
for(j=i+1,k=numSize-1,m=(j+k)/2;j<=k;m=(j+k)/2)
{
if(index_struct[m].data + index_struct[i].data == target)
{
indices[0]=index_struct[i].indice < index_struct[m].indice ? index_struct[i].indice+1 : index_struct[m].indice+1;
indices[1]=index_struct[i].indice < index_struct[m].indice ? index_struct[m].indice+1 : index_struct[i].indice+1;
return indices;
}
else if(index_struct[m].data + index_struct[i].data > target)
{
k=m-1;
}
else if(index_struct[m].data + index_struct[i].data < target)
{
j=m+1;
}
}
indices[0]=0;
indices[1]=0;
return indices;
}
然后上网搜索了一下,发现网上说最好的办法是用哈希表的方法,即采取“用空间换时间”的思想。将每个数组的元素利用hash函数映射的固定的位置,这么当选取第一个元素后,查找第二个元素时就能直接去查找,而不用遍历或比较了。这个方法总的时间复杂度为o(n)。这么说看起来很美好,可实际上里面还是存在一些问题。由于C语言不像C++有STL这样现成的容器可以调用,故我翻出以前的《数据结构》课本,写了一个最简单的“直接定址+开放定址”的hash表。具体写出了2种方法:
1.初始化HashTable数组长度为40000(经测试30000之内的数都不能AC,说明测试案例中最大的数超过30000),f(key)=key
2.初始化HashTable数组长度为numSize*NF(2 =< NF <= 30,由于numSize的大小,NF较大时会使HashTable数组溢出),f(key) = key % ( numSize * NF )
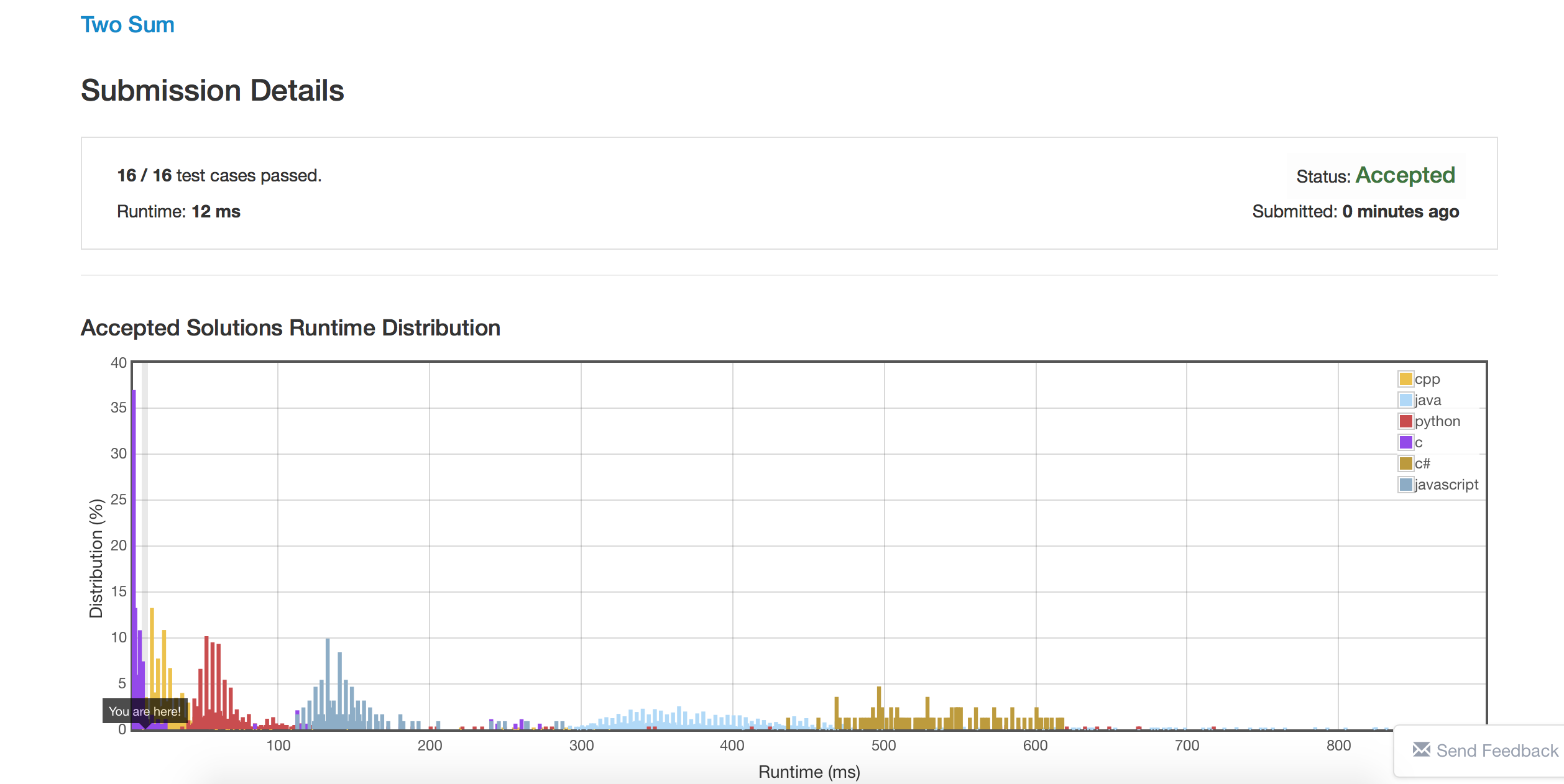
经过测试第1种方法AC后用时为12ms,第二种方法在NF较小时用时12ms,NF较大时用时16ms,原因也很简单,如果HashTable开的过大,对冲突率和查找速度并没什么影响,但初始化时会花费更多的时间。
方法二:直接映射,哈希表长度与numSize无关。Runtime:12ms
#define HashTableSize 40000
struct elem
{
float key;
int indice;
};
int searchHashTable(struct elem *hash_table,int key,int *p,int indice) //key&&(!indice) means success!
{
*p = key >= 0 ? key : -key;
while(hash_table[*p].key != 0.5 && (hash_table[*p].key != key || hash_table[*p].indice == indice))
{
(*p)++;
if(*p == HashTableSize)
*p = 0;
}
if(hash_table[*p].key != 0.5)
return 1;
else
return 0;
}
void insertHashTable(struct elem *hash_table,int indice,int key)
{
int p;
if(searchHashTable(hash_table,key,&p,-1))
{
do
{
++p;
if(p == HashTableSize)
p = 0;
}while(hash_table[p].key != 0.5);
hash_table[p].key=key;
hash_table[p].indice=indice;
}
else
{
hash_table[p].key=key;
hash_table[p].indice=indice;
}
}
int *twoSum(int *nums,int numSize,int target)
{
struct elem HashTable[HashTableSize];
int *indices=malloc(sizeof(int)*2);
int i,num2,p,j;
for(i=0;i<HashTableSize;i++)
{
HashTable[i].indice = -2;
HashTable[i].key = 0.5;
}
for(i=0;i<numSize;i++) insertHashTable(HashTable,i,nums[i]);
for(i=0;i<numSize;i++)
{
num2 = target - nums[i];
if(searchHashTable(HashTable,num2,&p,i))
{
j = HashTable[p].indice;
indices[0]= i < j ? i+1 : j+1;
indices[1]= i < j ? j+1 : j+1;
return indices;
}
}
indices[0] = 0;
indices[1] = 0;
return indices;
}方法三:取模映射,哈希表长度与numSize有关。Runtime:>=16ms
#define NF 2
struct elem
{
float key;
int indice;
};
int searchHashTable(struct elem *hash_table,int key,int *p,int indice,int numSize) //key&&(!indice) means success!
{
*p = (key >= 0 ? key : -key) % (numSize);
while(hash_table[*p].key != 0.5 && (hash_table[*p].key != key || hash_table[*p].indice == indice))
{
(*p)++;
if(*p == numSize)
*p = 0;
}
if(hash_table[*p].key != 0.5)
return 1;
else
return 0;
}
void insertHashTable(struct elem *hash_table,int indice,int key,int numSize)
{
int p;
if(searchHashTable(hash_table,key,&p,-1,numSize))
{
do
{
++p;
if(p == numSize)
p = 0;
}while(hash_table[p].key != 0.5);
hash_table[p].key=key;
hash_table[p].indice=indice;
}
else
{
hash_table[p].key=key;
hash_table[p].indice=indice;
}
}
int *twoSum(int *nums,int numSize,int target)
{
struct elem HashTable[numSize*NF];
int *indices=malloc(sizeof(int)*2);
int i,num2,p,j;
for(i=0;i<numSize*NF;i++)
{
HashTable[i].indice = -2;
HashTable[i].key = 0.5;
}
for(i=0;i<numSize;i++) insertHashTable(HashTable,i,nums[i],numSize*NF);
for(i=0;i<numSize;i++)
{
num2 = target - nums[i];
if(searchHashTable(HashTable,num2,&p,i,numSize*NF))
{
j = HashTable[p].indice;
indices[0]= i < j ? i+1 : j+1;
indices[1]= i < j ? j+1 : j+1;
return indices;
}
}
indices[0] = 0;
indices[1] = 0;
return indices;
}
小结:
1.由于此题要返回初始数组的索引,所以不管是采用二分查找还是哈希表的方法,都要用到struct结构数组,用成员indice保存初始的索引值。
2.hash表的构建要注意的几点:1)每个key经hash函数映射后都能保存到HashTable里。涉及到哈希函数的设计和哈希表大小的考虑;2)哈希表不能被装满,否则当出现表中不存在被查找的元素的情况时,既查找不到,又没有空纪录,将造成死循环。涉及到哈希表大小的考虑。
------------------------------分割线----------------------------------
这是我做的第一道Leetcode题目,做的过程中复习了二分查找和哈希表。由于未来两年在实验室主要都是用C,所以这些题目也都是用C来写的。感觉到了C语言的开发效率果然还是太低,很多东西还是得靠自己手写,缺少像C++的STL这样的容器或者Python的字典这样的东西。不过还是感受到了C语言“粒度比较小”这种特性,故也更加自由。并且看到AC后显示的Runtime图,彻彻底底的感受到了C语言在执行效率上的王者地位啊!
要学的东西还有很多。二分查找我之前应该是写过的,所以第一个方法很快就提交AC了,可hash表我还是第一次写,即使是这么一个最简单的hash,这么一个效率还不如二分查找的hash。。都花了我一个上午的时间。写的时候想到了一个梗,记得以前大二学《数据结构》的时候就和早上陪着我上自习的大衍说过想把书上所有的算法在学的时候都用C实现一遍,结果最后也就是当时想了想而已。。哎,大学都干啥了。现在开始努力,希望还不晚。毕竟为了毕业后有好的offer,我要把Leetcode的题目都刷完,并且坚持写总结的文章。先用C写一遍,以后再用正在学的Python实现一遍。我相信在这个过程中肯定能锻炼我的语言、算法、数据结构的基本功的。临近研三上的校招还有15个月,加油!















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









