






 本文总结了基于字典学习的图像分类方法,包括直接学习具有识别力的字典和使系数具有识别力的方法,如Meta-Face Learning、DLSI、SDL、D-KSVD、LC-KSVD和Fisher判决字典学习。这些方法通过改进重构和分类过程,增强了对光照、遮挡等噪声的鲁棒性,提高了识别准确性。
本文总结了基于字典学习的图像分类方法,包括直接学习具有识别力的字典和使系数具有识别力的方法,如Meta-Face Learning、DLSI、SDL、D-KSVD、LC-KSVD和Fisher判决字典学习。这些方法通过改进重构和分类过程,增强了对光照、遮挡等噪声的鲁棒性,提高了识别准确性。
题目:A Brief Summary of Dictionary Learning Based Approach for Classification
作者:Shu Kong and Donghui Wang
College of Computer Science and Technology, Zhejiang University
时间:May 31, 2012
一、整体介绍
1、最初学习得到的字典进用于信号重构,后来,研究者们采取措施通过研究标签信息以监督学习方式学习用于分类的字典。
2、已经存在的基于DL的分类方法大致分为两类:一类是直接学习具有识别力的字典,另一类是稀疏化稀疏,是字典具有识别力。 第一类主要利用表示误差进行分类判决,第二类主要利用稀疏稀疏作为新的特征进行分类。
SRC基本模型:
1、对x进行编码,对系数加l1范数约束,取最小值。
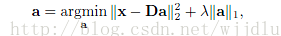
2、对x进行分类判决。
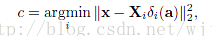
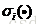
SRC对亮度和遮挡等噪声具有很强的鲁棒性。
传统字典学习框架:
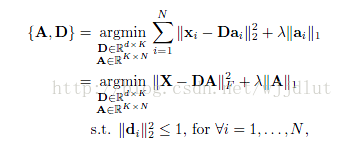
其中,共N个信号。A=[a1,a2,...,aN]是编码系数矩阵。矩阵A的1范数等价于A的各个列向量的1范数之和。
SRC的缺点:
(1)预定字典包含冗余和琐碎的不利于人脸识别的信息;
(2)训练数据增加,稀疏编码的计算量增加。
二、直接学习具有识别力的字典
为解决以上问题:
直接学习具有识别力的字典:
1、Meta-Face Learning
Yang等人的该方法是针对每一个类别学习得到一个自适应的字典。
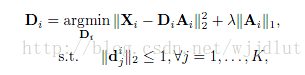
其中矩阵Xi包含第i个类别的所有样本,Di是第i个类别对应的字典。
2、Dictionary Learning with Structured Incoherence(DLSI)
不同类别的子字典的原子具有连贯性,则重构查询图像时的原子是可以互相代替的。这导致无法利用重构误差进行分类判决。为了解决这一问题,Ramirez等人增加了一个不连贯项的约束,使不同类别的子字典之间尽可能互相独立。
不连贯项:
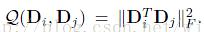
最终的字典学习算法为:
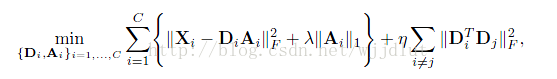
不连贯项的含义是:在重构误差时,忽略与公共原子(在各个类别中表示共同特征的原子)相关的系数的绝对值,一次提高系统的判决能力。
三、使系数具有识别力的方法
该类方法使稀疏系数具有识别力,间接使字典具有识别力。该类方法只需要学习一个整体的字典,不需要每个类别都学习一个相应的字典。
1、监督字典学习(SDL)
Mairal等人提出将逻辑回归与传统字典学习框架相结合。
优化公式为:
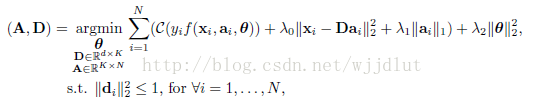
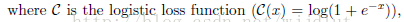
λ2 是防止过拟合的正则项参数。f是与系数a呈线性关系的函数:

或者与a和x成双线性关系的函数:
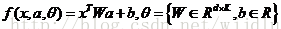
2、用于字典学习的有识别力的K-SVD方法(D-KSVD)
D-KSVD在传统DL框架上加了一个简单的线性回归作为惩罚项。
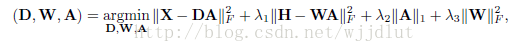
H=[h1,h2,...hN]是训练图像的标签。hn =[0,...0,1,0,...,0],非零元素的位置即为所属的类别。W是分类器的参数。
由上式可知,前两项可以混合为一项,最后一下根据KSVD可以去掉。最终优化得到D和W后,即可迅速对查询图像进行分类。
3、标签一致的KSVD(LC-KSVD)
Jiang等人提出LC-KSVD,提出了一个叫做“有识别力的稀疏编码误差”的标签一致的约束,与重构误差和分类误差结合,如下所示:


具有识别力的稀疏编码误差使得稀疏码A接近有识别力的稀疏编码Q。
4、Fisher 判决字典学习方法
总的优化函数框架:

C(X,D,A):识别精确项。
f(A):强加于A的识别力约束项。
在识别力精确项:我们希望DiAi=Xi,DjAi=0(i不等于j)。
于是:
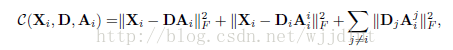
在系数的识别力约束项:使关于样本X的字典D有识别力,可以使编码A有识别力。即使A的类内散度SW小,类间散度SB大。
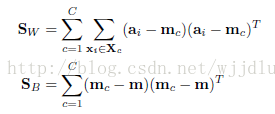
Fisher判决函数为:(tr(SW)-tr(SB)是非凸函数且不稳定,加上一项A的F范数项),如下所示:

所有内容融合之后,得到的FDDL为:

四、总结
字典学习的总体框架:
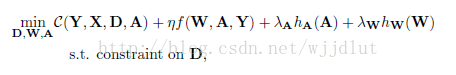















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









