







REFORCE:一种具备自我完善、格式限制和列探索功能的文本转SQL代理
论文:https://arxiv.org/abs/2502.00675
摘要
文本转SQL系统通过支持对结构化数据库进行自然语言查询,使人们能够更轻松地获取关键数据洞察。然而,由于大型复杂模式( > 3000 > {3000} >3000 列)、多样的SQL方言(如BigQuery、Snowflake)和复杂的查询需求(如转换、分析)等因素,在企业环境中部署此类系统仍具有挑战性。在模拟这种复杂环境而构建的基准数据集Spider 2.0上,当前的最优性能仅为 20 % {20}\% 20% 。主要限制包括指令遵循能力不足、长上下文理解能力差、自我优化能力弱以及特定方言知识不足。为了弥补这些差距,我们提出了ReFoRCE(具有格式限制和列探索功能的自我优化代理),它引入了(1)表压缩以缓解长上下文限制;(2)格式限制以确保答案格式准确;(3)迭代列探索以增强对模式的理解。此外,它采用了自我优化流程,包括(1)带有投票机制的并行工作流;(2)基于公共表表达式(CTE)的优化方法来处理未解决的情况。ReFoRCE取得了最优结果,在Spider 2.0 - Snow任务中得分26.69,在Spider 2.0 - Lite任务中得分24.50。
1 引言
文本转SQL(Text-to-SQL)技术将自然语言查询转换为SQL查询,是降低访问关系型数据库门槛的关键技术(泽勒和穆尼(Zelle & Mooney),1996年;泽特尔莫耶尔和柯林斯(Zettlemoyer & Collins),2012年;钟等人(Zhong et al.),2017年;余等人(Yu et al.),2018年;王等人(Wang et al.),2019年;高等人(Gao et al.),2023a;雷等人(Lei et al.),2024年)。这项技术为数据库提供了自然语言接口,支持商业智能和自动化流程等关键应用。文本转SQL减少了重复性的人工劳动,减轻了数据分析师和程序员的负担。
以往的文本到SQL(Text-to-SQL)研究主要集中在对较简单的数据集(如Spider 1.0数据集(于等人,2018年))进行模型训练和微调(钟等人,2017年;王等人,2019年;肖拉克等人,2021年)。由于大语言模型(LLM)具备强大的代码生成能力(人类公司,2023年;罗齐尔等人,2023年;阿奇姆等人,2023年),大语言模型的兴起已将这一范式从“预训练和微调”转变为提示学习。因此,目前众多文本到SQL的方法都依赖于使用强大的大语言模型应用程序编程接口(API)服务进行提示学习(张等人,2023年;高等人,2023a;普尔雷扎和拉菲伊,2024年;塔莱伊等人,2024年)。
这些方法在经典基准测试中取得了令人瞩目的成绩,例如,在Spider 1.0数据集(Yu等人,2018年)上的准确率超过90%,在BIRD数据集(Li等人,2024b)上达到70%。然而,这些数据集通常基于非工业数据库构建,这些数据库的表和列数量较少,SQL查询简单,问题也很直接。这些局限性无法反映现实世界任务的复杂性。因此,现有方法在新提出的Spider 2.0数据集(Lei等人,2024年)上遇到了困难,该数据集模拟了现实世界的挑战,需要处理多种SQL方言、不同的语法和函数、嵌套列、外部知识,以及具备处理模糊请求和列名的能力。
现实文本到SQL(Text-to-SQL)问题的这种复杂性需要能够让大语言模型(LLMs)与环境(即数据库)进行动态交互的智能体方法。这些方法利用工具、执行命令、观察反馈并规划行动,超越了简单的提示方式,能够处理更复杂的任务,如规划(王等人,2023年;辛等人,2024年)、推理(魏等人,2022年;贝斯塔等人,2024年;邵等人,2024年)和高级代码生成(陈等人,2023年;2024年;杨等人,2024年)。因此,雷等人(2024年)引入了Spider - 智能体(Spider - Agent),这是一个基于反应范式(ReAct,姚等人,2023年)的框架,该框架结合了推理和行动组件,以应对并克服Spider 2.0数据集带来的挑战。
然而,代码智能体在维持控制方面常常面临挑战,尤其是在长上下文场景中,它们可能会不遵循指令或忽略关键任务细节。在未指定值类型或SQL方言的情况下向大语言模型(LLM)提供完整的数据库信息,往往会导致反复迭代以修复语法错误、纠正数据类型或选择正确的函数,从而使有意义的推理空间受限。此外,现有的文本转SQL方法难以应对Spider 2.0数据集中的多方言、嵌套列和复杂数据类型等挑战。
为了解决这些问题,我们提出了ReFoRCE(具有格式限制和列探索功能的自优化代理),它通过将过程分解为可管理的子任务来简化流程,以便更好地进行控制。如图1所示,我们使用表信息压缩来缓解大型数据库中的长上下文问题,这是当前文本到SQL方法的一个常见限制。我们引入答案格式限制,以增强对指令的遵循并确保响应准确。此外,我们进行列探索,以迭代方式执行SQL查询,从简单到复杂逐步推进,从而理解SQL方言、数据类型和嵌套列。最后,我们实施自优化工作流程来纠正答案,并应用自一致性来提高输出结果的可信度。为了进一步提高可靠性,我们通过在多个线程中同时运行整个工作流程来实现并行化,并采用投票机制来确定最可能正确的结果。由于数据集的挑战性以及我们严格的一致性机制,有时执行生成的SQL查询不会返回任何行。对于这些情况,我们采用基于公共表表达式(CTE,Common Table Expression)的自优化方法。CTE是一种可在SQL查询中使用的临时结果集。我们解析代理生成的SQL语句并提取CTE语句进行执行。通过这种方式,我们让代理能够检查中间CTE结果,并逐步找到解决方案。
我们在Spider 2.0(雷等人,2024年)的两个任务上评估了我们的方法:Spider 2.0-Snow和Spider 2.0-Lite。Spider 2.0-Snow统一使用Snowflake SQL,而Spider 2.0-Lite还包含了BigQuery和SQLite的示例。ReFoRCE只需对提示进行最小的修改就能支持多种方言,使其在各种数据库系统中都具有通用性。我们的ReFoRCE代理取得了最先进的成果,在Spider 2.0-Snow上得分为26.69,在Spider 2.0-Lite上得分为24.50,超过了Spider-Agent约20分的成绩。这证明了我们的方法在处理Spider 2.0中的多种方言、嵌套列和复杂数据类型方面的有效性。
2 相关工作
2.1 文本到SQL的方法
近期的文本到SQL(Text-to-SQL)方法主要涉及微调(fine-tuning)和大语言模型提示(LLM-prompting)技术。微调方法(王等人,2019年;肖拉克等人,2021年;李等人,2023年;2024a)专注于通过捕捉模式表示、查询格式和逻辑关系来优化基准测试的模型。相比之下,大语言模型提示(张等人,2023年;高等人,2023a;波雷扎和拉菲伊,2024年;塔莱伊等人,2024年)利用精心设计的提示,通常在少样本或零样本设置下,消除了针对特定任务进行微调的需求。虽然这些方法在像Spider 1.0(于等人,2018年)和BIRD(李等人,2024b)这样较简单的数据集上表现出色,但由于在数据库理解、歧义消除和SQL方言处理方面存在挑战,它们在处理像Spider 2.0(雷等人,2024年)这样的复杂基准测试时遇到困难。具体而言,模式链接、SQL生成和迭代优化是文本到SQL的核心任务。语义匹配(科蒂亚里等人,2023年)、上下文示例(高等人,2023b)、子查询分解(波雷扎和拉菲伊,2024年)和带记忆的自我优化(辛等人,2024年)等技术推动了SQL生成的发展。校准技术,如使用大语言模型的对数概率(拉马钱德兰和萨拉瓦吉,2024年)或直接的是/否验证(田等人,2023年),进一步增强了对SQL正确性的信心,这表明文本到SQL方法正日益复杂精细。
2.2 编码智能体
编码智能体使大语言模型(LLM)能够通过使用工具、执行命令、观察反馈和规划行动,与环境进行动态交互。早期的框架,如ReAct(姚等人,2023年)引入了推理和行动组件,而自我调试(陈等人,2023年)和InterCode(杨等人,2024年)则展示了通过调试和轻量级强化学习进行迭代式问题解决的方法。规划与解决提示法(王等人,2023年)以及像Coder(陈等人,2024年)和Reflexion(辛等人,2024年)这样的多智能体系统,进一步增强了任务分解和迭代改进的能力。专门的框架,如Spider智能体(雷等人,2024年),解决了特定领域的挑战,如SQL查询生成。然而,编码智能体在专门任务中往往面临局限性,在这些任务中,特定领域的解决方案可能比通用框架表现更优(夏等人,2024年)。
另一类智能体研究聚焦于结构化的预定义工作流,这些工作流引导大语言模型(LLM)和工具在特定任务中实现更可靠的性能。源于思维链(Chain-of-Thought,Wei等人,2022年)和自一致性(Self-Consistency,Wang等人,2022年)等概念,工作流随着诸如流程(Flows,Josifoski等人,2023年)、自动生成(AutoGen,Wu等人,2023年)和流程思维(FlowMind,Zeng等人,2023年)等技术的进步而不断发展,实现了模块化、协作式和自动化的工作流程。在代码生成方面,像元生成预训练模型(MetaGPT,Hong等人,2023年)和阿尔法代码(AlphaCodium,Ridnik等人,2024年)这样的框架已经展示了结构化工作流在编码任务中的实用性。虽然现有的编码智能体和工作流解决了迭代优化和模块化问题求解,但ReFoRCE独特地将表格压缩、格式限制和迭代列探索作为应对企业级SQL挑战的新手段。
3 方法
3.1 预备知识
Spider 2.0(雷等人,2024年)是一个综合性代码代理任务。给定一个问题 Q \mathcal{Q} Q 、一个数据库接口 I \mathcal{I} I 和一个代码库 C \mathcal{C} C (包括上下文、配置和文档,如图1所示),其目标是根据观察结果 O k = execute ( C , I , Q ) {\mathcal{O}}_{k} = \operatorname{execute}\left( {\mathcal{C},\mathcal{I},\mathcal{Q}}\right) Ok=execute(C,I,Q) 迭代修改代码(SQL/ Python) C \mathcal{C} C ,直到获得最终结果 A \mathcal{A} A (文本/表格/数据库)。最终观察结果 O k {\mathcal{O}}_{k} Ok 作为代理对问题的回答,即 A = O k \mathcal{A} = {\mathcal{O}}_{k} A=Ok 。相比之下,Spider 2.0 - snow和Spider 2.0 - lite是独立的文本转SQL任务。给定一个数据库模式 D \mathcal{D} D 、一个自然语言问题 Q \mathcal{Q} Q 和辅助文档 E \mathcal{E} E ,文本转SQL解析器 f ( ⋅ ) f\left( \cdot \right) f(⋅) 会生成SQL查询 S = f ( Q , D , E ∣ θ ) \mathcal{S} = f\left( {\mathcal{Q},\mathcal{D},\mathcal{E} \mid \theta }\right) S=f(Q,D,E∣θ) ,其中 θ \theta θ 表示解析器的参数。
雷(Lei)等人(2024年)引入了Spider-Agent,这是一个基于ReAct(姚(Yao)等人,2023年)范式构建的框架,具备函数调用能力,如用于执行SQL查询的EXEC_SQL和用于执行命令行操作以导航DBT(数据构建工具,Data Build Tool)项目并读取模式相关文件的TERMINAL。该智能体通过接收观察信息来运行,这些观察信息代表环境的当前状态或智能体发起的函数调用的结果。基于这些观察信息,智能体生成一个“思考”,并从预定义的函数调用列表中选择一个合适的“行动”。当智能体调用TERMINATE函数时,任务即被视为完成。
3.2 REFORCE:具有格式限制和列探索功能的自我优化智能体
由于ReAct智能体具有高度的自由度,其工作流程缺乏必要的可靠性和可预测性。为解决这一问题,我们提出了ReFoRCE(具有格式限制和列探索功能的自优化智能体,Self-Refinement Agent with Format Restriction and Column Exploration),它通过将流程划分为可管理的子任务来简化流程,从而实现更有效的控制。ReFoRCE采用了一种自优化工作流程,该流程结合了格式限制和列探索功能,以识别具有挑战性的示例。我们实施了一个自优化工作流程来纠正答案,并应用自一致性来增强对输出结果的信心,如图1所示。为进一步提高可靠性,我们通过在多个线程中同时运行整个工作流程来实现并行化,并采用投票机制来确定最可能正确的结果。由于数据集本身具有挑战性,再加上我们采用了严格的一致性机制,有时执行生成的SQL查询不会返回任何行。对于这些示例,我们采用了一种基于公共表表达式(CTE,Common Table Expression)的自优化方法。CTE是一种临时结果集,可用于SQL查询。我们解析智能体生成的SQL语句并提取CTE语句进行执行。通过这种方式,我们让智能体能够检查中间CTE结果,并逐步找到解决方案。值得注意的是,这些技术在各种数据库系统上的工作方式相似,因此,支持一种新类型的数据库所需的工作量仅相当于添加几条提示信息。
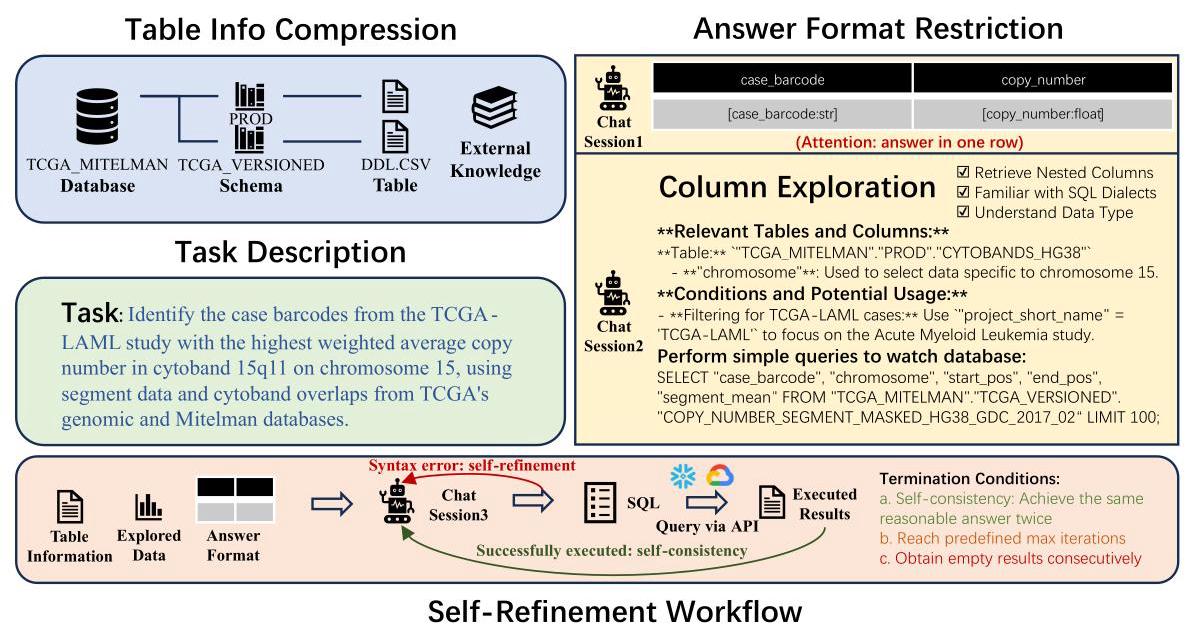
图1:我们的带有格式限制和列探索的自精炼代理(ReFoRCE)工作流程概述。
3.2.1 表格信息压缩
遵循Spider 2.0 - Snow(雷等人,2024年)的方法,我们为每个示例创建一个字典,使用数据库定义语言(DDL)文件整合外部知识和表格结构。在一些特定示例中,DDL文件超过了 300 K B {300}\mathrm{\;{KB}} 300KB ,超出了像ChatGPT这样的模型的上下文限制。为了解决这个问题,我们应用基于模式的匹配方法,将具有相似前缀或后缀的表格合并。对于这些表格,我们仅保留一个代表性的DDL文件作为输入,而对于其他表格,我们仅向模型提供表格名称。
给定数据库信息 D \mathcal{D} D 和辅助文档 E \mathcal{E} E ,我们应用压缩函数对其进行压缩,并将结果与问题 Q \mathcal{Q} Q 拼接,作为初始输入提示 P init {\mathcal{P}}_{\text{init }} Pinit : P init = compress ( D ) + E + Q . (1) {\mathcal{P}}_{\text{init }} = \operatorname{compress}\left( \mathcal{D}\right) + \mathcal{E} + \mathcal{Q}. \tag{1} Pinit =compress(D)+E+Q.(1) 例如,在GA360数据库中,有一年的数据,表名范围从GA_SESSIONS_20160801到GA_SESSIONS_20170801。每个表的DDL文件占用超过 150 K B {150}\mathrm{\;{KB}} 150KB ,导致总长度超过 50 M B {50}\mathrm{{MB}} 50MB ——这对于大语言模型(LLMs)来说是一个难以处理的超大尺寸。我们基于模式的压缩方法显著减小了此类数据库的DDL文件大小。
3.2.2 预期答案格式限制
现实中的文本转SQL(Text-to-SQL)问题常常面临与长上下文问题相关的挑战。当上下文超过 100 k {100}\mathrm{k} 100k 个标记时,模型可能会丢失关键信息,例如详细的任务描述。在任务描述清晰明确的情况下,确定预期的答案格式(例如列名、数据类型和行数)通常很简单。然而,当被过多信息淹没时,大语言模型(LLMs)往往难以准确遵循指令。即使使用旨在引导或纠正输出的提示,大语言模型也可能继续生成错误答案,并且无法纠正其回复。
为解决这一问题,我们提出预期答案格式限制(Expected Answer Format Restriction),即首先生成预期格式,并在自我优化过程中持续强化该格式。回复必须严格遵循以逗号分隔值(CSV)风格指定的格式,确保与执行的CSV文件一致。每列都应明确定义,包含所有必要的属性,每条记录应独占一行。该格式应考虑特定情况,如最高级、百分比或坐标,确保输出简洁、清晰且无歧义。对于有歧义的术语,可以添加可能的值或额外的列以保持清晰和精确。图1展示了一个格式限制的示例。例如,当问题要求给出最高数字时,答案应呈现在一行中。可以在格式表中添加“答案写在一行”等注释以确保清晰。此外,在Spider 2.0评估设置(雷等人,2024年)中,允许包含额外的列。例如,即使任务只要求提供条形码,我们的格式中也包含“拷贝数”列,这与任务高度相关。这种方法即使在处理长上下文和复杂任务描述时,也能确保一致性和准确性。
对于大语言模型(LLM)聊天会话 L session {\mathcal{L}}_{\text{session }} Lsession ,我们输入初始提示以及格式提示 P format {\mathcal{P}}_{\text{format }} Pformat 来生成预期的答案格式 F \mathcal{F} F : F = L session ( P init , P format ) . (2) \mathcal{F} = {\mathcal{L}}_{\text{session }}\left( {{\mathcal{P}}_{\text{init }},{\mathcal{P}}_{\text{format }}}\right) . \tag{2} F=Lsession (Pinit ,Pformat ).(2) #### 3.2.3 对潜在有用列的探索
当直接向大语言模型(LLM)提供整个数据库信息时,由于缺少关于值类型和SQL方言的详细信息,常常需要反复迭代来修正语法错误、纠正数据类型或调用正确的函数。这一过程不仅耗时,而且几乎没有真正推理的空间。对于Spider 2.0-Lite中的DAIL-SQL(高等人,2023a)和DIN-SQL(波雷扎和拉菲伊,2024)等基线模型,Lite数据集提供的样本行通常用于帮助模型理解表的结构。然而,对于嵌套列,即使是几行数据也可能过长,无法输入到LLM中。此外,样本行中的特定值往往缺乏多样性且存在偏差,这可能会误导模型根据这些有限的样本生成错误的答案。
为应对这些挑战并确保全面理解数据库结构,我们设计了一种系统的方法来探索潜在有用的列。该过程首先在旨在提取有意义信息的提示引导下,识别相关的表和列。动态生成的SQL查询从简单的非嵌套格式逐步发展到更复杂的格式,从而能够逐步理解数据库并得出正确答案。这些查询遵循“SELECT DISTINCT “COLUMN_NAME” FROM DATABASE . SCHEMA . TABLE WHERE …”的结构(特定于Snowflake方言),并遵循诸如避免使用公共表表达式(CTEs)和模式级检查等约束条件,同时将每个查询的输出限制为100行或 5 K B 5\mathrm{{KB}} 5KB 。对于JSON或嵌套格式的列,会使用诸如LATERAL FLATTEN之类的技术来显式处理,以提取嵌套值。此外,字符串匹配查询使用模糊模式(例如,%目标字符串%)来提高灵活性。
在这里,我们采用额外的大语言模型(LLM)聊天会话 L session ′ {\mathcal{L}}_{\text{session }}^{\prime } Lsession ′ ,其输入由 P init {\mathcal{P}}_{\text{init }} Pinit 以及列探索提示 P exploration {\mathcal{P}}_{\text{exploration }} Pexploration 组成。这会生成探索内容,包括相关的表和列 P column {\mathcal{P}}_{\text{column }} Pcolumn 以及用于与数据库交互的 SQL 查询 S exploration {\mathcal{S}}_{\text{exploration }} Sexploration 。然后调用数据库应用程序编程接口(API)来执行 SQL 查询并检索结果 R exploration {\mathcal{R}}_{\text{exploration }} Rexploration : P column , S exploration ′ = L session ′ ( P init , P exploration ) , (3) {\mathcal{P}}_{\text{column }},{\mathcal{S}}_{\text{exploration }}^{\prime } = {\mathcal{L}}_{\text{session }}^{\prime }\left( {{\mathcal{P}}_{\text{init }},{\mathcal{P}}_{\text{exploration }}}\right) , \tag{3} Pcolumn ,Sexploration ′=Lsession ′(Pinit ,Pexploration ),(3) R exploration = API ( S exploration ) . (4) {\mathcal{R}}_{\text{exploration }} = \operatorname{API}\left( {\mathcal{S}}_{\text{exploration }}\right) . \tag{4} Rexploration =API(Sexploration ).(4) 在此阶段,大语言模型(LLM)会同时生成 10 多个 SQL 查询,因此准确执行每个查询对于有效探索至关重要。然而,如果一个 SQL 查询包含错误,后续查询可能也会出现类似问题。为了解决这个问题,我们提出了算法 1,它提供了一种结构化的方法来执行 SQL 查询,同时通过自我修正动态解决错误。
3.2.4 问题解决的自我优化工作流程
执行反馈下的自我优化在获取表格信息 P init {\mathcal{P}}_{\text{init }} Pinit 、探索数值数据 P column + R exploration {\mathcal{P}}_{\text{column }} + {\mathcal{R}}_{\text{exploration }} Pcolumn +Rexploration 并定义预期答案格式 F \mathcal{F} F 后,我们将这些元素输入模型并采用自我优化过程。这一过程使模型能够纠正错误、改进答案,并通过自我一致性获得具有高置信度的结果 R final {\mathcal{R}}_{\text{final }} Rfinal 。(5)
— R final = self-refinement ( P init , P column + R exploration , F ) . {\mathcal{R}}_{\text{final }} = \text{ self-refinement }\left( {{\mathcal{P}}_{\text{init }},{\mathcal{P}}_{\text{column }} + {\mathcal{R}}_{\text{exploration }},\mathcal{F}}\right) . Rfinal = self-refinement (Pinit ,Pcolumn +Rexploration ,F). —
自优化工作流程的详细信息见算法2。从净化后的信息开始,它会生成SQL查询并通过应用程序编程接口(API)执行这些查询,根据返回的结果评估其正确性和合理性。对识别出的错误进行迭代优化以提高准确性。优化过程由终止条件控制,包括达到自一致性,即两次获得相同的合理答案。空结果或仅包含空字符串或零的列被视为不正确,并在一致性检查中排除。如果达到预定义的最大迭代次数,工作流程也会停止,因为这可能表明模型生成的答案置信度较低,这些答案将被视为空值。此外,连续的空结果表明不再进行进一步的优化。这种保守策略优先考虑非空答案的高置信度,即使会保留大量的空结果,以确保输出的稳健性和可靠性。
基于公共表表达式(CTE)的优化 此外,如果自优化工作流程未能生成SQL,我们会进一步尝试使用公共表表达式(CTE)构建逐步的数据流。公共表表达式是中间表,有助于将复杂查询分解为多个较简单的查询。我们明确提示智能体将SQL生成为一组有意义的公共表表达式的组合。
在智能体生成一条SQL语句后,我们对其进行解析以获取各个公共表表达式(CTE),并在每个CTE结束时获取执行结果。要求智能体单独验证每个执行结果。如果某个结果不符合预期,智能体可以选择重写当前的CTE。这种流程使智能体能够定位错误。这也为智能体提供了一种单独检查每个CTE逻辑的方法,并有助于探索其他列。
3.2.5 并行化
尽管有自一致性机制,但由于列探索的视角不同,同一示例在多次运行中可能会出现结果差异。为了增强对结果的信心,我们采用并行化方法,通过启动多个线程同时执行整个工作流程。首先通过编程方式比较结果,使用投票机制来确定最可能正确的结果。如果仅靠投票无法解决差异,模型会进一步评估结果以确定最准确的答案。这种方法考虑了不同的视角和多次迭代,有助于收敛到更高质量的结果。
使用相同的格式 F \mathcal{F} F 和数据库信息 P init {\mathcal{P}}_{\text{init }} Pinit ,我们启动多个线程(在我们的实验中设置为 3 个)以并行且独立地执行整个过程: R parallel = ⋃ Parallel { P column , S exploration = L session ′ ( P init , P exploration ) , R exploration = API ( S exploration , ) R final = self-r e if i rement ( P init , P column + R exploration , F ) , } . (6) {\mathcal{R}}_{\text{parallel }} = \bigcup \operatorname{Parallel}\left\{ \begin{array}{l} {\mathcal{P}}_{\text{column }},{\mathcal{S}}_{\text{exploration }} = {\mathcal{L}}_{\text{session }}^{\prime }\left( {{\mathcal{P}}_{\text{init }},{\mathcal{P}}_{\text{exploration }}}\right) , \\ {\mathcal{R}}_{\text{exploration }} = \operatorname{API}\left( {{\mathcal{S}}_{\text{exploration }},}\right) \\ {\mathcal{R}}_{\text{final }} = \operatorname{self-r}e\text{ if }i\text{ rement }\left( {{\mathcal{P}}_{\text{init }},{\mathcal{P}}_{\text{column }} + {\mathcal{R}}_{\text{exploration }},\mathcal{F}}\right) , \end{array}\right\} . \tag{6} Rparallel =⋃Parallel⎩ ⎨ ⎧Pcolumn ,Sexploration =Lsession ′(Pinit ,Pexploration ),Rexploration =API(Sexploration ,)Rfinal =self-re if i rement (Pinit ,Pcolumn +Rexploration ,F),⎭ ⎬ ⎫.(6) 最后,通过投票机制对并行执行的结果进行汇总:
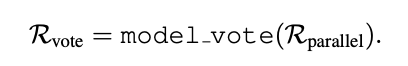
此外,由于每个示例都是独立的,并且模型和数据库应用程序编程接口(API)都支持并行执行,我们还实现了不同示例之间的并行化。这种策略在确保可靠且一致性能的同时,显著加快了整个过程。
4 实验
4.1 实验设置
数据集 我们使用Spider 2.0数据集(雷等人,2024年)评估我们的方法,该数据集包括两个子集:Spider 2.0-Snow和Spider 2.0-Lite。两个子集均包含547个示例,涵盖了150多个数据库,每个数据库平均有800列。每个SQL查询大约包含150个标记,这使得该任务特别具有挑战性。两个子集之间的关键区别在于它们的SQL方言:Spider 2.0-Snow仅专注于Snowflake方言,而Spider 2.0-Lite支持BigQuery、Snowflake和SQLite方言。
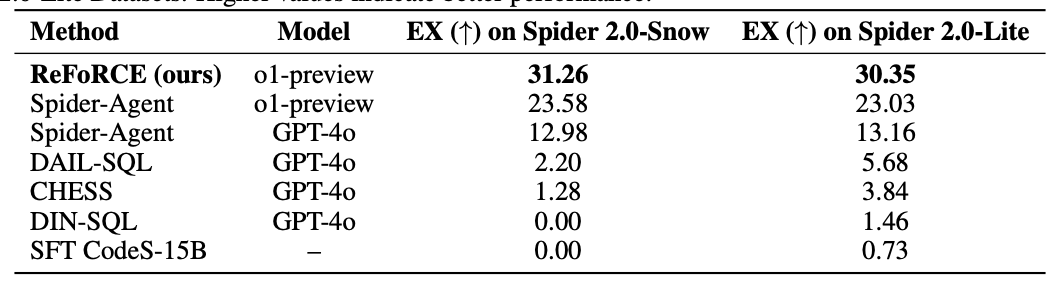
表1:在Spider 2.0-Snow和Spider 2.0-Lite数据集上执行准确率(EX)的方法比较。数值越高表示性能越好。
评估指标 我们使用广泛采用的指标——执行准确率(EX)来评估性能(Yu等人,2018年;Li等人,2024b)。对于某些示例,模糊的问题可能不会明确指定要返回哪些列。评估脚本旨在关注答案的关键部分,忽略不相关的列,专注于指令中列出的核心元素。因此,包含额外的列被认为是可以接受的。
大语言模型 我们使用GPT系列模型进行实验,具体为GPT - 4o(Achiam等人,2023年)和o1 - 预览版(OpenAI,2024年)。GPT - 4o用于测试一些基线,而o1 - 预览版用于我们的方法和Spider - 代理。我们选择o1 - 预览版而非正式的o1版本,是因为o1 - 预览版在这个特定任务上能取得更好的结果。
基线 我们针对Spider 2.0-Snow和Spider 2.0-Lite数据集采用了最先进的代码代理框架Spider-Agent(雷等人,2024年)。此外,我们还使用了广泛认可的提示方法,如DAIL-SQL(高等人,2023a)、DIN-SQL(波雷扎和拉菲伊,2024年)和SFT CodeS(李等人,2024a)。
4.2 评估结果
表1中的结果凸显了我们的方法在Spider 2.0-Snow和Spider 2.0-Lite数据集上的卓越性能。使用o1-preview模型,我们的方法在Spider 2.0-Snow上的执行准确率(EX)得分为26.69,在Spider 2.0-Lite上为24.50,显著优于所有其他方法。
这些结果证明了我们的方法在应对数据集带来的挑战方面的稳健性。在Spider 2.0 - Snow数据集上,我们的方法在有效处理嵌套列和复杂数据类型方面表现出色。在涵盖多种方言(包括Snowflake、SQLite和BigQuery)的Spider 2.0 - Lite数据集上,我们的方法展现出了卓越的适应性和一致性。在Spider 2.0 - Lite数据集上结果略低,这是因为我们的提示主要是为Snowflake方言设计的,因此在处理BigQuery方言中的某些情况时偶尔会出错。
与Spider - Agent相比,后者在两个数据集上使用相同的 ∘ 1 \circ 1 ∘1 - 预览模型的得分约为20分,我们的方法取得了更高的分数,凸显了其在文本到SQL(Text - to - SQL)任务中解决复杂案例的卓越能力。此外,使用GPT - 4 ⊙ \odot ⊙ 的方法,包括Spider - Agent、DAIL - SQL和CHESS,表现不佳,得分在0.00到5.68之间。这强调了我们专门方法的重要性,该方法是专门为应对跨不同SQL方言的文本到SQL任务的复杂性而设计的。
总之,这些结果有力地证明了我们的方法在处理文本到SQL(Text-to-SQL)任务的挑战方面达到了当前最优水平,特别是在涉及多种方言、嵌套列和高级数据类型的复杂场景中。这一成果表明,我们的方法在提升文本到SQL解析的执行准确性方面卓有成效。
5 结论
在本文中,我们提出了ReFoRCE,这是一个用于应对现实世界文本到SQL任务挑战的自优化框架,以Spider 2.0数据集为例。通过引入表信息压缩、格式限制、迭代列探索和基于公共表表达式(CTE)的优化等技术,ReFoRCE能够有效处理多种SQL方言、嵌套列和复杂数据类型。我们的方法取得了当前最优性能,在Spider 2.0-Snow上的得分达到26.69,在Spider 2.0-Lite上的得分达到24.50,显著优于之前由Spider-Agent创造的最佳结果。这些发现凸显了ReFoRCE在应对现实世界复杂性方面的鲁棒性和可靠性。
尽管ReFoRCE表现出色,但它仍存在一些局限性。表格信息的有损压缩限制了其处理非常大的表格上下文的能力,并且当前简单的探索策略在处理模糊列和局部最优问题时面临困难。此外,由于ReFoRCE主要侧重于预处理和自我优化,它在推理能力方面并未带来显著提升,而推理能力对于处理更复杂的查询至关重要。
为解决这些局限性,未来的工作将探索模式链接技术以增强上下文理解,并采用先进的列探索和推理策略,如蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS)和过程奖励模型(Process Reward Model,PRM)或纯强化学习(Reinforcement Learning,RL)(Guo等人,2025年),以更好地处理模糊列并改进优化。通过应对这些挑战,我们旨在提高ReFoRCE在更广泛的文本到SQL任务中的适用性,并为现实世界的数据库交互设定新的基准。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











