







文章目录
原文:Hussein Jundi Job Search with AI Agents
Github:https://github.com/Husseinjd/job-search-2.0
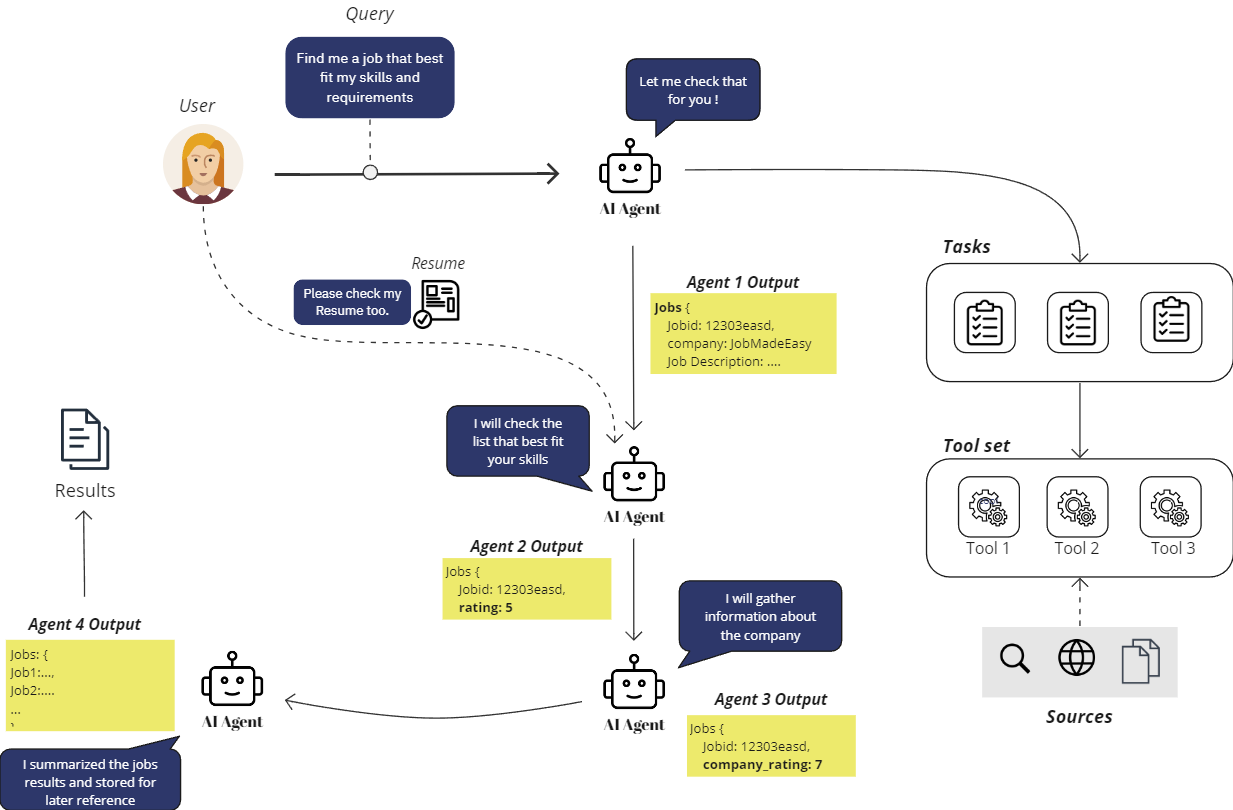
用 AI 代理进行求职 — 图片由作者提供
用户:AI,请帮我找到最适合我的简历的工作。
AI:好的。
求职可能会很困难且耗时。在浏览工作列表并最终找到工作之前,可能需要花费数周甚至数月的时间。
求职者的挣扎 — 图片由作者提供
所需时间取决于许多因素,如专业知识、角色需求、市场等等。但根据美国劳工统计局的失业数据(包括被动寻找工作的人)显示,2024年3月的中位持续时间为 21.6 周 ~ 5 个月。
以人类的年龄衡量,考虑到普通求职者寻找新工作所需的时间,这是花费在筛选数百份申请上的大量无法找回的生命时间。
提交的申请数量是成功找到工作的因素之一。一项研究结果显示,平均需要提交 100–200+ 份申请 才能找到合适的职位,尽管这可能会因市场、经济状况和申请者的专业知识而有所不同。为了搜索工作而投入的大量申请和努力,正是我们构建高效可扩展解决方案的动力,可以为个人节省数千小时的时间。
每位求职者面临的常见挑战(为什么…)

求职挑战 — 作者使用 OpenAI 的 DALLE-3 生成的图像
在充斥着工作列表的市场中找到最适合自己技能和要求的角色是具有挑战性的。如果你曾处于这种境地,你就知道浏览数百个列表、尝试匹配技能、薪资范围、先决条件等是多么具有压力和疲劳感。寻找的过程越长,一个人的动力就越低,放弃搜索并妥协的可能性就越高。
找到合适角色所需的时间因个人经验、申请时机以及其技能在职场中的需求程度而异。其他无法控制的因素包括影响所申请行业和组织的因素。
本文中我们在构建 AI 动力的求职引擎时所面临的挑战主要集中在优化求职和匹配流程上,从而解决以下关键挑战:
关键挑战
-
求职广告搜索:传统上,筛选工作始于选择合适的平台,在这些平台上发布了招聘信息。通过筛选具有特定标准的工作并评估最终结果,吸收它们的所有内容。为了更好地覆盖范围,许多人选择在多个平台上工作。当需要在多个来源之间周旋并跟踪各处信息时,困难就开始了。
-
求职广告评估:这份工作广告是否符合我的以往经验和技能?我是否具有所需的工作经验年限?它是否位于正确的位置?我需要说什么语言?薪资范围是否符合我的需求?角色的开始日期是什么时候?这些都是评估工作广告是否符合自己要求时会产生的一些问题。
-
组织评估:在求职筛选过程中的一个常见步骤是研究组织。一些评估组织的常见标准包括员工评价、市场表现、声誉等等。根据组织所在市场的不同,还可以引入更多的基准或标准。如果您正在寻找跨市场机会,考虑到需要考虑的所有因素,这一步可能会非常耗时。
-
工作筛选:在做出最终决定之前,经过对数十甚至数百个工作列表的筛选,您决定将通过的少数工作进行筛选。无论选择哪种方法,都需要一种基于某些标准的评分策略来对列表进行排序。这些是基于个人偏好和优先事项的主观评级。您可以想象到,需要对工作列表进行多次混合和匹配才能完成这项任务。
⚠️ 注意: 在寻找工作过程中遇到的挑战远不止上面列出的那些。讨论的列表针对的是文章内容和解决方案范围。
这些挑战包括重复性任务、需要强大的推理能力以及需要消化大量内容以得出清晰的可行列表。
这些任务完全符合采用LLM动力代理的关键特征。
人工智能代理在优化求职过程中的关键作用(“什么……”)
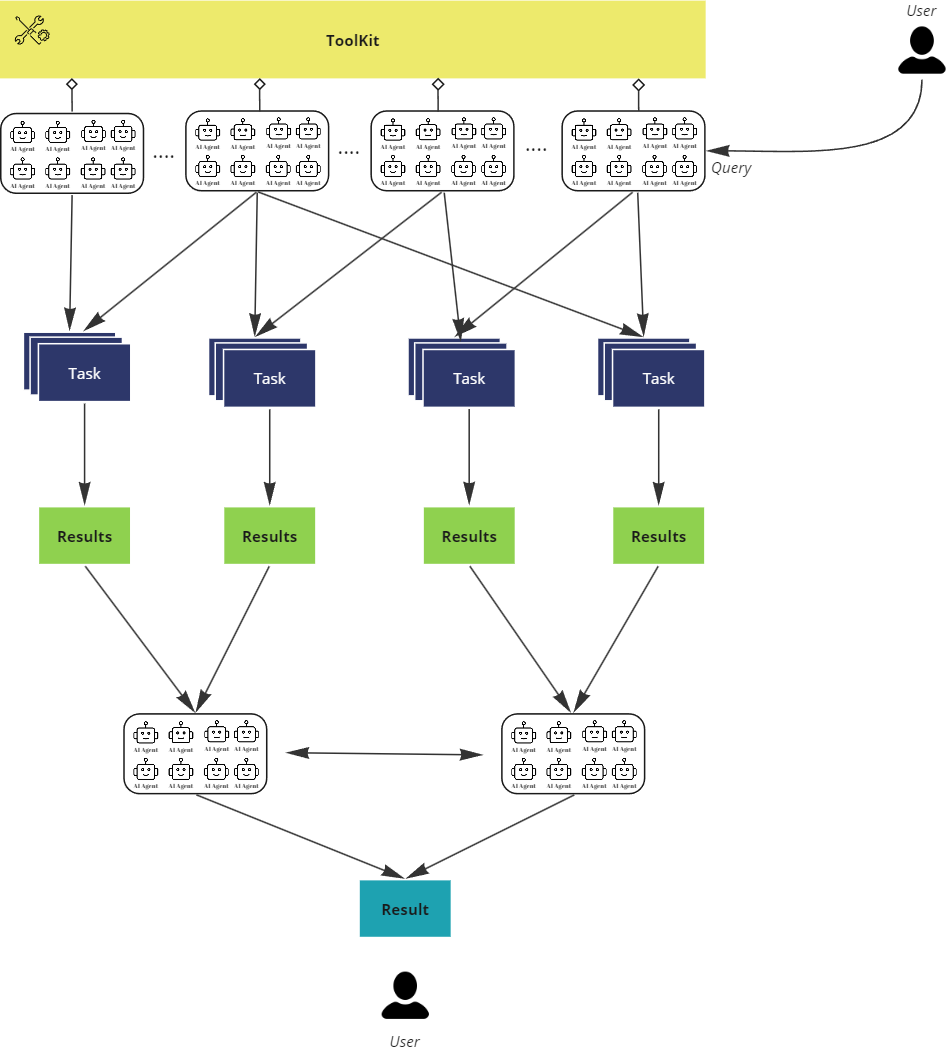
代理工作流程-作者提供的图像
想象一下雇佣了数百名能够筛选工作广告、深入评估广告公司及其招聘信息,并最终量身定制建议以最符合您需求的个体。这是一个全方位的流程,建立在自动化和推理之上,极大地减少了任何人筛选在线工作广告所需的时间。
让我们分析一下人工智能代理在自动化和个性化求职搜索和推荐方面的能力。我们将在接下来的部分进一步探讨构建引擎的内容。现在,我们关注人工智能代理带来了什么。
1. 代理可以利用工具
代理能够利用定义好的工具来完成任务。这包括能够提供更好的研究能力的工具,比如提供搜索互联网和使用预定义API请求数据的工具。这扩展了代理的能力,使其能够与远远超出其训练数据范围的大量工具进行交互,并且额外提供了用户如何使用选定工具包来解决特定任务的指导能力。
2. 代理可以消化大量信息
随着人工智能模型上下文窗口的增大(1ml+),甚至达到无限上下文窗口,代理可以消化和推理的信息量不断增加。正确分配,代理可以分析无限量的信息并向用户提供最终的摘要版本。
3. 代理可以推理
虽然人工智能代理的推理能力可能存在局限性,但新的、改进的、并且越来越频繁发布的优化模型正在逐渐缩小这一差距。考虑到分析工作广告并将其与用户查询基于某些参数进行比较的任务,对于训练有素的人工智能代理来说,该任务可能被认为是一个简单的分析任务。
4. 代理可以总结和结构化结果
一个能够处理大量信息的工具是有价值的,但当它无法以有效和结构化的方式传递信息时,它就失去了其价值。人工智能代理容易出现幻觉,这可能会影响信息的摘要和报告方式。提供良好设计的提示和额外的验证步骤可以确保代理以正确和可靠的结果完成其任务。
5. 代理可以协作
6. 代理可扩展
将大量代理动态分配到任务的并行执行中是非常强大的。当问题可以分解为较小的部分并由单独的代理处理时,这种方法会显现出优势。可以将大量代理分配给一批职位发布任务,每个代理负责处理流程中的一步,并将结果传递给下一个阶段。最后,代理可以汇总结果并根据预定义模型进行结构化。这是构建跨多个渠道或来源快速可扩展的职位广告处理的一种方法。
我们如何将所有这些能力整合到我们的用例中呢?
引入 AI 代理的能力到流程中(如何。。。)
为了确保解决方案充分利用所有 AI 能力,我们在流程的每个步骤都引入了代理。
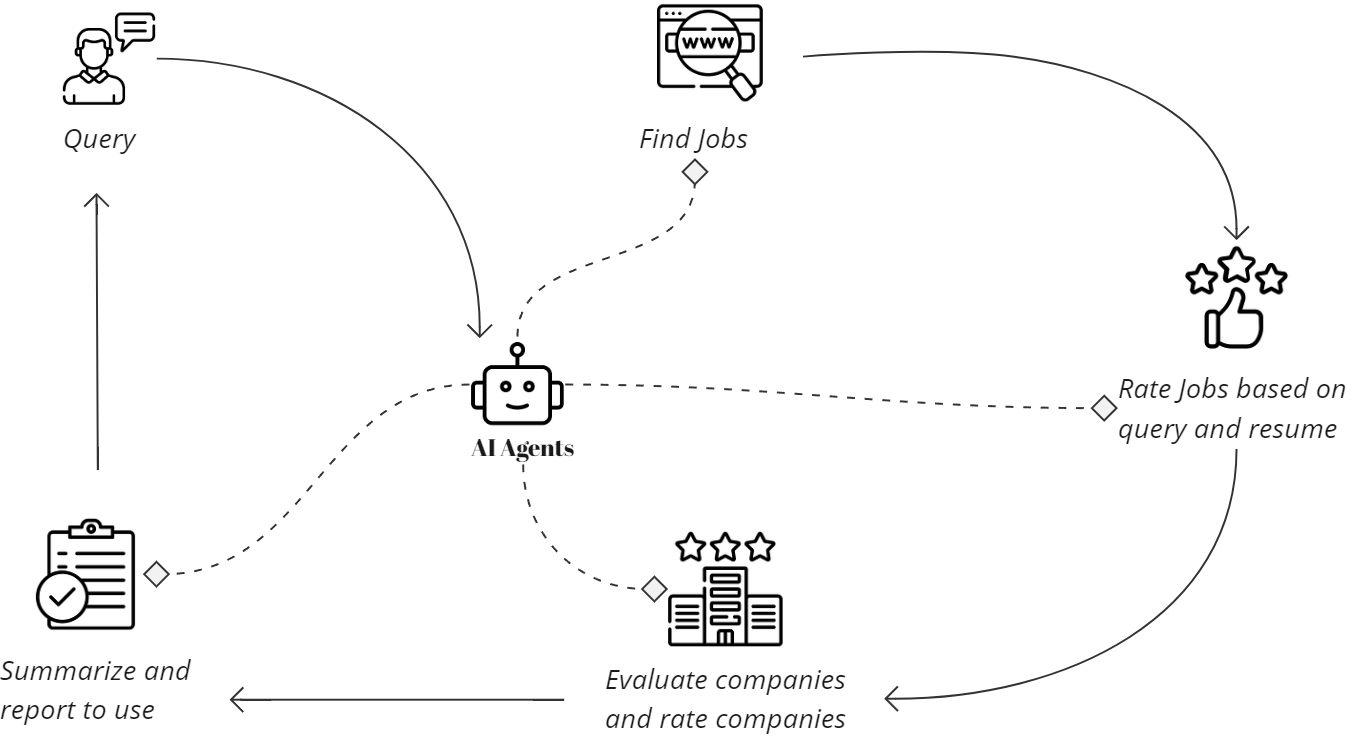
代理任务 — 图片由作者生成
-
代理将使用工具 检索 职位广告的信息。初始职位发布将根据用户查询进行检索。
-
代理将根据用户的简历和查询为职位发布 评分 并解释评分背后的理由。
-
代理将使用互联网访问工具 研究 有关职位广告来源组织的信息,并根据此信息为组织提供评分。
-
代理最终将 总结 结果,并根据预定义模型 结构化 结果。
下一节将深入探讨如何利用列出的 AI 代理能力构建职位搜索引擎。
实践教程:构建 AI 驱动的职位搜索引擎
在当前部分,我们将逐步介绍完整的实现过程,并以分析最终结果和潜在改进结束。
项目结构
项目结构确保功能和组件之间的明确分离,提供了更轻松的方法来修改和调整代码以满足您的要求。它包括:
- 一个
configs目录,包含配置代理(角色、背景、背景故事)和任务(描述和预期输出)所需的所有配置和参数 - 一个
data目录,包含测试职位搜索引擎所需的所有数据 - 一个
models目录,包含定义的期望输出模型 - 一个
utils目录,包含所需的支持函数 agents_factory.py和tasks_factory.py用于根据定义的配置动态生成代理和任务的工厂类
project/
├── configs
│ └── agents.yml # 代理配置
│ └── tasks.yml # 任务配置
│
├── data
│ ├── sample_jobs.json # 包含职位列表的 JSON 文件
│ └── sample_resume.txt # 包含简历的文本文件
│
├── models
│ └── models.py # ORM 模型
│
├── utils
│ └── utils.py # 实用函数和辅助程序
│
├── .env # 包含所有所需环境变量
│
├── agents_factory.py # 用于创建代理实例的工厂类
├── tasks_factory.py # 用于创建任务实例的工厂类
│
└── main.py # 主文件
框架
该项目将利用 crewAI 框架 构建端到端应用程序。它提供了一个简单的接口来构建具有分配任务和特定工具的 AI 代理。它与其他可用的 AI 框架非常好地集成在一起,因此完全适合本文的范围。
首先确保一个 Python 环境(我使用的是 python-3.11.9)可用,并使用所有所需的工具安装框架。
pip install 'crewai[tools]'
安装 crewai[tools] 包应该涵盖运行应用程序所需的所有包。
工具
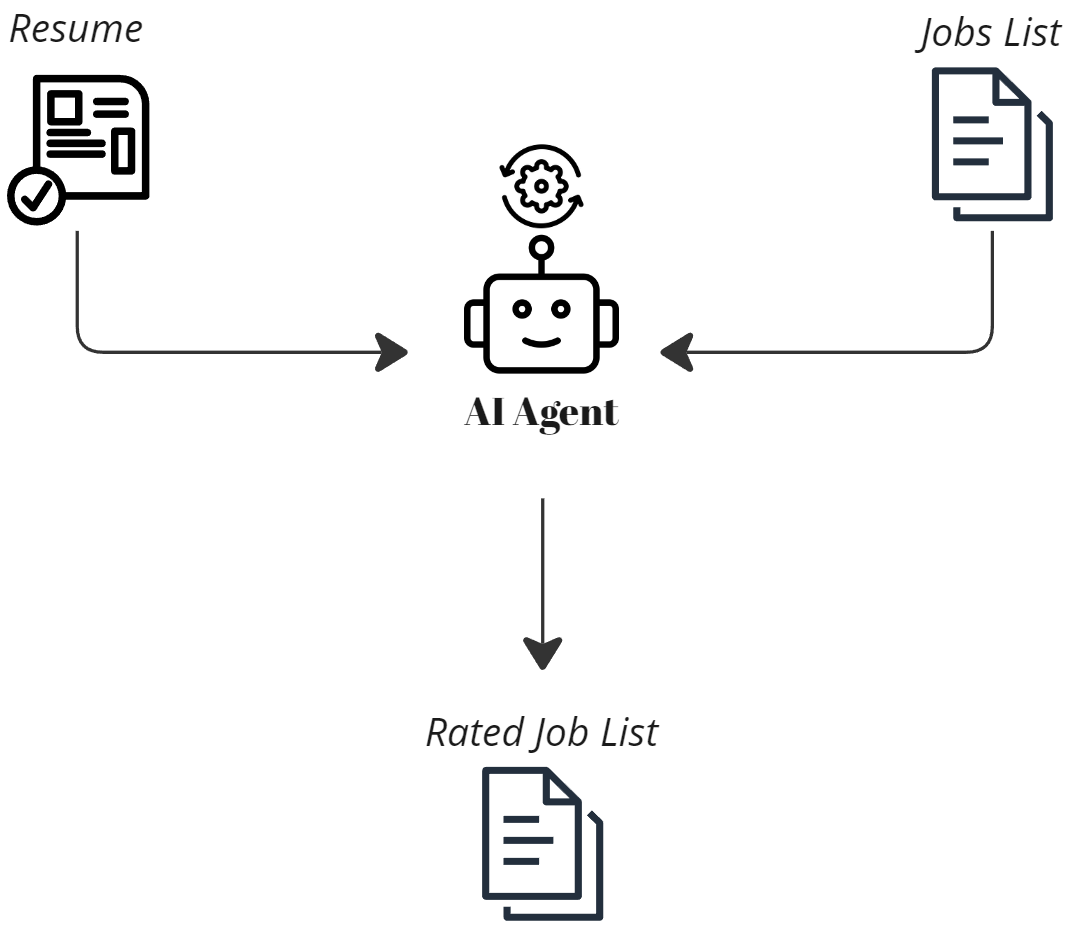
代理工具 — 图片由作者生成
代理将需要一组工具来完成其分配的任务。将工具分配给代理将取决于我们如何定义请求流架构以及信息如何从一个代理传递到另一个代理。
为测试我们的用例,需要两个工具,这两个工具已经在 crewAI 中可用。
FileReadTool
在生产规模上,当人们能够积累大量可靠的 API 提供职位数据时,最常用的代理工具是那些可以与多个提供商进行接口并根据选择的参数获取职位信息的工具。
针对我们应用的范围,我们将使用已经检索到的JSON响应 *sample_jobs.json*,其中包含一系列工作详细信息,以便重点展示解决方案。
另外提供一个生成的简历 *sample_resume.txt* 用于测试代理提供的评分。
SerperDevTool
代理将被指派收集关于组织的信息,并为用户提供评级反馈。这个工具通过使代理能够搜索互联网来支持这一过程。要使用该工具,请确保在 serper.dev 上创建帐户以获取所需的API密钥,并将其加载到环境中。
确保API密钥在 .env 文件中定义。
SERPER_API_KEY=<>
工具可以直接导入
from crewai_tools import FileReadTool, SerperDevTool
添加工具并分配给代理使得通过新功能快速、简单地扩展应用程序范围成为可能。
数据
*sample_jobs.json* 包含一个JSON响应,其中包含一系列合成AI生成的样本招聘广告,用作我们用例的测试数据。
虽然本文中呈现的工作数据是以JSON格式呈现的,但也可以轻松转换为其他任何格式供代理解析,比如个人收集的作业描述数据文档存储为简单文本、PDF或Excel文件。
充分利用搜索过程需要代理使用工具与工作平台API进行接口,以实现数据摄入过程的全面自动化和可扩展性。此类官方工作搜索API提供商的示例包括 Glassdoor 或 Jooble。
💡 用户确保收集任何工作数据符合供应商设置的服务条款非常 重要。
{
"jobs": [
{
"id": "VyxlLGIsICxELGUsdixlLGwsbyxwLGUscixELGUsbSxhLG4sdCxTLHkscixhLGMsdSxzLGUsLCwgLE4=",
"title": "Web Developer",
"company": "Apple",
"description": "作为CQ Partners的Web开发人员,您将成为网站和基于web的应用程序的构建、维护和促进领导者...",
"image": "<https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQAkPEjEwMeJizfsnGN-qUAEw8pmPdk357KIzsi&s=0>",
"location": "纽约州锡拉丘兹",
"employmentType": "全职",
"datePosted": "17小时前",
"salaryRange": "",
"jobProvider": "LinkedIn",
"url": "<https://www.linkedin.com/jobs/view/web-developer-at-demant-3904417702?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic>"
},
{
"id": "VyxlLGIsICxELGUsdixlLGwsbyxwLGUsciwsLCAsVSxYLC8sVSxJLCwsICxCLHIsYSxuLGQsaSxuLGc=",
"title": "Web Developer, UX/UI, Branding, Graphics",
"company": "Adobe",
"description": "所需学位:相关领域的学士学位...",
"image": "<https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSV7-v1EkEhWtAh8W8WaqPD6vMQG2uBi0GOOOmb&s=0>",
"location": "马里兰州哥伦比亚",
"employmentType": "全职",
"datePosted": "1天前",
"salaryRange": "",
"jobProvider": "LinkedIn",
"url": "<https://www.linkedin.com/jobs/view/web-developer-ux-ui-branding-graphics-at-adg-creative-3903771314?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic>"
},
......
另外还有一个包含经验丰富的数据科学家生成简历的 *sample_resume.txt* 文件。
你可以在 Github 上获取这些文件的完整内容。
任务
任务分发给携带正确工具和技能的代理执行。
每个任务都有一个描述,一个期望输出,以及负责完成它的代理。
# configs/tasks.yml
job_search:
description: |
找到满足以下要求的工作列表: {query}
expected_output: 作为有效json结构化输出,列出所有找到的工作及其信息。确保字段名称保持不变。
job_rating:
description: |
使用你的工具查找简历文件信息。
根据简历信息为你收到的工作提供额外评级。
根据上下文,评级介于1-10之间,10分为最适合。每个工作都应有一个评级。
此外,增加一个 rating_description 字段,说明评级背后的理由,用1或2句话描述。
确保所有关于工作的信息也保留在输出中。
expected_output: 作为有效json结构化输出,列出找到的工作及其相应评级。确保字段名称保持不变。
evaluate_company:
description: |
使用你的工具查找工作公司的信息。
信息可以包括公司文化评论,公司财务报告和股票表现。
为公司额外提供一个名为 company_rating 的评级。
评级介于1-10之间,10分为最佳评级。每个工作都应有一个评级。
此外,增加一个 company_rating_description 字段,用1或2句话解释评级背后的原因。
确保所有关于工作的信息也保留在输出中。
expected_output: 作为有效json结构化输出,列出找到的工作及其相应评级,确保根据此模型{output_schema}构建所有信息。
structure_results:
description: |
利用所有上下文来结构化输出以满足最终报告的需要。
expected_output: 作为有效json结构化输出,列出找到的工作及其相应评级。确保你提供的最终输出是有效json,符合{output_schema}模式。
TasksFactory 类用于生成所有需要的任务。
# project/tasks_factory.py
from textwrap import dedent
from typing import Optional
from crewai import Agent, Task
from utils.utils import load_config # 加载 YAML
class TasksFactory:
def __init__(self, config_path):
self.config = load_config(config_path)
def create_task(
self,
task_type: str,
agent: Agent,
query: Optional[str] = None,
output_schema: Optional[str] = None,
):
task_config = self.config.get(task_type)
if not task_config:
raise ValueError(f"No configuration found for {task_type}")
description = task_config["description"]
if "{query}" in description and query is not None:
description = description.format(query=query)
expected_output = task_config["expected_output"]
if "{output_schema}" in expected_output and output_schema is not None:
expected_output = expected_output.format(output_schema=output_schema)
return Task(
description=dedent(description),
expected_output=dedent(expected_output),
agent=agent,
)
代理
代理具有角色、目标和背景故事,以最好地完成所选任务。
# configs/tasks.yml
job_search_expert:
role: 最佳求职代理
goal: 通过找到最佳的工作职位和广告来给所有请求者留下深刻印象
backstory: 在职场中拥有丰富经验的资深求职分析师。
job_rating_expert:
role: 最佳工作评分代理
goal: 通过您找到与简历信息最匹配的工作,并提供准确评分的能力,给所有请求者留下深刻印象
backstory: 在工作匹配和评分方面拥有丰富经验的资深工作评分专家
company_rating_expert:
role: 最佳公司评估代理
goal: 找到关于公司的所有重要信息,以评估工作的适宜性
backstory: 在公司信息查找和评估方面拥有丰富经验的资深公司信息查找和评估专家
summarization_expert:
role: 最佳输出验证和总结者
goal: 确保任务所需的最终输出符合任务要求
backstory: 是最有经验的报告专家,知道如何根据需要和正确的结构报告输出
类似于 TasksFactory,AgentsFactory 类用于根据其配置生成所有需要的 AI 代理。
# project/agents_factory.py
from typing import Any, List, Optional
from crewai import Agent
from utils.utils import load_config # 加载 YAML
class AgentsFactory:
def __init__(self, config_path):
self.config = load_config(config_path)
def create_agent(
self,
agent_type: str,
llm: Any,
tools: Optional[List] = None,
verbose: bool = True,
allow_delegation: bool = False,
) -> Agent:
agent_config = self.config.get(agent_type)
if not agent_config:
raise ValueError(f"No configuration found for {agent_type}")
if tools is None:
tools = []
return Agent(
role=agent_config["role"],
goal=agent_config["goal"],
backstory=agent_config["backstory"],
verbose=verbose,
tools=tools,
llm=llm,
allow_delegation=allow_delegation,
)
LLM
关于选择 LLMs 的选项范围不断增长,几乎每周都会发布新模型。在这个设置中,我们将使用 Azure Open AI 模型,具体是 gpt-4–32k 版本 0613。但是,可以随意调整和测试代码以适应您喜欢的 LLM。
要使用 Azure OpenAI 模型,需要 API KEY 和 ENDPOINT。Azure 提供了很好的 文档 来设置和部署这些模型。
我们将所需的环境变量添加到 .env 文件中
OPENAI_API_VERSION = <>
AZURE_OPENAI_KEY= <>
AZURE_OPENAI_ENDPOINT = <>
使用以下代码导入并使用所选模型。
from langchain_openai import AzureChatOpenAI
import os
azure_llm = AzureChatOpenAI(
azure_endpoint=os.environ.get("AZURE_OPENAI_ENDPOINT"),
api_key=os.environ.get("AZURE_OPENAI_KEY"),
deployment_name="gpt4",
streaming=True,
temperature=0 # 我们将其设置为 0 以确保输出更一致和准确
)
输出模型
为了确保代理的最终一致输出,我们定义了我们期望的输出模型。
# models/models.py
from typing import List, Optional
from pydantic import BaseModel
class Job(BaseModel):```
# 把一切联系在一起:船员
前面的图示展示了代理人将使用的事件序列,以实现期望的输出。完成一个任务后,将其交给下一个优化了特定角色以处理任务的代理人。因此,配置顺序流程符合我们的目的。您始终可以选择重新构建设计,并选择通过代理人协作和并行处理任务的不同策略来解决任务。
最后,我们在 `main.py` 中创建搜索船员来创建、分配和运行所有 AI 代理。
```python
import json
import os
from textwrap import dedent
from crewai import Crew, Process
from crewai_tools import FileReadTool, SerperDevTool
from dotenv import load_dotenv
from langchain_openai import AzureChatOpenAI
from pydantic import ValidationError
from agents_factory import AgentsFactory
from models.models import JobResults
from tasks_factory import TasksFactory
load_dotenv()
class JobSearchCrew:
def __init__(self, query: str):
self.query = query
def run(self):
# 定义 LLM AI 代理将利用的 AzureChatOpenAI
azure_llm = AzureChatOpenAI(
azure_endpoint=os.environ.get("AZURE_OPENAI_ENDPOINT"),
api_key=os.environ.get("AZURE_OPENAI_KEY"),
deployment_name="gpt4",
streaming=True,
temperature=0,
)
# 初始化所有所需的工具
resume_file_read_tool = FileReadTool(file_path="data/sample_resume.txt")
jobs_file_read_tool = FileReadTool(file_path="data/sample_jobs.json")
search_tool = SerperDevTool(n_results=5)
# 创建代理人
agent_factory = AgentsFactory("configs/agents.yml")
job_search_expert_agent = agent_factory.create_agent(
"job_search_expert", tools=[jobs_file_read_tool], llm=azure_llm
)
job_rating_expert_agent = agent_factory.create_agent(
"job_rating_expert", tools=[resume_file_read_tool], llm=azure_llm
)
company_rating_expert_agent = agent_factory.create_agent(
"company_rating_expert", tools=[search_tool], llm=azure_llm
)
summarization_expert_agent = agent_factory.create_agent(
"summarization_expert", tools=None, llm=azure_llm
)
# 响应模型模式
response_schema = json.dumps(JobResults.model_json_schema(), indent=2)
# 创建任务
tasks_factory = TasksFactory("configs/tasks.yml")
job_search_task = tasks_factory.create_task(
"job_search", job_search_expert_agent, query=self.query
)
job_rating_task = tasks_factory.create_task(
"job_rating", job_rating_expert_agent
)
evaluate_company_task = tasks_factory.create_task(
"evaluate_company",
company_rating_expert_agent,
output_schema=response_schema,
)
structure_results_task = tasks_factory.create_task(
"structure_results",
summarization_expert_agent,
output_schema=response_schema,
)
# 组装船员
crew = Crew(
agents=[
job_search_expert_agent,
job_rating_expert_agent,
company_rating_expert_agent,
summarization_expert_agent,
],
tasks=[
job_search_task,
job_rating_task,
evaluate_company_task,
structure_results_task,
],
verbose=1,
process=Process.sequential,
)
result = crew.kickoff()
return result
if __name__ == "__main__":
print("## 欢迎使用职位搜索船员")
print("-------------------------------")
query = input(
dedent("""
请提供您正在寻找的工作特征列表:
""")
)
crew = JobSearchCrew(query)
result = crew.run()
print("正在验证最终结果..")
try:
validated_result = JobResults.model_validate_json(result)
except ValidationError as e:
print(e.json())
print("数据输出验证错误,请重试...")
print("\n\n########################")
print("## 结果 ")
print("########################\n")
print(result)
任务执行后,我们运行验证检查以确保 JSON 输出符合定义的模型模式。此外,我们还可以潜在地添加进一步的验证循环以确保代理人返回所需的结构。我们不会详细介绍实施这个完整过程的细节,但如果您感兴趣,可以自由查阅关于这个主题的文章。
结果分析
我们只需运行代码
python main.py
对于我们的初始代理查询,我们输入以下内容:
提供您正在寻找的工作的特征列表:
在美国的机器学习和数据科学工作,薪资范围为10万美元至17万美元
查询可以进一步扩展,包括地点、开始日期、行业等等,以及许多其他参数,可以根据需要筛选和查找工作列表。
输出:
终端结果显示第一个代理成功执行并使用工具检索了工作列表内容。
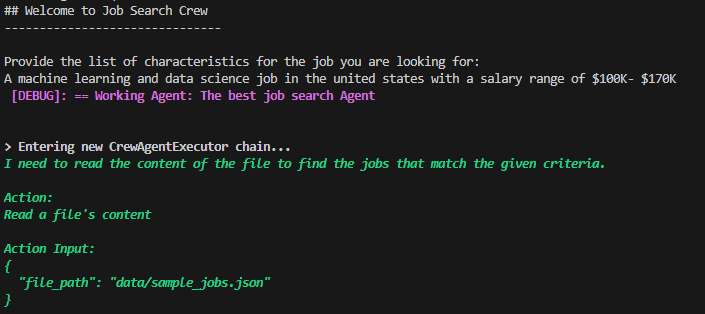
输出1 — 作者生成
然后,代理成功过滤列表并根据输入查询找到正确的工作。
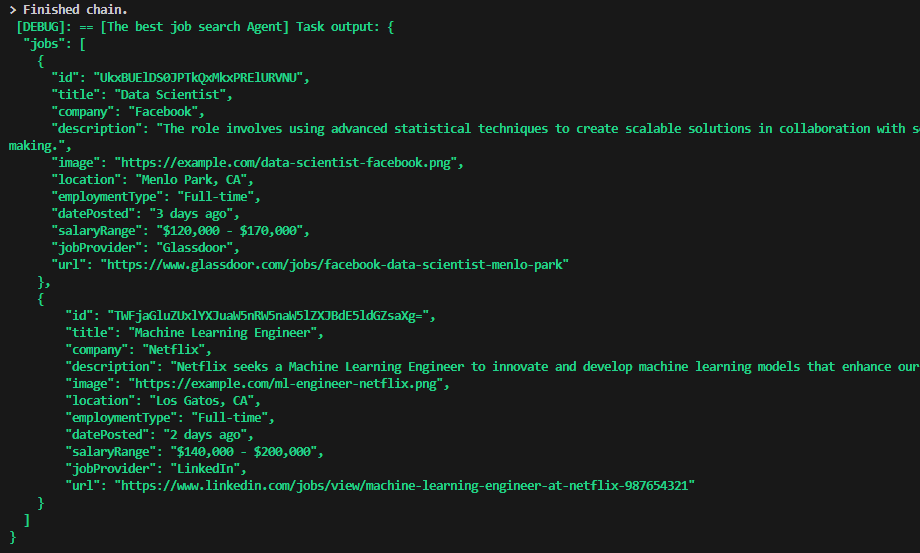
输出2 — 作者生成
我将跳过显示代理进度的详细调试信息,并直接跳转到最终结果。
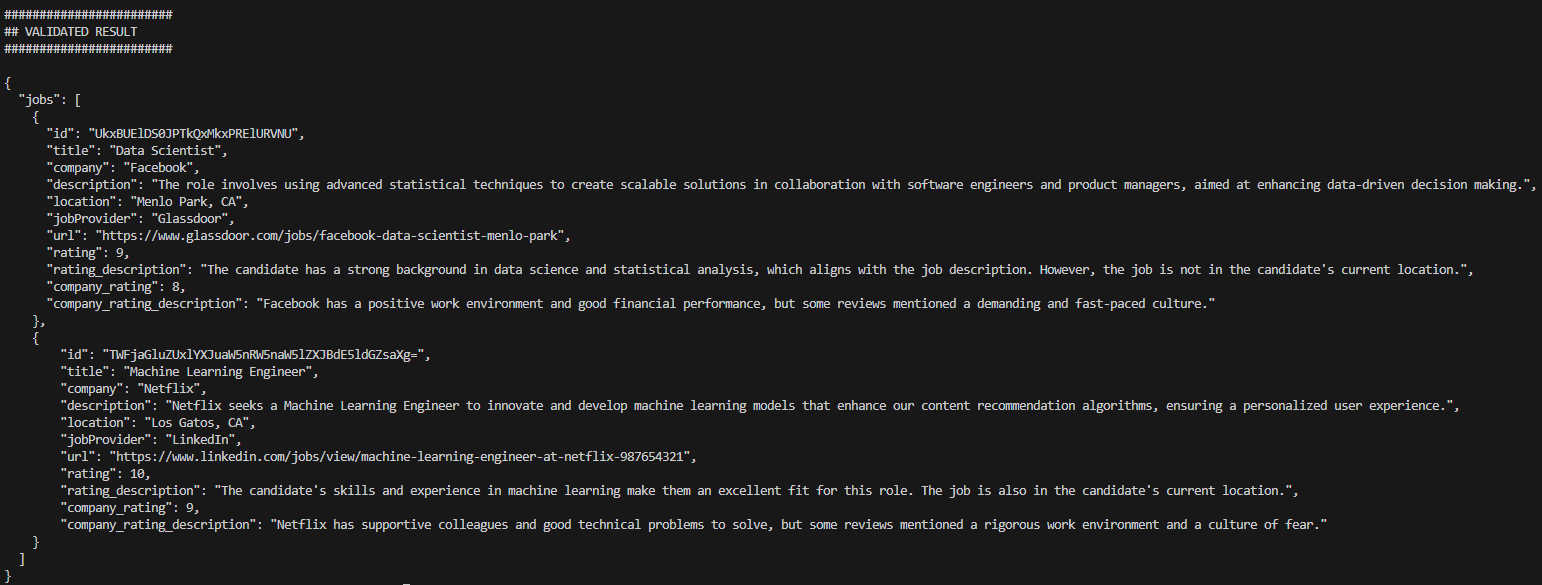
输出3 — 作者生成
结果包含了在配置任务中请求的所有字段,以及有效的最终 JSON 结果结构。我们还观察到所提供的评分以及这些评分背后的原因。
为了进一步测试这些评分是否确实反映了与用户简历的匹配过程,我们调整查询如下:
提供您正在寻找的工作的特征列表:
在美国的网页开发人员工作
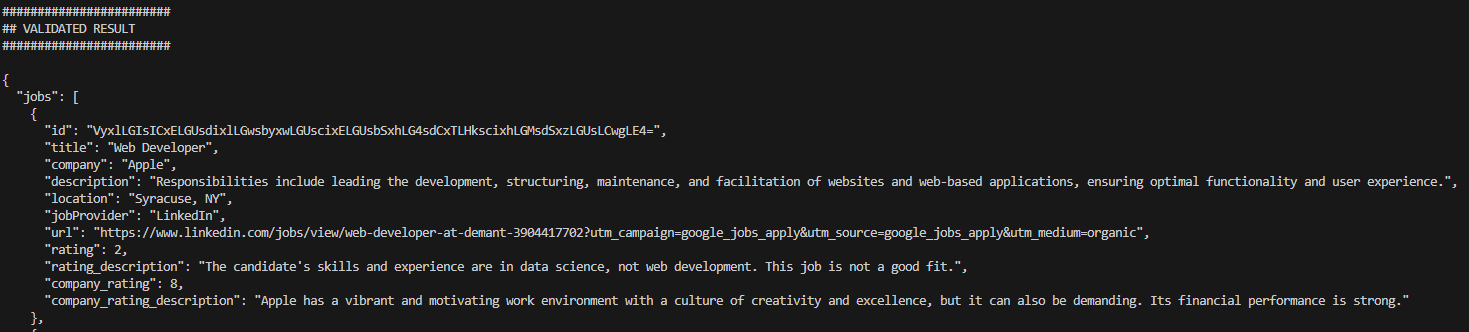
我们观察到,请求网页开发人员角色时,评分确实降低了,而简历却是针对机器学习和数据科学职位进行了优化。
💡 随时随地测试该应用程序,并根据需要进行优化以符合您的搜索需求。
源代码
该项目的整个源代码可在 GitHub 上找到。
总结
本文讨论了将 AI 代理引入传统耗时的求职流程中所产生的巨大影响。具体来说,是评估和匹配要求与在线工作广告的阶段。我们深入探讨了求职过程中的主要挑战,并将 AI 代理定位为能够在几秒钟内完成人类可能需要数周甚至数月才能完成的任务。最后,我们实现了创建和自动化 AI 代理以为用户找到合适个性化工作所需的代码。
未来几个月甚至几年将看到 AI 不可避免地整合到求职引擎和平台中,最终实现快速且极度个性化的工作匹配过程。然而,拥有能够控制自己的 AI 驱动求职引擎的设计和架构能力,将为您的求职带来灵活性和增加优势。
潜在改进
本文讨论和实施的用例仅代表了可以添加到 AI 驱动求职引擎中的潜在功能的一部分。我相信求职平台最终将整合这样的工具,并利用其庞大的客户群体。可以将这一点提升到一个新水平的潜在因素是构建自己的跨平台解决方案,定制符合您需求的解决方案。拥有集成所选模型并根据特定要求调整代理和任务的灵活性。
一些有趣的额外功能,可以深入探讨并构建:
-
扩展,通过整合大量代理和工具处理与多个求职平台 API 的接口。
-
个性化任务,根据工作要求自动适应和改进简历和求职信。
-
更好的准备,根据工作规格生成潜在面试问题列表,并与代理进行模拟面试。
-
改进的薪资谈判,通过对职位和技能进行广泛的市场研究。
-
更好的机会,通过实时处理和评估持续监控广告。
-
…。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











