







和你一起终身学习,这里是程序员Android
经典好文推荐,通过阅读本文,您将收获以下知识点:
BufferQueue 类是 Android 中所有图形处理操作的核心。它的作用很简单:将生成图形数据缓冲区的一方(生产方)连接到接受数据以进行显示或进一步处理的一方(消耗方)。几乎所有在系统中移动图形数据缓冲区的内容都依赖于 BufferQueue。
现在,我们添加一个空的drawNativeWindow实现,先将我们的应用跑起来吧。
int drawNativeWindow(sp<WindowSurfaceWrapper> /* windowSurface */) {
return NO_ERROR;
}
int main(int argc, char *argv[]) {
unsigned samples = 0;
printf("usage: %s [samples]\n", argv[0]);
if (argc == 2) {
samples = atoi( argv[1] );
printf("Multisample enabled: GL_SAMPLES = %u\n", samples);
}
sp<ProcessState> proc(ProcessState::self());
ProcessState::self()->startThreadPool();
sp<WindowSurfaceWrapper> windowSurface(new WindowSurfaceWrapper(String8("NativeBinApp")));
drawNativeWindow(windowSurface);
IPCThreadState::self()->joinThreadPool();
return EXIT_SUCCESS;
}Android.bp如下:
cc_binary {
name: "NativeApp",
srcs: [
"NativeApp.cpp",
"WindowSurfaceWrapper.cpp",
],
shared_libs: [
"liblog",
"libbinder",
"libui",
"libgui",
"libutils",
],
init_rc: ["NativeApp.rc"],
}NativeApp.rc文件如下:
service NativeApp /system/bin/NativeApp
class core
oneshot将应用push到系统的bin目录下就可以运行了:
adb push out/target/product/generic/system/bin/NativeApp /vendor/bin/运行应用:
adb shell NativeBin很遗憾的是,我们在手机屏幕上是看不是任何东西的。Why?因为没有画任何东西。但是,我们dump SurfaceFlinger的时候,还是能够看到我们创建的应用窗口的,只是没有内容,SurfaceFlinger不显示,即使去显示,也看不到。
adb shell dumpsys SurfaceFlinger我们创建应用Layer时,名字为“NativeBinApp”,下面就是我们dump出来的Layer的信息:
+ Layer 0x7b3ba66000 (NativeBinApp#0)
Region transparentRegion (this=0x7b3ba66380, count=1)
[ 0, 0, 0, 0]
Region visibleRegion (this=0x7b3ba66010, count=1)
[ 0, 0, 0, 0]
Region surfaceDamageRegion (this=0x7b3ba66088, count=1)
[ 0, 0, 0, 0]
layerStack= 0, z=2147483647, pos=(0,0), size=( 720,1280), crop=( 0, 0, -1, -1), finalCrop=( 0, 0, -1, -1), isOpaque=0, invalidate=0, dataspace=Default (0), pixelformat=Unknown/None alpha=1.000, flags=0x00000002, tr=[1.00, 0.00][0.00, 1.00]
client=0x7b4002d0c0
format= 2, activeBuffer=[ 0x 0: 0, 0], queued-frames=0, mRefreshPending=0
mTexName=7 mCurrentTexture=-1
mCurrentCrop=[0,0,0,0] mCurrentTransform=0
mAbandoned=0
- BufferQueue mMaxAcquiredBufferCount=1 mMaxDequeuedBufferCount=2
mDequeueBufferCannotBlock=0 mAsyncMode=0
default-size=[720x1280] default-format=2 transform-hint=00 frame-counter=0
FIFO(0):
Slots:
[00:0x0] state=FREE
[01:0x0] state=FREE
[02:0x0] state=FREE我们已经创建了窗口,但是界面没有内容显示,我们先完善我们的应用,在窗口中显示点内容吧~
Native应用绘制界面
下面是drawNativeWindow窗口的对应的代码,关键的步骤的用序号标出来了~
int drawNativeWindow(sp<WindowSurfaceWrapper> windowSurface) {
status_t err = NO_ERROR;
ANativeWindowBuffer *aNativeBuffer = nullptr;
sp<SurfaceControl> surfaceControl = windowSurface->getSurfaceControl();
ANativeWindow* aNativeWindow = surfaceControl->getSurface().get();
// 1. We need to reconnect to the ANativeWindow as a CPU client to ensure that no frames
// get dropped by SurfaceFlinger assuming that these are other frames.
err = native_window_api_disconnect(aNativeWindow, NATIVE_WINDOW_API_CPU);
if (err != NO_ERROR) {
ALOGE("ERROR: unable to native_window_api_disconnect ignore...\n");
}
// 2. connect the ANativeWindow as a CPU client
err = native_window_api_connect(aNativeWindow, NATIVE_WINDOW_API_CPU);
if (err != NO_ERROR) {
ALOGE("ERROR: unable to native_window_api_connect\n");
return EXIT_FAILURE;
}
// 3. set the ANativeWindow dimensions
err = native_window_set_buffers_user_dimensions(aNativeWindow, windowSurface->width(), windowSurface->height());
if (err != NO_ERROR) {
ALOGE("ERROR: unable to native_window_set_buffers_user_dimensions\n");
return EXIT_FAILURE;
}
// 4. set the ANativeWindow format
int format = PIXEL_FORMAT_RGBX_8888;
err = native_window_set_buffers_format(aNativeWindow,format );
if (err != NO_ERROR) {
ALOGE("ERROR: unable to native_window_set_buffers_format\n");
return EXIT_FAILURE;
}
// 5. set the ANativeWindow transform
int rotation = 0;
int transform = 0;
if ((rotation % 90) == 0) {
switch ((rotation / 90) & 3) {
case 1: transform = HAL_TRANSFORM_ROT_90; break;
case 2: transform = HAL_TRANSFORM_ROT_180; break;
case 3: transform = HAL_TRANSFORM_ROT_270; break;
default: transform = 0; break;
}
}
err = native_window_set_buffers_transform(aNativeWindow, transform);
if (err != NO_ERROR) {
ALOGE("native_window_set_buffers_transform failed: %s (%d)", strerror(-err), -err);
return err;
}
// 6. handle the ANativeWindow usage
int consumerUsage = 0;
err = aNativeWindow->query(aNativeWindow, NATIVE_WINDOW_CONSUMER_USAGE_BITS, &consumerUsage);
if (err != NO_ERROR) {
ALOGE("failed to get consumer usage bits. ignoring");
err = NO_ERROR;
}
// Make sure to check whether either requested protected buffers.
int usage = GRALLOC_USAGE_SW_WRITE_OFTEN;
if (usage & GRALLOC_USAGE_PROTECTED) {
// Check if the ANativeWindow sends images directly to SurfaceFlinger.
int queuesToNativeWindow = 0;
err = aNativeWindow->query(
aNativeWindow, NATIVE_WINDOW_QUEUES_TO_WINDOW_COMPOSER, &queuesToNativeWindow);
if (err != NO_ERROR) {
ALOGE("error authenticating native window: %s (%d)", strerror(-err), -err);
return err;
}
// Check if the consumer end of the ANativeWindow can handle protected content.
int isConsumerProtected = 0;
err = aNativeWindow->query(
aNativeWindow, NATIVE_WINDOW_CONSUMER_IS_PROTECTED, &isConsumerProtected);
if (err != NO_ERROR) {
ALOGE("error query native window: %s (%d)", strerror(-err), -err);
return err;
}
// Deny queuing into native window if neither condition is satisfied.
if (queuesToNativeWindow != 1 && isConsumerProtected != 1) {
ALOGE("native window cannot handle protected buffers: the consumer should either be "
"a hardware composer or support hardware protection");
return PERMISSION_DENIED;
}
}
// 7. set the ANativeWindow usage
int finalUsage = usage | consumerUsage;
ALOGE("gralloc usage: %#x(producer) + %#x(consumer) = %#x", usage, consumerUsage, finalUsage);
err = native_window_set_usage(aNativeWindow, finalUsage);
if (err != NO_ERROR) {
ALOGE("native_window_set_usage failed: %s (%d)", strerror(-err), -err);
return err;
}
// 8. set the ANativeWindow scale mode
err = native_window_set_scaling_mode(
aNativeWindow, NATIVE_WINDOW_SCALING_MODE_SCALE_TO_WINDOW);
if (err != NO_ERROR) {
ALOGE("native_window_set_scaling_mode failed: %s (%d)", strerror(-err), -err);
return err;
}
ALOGE("set up nativeWindow %p for %dx%d, color %#x, rotation %d, usage %#x",
aNativeWindow, windowSurface->width(), windowSurface->height(), format, rotation, finalUsage);
// 9. set the ANativeWindow permission to allocte new buffer, default is true
static_cast<Surface*>(aNativeWindow)->getIGraphicBufferProducer()->allowAllocation(true);
// 10. set the ANativeWindow buffer count
int numBufs = 0;
int minUndequeuedBufs = 0;
err = aNativeWindow->query(aNativeWindow,
NATIVE_WINDOW_MIN_UNDEQUEUED_BUFFERS, &minUndequeuedBufs);
if (err != NO_ERROR) {
ALOGE("error pushing blank frames: MIN_UNDEQUEUED_BUFFERS query "
"failed: %s (%d)", strerror(-err), -err);
goto handle_error;
}
numBufs = minUndequeuedBufs + 1;
err = native_window_set_buffer_count(aNativeWindow, numBufs);
if (err != NO_ERROR) {
ALOGE("error pushing blank frames: set_buffer_count failed: %s (%d)", strerror(-err), -err);
goto handle_error;
}
// 11. draw the ANativeWindow
for (int i = 0; i < numBufs + 1; i++) {
// 12. dequeue a buffer
int hwcFD= -1;
err = aNativeWindow->dequeueBuffer(aNativeWindow, &aNativeBuffer, &hwcFD);
if (err != NO_ERROR) {
ALOGE("error pushing blank frames: dequeueBuffer failed: %s (%d)",
strerror(-err), -err);
break;
}
// 13. make sure really control the dequeued buffer
sp<Fence> hwcFence(new Fence(hwcFD));
int waitResult = hwcFence->waitForever("dequeueBuffer_EmptyNative");
if (waitResult != OK) {
ALOGE("dequeueBuffer_EmptyNative: Fence::wait returned an error: %d", waitResult);
break;
}
sp<GraphicBuffer> buf(GraphicBuffer::from(aNativeBuffer));
// 14. Fill the buffer with black
uint8_t *img = NULL;
err = buf->lock(GRALLOC_USAGE_SW_WRITE_OFTEN, (void**)(&img));
if (err != NO_ERROR) {
ALOGE("error pushing blank frames: lock failed: %s (%d)", strerror(-err), -err);
break;
}
//15. Draw the window, here we fill the window with black.
*img = 0;
err = buf->unlock();
if (err != NO_ERROR) {
ALOGE("error pushing blank frames: unlock failed: %s (%d)", strerror(-err), -err);
break;
}
// 16. queue the buffer to display
int gpuFD = -1;
err = aNativeWindow->queueBuffer(aNativeWindow, buf->getNativeBuffer(), gpuFD);
if (err != NO_ERROR) {
ALOGE("error pushing blank frames: queueBuffer failed: %s (%d)", strerror(-err), -err);
break;
}
aNativeBuffer = NULL;
}
handle_error:
// 17. cancel buffer
if (aNativeBuffer != NULL) {
aNativeWindow->cancelBuffer(aNativeWindow, aNativeBuffer, -1);
aNativeBuffer = NULL;
}
// 18. Clean up after success or error.
status_t err2 = native_window_api_disconnect(aNativeWindow, NATIVE_WINDOW_API_CPU);
if (err2 != NO_ERROR) {
ALOGE("error pushing blank frames: api_disconnect failed: %s (%d)", strerror(-err2), -err2);
if (err == NO_ERROR) {
err = err2;
}
}
return err;
}关键步骤如下:
- 获取我们已经创建的Layer的窗口ANativeWindow
- 断掉之前的BufferQueue连接native_window_api_disconnect,这一步是可选的
- 连接Window到BufferQueue native_window_api_connect
- 设置Buffer的大小尺寸native_window_set_buffers_user_dimensions,可选
- 设置Buffer格式,可选,之前创建Layer的时候已经设置了。
- 设置Buffer的transform
- 处理Buffer的usage,主要的DRM内容的处理
- 设置Buffer的usage,usage由producer的usage和Consumer的usage组成
- 设置scale模式,如果上层给的数据,比如Video,超出Buffer的大小后,怎么处理,是截取一部分还是,缩小。
- 设置permission,设置Buffer,默认true,可选。
- 设置Buffer数量,就是,BufferQueue中有多少个buffer可以用,可选
- 绘制窗口,窗口有一个buffer队列,对每一个buffer都需要绘制。
- dequeueBuffer先拿到一块可用的Buffer,也就是FREE的Buffer。
- Buffer虽然是Free的,但是在异步模式下,Buffer不可能还在使用中,需要等到Fence才能确保buffer没有在被使用
- 往Free的Buffer里面绘制东西,
- 我们这里直接显示全黑,*img = 0
- 将绘制好的Buffer,queue到Buffer队列中,queueBuffer。
- 错误处理,取消掉Buffer,cancelBuffer
- 断开BufferQueue和窗口的连接,native_window_api_disconnect
OK~再编译执行一下,屏幕是不是黑了?
Dumps一下SurfaceFlinger,我们的应用窗口信息如下:
+ Layer 0x7b3ba61000 (NativeBinApp#0)
Region transparentRegion (this=0x7b3ba61380, count=1)
[ 0, 0, 0, 0]
Region visibleRegion (this=0x7b3ba61010, count=1)
[ 0, 0, 720, 1280]
Region surfaceDamageRegion (this=0x7b3ba61088, count=1)
[ 0, 0, -1, -1]
layerStack= 0, z=2147483647, pos=(0,0), size=( 720,1280), crop=( 0, 0, -1, -1), finalCrop=( 0, 0, -1, -1), isOpaque=1, invalidate=0, dataspace=Default (0), pixelformat=RGBx_8888 alpha=1.000, flags=0x00000002, tr=[1.00, 0.00][0.00, 1.00]
client=0x7b4002d6c0
format= 2, activeBuffer=[ 720x1280: 720, 2], queued-frames=0, mRefreshPending=0
mTexName=2 mCurrentTexture=1
mCurrentCrop=[0,0,0,0] mCurrentTransform=0
mAbandoned=0
- BufferQueue mMaxAcquiredBufferCount=1 mMaxDequeuedBufferCount=1
mDequeueBufferCannotBlock=0 mAsyncMode=0
default-size=[720x1280] default-format=2 transform-hint=00 frame-counter=3
FIFO(0):
Slots:
[01:0x0] state=FREE
[02:0x0] state=FREE对比看一下,和前面的dump信息有什么不一样?
另外,如果我们将原来的*img = 0替换掉,可以绘制其他一些东西。fillWithCheckerboard可以将屏幕填充为小方块。
fillWithCheckerboard(img, windowSurface->width(), windowSurface->height(), buf->getStride());
void fillWithCheckerboard(uint8_t* img, int width, int height, int stride) {
bool change = false;
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
uint8_t* pixel = img + (4 * (y*stride + x));
if ( x % 10 == 0) {
change = !change;
}
if(change) {
pixel[0] = 255;
pixel[1] = 255;
pixel[2] = 255;
} else {
pixel[0] = 0;
pixel[1] = 0;
pixel[2] = 0;
}
pixel[3] = 0;
}
if ( y % 10 == 0) {
change = !change;
}
}
}绘制应用,我们这里直接用的API,这些API是怎么工作的,数据怎么送给显示的?接下里,我们将具体分析。
SurfaceFlinger创建Layer
上一章讲到,应用创建Layer时,流程只跟到SurfaceFlinger,SurfaceFlinger是怎么窗口Layer的,和 Layer和BufferQueue又是怎么关联的,我们接着就来看看。
Layer分两种类型:
- bNormal Layer,普通Layer,由createBufferLayer创建,由BufferLayer类描述。
- Coler Layer,由createColorLayer创建,由ColorLayer类描述。
Layer相关类的关系如下:
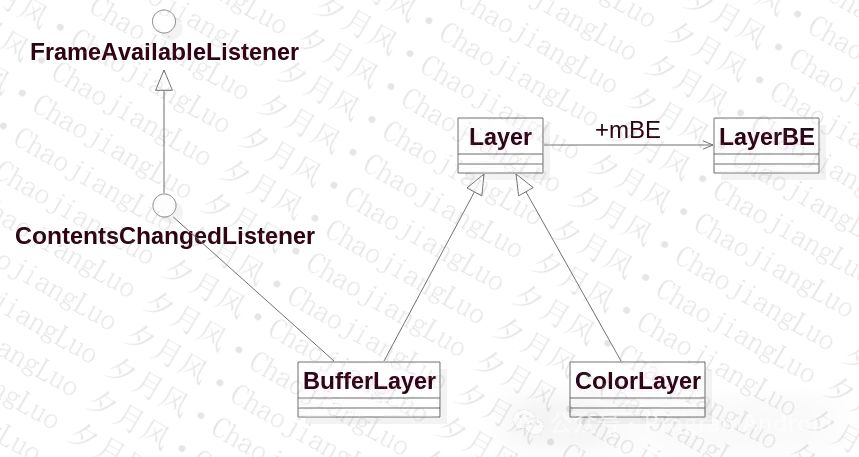
- BufferLayer和ColorLayer继承Layer类
- Layer类,有LayerBE的一个实例
- BufferLayer实现ContentsChangedListener和FrameAvailableListener两个接口类,主要是监听显示内容的改变。
ColorLayer比较 简单,我们先来看BufferLayer。reateBufferLayer实现如下:
status_t SurfaceFlinger::createBufferLayer(const sp<Client>& client,
const String8& name, uint32_t w, uint32_t h, uint32_t flags, PixelFormat& format,
sp<IBinder>* handle, sp<IGraphicBufferProducer>* gbp, sp<Layer>* outLayer)
{
... ...
sp<BufferLayer> layer = new BufferLayer(this, client, name, w, h, flags);
status_t err = layer->setBuffers(w, h, format, flags);
if (err == NO_ERROR) {
*handle = layer->getHandle();
*gbp = layer->getProducer();
*outLayer = layer;
}
ALOGE_IF(err, "createBufferLayer() failed (%s)", strerror(-err));
return err;
}createBufferLayer时,创建一个BufferLayer。
BufferLayer的构造函数如下:
BufferLayer::BufferLayer(SurfaceFlinger* flinger, const sp<Client>& client, const String8& name,
uint32_t w, uint32_t h, uint32_t flags)
: Layer(flinger, client, name, w, h, flags),
mConsumer(nullptr),
mTextureName(UINT32_MAX),
mFormat(PIXEL_FORMAT_NONE),
mCurrentScalingMode(NATIVE_WINDOW_SCALING_MODE_FREEZE),
mBufferLatched(false),
mPreviousFrameNumber(0),
mUpdateTexImageFailed(false),
mRefreshPending(false) {
ALOGV("Creating Layer %s", name.string());
mFlinger->getRenderEngine().genTextures(1, &mTextureName);
mTexture.init(Texture::TEXTURE_EXTERNAL, mTextureName);
if (flags & ISurfaceComposerClient::eNonPremultiplied) mPremultipliedAlpha = false;
mCurrentState.requested = mCurrentState.active;
// drawing state & current state are identical
mDrawingState = mCurrentState;
}在LayerBuffer的构造函数中,主要是初始化了一个mTextureName,已经一些状态的初始化;以及调用Layer的构造函数。
Layer::Layer(SurfaceFlinger* flinger, const sp<Client>& client, const String8& name, uint32_t w,
uint32_t h, uint32_t flags)
: contentDirty(false),
sequence(uint32_t(android_atomic_inc(&sSequence))),
mFlinger(flinger),
mPremultipliedAlpha(true),
mName(name),
mTransactionFlags(0),
mPendingStateMutex(),
mPendingStates(),
mQueuedFrames(0),
mSidebandStreamChanged(false),
mActiveBufferSlot(BufferQueue::INVALID_BUFFER_SLOT),
mCurrentTransform(0),
mOverrideScalingMode(-1),
mCurrentOpacity(true),
mCurrentFrameNumber(0),
mFrameLatencyNeeded(false),
mFiltering(false),
mNeedsFiltering(false),
mProtectedByApp(false),
mClientRef(client),
mPotentialCursor(false),
mQueueItemLock(),
mQueueItemCondition(),
mQueueItems(),
mLastFrameNumberReceived(0),
mAutoRefresh(false),
mFreezeGeometryUpdates(false) {
mCurrentCrop.makeInvalid();
uint32_t layerFlags = 0;
if (flags & ISurfaceComposerClient::eHidden) layerFlags |= layer_state_t::eLayerHidden;
if (flags & ISurfaceComposerClient::eOpaque) layerFlags |= layer_state_t::eLayerOpaque;
if (flags & ISurfaceComposerClient::eSecure) layerFlags |= layer_state_t::eLayerSecure;
mName = name;
mTransactionName = String8("TX - ") + mName;
mCurrentState.active.w = w;
... ... init mCurrentState
mCurrentState.type = 0;
// drawing state & current state are identical
mDrawingState = mCurrentState;
const auto& hwc = flinger->getHwComposer();
const auto& activeConfig = hwc.getActiveConfig(HWC_DISPLAY_PRIMARY);
nsecs_t displayPeriod = activeConfig->getVsyncPeriod();
mFrameTracker.setDisplayRefreshPeriod(displayPeriod);
CompositorTiming compositorTiming;
flinger->getCompositorTiming(&compositorTiming);
mFrameEventHistory.initializeCompositorTiming(compositorTiming);
}Layerd的构造函数中,主要做一些变量的初始化,以及mCurrentState的初始化。
BufferLayer和Layer都是继承RefBase的,还要一个地方做初始化,那就是onFirstRef。
Layer的onFirstRef是空的:
void Layer::onFirstRef() {}BufferLayer的onFirstRef则做了很多操作。在这里我们就看到Producer和Consumer出场了。
void BufferLayer::onFirstRef() {
// Creates a custom BufferQueue for SurfaceFlingerConsumer to use
sp<IGraphicBufferProducer> producer;
sp<IGraphicBufferConsumer> consumer;
BufferQueue::createBufferQueue(&producer, &consumer, true);
mProducer = new MonitoredProducer(producer, mFlinger, this);
mConsumer = new BufferLayerConsumer(consumer,
mFlinger->getRenderEngine(), mTextureName, this);
mConsumer->setConsumerUsageBits(getEffectiveUsage(0));
mConsumer->setContentsChangedListener(this);
mConsumer->setName(mName);
if (mFlinger->isLayerTripleBufferingDisabled()) {
mProducer->setMaxDequeuedBufferCount(2);
}
const sp<const DisplayDevice> hw(mFlinger->getDefaultDisplayDevice());
updateTransformHint(hw);
}BufferLayer,通过BufferQueue的createBufferQueue,创建了一个buffer队列,一个buffer队列,有一个生产者producer,和一个消费者consumer。
createBufferQueue实现如下:
void BufferQueue::createBufferQueue(sp<IGraphicBufferProducer>* outProducer,
sp<IGraphicBufferConsumer>* outConsumer,
bool consumerIsSurfaceFlinger) {
... ...
sp<BufferQueueCore> core(new BufferQueueCore());
LOG_ALWAYS_FATAL_IF(core == NULL,
"BufferQueue: failed to create BufferQueueCore");
sp<IGraphicBufferProducer> producer(new BufferQueueProducer(core, consumerIsSurfaceFlinger));
LOG_ALWAYS_FATAL_IF(producer == NULL,
"BufferQueue: failed to create BufferQueueProducer");
sp<IGraphicBufferConsumer> consumer(new BufferQueueConsumer(core));
LOG_ALWAYS_FATAL_IF(consumer == NULL,
"BufferQueue: failed to create BufferQueueConsumer");
*outProducer = producer;
*outConsumer = consumer;}
- 首先创建了一个BufferQueueCore,这个是BufferQueue的核心。
- 然后创建了一个BufferQueueProducer和一个BufferQueueConsumer,注意Producer和Consumer都持有BufferQueueCore的引用。
BufferQueue创建完后,BufferLayer,又对BufferQueueCore中的Producer和Consume进行封装。分别创建了MonitoredProducer和BufferLayerConsumer。
最后,再对创建的mConsumer和mProducer进行初始化。
mConsumer这边主要有:
- setConsumerUsageBits,设置Consumer的usage
- setContentsChangedListener,这种内容改变的监听,注意这里传的是this指针,因为BufferLayer实现了两个接口,还记得不?
- setName,设置Consumer 名
mProducer这边主要有
- setMaxDequeuedBufferCount
根据系统的属性,设置Producer最多可以申请多少个Buffer,默认是3个;如果配置了属性ro.sf.disable_triple_buffer为true,那就只能用2个。
这个是在SurfaceFlinger初始化时,在SurfaceFlinger的构造函数中决定的。
property_get("ro.sf.disable_triple_buffer", value, "1");
mLayerTripleBufferingDisabled = atoi(value);
ALOGI_IF(mLayerTripleBufferingDisabled, "Disabling Triple Buffering");我们来看看Layer和BufferQueue之间的关系~
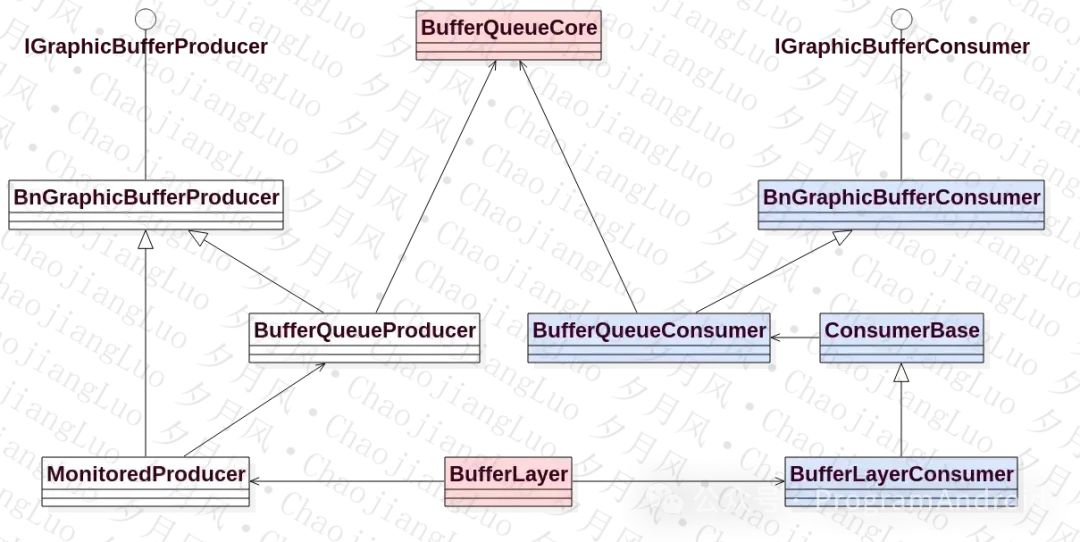
解释一下:
- 一个Layer对应一个BufferQueue,一个BufferQueue中有多个Buffer,一般是2个或者3个。
- 一个Layer有一个Producer,一个Consumer
- 结合前面的分析,一个Surface和一个Layer也是一一对应的,和窗口也是一一对应的。
可见,BufferQueue就是两个连接纽带,连接着Producer和Consumer。接下来,我们就来分别看一下Producer和Consumer。
MonitoredProducer是对BufferQueueProducer的封装,其目的,就是Producer销毁时,能通知SurfaceFlinger。这就是取名Monitored的愿意。余下的,MonitoredProducer的很多接口都是直接调,对应的BufferQueueProducer的实现。
销毁监听,就是在MonitoredProducer析构函数中,post一个消息到SurfaceFlinger的主线程中。通知SurFaceFlinger Producer已经销毁,SurfaceFlinger 会将销毁的Producer从mGraphicBufferProducerList中删掉。代码如下:
MonitoredProducer::~MonitoredProducer() {
// Remove ourselves from SurfaceFlinger's list. We do this asynchronously
// because we don't know where this destructor is called from. It could be
// called with the mStateLock held, leading to a dead-lock (it actually
// happens).
class MessageCleanUpList : public MessageBase {
public:
MessageCleanUpList(const sp<SurfaceFlinger>& flinger,
const wp<IBinder>& producer)
: mFlinger(flinger), mProducer(producer) {}
virtual ~MessageCleanUpList() {}
virtual bool handler() {
Mutex::Autolock _l(mFlinger->mStateLock);
mFlinger->mGraphicBufferProducerList.remove(mProducer);
return true;
}
private:
sp<SurfaceFlinger> mFlinger;
wp<IBinder> mProducer;
};
mFlinger->postMessageAsync(new MessageCleanUpList(mFlinger, asBinder(mProducer)));
}BufferQueueProducer就是Producer真是实现的地方了。前面我们的应用代码中,要绘制一个窗口,有很多个步骤,而每一步的实现,基本都在BufferQueueProducer中。
BufferQueueProducer的类图如下:

其中,dequeueBuffer和queueBuffer是两个非常重要的函数。我们的应用中,是不是通过ANativeWindow的dequeueBuffer函数,获取到一个Buffer,再通过ANativeWindow的queueBuffer,送到显示这边的。具体过程我们稍后我讲解。
再来看Consumer,BufferLayerConsumer继承ConsumerBase。BufferLayerConsumer的构造函数中,主要是一些变量的初始化,主要是ConsumerBase的构造函数:
* frameworks/native/libs/gui/ConsumerBase.cpp
ConsumerBase::ConsumerBase(const sp<IGraphicBufferConsumer>& bufferQueue, bool controlledByApp) :
mAbandoned(false),
mConsumer(bufferQueue),
mPrevFinalReleaseFence(Fence::NO_FENCE) {
// Choose a name using the PID and a process-unique ID.
mName = String8::format("unnamed-%d-%d", getpid(), createProcessUniqueId());
// Note that we can't create an sp<...>(this) in a ctor that will not keep a
// reference once the ctor ends, as that would cause the refcount of 'this'
// dropping to 0 at the end of the ctor. Since all we need is a wp<...>
// that's what we create.
wp<ConsumerListener> listener = static_cast<ConsumerListener*>(this);
sp<IConsumerListener> proxy = new BufferQueue::ProxyConsumerListener(listener);
status_t err = mConsumer->consumerConnect(proxy, controlledByApp);
if (err != NO_ERROR) {
CB_LOGE("ConsumerBase: error connecting to BufferQueue: %s (%d)",
strerror(-err), err);
} else {
mConsumer->setConsumerName(mName);
}
}在ConsumerBase的构造函数中,给BufferQueue设置了监听,这样Consumer和BufferQueue,就算是连上了。
注意这里的Listener。BufferLayer是实现了BufferLayerConsumer的ContentsChangedListener,在BufferLayer的onFirstRef中,这个Listener被设置给了BufferLayerConsumer。
mConsumer->setContentsChangedListener(this);BufferLayerConsumer的setContentsChangedListener函数如下:
void BufferLayerConsumer::setContentsChangedListener(const wp<ContentsChangedListener>& listener) {
setFrameAvailableListener(listener);
Mutex::Autolock lock(mMutex);
mContentsChangedListener = listener;
}可见,在setFrameAvailableListener函数中,BufferLayer的Listener实现被赋值给了mFrameAvailableListener。同时调用setFrameAvailableListener
setFrameAvailableListener的实现在父类ConsumerBase中。
void ConsumerBase::setFrameAvailableListener(
const wp<FrameAvailableListener>& listener) {
CB_LOGV("setFrameAvailableListener");
Mutex::Autolock lock(mFrameAvailableMutex);
mFrameAvailableListener = listener;
}此时,又被赋值给了mFrameAvailableListener,注意,这里的mFrameAvailableListener是BufferLayer中实现的Listener。
ConsumerBase自身实现ConsumerListener,中构造的Listener,通过代理ProxyConsumerListener,在connect时传给了BufferQueueConsumer。
* frameworks/native/libs/gui/BufferQueueConsumer.cpp
status_t BufferQueueConsumer::connect(
const sp<IConsumerListener>& consumerListener, bool controlledByApp) {
ATRACE_CALL();
if (consumerListener == NULL) {
BQ_LOGE("connect: consumerListener may not be NULL");
return BAD_VALUE;
}
BQ_LOGV("connect: controlledByApp=%s",
controlledByApp ? "true" : "false");
Mutex::Autolock lock(mCore->mMutex);
if (mCore->mIsAbandoned) {
BQ_LOGE("connect: BufferQueue has been abandoned");
return NO_INIT;
}
mCore->mConsumerListener = consumerListener;
mCore->mConsumerControlledByApp = controlledByApp;
return NO_ERROR;
}看明白了吧?BufferLayer实现的ContentsChangedListener被保存在ConsumerBase中mFrameAvailableListener。而ConsumerBase实现的ConsumerListener,被传到BufferQueueConsumer,保存在BufferQueueCore的mConsumerListener中。
所以,Listener的通知路线应该是这样的~
- Producer生产完后,会通过BufferQueueCore中的mConsumerListener通知ConsumerBase
- ConsumerBase,接受到BufferQueueConsumer的通知,再通过BufferLayer传下来的信使mFrameAvailableListener,通知BufferLayer。
- BufferLayer接受到通知后,就可以去消费生产完的Buffer了。
到此,Consumer这边准备就绪了,就等着Producer去生产了。注意一点,在分析应用创建Layer时,会得到一个IGraphicBufferProducer,这个就是对应BufferLayer
sp<SurfaceControl> SurfaceComposerClient::createSurface(
... ...
sp<IGraphicBufferProducer> gbp;
if (parent != nullptr) {
parentHandle = parent->getHandle();
}
status_t err = mClient->createSurface(name, w, h, format, flags, parentHandle,
windowType, ownerUid, &handle, &gbp);
ALOGE_IF(err, "SurfaceComposerClient::createSurface error %s", strerror(-err));
if (err == NO_ERROR) {
sur = new SurfaceControl(this, handle, gbp);
}
}
return sur;
}让我们回到我们的应用代码~
Native窗口
在应用代码中,我们已经用到几个关键的类,Surface和SurfaceControl,ANativeWindow和ANativeWindowBuffer;他们又是什么的关系呢,怎么和BufferQueue产生联系的呢?
ANativeWindow
ANativeWindow是Native对一个窗口的描述,和Surface是对等的,Why?可以通过接口ANativeWindow_fromSurface()将Surface转换为ANativeWindow。而事实也ANativeWindow是对BufferQueue的Producer端进行一个封装。
ANativeWindow的定义如下,英文的注释很详细
* frameworks/native/libs/nativewindow/include/system/window.h
struct ANativeWindow
{
#ifdef __cplusplus
ANativeWindow()
: flags(0), minSwapInterval(0), maxSwapInterval(0), xdpi(0), ydpi(0)
{
common.magic = ANDROID_NATIVE_WINDOW_MAGIC;
common.version = sizeof(ANativeWindow);
memset(common.reserved, 0, sizeof(common.reserved));
}
/* Implement the methods that sp<ANativeWindow> expects so that it
can be used to automatically refcount ANativeWindow's. */
void incStrong(const void* /*id*/) const {
common.incRef(const_cast<android_native_base_t*>(&common));
}
void decStrong(const void* /*id*/) const {
common.decRef(const_cast<android_native_base_t*>(&common));
}
#endif
// 相当于从android_native_base_t继承
struct android_native_base_t common;
/* flags describing some attributes of this surface or its updater */
const uint32_t flags;
/* min swap interval supported by this updated */
const int minSwapInterval;
/* max swap interval supported by this updated */
const int maxSwapInterval;
/* horizontal and vertical resolution in DPI */
const float xdpi;
const float ydpi;
/* Some storage reserved for the OEM's driver. */
intptr_t oem[4];
// 设置swap的间隔,也就是设置Producer是同步还是异步
int (*setSwapInterval)(struct ANativeWindow* window,
int interval);
// dequeue一块buffer,执行后,buffer就不是locked状态,内容不能修改
// 这里会造成block,引起ANR等如果没有空闲Buffer
// 这个方法现象不建议使用,现在直接使用下面的dequeueBuffer方法
int (*dequeueBuffer_DEPRECATED)(struct ANativeWindow* window,
struct ANativeWindowBuffer** buffer);
// 在修改Buffer的内容前,先锁住这个Buffer
int (*lockBuffer_DEPRECATED)(struct ANativeWindow* window,
struct ANativeWindowBuffer* buffer);
// 修改完后,通过此方法将buffer送输出,这个Buffer也没有在用了。
int (*queueBuffer_DEPRECATED)(struct ANativeWindow* window,
struct ANativeWindowBuffer* buffer);
// 获取我们需要的值
int (*query)(const struct ANativeWindow* window,
int what, int* value);
// 执行对应的操纵
int (*perform)(struct ANativeWindow* window,
int operation, ... );
// 取消掉一个已经被deueue出来的值
int (*cancelBuffer_DEPRECATED)(struct ANativeWindow* window,
struct ANativeWindowBuffer* buffer);
// dequeueBuffer_DEPRECATED的新版本,使用者自己处理Fence
int (*dequeueBuffer)(struct ANativeWindow* window,
struct ANativeWindowBuffer** buffer, int* fenceFd);
// queueBuffer_DEPRECATED的新版本
int (*queueBuffer)(struct ANativeWindow* window,
struct ANativeWindowBuffer* buffer, int fenceFd);
// cancelBuffer_DEPRECATED的新版本,必须要和dequeue在同一个线程中
int (*cancelBuffer)(struct ANativeWindow* window,
struct ANativeWindowBuffer* buffer, int fenceFd);
};此外,window.h头文件中还提供了很多类型native_window_**的API,这些API就是通过ANativeWindow的perform函数调下去的。API很多,这里就不一一介绍了,前面我们的应用代码中已经使用了不少。
为什么说ANativeWindow和Surface是对等的?我们来看看Surface
Surface
Surface也是BufferQueue在Producer端的封装,每个窗口都有且只有一个自己的Surface(同一时刻)。为什么说ANativeWindow和Surface是对等的,实际上Surface继承ANativeWindow。
* frameworks/native/libs/gui/include/gui/Surface.h
class Surface
: public ANativeObjectBase<ANativeWindow, Surface, RefBase>ANativeWindow是一个模板类,主要是将类似ANativeWindow这样的类型,转换为引用计数控制的类型,实现对象的自动释放。
template <typename NATIVE_TYPE, typename TYPE, typename REF,
typename NATIVE_BASE = android_native_base_t>
class ANativeObjectBase : public NATIVE_TYPE, public REF
{Surface的代码比较多,这里就不贴代码了。但是整体而言,主要如下:
- ANativeWindow的hooks函数,命名为hook_***,总共10个hook函数,如hook_perform,hook_dequeueBuffer等
- window.h头文件中定义的API的分发,命名为dispatch***,总共29个,如dispatchConnect,dispatchSetCrop等
- Surface对hook函数和dispatch函数的具体实现,这些给函数就和BufferQueue交互。
- 窗口,Buffer的很多描述的属性定义在Surface中。
Surface的实现在:
* frameworks/native/libs/gui/Surface.cpp在构造函数中,主要是变量的初始化,和ANativeWindow的函数的初始化,将hook函数直接赋值给ANativeWindow对应的函数。
根据我们应用的代码,我们来看看具有代表行的一两个流程,就看native_window_set_buffers_format。
* frameworks/native/libs/nativewindow/include/system/window.h
static inline int native_window_set_buffers_format(
struct ANativeWindow* window,
int format)
{
return window->perform(window, NATIVE_WINDOW_SET_BUFFERS_FORMAT, format);
}native_window_api_connect 调的是 ANativeWindow 的 perform 函数,而perform的类型为 NATIVE_WINDOW_SET_BUFFERS_FORMAT。
perform函数是Surface中实现的:
* frameworks/native/libs/gui/Surface.cpp
int Surface::perform(int operation, va_list args)
{
int res = NO_ERROR;
switch (operation) {
... ...
case NATIVE_WINDOW_SET_BUFFERS_FORMAT:
res = dispatchSetBuffersFormat(args);
break;
... ...
}dispatch函数为dispatchSetBuffersFormat
int Surface::dispatchSetBuffersFormat(va_list args) {
PixelFormat format = va_arg(args, PixelFormat);
return setBuffersFormat(format);
}Surface的实现为:
int Surface::setBuffersFormat(PixelFormat format)
{
ALOGV("Surface::setBuffersFormat");
Mutex::Autolock lock(mMutex);
if (format != mReqFormat) {
mSharedBufferSlot = BufferItem::INVALID_BUFFER_SLOT;
}
mReqFormat = format;
return NO_ERROR;
}设置的Buffer格式被赋值给了mReqFormat。
以此类推,window.h 头文件中的API,都会设置一个类型,然后通过perform函数,调到Surface中的具体实现。
hook的函数也是类似的,我们以ANativeWindow的dequeueBuffer为例,ANativeWindow的dequeueBuffer函数,直接被赋值为Surface的dequeueBuffer。
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
... ...
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight,
reqFormat, reqUsage, &mBufferAge,
enableFrameTimestamps ? &frameTimestamps
: nullptr);
... ...
sp<GraphicBuffer>& gbuf(mSlots[buf].buffer);
... ...
*buffer = gbuf.get();
... ...
return OK;
}dequeueBuffer的时候,通过mGraphicBufferProducer的dequeueBuffer,去找到可用Buffer的id,然后根据id去队列里面取Buffer。
这下明白,为什么说 ANativeWindow和Surface是对等的了吧。但是... ..
但是,对不对等,取决于是否真是的用到Surface。比如,我不想用 Surface的这个流程,我自己写一个MySurface,继承与ANativeWindow,然后我用自己的MySurface。此时,元芳,你怎么看?
那么ANativeWindow和Surface怎么对等的呢?我们且来看SurfaceControl。
SurfaceControl
SurfaceControl,简单理解就是控制Surface的。怎么控制?我们先来看,什么时候创建的SurfaceControl。
创建Layer的时候,通过createSurface创建了Layer,
sp<SurfaceControl> SurfaceComposerClient::createSurface(
... ...
sp<IGraphicBufferProducer> gbp;
if (parent != nullptr) {
parentHandle = parent->getHandle();
}
status_t err = mClient->createSurface(name, w, h, format, flags, parentHandle,
windowType, ownerUid, &handle, &gbp);
ALOGE_IF(err, "SurfaceComposerClient::createSurface error %s", strerror(-err));
if (err == NO_ERROR) {
sur = new SurfaceControl(this, handle, gbp);
}
}
return sur;
}创建了Layer后,获取到Layer的handle和BufferQueue的Producer,SurfaceControl中就有了Layer的handle和Producer了。
SurfaceControl的类图:

构造函数如下:
* frameworks/native/libs/gui/SurfaceControl.cpp
SurfaceControl::SurfaceControl(
const sp<SurfaceComposerClient>& client,
const sp<IBinder>& handle,
const sp<IGraphicBufferProducer>& gbp)
: mClient(client), mHandle(handle), mGraphicBufferProducer(gbp)
{
}这里SurfaceControl就和Layer,BufferQueue建立联系了。
再回到我们的代码:
ANativeWindow* aNativeWindow = surfaceControl->getSurface().get();这里SurfaceControl的getSurface是一个sp<Surface>,这里是多态的用法,这就是为什么说ANativeWindow和Surface对等了。
getSurface函数如下:
sp<Surface> SurfaceControl::getSurface() const
{
Mutex::Autolock _l(mLock);
if (mSurfaceData == 0) {
return generateSurfaceLocked();
}
return mSurfaceData;
}generateSurfaceLocked函数中,创建一个Surface
sp<Surface> SurfaceControl::generateSurfaceLocked() const
{
// This surface is always consumed by SurfaceFlinger, so the
// producerControlledByApp value doesn't matter; using false.
mSurfaceData = new Surface(mGraphicBufferProducer, false);
return mSurfaceData;
}看到了吧,Surface中的mGraphicBufferProducer是从哪儿来的了吧。在Layer端为MonitoredProducer,Surface这边是Binder的Bp端。
我们先来看Surface相关类的关系吧
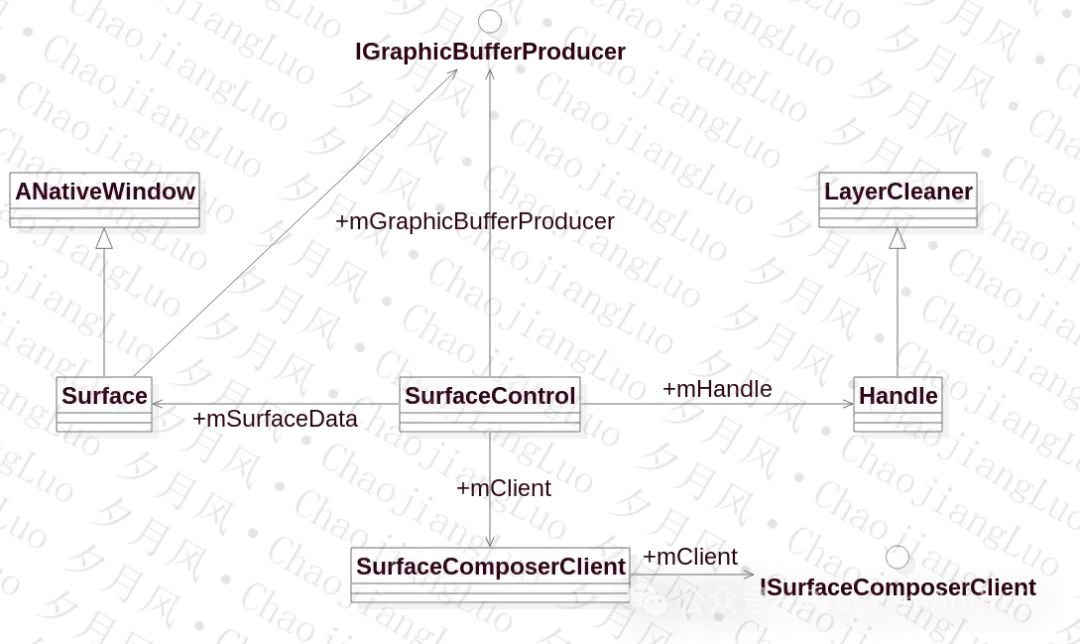
看了Surface相关的关系类图,再和SurfaceFlinger,Layer相关的关系类似结合,应用和SurfaceFlinger服务的关系是不是就很清楚了。
到此,应用该做的准备工作都准备完了,应用端主要通过IGraphicBufferProducer和ISurfaceComposerClient两个接口SurfaceFlinger进行交互。
在开始下面的知识之前,我们先来看看这个LayerCleaner
窗口销毁的善后处理
应用被销毁后,Client端就被清理了,SurfaceControl,SurfaceComposerClient,被销毁。但是服务端,SurfaceFlinger是另外一个进程,为应用进程申请的相关资源什么很好释放呢?
关键还是看上面类图中的Handler。我们就来看一下流程:
SurfaceControl::~SurfaceControl()
{
destroy();
}在destroy函数中,销毁应用进程中的资源:
void SurfaceControl::destroy()
{
if (isValid()) {
mClient->destroySurface(mHandle);
}
// clear all references and trigger an IPC now, to make sure things
// happen without delay, since these resources are quite heavy.
mClient.clear();
mHandle.clear();
mGraphicBufferProducer.clear();
IPCThreadState::self()->flushCommands();
}而服务端的,有两种方式:
- 直接通过 Client destroySurface:
* frameworks/native/services/surfaceflinger/Client.cpp
status_t Client::destroySurface(const sp<IBinder>& handle) {
return mFlinger->onLayerRemoved(this, handle);
}status_t SurfaceFlinger::onLayerRemoved(const sp<Client>& client, const sp<IBinder>& handle)
{
// called by a client when it wants to remove a Layer
status_t err = NO_ERROR;
sp<Layer> l(client->getLayerUser(handle));
if (l != NULL) {
mInterceptor.saveSurfaceDeletion(l);
err = removeLayer(l);
ALOGE_IF(err<0 && err != NAME_NOT_FOUND,
"error removing layer=%p (%s)", l.get(), strerror(-err));
}
return err;
}但是,注意这里的isValid()
如果isValid无效呢?
这个时候,我们就要通过mClient和mHandle。这个时候是引用计数控制的自动释放。
- 引用计数控制自动释放
mClient.clear();
mHandle.clear();clear函数会是否对象的应用,最终调用析构函数:
Client::~Client()
{
const size_t count = mLayers.size();
for (size_t i=0 ; i<count ; i++) {
sp<Layer> l = mLayers.valueAt(i).promote();
if (l != nullptr) {
mFlinger->removeLayer(l);
}
}
}这里是不是和destroySurface函数是异曲同工之处。
再来看Handle:
* frameworks/native/services/surfaceflinger/Layer.h
class Handle : public BBinder, public LayerCleaner {
public:
Handle(const sp<SurfaceFlinger>& flinger, const sp<Layer>& layer)
: LayerCleaner(flinger, layer), owner(layer) {}
wp<Layer> owner;
};Handle析构时,会调父类的析构:
protected:
~LayerCleaner() {
// destroy client resources
mFlinger->onLayerDestroyed(mLayer);
}
};LayerCleaner的析构中同样调的SurfaceFlinger的onLayerRemoved函数。再调的removeLayer
status_t SurfaceFlinger::removeLayer(const sp<Layer>& layer, bool topLevelOnly) {
... ...
const auto& p = layer->getParent();
ssize_t index;
if (p != nullptr) {
... ...
index = p->removeChild(layer);
} else {
index = mCurrentState.layersSortedByZ.remove(layer);
}
... ...
layer->onRemovedFromCurrentState();
mLayersPendingRemoval.add(layer);
mLayersRemoved = true;
mNumLayers -= 1 + layer->getChildrenCount();
setTransactionFlags(eTransactionNeeded);
return NO_ERROR;
}删除Layer时,主要做了以下几件事:
- 将Layer从父Layer中删掉,或者从mCurrentState中删掉,放到待删除Layer列表中
- onRemovedFromCurrentState,清理Layer,如果是父Layer,子Layer也删掉
- setTransactionFlags,通知SurfaceFlinger更新,更新后,我们删掉的Layer就没有了,屏幕就不显示了。
最后销毁Layer
* frameworks/native/services/surfaceflinger/Layer.cpp
Layer::~Layer() {
sp<Client> c(mClientRef.promote());
if (c != 0) {
c->detachLayer(this);
}
for (auto& point : mRemoteSyncPoints) {
point->setTransactionApplied();
}
for (auto& point : mLocalSyncPoints) {
point->setFrameAvailable();
}
mFrameTracker.logAndResetStats(mName);
}A代码。我们这里只绘制了一次,但是在Andoroid的系统中,界面的不断更新的,也就是说,这里的绘制是一个不断循环的过程。
// 11. draw the ANativeWindow
for (int i = 0; i < numBufs + 1; i++) {
// 12. dequeue a buffer
int hwcFD= -1;
err = aNativeWindow->dequeueBuffer(aNativeWindow, &aNativeBuffer, &hwcFD);
if (err != NO_ERROR) {
ALOGE("error pushing blank frames: dequeueBuffer failed: %s (%d)",
strerror(-err), -err);
break;
}
// 13. make sure really control the dequeued buffer
sp<Fence> hwcFence(new Fence(hwcFD));
int waitResult = hwcFence->waitForever("dequeueBuffer_EmptyNative");
if (waitResult != OK) {
ALOGE("dequeueBuffer_EmptyNative: Fence::wait returned an error: %d", waitResult);
break;
}
sp<GraphicBuffer> buf(GraphicBuffer::from(aNativeBuffer));
// 14. Fill the buffer with black
uint8_t *img = NULL;
err = buf->lock(GRALLOC_USAGE_SW_WRITE_OFTEN, (void**)(&img));
if (err != NO_ERROR) {
ALOGE("error pushing blank frames: lock failed: %s (%d)", strerror(-err), -err);
break;
}
//15. Draw the window, here we fill the window with black.
*img = 0;
err = buf->unlock();
if (err != NO_ERROR) {
ALOGE("error pushing blank frames: unlock failed: %s (%d)", strerror(-err), -err);
break;
}
// 16. queue the buffer to display
int gpuFD = -1;
err = aNativeWindow->queueBuffer(aNativeWindow, buf->getNativeBuffer(), gpuFD);
if (err != NO_ERROR) {
ALOGE("error pushing blank frames: queueBuffer failed: %s (%d)", strerror(-err), -err);
break;
}
aNativeBuffer = NULL;
}抽象一下,就是:
while {
dequeueBuffer
lock
unlock
queueBuffer
}这里的GraphicBuffer是队列中的Buffer, 循环使用,显示完了,又可以用来绘制新的显示数据。
我们可以来看一下,我们跑测试应用时的显示数据流:
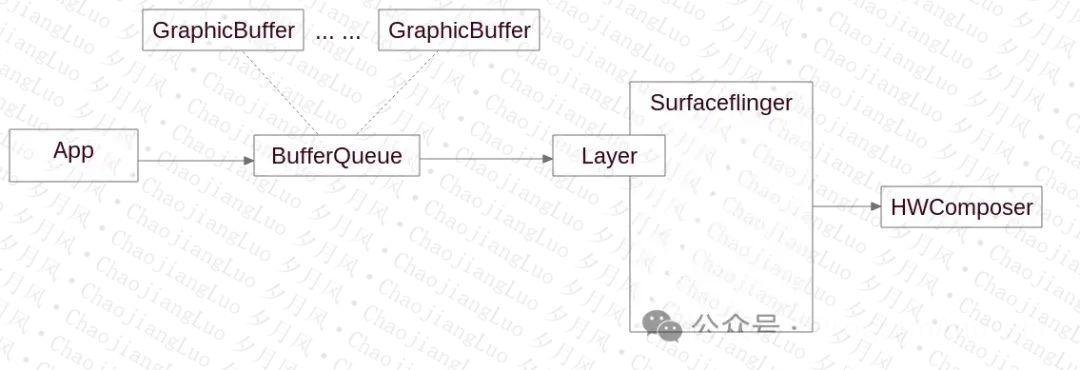
应用绘制完成后,将数据交还给BufferQueue,Layer这边从BufferQueue中获取数据,进行合成显示。
扩展到多个界面时,数据流图如下:
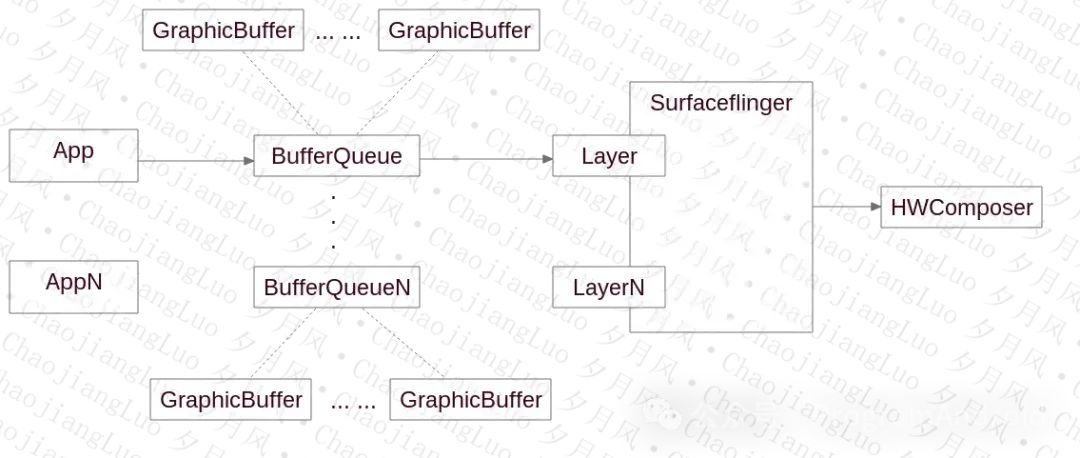
这中间过程复杂,我们一个流程一个流程的看。
dequeueBuffer申请buffer绘制
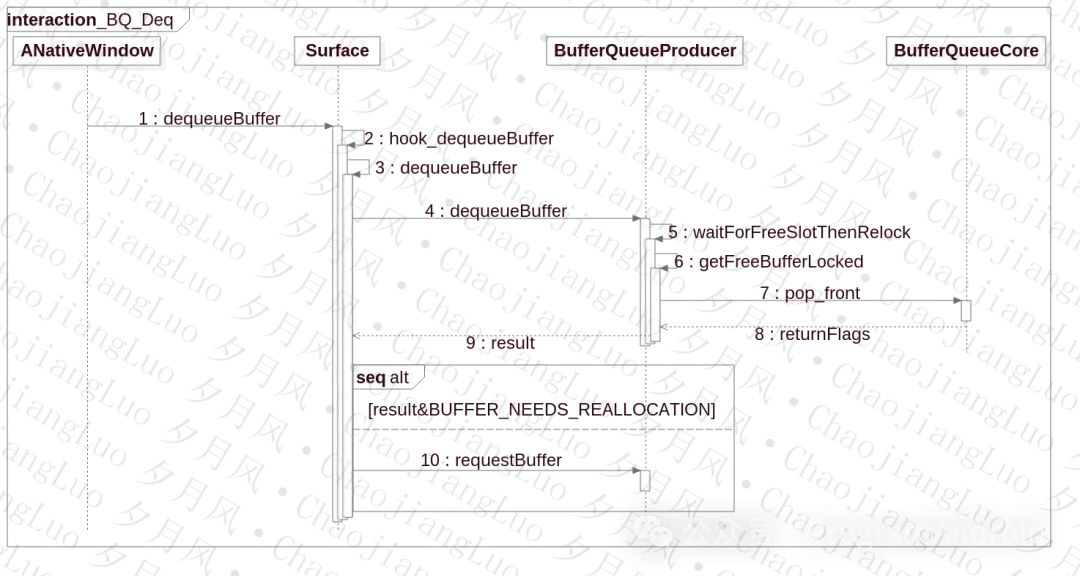
应用要进程绘制,首先要申请一块Buffer,我们这边ANativeWindow通过dequeueBuffer从BufferQueue中获取一块Buffer。ANativeWindow的dequeueBuffer初始化为Surface的hook_dequeueBuffer方法。
int Surface::hook_dequeueBuffer(ANativeWindow* window,
ANativeWindowBuffer** buffer, int* fenceFd) {
Surface* c = getSelf(window);
return c->dequeueBuffer(buffer, fenceFd);
}通过hook函数,调到Surface的dequeueBuffer方法,dequeueBuffer比较长,我们分阶段来看:
1.deqeue准备
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
... ...
{
Mutex::Autolock lock(mMutex);
if (mReportRemovedBuffers) {
mRemovedBuffers.clear();
}
reqWidth = mReqWidth ? mReqWidth : mUserWidth;
reqHeight = mReqHeight ? mReqHeight : mUserHeight;
reqFormat = mReqFormat;
reqUsage = mReqUsage;
enableFrameTimestamps = mEnableFrameTimestamps;
if (mSharedBufferMode && mAutoRefresh && mSharedBufferSlot !=
BufferItem::INVALID_BUFFER_SLOT) {
sp<GraphicBuffer>& gbuf(mSlots[mSharedBufferSlot].buffer);
if (gbuf != NULL) {
*buffer = gbuf.get();
*fenceFd = -1;
return OK;
}
}
} // Drop the lock so that we can still touch the Surface while blocking in IGBP::dequeueBuffer在准备阶段,主要是处理,前面的设置的参数需求,对Buffer大小的需求,格式和usage的需求。这过程是被锁mMutex锁住的。这里的mSharedBufferMode是一种特殊的模式,是上层应用请求的,专门给特殊的应用使用的,主要是VR应用。因为VR应用要求低延时,BufferQueue采用的交换用的Buffer多了,延迟增加。为了降低延迟,设计了这个共享buffer的模式,Producer和Consumer共用一个Buffer。应用绘制完成后,直接给到Consumer进行显示。后续我们的讲解将直接跳过这么这种模式。
2.实际dequeue阶段
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
... ...
int buf = -1;
sp<Fence> fence;
nsecs_t startTime = systemTime();
FrameEventHistoryDelta frameTimestamps;
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight,
reqFormat, reqUsage, &mBufferAge,
enableFrameTimestamps ? &frameTimestamps
: nullptr);
mLastDequeueDuration = systemTime() - startTime;
if (result < 0) {
ALOGV("dequeueBuffer: IGraphicBufferProducer::dequeueBuffer"
"(%d, %d, %d, %#" PRIx64 ") failed: %d",
reqWidth, reqHeight, reqFormat, reqUsage, result);
return result;
}
if (buf < 0 || buf >= NUM_BUFFER_SLOTS) {
ALOGE("dequeueBuffer: IGraphicBufferProducer returned invalid slot number %d", buf);
android_errorWriteLog(0x534e4554, "36991414"); // SafetyNet logging
return FAILED_TRANSACTION;
}dequeue是通过mGraphicBufferProducer来完成的。dequeueBuffer参数就是我们需要的大小的需求,格式和usage参数。dequeue回来的就是buf,并不是具体的Buffer,而是Buffer的序号。
Surface这边的dequeueBuffer暂停,我们先看看GraphicBufferProducer的dequeue函数。GraphicBufferProducer的dequeue函数更长,但是大家不要怕,我们来解析一下。分段来看:
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
ATRACE_CALL();
{ // Autolock scope
Mutex::Autolock lock(mCore->mMutex);
mConsumerName = mCore->mConsumerName;
if (mCore->mIsAbandoned) {
BQ_LOGE("dequeueBuffer: BufferQueue has been abandoned");
return NO_INIT;
}
if (mCore->mConnectedApi == BufferQueueCore::NO_CONNECTED_API) {
BQ_LOGE("dequeueBuffer: BufferQueue has no connected producer");
return NO_INIT;
}
} // Autolock scope
BQ_LOGV("dequeueBuffer: w=%u h=%u format=%#x, usage=%#" PRIx64, width, height, format, usage);
if ((width && !height) || (!width && height)) {
BQ_LOGE("dequeueBuffer: invalid size: w=%u h=%u", width, height);
return BAD_VALUE;
}前置条件判断
- mConsumerName, 消费者的名字,这个是从Layer那边过来的,这个buffer是属于哪个Layer,哪个窗口。
- mIsAbandoned,表示BufferQueue是否被丢弃,丢弃后BufferQueue就不能用了。
- mConnectedApi,标识这个BufferQueue连接到了哪个API,App connect到BufferQueue时设置的
继续看
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
... ...
status_t returnFlags = NO_ERROR;
EGLDisplay eglDisplay = EGL_NO_DISPLAY;
EGLSyncKHR eglFence = EGL_NO_SYNC_KHR;
bool attachedByConsumer = false;
{ // Autolock scope
Mutex::Autolock lock(mCore->mMutex);
mCore->waitWhileAllocatingLocked();
if (format == 0) {
format = mCore->mDefaultBufferFormat;
}
// Enable the usage bits the consumer requested
usage |= mCore->mConsumerUsageBits;
const bool useDefaultSize = !width && !height;
if (useDefaultSize) {
width = mCore->mDefaultWidth;
height = mCore->mDefaultHeight;
}需求参数的处理,宽高,format,都是应用传过来的。usage这里会跟Consumer的位或一下,最终是Producer和Consumer两个的总和。如果正在申请Buffer,waitWhileAllocatingLocked,这边会去block等待。
接下里,根据参数,找到一个可用的Buffer
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
... ...
int found = BufferItem::INVALID_BUFFER_SLOT;
while (found == BufferItem::INVALID_BUFFER_SLOT) {
status_t status = waitForFreeSlotThenRelock(FreeSlotCaller::Dequeue,
&found);
if (status != NO_ERROR) {
return status;
}
// This should not happen
if (found == BufferQueueCore::INVALID_BUFFER_SLOT) {
BQ_LOGE("dequeueBuffer: no available buffer slots");
return -EBUSY;
}
const sp<GraphicBuffer>& buffer(mSlots[found].mGraphicBuffer);
// If we are not allowed to allocate new buffers,
// waitForFreeSlotThenRelock must have returned a slot containing a
// buffer. If this buffer would require reallocation to meet the
// requested attributes, we free it and attempt to get another one.
if (!mCore->mAllowAllocation) {
if (buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage)) {
if (mCore->mSharedBufferSlot == found) {
BQ_LOGE("dequeueBuffer: cannot re-allocate a sharedbuffer");
return BAD_VALUE;
}
mCore->mFreeSlots.insert(found);
mCore->clearBufferSlotLocked(found);
found = BufferItem::INVALID_BUFFER_SLOT;
continue;
}
}
}found是Buffer的序号,这里采用while循环的去等待可用的Buffer,如果有Free的Buffer,将Buffer从mSlots中获取出来GraphicBuffer。如果获取到的Buffer和我们需要的Buffer宽高,属性等不满足。而Producer又不允许分配buffer,我们就将它释放掉,重新获取一个。直到找到我们需要的Buffer。
我们来看found是从哪儿来的~这里面的函数都比较长,waitForFreeSlotThenRelock也不例外。waitForFreeSlotThenRelock中就是一个while循环。
status_t BufferQueueProducer::waitForFreeSlotThenRelock(FreeSlotCaller caller,
int* found) const {
auto callerString = (caller == FreeSlotCaller::Dequeue) ?
"dequeueBuffer" : "attachBuffer";
bool tryAgain = true;
while (tryAgain) {
if (mCore->mIsAbandoned) {
BQ_LOGE("%s: BufferQueue has been abandoned", callerString);
return NO_INIT;
}
int dequeuedCount = 0;
int acquiredCount = 0;
for (int s : mCore->mActiveBuffers) {
if (mSlots[s].mBufferState.isDequeued()) {
++dequeuedCount;
}
if (mSlots[s].mBufferState.isAcquired()) {
++acquiredCount;
}
}留意BufferQueueCore的这个几个数组,前面我们已经见过的mSlots,这里又有一个mActiveBuffers。mSlots是总的;这里的mActiveBuffers是活跃的,不包含free的状态的。
这里我们先找出来,有多少个buffer是已经处于dequeued状态的dequeuedCount;多少个是处于acquired状态的。dequeued状态就是被应用拿去绘制去了,acquired状态就是buffer被消费者拿去合成显示去了。
什么情况下能找到可用的Buffer?
status_t BufferQueueProducer::waitForFreeSlotThenRelock(FreeSlotCaller caller,
int* found) const {
... ...
// Producers are not allowed to dequeue more than
// mMaxDequeuedBufferCount buffers.
// This check is only done if a buffer has already been queued
if (mCore->mBufferHasBeenQueued &&
dequeuedCount >= mCore->mMaxDequeuedBufferCount) {
BQ_LOGE("%s: attempting to exceed the max dequeued buffer count "
"(%d)", callerString, mCore->mMaxDequeuedBufferCount);
return INVALID_OPERATION;
}超过最大可dequeue数mMaxDequeuedBufferCount时,不能再dequeue到Buffer。太贪心了,吃着碗里的,看着锅中的。如果出现这个问题,应该是应用绘制的很慢,或者是buffer存在了泄露。
再来看下面的这种情况:
*found = BufferQueueCore::INVALID_BUFFER_SLOT;
... ...
const int maxBufferCount = mCore->getMaxBufferCountLocked();
bool tooManyBuffers = mCore->mQueue.size()
> static_cast<size_t>(maxBufferCount);
if (tooManyBuffers) {
BQ_LOGV("%s: queue size is %zu, waiting", callerString,
mCore->mQueue.size());
} else {
if (mCore->mSharedBufferMode && mCore->mSharedBufferSlot !=
BufferQueueCore::INVALID_BUFFER_SLOT) {
*found = mCore->mSharedBufferSlot;
} else {
if (caller == FreeSlotCaller::Dequeue) {
// If we're calling this from dequeue, prefer free buffers
int slot = getFreeBufferLocked();
if (slot != BufferQueueCore::INVALID_BUFFER_SLOT) {
*found = slot;
} else if (mCore->mAllowAllocation) {
*found = getFreeSlotLocked();
}
} else {
// If we're calling this from attach, prefer free slots
int slot = getFreeSlotLocked();
if (slot != BufferQueueCore::INVALID_BUFFER_SLOT) {
*found = slot;
} else {
*found = getFreeBufferLocked();
}
}
}
}BufferQueueCore又出来一个队列mQueue,mQueue是一个FIFO的队列应用绘制完成后,queue到BufferQueue中,其实就是queue到这个队列里面。
tooManyBuffers表示应用已经绘制完成了,但是一直没有被消费,处于queued状态的buffer超过了maxBufferCount数,这个时候不能再分配,如果分配就会造成内存紧张。
我们这里的caller是Dequeue,getFreeBufferLocked和getFreeSlotLocked又引出BufferQueueCore的两个队列。mFreeBuffers和mFreeSlots。我们说过,这里的队列是Buffer的序号,mFreeBuffers表示Buffer是Free的,这个序号对应的Buffer已经被分配出来了,只是现在没有被使用。而mFreeSlots表示,序号是Free的,这些序号还没有被用过,说明对应的是没有Buffer,Buffer还没有分配。
如果找不到,found还是为INVALID_BUFFER_SLOT。没有关系,如果是tooManyBuffers太多,或是INVALID_BUFFER_SLOT,将再试一次tryAgain。
tryAgain = (*found == BufferQueueCore::INVALID_BUFFER_SLOT) ||
tooManyBuffers;
if (tryAgain) {
// Return an error if we're in non-blocking mode (producer and
// consumer are controlled by the application).
// However, the consumer is allowed to briefly acquire an extra
// buffer (which could cause us to have to wait here), which is
// okay, since it is only used to implement an atomic acquire +
// release (e.g., in GLConsumer::updateTexImage())
if ((mCore->mDequeueBufferCannotBlock || mCore->mAsyncMode) &&
(acquiredCount <= mCore->mMaxAcquiredBufferCount)) {
return WOULD_BLOCK;
}
if (mDequeueTimeout >= 0) {
status_t result = mCore->mDequeueCondition.waitRelative(
mCore->mMutex, mDequeueTimeout);
if (result == TIMED_OUT) {
return result;
}
} else {
mCore->mDequeueCondition.wait(mCore->mMutex);
}
}
} // while (tryAgain)
return NO_ERROR;
}tryAgain时,先看看dequeue Buffer是不是阻塞式的,如果不是,直接返回了,此时没有dequeue到我们需要的buffer。如果是阻塞式的,就等着吧,等有Buffer release。等有两种方式,一种是等固定的时间,一种是等mCore->mMutex。
当然,如果找到了可以用的Buffer,就不用tryAgain了,直接返回去了。
继续来看BufferQueueProducer的dequeueBuffer:
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
... ...
const sp<GraphicBuffer>& buffer(mSlots[found].mGraphicBuffer);
if (mCore->mSharedBufferSlot == found &&
buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage)) {
BQ_LOGE("dequeueBuffer: cannot re-allocate a shared"
"buffer");
return BAD_VALUE;
}
if (mCore->mSharedBufferSlot != found) {
mCore->mActiveBuffers.insert(found);
}
*outSlot = found;
ATRACE_BUFFER_INDEX(found);
attachedByConsumer = mSlots[found].mNeedsReallocation;
mSlots[found].mNeedsReallocation = false;
mSlots[found].mBufferState.dequeue();
if ((buffer == NULL) ||
buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage))
{
mSlots[found].mAcquireCalled = false;
mSlots[found].mGraphicBuffer = NULL;
mSlots[found].mRequestBufferCalled = false;
mSlots[found].mEglDisplay = EGL_NO_DISPLAY;
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;
mCore->mBufferAge = 0;
mCore->mIsAllocating = true;
returnFlags |= BUFFER_NEEDS_REALLOCATION;
} else {
// We add 1 because that will be the frame number when this buffer
// is queued
mCore->mBufferAge = mCore->mFrameCounter + 1 - mSlots[found].mFrameNumber;
}根据找到buffer序号,找到GraphicBuffer,再看看需不需要重新分配。SharedBufer不能重新分配buffer,直接返回了。如果不是共享buffer,将我们找到found加如mActiveBuffers队列中。outSlot的buffer就是found。
如果需要重新分配,那就要释放掉原来的Buffer。mSlots中需要的信息复位。returnFlags加上BUFFER_NEEDS_REALLOCATION。如果不需要重新分配,mCore->mBufferAge +1。
eglDisplay = mSlots[found].mEglDisplay;
eglFence = mSlots[found].mEglFence;
// Don't return a fence in shared buffer mode, except for the first
// frame.
*outFence = (mCore->mSharedBufferMode &&
mCore->mSharedBufferSlot == found) ?
Fence::NO_FENCE : mSlots[found].mFence;
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;
// If shared buffer mode has just been enabled, cache the slot of the
// first buffer that is dequeued and mark it as the shared buffer.
if (mCore->mSharedBufferMode && mCore->mSharedBufferSlot ==
BufferQueueCore::INVALID_BUFFER_SLOT) {
mCore->mSharedBufferSlot = found;
mSlots[found].mBufferState.mShared = true;
}
} // Autolock scopeeglDisplay用以创建EGLSyncKHR。eglFence同步Buffer,上一个使用者使用完成后,将signal出来。outFence的值就是eglFence,共享buffer没有fence。如果是共享的buffer,将found保存下来,以后就一直用这个 buffer了。
重新分配Buffer,需要重新new一个GraphicBuffer。
if (returnFlags & BUFFER_NEEDS_REALLOCATION) {
BQ_LOGV("dequeueBuffer: allocating a new buffer for slot %d", *outSlot);
sp<GraphicBuffer> graphicBuffer = new GraphicBuffer(
width, height, format, BQ_LAYER_COUNT, usage,
{mConsumerName.string(), mConsumerName.size()});
status_t error = graphicBuffer->initCheck();
{ // Autolock scope
Mutex::Autolock lock(mCore->mMutex);
if (error == NO_ERROR && !mCore->mIsAbandoned) {
graphicBuffer->setGenerationNumber(mCore->mGenerationNumber);
mSlots[*outSlot].mGraphicBuffer = graphicBuffer;
}
mCore->mIsAllocating = false;
mCore->mIsAllocatingCondition.broadcast();
if (error != NO_ERROR) {
mCore->mFreeSlots.insert(*outSlot);
mCore->clearBufferSlotLocked(*outSlot);
BQ_LOGE("dequeueBuffer: createGraphicBuffer failed");
return error;
}
if (mCore->mIsAbandoned) {
mCore->mFreeSlots.insert(*outSlot);
mCore->clearBufferSlotLocked(*outSlot);
BQ_LOGE("dequeueBuffer: BufferQueue has been abandoned");
return NO_INIT;
}
VALIDATE_CONSISTENCY();
} // Autolock scope
}新分配的Buffer保存到mSlots[*outSlot].mGraphicBuffer。这里的mSlot是BufferQueueCore的mSlots的引用(看构造函数)。如果Buffer分配失败了,Buffer的序号,放入队列mFreeSlots中。
怎么分Buffer的后续再介绍,继续看dequeueBuffer。
if (attachedByConsumer) {
returnFlags |= BUFFER_NEEDS_REALLOCATION;
}
if (eglFence != EGL_NO_SYNC_KHR) {
EGLint result = eglClientWaitSyncKHR(eglDisplay, eglFence, 0,
1000000000);
// If something goes wrong, log the error, but return the buffer without
// synchronizing access to it. It's too late at this point to abort the
// dequeue operation.
if (result == EGL_FALSE) {
BQ_LOGE("dequeueBuffer: error %#x waiting for fence",
eglGetError());
} else if (result == EGL_TIMEOUT_EXPIRED_KHR) {
BQ_LOGE("dequeueBuffer: timeout waiting for fence");
}
eglDestroySyncKHR(eglDisplay, eglFence);
}
BQ_LOGV("dequeueBuffer: returning slot=%d/%" PRIu64 " buf=%p flags=%#x",
*outSlot,
mSlots[*outSlot].mFrameNumber,
mSlots[*outSlot].mGraphicBuffer->handle, returnFlags);
if (outBufferAge) {
*outBufferAge = mCore->mBufferAge;
}
addAndGetFrameTimestamps(nullptr, outTimestamps);
return returnFlags;
}attachedByConsumer,如果这个Buffer是Consumer这边attach上来的,需要给到这个标识BUFFER_NEEDS_REALLOCATION给Producer,但是不需要去new已给,因为已经new过了。
eglClientWaitSyncKHR,等eglfence。这个逻辑现在已经很少走到了。
此外,返回的是returnFlags。
BufferQueueProducer的dequeueBuffer完了,让我们回到Surface的dequeueBuffer。
3.dequeue后的处理阶段
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
... ...
Mutex::Autolock lock(mMutex);
// Write this while holding the mutex
mLastDequeueStartTime = startTime;
sp<GraphicBuffer>& gbuf(mSlots[buf].buffer);
// this should never happen
ALOGE_IF(fence == NULL, "Surface::dequeueBuffer: received null Fence! buf=%d", buf);
if (result & IGraphicBufferProducer::RELEASE_ALL_BUFFERS) {
freeAllBuffers();
}
if (enableFrameTimestamps) {
mFrameEventHistory->applyDelta(frameTimestamps);
}
if ((result & IGraphicBufferProducer::BUFFER_NEEDS_REALLOCATION) || gbuf == nullptr) {
if (mReportRemovedBuffers && (gbuf != nullptr)) {
mRemovedBuffers.push_back(gbuf);
}
result = mGraphicBufferProducer->requestBuffer(buf, &gbuf);
if (result != NO_ERROR) {
ALOGE("dequeueBuffer: IGraphicBufferProducer::requestBuffer failed: %d", result);
mGraphicBufferProducer->cancelBuffer(buf, fence);
return result;
}
}
if (fence->isValid()) {
*fenceFd = fence->dup();
if (*fenceFd == -1) {
ALOGE("dequeueBuffer: error duping fence: %d", errno);
// dup() should never fail; something is badly wrong. Soldier on
// and hope for the best; the worst that should happen is some
// visible corruption that lasts until the next frame.
}
} else {
*fenceFd = -1;
}
*buffer = gbuf.get();
if (mSharedBufferMode && mAutoRefresh) {
mSharedBufferSlot = buf;
mSharedBufferHasBeenQueued = false;
} else if (mSharedBufferSlot == buf) {
mSharedBufferSlot = BufferItem::INVALID_BUFFER_SLOT;
mSharedBufferHasBeenQueued = false;
}
return OK;
}- 拿到Buffer后,首先是timestamp的处理,记录一下dequeue的时间。
- 从Surface的mSlots中根据buffer序号,取出GraphicsBuffer gbuf。如果gbuf没有,或者需要重新分配,再次通过BufferQueuerProducer的requestBuffer来完成。
- 最后是fenceFd的获取,根据Buffer的Fence,dup获得。
前面BufferQueuerProducer去dequeueBuffer时,只拿回了buffer的序号,并没有GraphicBuffer过来。GraphicBuffer是通过这里的requestBuffer去获取到的。获取到后就直接保存在Surface的mSlots中,后续就不用再去request了。需要主要的是,这里并不是拷贝GraphicBuffer的内容,BufferQueue 是不会复制Buffer内容的;采用的是共享Buffer,Buffer基本都是通过句柄handle进行传递。
我们来看看requestBuffer~
status_t BufferQueueProducer::requestBuffer(int slot, sp<GraphicBuffer>* buf) {
ATRACE_CALL();
BQ_LOGV("requestBuffer: slot %d", slot);
Mutex::Autolock lock(mCore->mMutex);
... ...
mSlots[slot].mRequestBufferCalled = true;
*buf = mSlots[slot].mGraphicBuffer;
return NO_ERROR;
}BufferQueueProducer的requestBuffer挺简单,直接根据buffer的序号,返回BufferQueueCore mSlots中对应的GraphicBuffer。
requestBuffer需要传一个GraphicBuffer,这就比较大了,现在的显示屏分辨率都很好,一个Buffer就几兆了,这就是为什么dequeue时不直接传Buffer的原因。
requestBuffer的binder逻辑,值得一看~
class BpGraphicBufferProducer : public BpInterface<IGraphicBufferProducer>
{
public:
explicit BpGraphicBufferProducer(const sp<IBinder>& impl)
: BpInterface<IGraphicBufferProducer>(impl)
{
}
virtual status_t requestBuffer(int bufferIdx, sp<GraphicBuffer>* buf) {
Parcel data, reply;
data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor());
data.writeInt32(bufferIdx);
status_t result =remote()->transact(REQUEST_BUFFER, data, &reply);
if (result != NO_ERROR) {
return result;
}
bool nonNull = reply.readInt32();
if (nonNull) {
*buf = new GraphicBuffer();
result = reply.read(**buf);
if(result != NO_ERROR) {
(*buf).clear();
return result;
}
}
result = reply.readInt32();
return result;
}Bp端通过REQUEST_BUFFER transact到Bn端,Bp端new一个GraphicBuffer,再将Bn端的GraphicBuffer 读过来,构成Bp端的Bufer。到达到这个目的,GraphicBuffer需要继承Flattenable,能够将GraphicBuffer序列化和反序列化,以实现Binder的传输。
status_t BnGraphicBufferProducer::onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
switch(code) {
case REQUEST_BUFFER: {
CHECK_INTERFACE(IGraphicBufferProducer, data, reply);
int bufferIdx = data.readInt32();
sp<GraphicBuffer> buffer;
int result = requestBuffer(bufferIdx, &buffer);
reply->writeInt32(buffer != 0);
if (buffer != 0) {
reply->write(*buffer);
}
reply->writeInt32(result);
return NO_ERROR;
}Bn端将Buffer写到reply中,Bp端冲reply中读。
到此,dequeueBuffer流程完了,我们来看看dequeue的流程图:
queueBuffer处理
App拿到Buffer后,将往Buffer里面绘制各自的数据,我们的测试应用中,绘制都非常简单。这里就不看了。我们来看绘制完成后,绘制的数据是怎么送去合成显示的。
queueBuffer我们直接从Surface的queueBuffer开始看,ANativeWindow前面的流程都类似。
int Surface::queueBuffer(android_native_buffer_t* buffer, int fenceFd) {
ATRACE_CALL();
ALOGV("Surface::queueBuffer");
Mutex::Autolock lock(mMutex);
int64_t timestamp;
bool isAutoTimestamp = false;
if (mTimestamp == NATIVE_WINDOW_TIMESTAMP_AUTO) {
timestamp = systemTime(SYSTEM_TIME_MONOTONIC);
isAutoTimestamp = true;
ALOGV("Surface::queueBuffer making up timestamp: %.2f ms",
timestamp / 1000000.0);
} else {
timestamp = mTimestamp;
}
int i = getSlotFromBufferLocked(buffer);
... ...getSlotFromBufferLocked,dequeue时,根据buffer序号取Buffer;queue时,是根据Buffer去找序号,根据Buffer的handle去找的。
int Surface::queueBuffer(android_native_buffer_t* buffer, int fenceFd) {
... ...
// Make sure the crop rectangle is entirely inside the buffer.
Rect crop(Rect::EMPTY_RECT);
mCrop.intersect(Rect(buffer->width, buffer->height), &crop);
sp<Fence> fence(fenceFd >= 0 ? new Fence(fenceFd) : Fence::NO_FENCE);
IGraphicBufferProducer::QueueBufferOutput output;
IGraphicBufferProducer::QueueBufferInput input(timestamp, isAutoTimestamp,
mDataSpace, crop, mScalingMode, mTransform ^ mStickyTransform,
fence, mStickyTransform, mEnableFrameTimestamps);
if (mConnectedToCpu || mDirtyRegion.bounds() == Rect::INVALID_RECT) {
input.setSurfaceDamage(Region::INVALID_REGION);
} else {
int width = buffer->width;
int height = buffer->height;
bool rotated90 = (mTransform ^ mStickyTransform) &
NATIVE_WINDOW_TRANSFORM_ROT_90;
if (rotated90) {
std::swap(width, height);
}
Region flippedRegion;
for (auto rect : mDirtyRegion) {
int left = rect.left;
int right = rect.right;
int top = height - rect.bottom; // Flip from OpenGL convention
int bottom = height - rect.top; // Flip from OpenGL convention
switch (mTransform ^ mStickyTransform) {
case NATIVE_WINDOW_TRANSFORM_ROT_90: {
// Rotate 270 degrees
Rect flippedRect{top, width - right, bottom, width - left};
flippedRegion.orSelf(flippedRect);
break;
}
case NATIVE_WINDOW_TRANSFORM_ROT_180: {
// Rotate 180 degrees
Rect flippedRect{width - right, height - bottom,
width - left, height - top};
flippedRegion.orSelf(flippedRect);
break;
}
case NATIVE_WINDOW_TRANSFORM_ROT_270: {
// Rotate 90 degrees
Rect flippedRect{height - bottom, left,
height - top, right};
flippedRegion.orSelf(flippedRect);
break;
}
default: {
Rect flippedRect{left, top, right, bottom};
flippedRegion.orSelf(flippedRect);
break;
}
}
}
input.setSurfaceDamage(flippedRegion);
}- mCrop,用以剪切Buffer的,mCrop不能超过buffer的大小~也就是说,我们的buffer可以只显示一部分。
- queueBuffer封装了两个对象QueueBufferInput和QueueBufferOutput,一个是queueBuffer时的输入,已给是返回值。
- flippedRegion,Opengl里面采用是坐标系是左下为远点,而Graphic&Display子系统中采用左上为远点,所以这里需要做一下倒转。另外,受transform的影响,这里也需要统一一下。
- SurfaceDamage,受损区域,表示Surface也就是Buffer的那些个区域被更新了。支持部分更新。
int Surface::queueBuffer(android_native_buffer_t* buffer, int fenceFd) {
... ...
nsecs_t now = systemTime();
status_t err = mGraphicBufferProducer->queueBuffer(i, input, &output);
mLastQueueDuration = systemTime() - now;
if (err != OK) {
ALOGE("queueBuffer: error queuing buffer to SurfaceTexture, %d", err);
}
if (mEnableFrameTimestamps) {
mFrameEventHistory->applyDelta(output.frameTimestamps);
mFrameEventHistory->updateAcquireFence(mNextFrameNumber,
std::make_shared<FenceTime>(std::move(fence)));
mFrameEventHistory->updateSignalTimes();
}
mLastFrameNumber = mNextFrameNumber;
mDefaultWidth = output.width;
mDefaultHeight = output.height;
mNextFrameNumber = output.nextFrameNumber;
... ...
return err;
}queueBuffer的实现也是在GraphicBufferProducer中完成的。queue完成后,会更新一些默认的数据mDefaultWidth和mDefaultHeight。mNextFrameNumber是Frame的number,以及timestamp。
BufferQueueProducer的queueBuffer也是一个几百行的函数~
QueueBufferInput其实就是对Buffer的描述的封装,通过QueueBufferInput能在Binder中进行传输。因此在queueBuffer函数中,现将QueueBufferInput deflate出来。
status_t BufferQueueProducer::queueBuffer(int slot,
const QueueBufferInput &input, QueueBufferOutput *output) {
ATRACE_CALL();
ATRACE_BUFFER_INDEX(slot);
int64_t requestedPresentTimestamp;
bool isAutoTimestamp;
android_dataspace dataSpace;
Rect crop(Rect::EMPTY_RECT);
int scalingMode;
uint32_t transform;
uint32_t stickyTransform;
sp<Fence> acquireFence;
bool getFrameTimestamps = false;
input.deflate(&requestedPresentTimestamp, &isAutoTimestamp, &dataSpace,
&crop, &scalingMode, &transform, &acquireFence, &stickyTransform,
&getFrameTimestamps);
const Region& surfaceDamage = input.getSurfaceDamage();
if (acquireFence == NULL) {
BQ_LOGE("queueBuffer: fence is NULL");
return BAD_VALUE;
}
auto acquireFenceTime = std::make_shared<FenceTime>(acquireFence);
switch (scalingMode) {
case NATIVE_WINDOW_SCALING_MODE_FREEZE:
case NATIVE_WINDOW_SCALING_MODE_SCALE_TO_WINDOW:
case NATIVE_WINDOW_SCALING_MODE_SCALE_CROP:
case NATIVE_WINDOW_SCALING_MODE_NO_SCALE_CROP:
break;
default:
BQ_LOGE("queueBuffer: unknown scaling mode %d", scalingMode);
return BAD_VALUE;
}- requestedPresentTimestamp分两中情况,一种是自动的,另外一种是应用控制的。如果是自动的,那就是queueBuffer时是时间
timestamp = systemTime(SYSTEM_TIME_MONOTONIC。 - android_dataspace是数据空间,新增加的特性~
- fence可以是NO_FENCE,但是不能是空指针
- scalingmode,Video播放,或者camera预览的时候用的比较多。当显示的内容和屏幕的大小不成比例时,采用什么处理方式。SCALE_TO_WINDOW就是根据window的大小,缩放buffer,buffer的内容能被显示全;SCALE_CROP,根据窗口大小,截取buffer,部分buffer的内容就不能显示出来。
继续往下看:
status_t BufferQueueProducer::queueBuffer(int slot,
const QueueBufferInput &input, QueueBufferOutput *output) {
... ...
sp<IConsumerListener> frameAvailableListener;
sp<IConsumerListener> frameReplacedListener;
int callbackTicket = 0;
uint64_t currentFrameNumber = 0;
BufferItem item;
{ // Autolock scope
Mutex::Autolock lock(mCore->mMutex);
... ...//判断buffer的有效性
const sp<GraphicBuffer>& graphicBuffer(mSlots[slot].mGraphicBuffer);
Rect bufferRect(graphicBuffer->getWidth(), graphicBuffer->getHeight());
Rect croppedRect(Rect::EMPTY_RECT);
crop.intersect(bufferRect, &croppedRect);
if (croppedRect != crop) {
BQ_LOGE("queueBuffer: crop rect is not contained within the "
"buffer in slot %d", slot);
return BAD_VALUE;
}
// Override UNKNOWN dataspace with consumer default
if (dataSpace == HAL_DATASPACE_UNKNOWN) {
dataSpace = mCore->mDefaultBufferDataSpace;
}
mSlots[slot].mFence = acquireFence;
mSlots[slot].mBufferState.queue();
// Increment the frame counter and store a local version of it
// for use outside the lock on mCore->mMutex.
++mCore->mFrameCounter;
currentFrameNumber = mCore->mFrameCounter;
mSlots[slot].mFrameNumber = currentFrameNumber;
item.mAcquireCalled = mSlots[slot].mAcquireCalled;
item.mGraphicBuffer = mSlots[slot].mGraphicBuffer;
item.mCrop = crop;
item.mTransform = transform &
~static_cast<uint32_t>(NATIVE_WINDOW_TRANSFORM_INVERSE_DISPLAY);
item.mTransformToDisplayInverse =
(transform & NATIVE_WINDOW_TRANSFORM_INVERSE_DISPLAY) != 0;
item.mScalingMode = static_cast<uint32_t>(scalingMode);
item.mTimestamp = requestedPresentTimestamp;
item.mIsAutoTimestamp = isAutoTimestamp;
item.mDataSpace = dataSpace;
item.mFrameNumber = currentFrameNumber;
item.mSlot = slot;
item.mFence = acquireFence;
item.mFenceTime = acquireFenceTime;
item.mIsDroppable = mCore->mAsyncMode ||
mCore->mDequeueBufferCannotBlock ||
(mCore->mSharedBufferMode && mCore->mSharedBufferSlot == slot);
item.mSurfaceDamage = surfaceDamage;
item.mQueuedBuffer = true;
item.mAutoRefresh = mCore->mSharedBufferMode && mCore->mAutoRefresh;
mStickyTransform = stickyTransform;
// Cache the shared buffer data so that the BufferItem can be recreated.
if (mCore->mSharedBufferMode) {
mCore->mSharedBufferCache.crop = crop;
mCore->mSharedBufferCache.transform = transform;
mCore->mSharedBufferCache.scalingMode = static_cast<uint32_t>(
scalingMode);
mCore->mSharedBufferCache.dataspace = dataSpace;
}
output->bufferReplaced = false;
if (mCore->mQueue.empty()) {
// When the queue is empty, we can ignore mDequeueBufferCannotBlock
// and simply queue this buffer
mCore->mQueue.push_back(item);
frameAvailableListener = mCore->mConsumerListener;
} else {
// When the queue is not empty, we need to look at the last buffer
// in the queue to see if we need to replace it
const BufferItem& last = mCore->mQueue.itemAt(
mCore->mQueue.size() - 1);
if (last.mIsDroppable) {
if (!last.mIsStale) {
... ...
}
// Overwrite the droppable buffer with the incoming one
mCore->mQueue.editItemAt(mCore->mQueue.size() - 1) = item;
frameReplacedListener = mCore->mConsumerListener;
} else {
mCore->mQueue.push_back(item);
frameAvailableListener = mCore->mConsumerListener;
}
}
mCore->mBufferHasBeenQueued = true;
mCore->mDequeueCondition.broadcast();
mCore->mLastQueuedSlot = slot;
output->width = mCore->mDefaultWidth;
output->height = mCore->mDefaultHeight;
output->transformHint = mCore->mTransformHint;
output->numPendingBuffers = static_cast<uint32_t>(mCore->mQueue.size());
output->nextFrameNumber = mCore->mFrameCounter + 1;
ATRACE_INT(mCore->mConsumerName.string(),
static_cast<int32_t>(mCore->mQueue.size()));
mCore->mOccupancyTracker.registerOccupancyChange(mCore->mQueue.size());
// Take a ticket for the callback functions
callbackTicket = mNextCallbackTicket++;
VALIDATE_CONSISTENCY();
} // Autolock scope- 根据序号将GraphicBuffer取出来,不要怀疑,应用使用的graphicBuffer也是从mSlots中获取过去的。
- Bufferqueue中,用BufferItem来描述buffer,GraphicBuffer以及描述,都封装在BuferItem中。
- 封装好的BufferItem,push到mQueue中
- Buffer 好了,可以消费了,Listener可以工作了, frameAvailableListener
- Occupancy,用来告诉内存统计,这里占用的内存大小
这里没有太复杂的逻辑,关键是要理解这些属性所表示的实际意义
status_t BufferQueueProducer::queueBuffer(int slot,
const QueueBufferInput &input, QueueBufferOutput *output) {
... ...
int connectedApi;
sp<Fence> lastQueuedFence;
{ // scope for the lock
Mutex::Autolock lock(mCallbackMutex);
while (callbackTicket != mCurrentCallbackTicket) {
mCallbackCondition.wait(mCallbackMutex);
}
if (frameAvailableListener != NULL) {
frameAvailableListener->onFrameAvailable(item);
} else if (frameReplacedListener != NULL) {
frameReplacedListener->onFrameReplaced(item);
}
connectedApi = mCore->mConnectedApi;
lastQueuedFence = std::move(mLastQueueBufferFence);
mLastQueueBufferFence = std::move(acquireFence);
mLastQueuedCrop = item.mCrop;
mLastQueuedTransform = item.mTransform;
++mCurrentCallbackTicket;
mCallbackCondition.broadcast();
}
// Wait without lock held
if (connectedApi == NATIVE_WINDOW_API_EGL) {
// Waiting here allows for two full buffers to be queued but not a
// third. In the event that frames take varying time, this makes a
// small trade-off in favor of latency rather than throughput.
lastQueuedFence->waitForever("Throttling EGL Production");
}
// Update and get FrameEventHistory.
nsecs_t postedTime = systemTime(SYSTEM_TIME_MONOTONIC);
NewFrameEventsEntry newFrameEventsEntry = {
currentFrameNumber,
postedTime,
requestedPresentTimestamp,
std::move(acquireFenceTime)
};
addAndGetFrameTimestamps(&newFrameEventsEntry,
getFrameTimestamps ? &output->frameTimestamps : nullptr);
return NO_ERROR;
}- frameAvailableListener,通知消费者,Buffer可以消费了。记住这里,我们后续消费Buffer的流程从这里开始看。
- lastQueuedFence,上一帧queue的Buffer的Fence
- lastQueuedFence->waitForever,这里可能会比较耗时。Android在8.0及以后的版本,对fence的管理加强了,如果HAL实现的不好,这里会等很长时间。这个lastQueuedFence是上一针的acquireFence,acquirefence是绘制,一般是GPU那边signal的,表示绘制已经完成。如果上一帧的fence一直没有signal,说明上一帧一直没有绘制完成,等在这里也是有道理的。当然有些芯片商的实现不太好,可能没有完全理解Android的设计,实现的时候难免会造成不必要的block。
queueBuffer完成,相比dequeueBuffer,逻辑简单一些,也就是将数据传过来,封装成BufferItem,push到BufferQueueCore的mQueue中,再通过frameAvailableListener通知消费者去消费。创建Layer时,我们看过,frameAvailableListener是Consumer那边设置过来的。
Buffer状态
对于生产者这边,BufferQueue的流程基本讲完了。简单说来,首先提需求,告诉BufferQueue需要什么样的Buffer,大小,格式,usage等等;然后dequeue Buffer出来,往Buffer里面绘制显示数据;绘制完成后,queue到BufferQueue里面,并通知消费者进行消费。如此不断的的dequeue,绘制,queue。
消费者这边的流程,我们还没有讲到。对于消费者来说,收到通知后,将从BufferQueue里面取queue过来的Buffer进行合成,合成完的Buffer再释放掉,这里的释放,是概念上的,并没有真正释放内存,只是让其返回队列,可以被再次dequeue。消费者这边也是不断的接通知,取buffer合成,然后释放,不断循环。
此图是Android官网对BufferQueue通信过程的描述,这很好的描述这个过程。
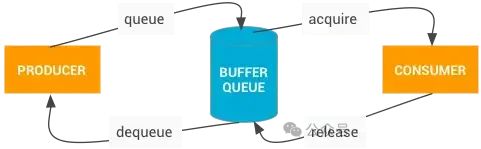
在Android 6.0及之前的版本,在这些通信过程中,都将Buffer的状态标记为具体的状态。这四个过程Buffer分别对应不同的四个状态:
DEQUEUED 状态
Producer dequeue一个Buffer后,这个Buffer就变为DEQUEUED状态,release Fence发信号后,Producer就可以修改Buffer的内容,我们称为release Fence。此时Buffer被Producer占用。DEQUEUED状态的Buffer可以迁移到 QUEUED 状态,通过queueBuffer或attachBuffer流程。也可以迁移到FREE装,通过cancelBuffer或detachBuffer流程。QUEUED 状态
Buffer绘制完后,queue到BufferQueue中,给Consumer进行消费。此时Buffer可能还没有真正绘制完成,必现要等对应的Fence发信号出来后,才真正完成。此时Buffer是BufferQueue持有,可以迁移到ACQUIRED状态,通过acquireBuffer流程。而已可以迁移到FREE状态,如果另外一个Buffer被异步的queue进来。ACQUIRED 状态
Buffer已经被Consumer获取,但是也必须要等对应的Fence发信号才能被Consumer读写,找个Fence是从Producer那边,queueBuffer的时候传过来的。我们将其称为acquire fence。此时,Buffer被Consumer持有。状态可以迁移到FREE状态,通过releaseBuffer或detachBuffer流程。除了从acquireBuffer流程可以迁移到ACQUIRED状态,attachBuffer流程也可以迁移到ACQUIRED状态。FREE 状态
FREE状态,说明Buffer被BufferQueue持有,可以被Producer dequeue,它将迁移到DEQUEUED状态,通过dequeueBuffer流程。SHARED状态
SHARED状态是一个特殊的状态,SHARED的Buffer并不参与前面所说的状态迁移。它说明Buffer被用与共享Buffer模式。除了FREE状态,它可以是其他的任何状态。它可以被多次dequeued, queued, 或者 acquired。这中共享Buffer的模式,主要用于VR等低延迟要求的场合。
目前,Buffer的状态,都是通过各个状态的Buffer的量来表示状态,对应的关系如下:
| Buffer状态 | mShared | mDequeueCount | mQueueCount | mAcquireCount |
|---|---|---|---|---|
| FREE | false | 0 | 0 | 0 |
| DEQUEUED | false | 1 | 0 | 0 |
| QUEUED | false | 0 | 1 | 0 |
| ACQUIRED | false | 0 | 0 | 1 |
| SHARED | true | any | any | any |
Buffer的状态在代码中用BufferState描述,BufferState的定义如下:
* frameworks/native/libs/gui/include/gui/BufferSlot.h
struct BufferState {
BufferState()
: mDequeueCount(0),
mQueueCount(0),
mAcquireCount(0),
mShared(false) {
}
uint32_t mDequeueCount;
uint32_t mQueueCount;
uint32_t mAcquireCount;
bool mShared;
... ...
};前面讲解dequeueBuffer和queueBuffer流程时,BufferQueue有很多个队列,我们再来看一下BufferQueue中,几个队列间的关系。
BufferQueueCore中的定义如下:
* frameworks/native/libs/gui/include/gui/BufferQueueCore.h
class BufferQueueCore : public virtual RefBase {
... ...
typedef Vector<BufferItem> Fifo;
... ...
// mSlots is an array of buffer slots that must be mirrored on the producer
// side. This allows buffer ownership to be transferred between the producer
// and consumer without sending a GraphicBuffer over Binder. The entire
// array is initialized to NULL at construction time, and buffers are
// allocated for a slot when requestBuffer is called with that slot's index.
BufferQueueDefs::SlotsType mSlots;
// mQueue is a FIFO of queued buffers used in synchronous mode.
Fifo mQueue;
// mFreeSlots contains all of the slots which are FREE and do not currently
// have a buffer attached.
std::set<int> mFreeSlots;
// mFreeBuffers contains all of the slots which are FREE and currently have
// a buffer attached.
std::list<int> mFreeBuffers;
// mUnusedSlots contains all slots that are currently unused. They should be
// free and not have a buffer attached.
std::list<int> mUnusedSlots;
// mActiveBuffers contains all slots which have a non-FREE buffer attached.
std::set<int> mActiveBuffers;mSlots
mSlots 是Buffer序号的一个数组,Producer端的mSlots也是这个mSlots,Consumer端是mSlots也是里的mSlots的引用。它可实现Buffer在Producer和Consumer之间转移,而不需要真正的在Binder间去传输一个GraphicBuffer。初始状态时为空,当requestBuffer流程执行时,将去为对应的Buffer序号,分配真正的Buffer。mQueue
mQueue是一个先进先出的Vector,是同步模式下使用。里面就是处于QUEUED状态的Buffer。mFreeSlots
mFreeSlots包含所有是FREE状态,且还没有分配Buffer的,Buffer序号集合。刚开始时,mFreeSlots被初始化为MaxBufferCount个Buffer序号集合,dequeueBuffer的时候,将先从这个集合中获取。但是消费者消费完成,释放的Buffer并不返回到这个队列中,而是返回到mFreeBuffers中。mFreeBuffers
mFreeBuffers包含的是所有FREE状态,且已经分配Buffer的,Buffer序号的结合。消费者消费完成,释放的Buffer并不返回到这个队列中,而是返回到mFreeBuffers中。mUnusedSlots
mUnusedSlots和mFreeSlots有些相似,只是mFreeSlots会被用到,而mUnusedSlots中的Buffer序号不会不用到。也就是,总的Buffer序号NUM_BUFFER_SLOTS中,除去MaxBufferCount个mFreeSlots,剩余的集合。mActiveBuffers
mActiveBuffers包含所有非FREE状态的Buffer。也就是包含了DEQUEUED,QUEUED,ACQUIRED以及SHARED这几个状态的。
我们从数学的角度来看看他们之间的关系:
mSlots的数组大小为NUM_BUFFER_SLOTS,但是其中,真正用起来的也只有MaxBufferCount个,其他的都不会被用到。所以,我们可以这么理解,mSlots是BufferQueue中实际流转起来的Buffer。
mSlots = mFreeBuffers + mActiveBuffers对于整体而言:
NUM_BUFFER_SLOTS = mUnusedSlots + mFreeSlots + mFreeBuffers + mActiveBuffersmSlots是BufferSlot的集合,BufferSlot定义如下:
struct BufferSlot {
BufferSlot()
: mGraphicBuffer(nullptr),
mEglDisplay(EGL_NO_DISPLAY),
mBufferState(),
mRequestBufferCalled(false),
mFrameNumber(0),
mEglFence(EGL_NO_SYNC_KHR),
mFence(Fence::NO_FENCE),
mAcquireCalled(false),
mNeedsReallocation(false) {
}
// Buffer序号对应的Buffer
sp<GraphicBuffer> mGraphicBuffer;
// 创建EGLSyncKHR对象用
EGLDisplay mEglDisplay;
// Buffer序号当前的状态
BufferState mBufferState;
// mRequestBufferCalled 表示Producer确实已经调用requestBuffer
bool mRequestBufferCalled;
// mFrameNumber 表示该Buffer序号已经被queue的次数. 主要用于dequeueBuffer时,遵从LRU,这很有用,因为buffer 变FREE时,可能release Fence还没有发信号出来。
uint64_t mFrameNumber;
// 现在已经被mFence替换了,基本不用
EGLSyncKHR mEglFence;
// mFence 是同步的一种方式,上一个owner使用完Buffer后,需要发信号出来,下一个owner才可以使用。
sp<Fence> mFence;
// 表示Buffer已经被Consumer取走
bool mAcquireCalled;
// 表示Buffer需要重新分配,需要设置BUFFER_NEEDS_REALLOCATION 通知Producer,不要用原来的缓存的Buffer
bool mNeedsReallocation;
};看完Buffer的状态后,再回头去看看前面介绍的dequeueBuffer和queueBuffer,是不是就很好理解了。
我们再来看看BufferQueue的工作模式,BufferQueue可以工作在几个模式:
- 同步模式 Synchronous-like mode
默认情况下,BufferQueue将工作在同步模式下。在该模式下,每个Buffer都从Producer进入,从Consumer退出,没有Buffer没有丢弃掉。如果Producer生产的太快,Consumer来不及消费,Producer将阻塞等待FREE的Buffer。前面的分析流程的时候在waitForFreeSlotThenRelock也说到了这点。
这是waitForFreeSlotThenRelock函数中的逻辑:
if (mDequeueTimeout >= 0) {
status_t result = mCore->mDequeueCondition.waitRelative(
mCore->mMutex, mDequeueTimeout);
if (result == TIMED_OUT) {
return result;
}
} else {
mCore->mDequeueCondition.wait(mCore->mMutex);
}- 非同步模式 Non-blocking mode
和同步模式相反,BufferQueue工作在非阻塞模式下,在这种模式下,如果没有FREE Buffer,将生成一个错误,而不是阻塞等待FREE的Buffer。这种模式,也没有Buffer不丢弃。这中模式可以避免潜在的死锁,如果应用不理解Graphics框架中复杂的依赖条件。前面我们的代码分析中也看到这一点。waitForFreeSlotThenRelock什么时候不去tryAgain?
if (tryAgain) {
if ((mCore->mDequeueBufferCannotBlock || mCore->mAsyncMode) &&
(acquiredCount <= mCore->mMaxAcquiredBufferCount)) {
return WOULD_BLOCK;
}mAsyncMode是通过BufferQueueProducer的setAsyncMode函数设置的,从Producer调用过来,受Producer控制。
mDequeueBufferCannotBlock则是在Producer 连接到BufferQueue时,根据条件判断的,具体逻辑如下:
status_t BufferQueueProducer::connect(const sp<IProducerListener>& listener,
int api, bool producerControlledByApp, QueueBufferOutput *output) {
... ...
if (mDequeueTimeout < 0) {
mCore->mDequeueBufferCannotBlock =
mCore->mConsumerControlledByApp && producerControlledByApp;
}
mCore->mAllowAllocation = true;
VALIDATE_CONSISTENCY();
return status;
}舍弃模式 Discard mode
BufferQueue可以配置为丢弃旧Buffer,而不是生成错误或进行等待。比如,如果用GL对纹理进行快速的绘制,那么旧的Buffer不要丢弃。共享Buffer模式 shared buffer mode
共享Buffer模式,表示Buffer是Producer和Consumer共享。共享Buffer模式下,一直用的都是同一个Buffer。而Buffer的状态不能迁移为FREE状态。代码中可以留意mCore->mSharedBufferMode和mCore->mSharedBufferSlot。这个模式其实也包含在同步模式中,只是比较特殊,单独说一下。
现在,再回头去看看前面介绍的dequeueBuffer和queueBuffer,是不是就更好理解了。
acquireBuffer流程
Buffer queue到BufferQueue中后,将通知消费者去消费。消费时,通过acquireBuffer来获取Buffer,我们且不管acquireBuffer是什么地方调的,我们先来看BufferQueue中acquireBuffer的处理流程。
* frameworks/native/libs/gui/BufferQueueConsumer.cpp
status_t BufferQueueConsumer::acquireBuffer(BufferItem* outBuffer,
nsecs_t expectedPresent, uint64_t maxFrameNumber) {
ATRACE_CALL();
int numDroppedBuffers = 0;
sp<IProducerListener> listener;
{
Mutex::Autolock lock(mCore->mMutex);
int numAcquiredBuffers = 0;
for (int s : mCore->mActiveBuffers) {
if (mSlots[s].mBufferState.isAcquired()) {
++numAcquiredBuffers;
}
}
if (numAcquiredBuffers >= mCore->mMaxAcquiredBufferCount + 1) {
BQ_LOGE("acquireBuffer: max acquired buffer count reached: %d (max %d)",
numAcquiredBuffers, mCore->mMaxAcquiredBufferCount);
return INVALID_OPERATION;
}
bool sharedBufferAvailable = mCore->mSharedBufferMode &&
mCore->mAutoRefresh && mCore->mSharedBufferSlot !=
BufferQueueCore::INVALID_BUFFER_SLOT;
// In asynchronous mode the list is guaranteed to be one buffer deep,
// while in synchronous mode we use the oldest buffer.
if (mCore->mQueue.empty() && !sharedBufferAvailable) {
return NO_BUFFER_AVAILABLE;
}- acquireBuffer时,也是受mCore->mMutex控制的。
- numAcquiredBuffers,已经acquired的Buffer。mMaxAcquiredBufferCount最大可以acquire的Buffer,可以溢出一个,以便Consumer能方便替换旧的Buffer,如果旧的Buffer还没有释放时。
- sharedBufferAvailable,共享Buffer模式下使用。在这个模式下,mAutoRefresh表示,Consumer永远可以acquire到一块Buffer,即使BufferQueue还没有处于可以acquire的状态。
- mQueue,如没有Buffer被queue过来,mQueue为空,那么Consumer这边就acquire不到新的Buffer,Consumer这边已经acquire的会被继续使用。
如果有Buffer或是共享Buffer模式,继续~
* frameworks/native/libs/gui/BufferQueueConsumer.cpp
BufferQueueCore::Fifo::iterator front(mCore->mQueue.begin());
if (expectedPresent != 0 && !mCore->mQueue.empty()) {
const int MAX_REASONABLE_NSEC = 1000000000ULL; // 1 second
while (mCore->mQueue.size() > 1 && !mCore->mQueue[0].mIsAutoTimestamp) {
const BufferItem& bufferItem(mCore->mQueue[1]);
// If dropping entry[0] would leave us with a buffer that the
// consumer is not yet ready for, don't drop it.
if (maxFrameNumber && bufferItem.mFrameNumber > maxFrameNumber) {
break;
}
if (desiredPresent < expectedPresent - MAX_REASONABLE_NSEC ||
desiredPresent > expectedPresent) {
// This buffer is set to display in the near future, or
// desiredPresent is garbage. Either way we don't want to drop
// the previous buffer just to get this on the screen sooner.
BQ_LOGV("acquireBuffer: nodrop desire=%" PRId64 " expect=%"
PRId64 " (%" PRId64 ") now=%" PRId64,
desiredPresent, expectedPresent,
desiredPresent - expectedPresent,
systemTime(CLOCK_MONOTONIC));
break;
}
BQ_LOGV("acquireBuffer: drop desire=%" PRId64 " expect=%" PRId64
" size=%zu",
desiredPresent, expectedPresent, mCore->mQueue.size());
if (!front->mIsStale) {
// Front buffer is still in mSlots, so mark the slot as free
mSlots[front->mSlot].mBufferState.freeQueued();
if (!mCore->mSharedBufferMode &&
mSlots[front->mSlot].mBufferState.isFree()) {
mSlots[front->mSlot].mBufferState.mShared = false;
}
// Don't put the shared buffer on the free list
if (!mSlots[front->mSlot].mBufferState.isShared()) {
mCore->mActiveBuffers.erase(front->mSlot);
mCore->mFreeBuffers.push_back(front->mSlot);
}
listener = mCore->mConnectedProducerListener;
++numDroppedBuffers;
}
mCore->mQueue.erase(front);
front = mCore->mQueue.begin();
}
bool bufferIsDue = desiredPresent <= expectedPresent ||
desiredPresent > expectedPresent + MAX_REASONABLE_NSEC;
bool consumerIsReady = maxFrameNumber > 0 ?
front->mFrameNumber <= maxFrameNumber : true;
if (!bufferIsDue || !consumerIsReady) {
return PRESENT_LATER;
}
}这里主要做了一些几件事:
- expectedPresent 期望被显示的时间
也就是这个Buffer希望在什么时候被显示到屏幕上。如果Buffer的DesiredPresent的时间早于这个时间,那么这个Buffer将被准时显示。或者稍晚才被显示,如果我们不想显示直到expectedPresent时间之后,我们返回PRESENT_LATER,不去acquire它。但是如果时间在一秒之内,就不会延迟了,直接acquire回去。 - 检查是否需要丢弃一些帧
如果是Surface自动生成的时间,就不去检查是否需要丢弃掉一些帧,这些Surface对显示时间是没有严格的要求的。如果mQueue中有多个Buffer,我们将丢掉一些queue过来比较早的Buffer。如果最近queue的Buffer,离期望显示的时间已经没有一秒了,那之前queue过来的Buffer都将被丢弃掉。这很好理解,你好比你要买一款手机,新款的广告虽然来了,但是还有一段时间才能上市,你等不了这么就久,就先买就旧款了,总得用手机吧。但是,如果新款不到一秒就上市了,我们就稍微等会儿直接买新款,不买旧款了。
front->mIsStale,表示Buffer已经被释放了,这是在BufferQueueCore::freeAllBuffersLocked时置的位。此时,我们需要将Buffer都返回到BufferQueue FREE状态中。
该丢弃的丢弃了,余下的就可以用来去显示了。
* frameworks/native/libs/gui/BufferQueueConsumer.cpp
int slot = BufferQueueCore::INVALID_BUFFER_SLOT;
if (sharedBufferAvailable && mCore->mQueue.empty()) {
// make sure the buffer has finished allocating before acquiring it
mCore->waitWhileAllocatingLocked();
slot = mCore->mSharedBufferSlot;
// Recreate the BufferItem for the shared buffer from the data that
// was cached when it was last queued.
outBuffer->mGraphicBuffer = mSlots[slot].mGraphicBuffer;
outBuffer->mFence = Fence::NO_FENCE;
outBuffer->mFenceTime = FenceTime::NO_FENCE;
outBuffer->mCrop = mCore->mSharedBufferCache.crop;
outBuffer->mTransform = mCore->mSharedBufferCache.transform &
~static_cast<uint32_t>(
NATIVE_WINDOW_TRANSFORM_INVERSE_DISPLAY);
outBuffer->mScalingMode = mCore->mSharedBufferCache.scalingMode;
outBuffer->mDataSpace = mCore->mSharedBufferCache.dataspace;
outBuffer->mFrameNumber = mCore->mFrameCounter;
outBuffer->mSlot = slot;
outBuffer->mAcquireCalled = mSlots[slot].mAcquireCalled;
outBuffer->mTransformToDisplayInverse =
(mCore->mSharedBufferCache.transform &
NATIVE_WINDOW_TRANSFORM_INVERSE_DISPLAY) != 0;
outBuffer->mSurfaceDamage = Region::INVALID_REGION;
outBuffer->mQueuedBuffer = false;
outBuffer->mIsStale = false;
outBuffer->mAutoRefresh = mCore->mSharedBufferMode &&
mCore->mAutoRefresh;
} else {
slot = front->mSlot;
*outBuffer = *front;
}如果是共享Buffer模式,即使mQueue为空,也会把共享的Buffer返回去。其他情况下就返回,mQueue的第一个Buffer。
* frameworks/native/libs/gui/BufferQueueConsumer.cpp
ATRACE_BUFFER_INDEX(slot);
if (!outBuffer->mIsStale) {
mSlots[slot].mAcquireCalled = true;
if (mCore->mQueue.empty()) {
mSlots[slot].mBufferState.acquireNotInQueue();
} else {
mSlots[slot].mBufferState.acquire();
}
mSlots[slot].mFence = Fence::NO_FENCE;
}
if (outBuffer->mAcquireCalled) {
outBuffer->mGraphicBuffer = NULL;
}
mCore->mQueue.erase(front);
mCore->mDequeueCondition.broadcast();
ATRACE_INT(mCore->mConsumerName.string(),
static_cast<int32_t>(mCore->mQueue.size()));
mCore->mOccupancyTracker.registerOccupancyChange(mCore->mQueue.size());
VALIDATE_CONSISTENCY();
}
if (listener != NULL) {
for (int i = 0; i < numDroppedBuffers; ++i) {
listener->onBufferReleased();
}
}
return NO_ERROR;
}acquire到Buffer后,修改mSlots中对应Buffer序号的mBufferState状态。acquire的Buffer,需要从mQueue中 删掉。留意这里的ATRACE_INT,这个在systrace分析时,非常有用。如果Buffer被丢弃了,可以通过Producer的监听者,去通知Producer Buffer已经被release掉了。
releaseBuffer流程分析
Consumer具体怎么消费的,我们暂时不管,我们先来看消费完成后,releaseBuffer的流程。
* frameworks/native/libs/gui/BufferQueueConsumer.cpp
status_t BufferQueueConsumer::releaseBuffer(int slot, uint64_t frameNumber,
const sp<Fence>& releaseFence, EGLDisplay eglDisplay,
EGLSyncKHR eglFence) {
ATRACE_CALL();
ATRACE_BUFFER_INDEX(slot);
if (slot < 0 || slot >= BufferQueueDefs::NUM_BUFFER_SLOTS ||
releaseFence == NULL) {
BQ_LOGE("releaseBuffer: slot %d out of range or fence %p NULL", slot,
releaseFence.get());
return BAD_VALUE;
}
sp<IProducerListener> listener;
{ // Autolock scope
Mutex::Autolock lock(mCore->mMutex);
// FrameNumber已经变,buffer已经被重新分配
if (frameNumber != mSlots[slot].mFrameNumber &&
!mSlots[slot].mBufferState.isShared()) {
return STALE_BUFFER_SLOT;
}
if (!mSlots[slot].mBufferState.isAcquired()) {
BQ_LOGE("releaseBuffer: attempted to release buffer slot %d "
"but its state was %s", slot,
mSlots[slot].mBufferState.string());
return BAD_VALUE;
}
mSlots[slot].mEglDisplay = eglDisplay;
mSlots[slot].mEglFence = eglFence;
mSlots[slot].mFence = releaseFence;
mSlots[slot].mBufferState.release();
if (!mCore->mSharedBufferMode && mSlots[slot].mBufferState.isFree()) {
mSlots[slot].mBufferState.mShared = false;
}
// Don't put the shared buffer on the free list.
if (!mSlots[slot].mBufferState.isShared()) {
mCore->mActiveBuffers.erase(slot);
mCore->mFreeBuffers.push_back(slot);
}
listener = mCore->mConnectedProducerListener;
BQ_LOGV("releaseBuffer: releasing slot %d", slot);
mCore->mDequeueCondition.broadcast();
VALIDATE_CONSISTENCY();
} // Autolock scope
// Call back without lock held
if (listener != NULL) {
listener->onBufferReleased();
}
return NO_ERROR;
}- release Buffer的流程相对简单,slot就是需要释放的Buffer的序号。
- Buffer的FrameNumber变了,可能Buffer已经重新分配,这个是不用管。
- 只能释放acquire状态的buffer序号,释放后是Buffer放会mFreeBuffers中。
- releaseFence,从Consumer那边传过来,Producer可以Dequeue mFreeBuffers中的Buffer,但是只有releaseFence发信号出来后,Consumer才真正用完,Producer才可以写。
- 同样的,可以通过listener通知Producer。
就这么多~~
小结
本章主要通过测试应用,讲解ANativeWindow,Surface间的关系,Surface和Producer,Consumer间的关系;P应用怎么使用BufferQueue。讲解了BufferQueue相关的几个流程,dequeueBuffer,queueBuffer,acquireBuffer,releaseBuffer;以及Buffer的状态,DEQUEUED,QUEUED,ACQUIRED,FREE迁移。
作者:夕月风
原文链接:https://www.jianshu.com/p/81e9c814f10a
参考文献:
【腾讯文档】Android Framework 知识库
https://docs.qq.com/doc/DSXBmSG9VbEROUXF5
至此,本篇已结束。转载网络的文章,小编觉得很优秀,欢迎点击阅读原文,支持原创作者,如有侵权,恳请联系小编删除,欢迎您的建议与指正。同时期待您的关注,感谢您的阅读,谢谢!
点个在看,为大佬点赞!















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









