







1. 堆排序
(1).堆
堆实际上是一棵完全二叉树,其任何一非叶节点满足性质:
Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]或者Key[i]>=Key[2i+1]&&key>=key[2i+2]
即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。
堆分为大顶堆和小顶堆,满足Key[i]>=Key[2i+1]&&key>=key[2i+2]称为大顶堆,满足 Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]称为小顶堆。由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。
(2).堆排序的思想
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。
其基本思想为(大顶堆):
1)将初始待排序关键字序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无序区;
2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n];
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
操作过程如下:
1)初始化堆:将R[1..n]构造为堆;
2)将当前无序区的堆顶元素R[1]同该区间的最后一个记录交换,然后将新的无序区调整为新的堆。
因此对于堆排序,最重要的两个操作就是构造初始堆和调整堆,其实构造初始堆事实上也是调整堆的过程,只不过构造初始堆是对所有的非叶节点都进行调整。
下面举例说明:
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。
首先根据该数组元素构建一个完全二叉树,得到
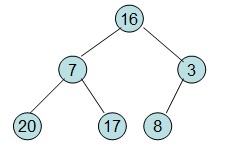


 20和16交换后导致16不满足堆的性质,因此需重新调整
20和16交换后导致16不满足堆的性质,因此需重新调整
 这样就得到了初始堆。
这样就得到了初始堆。
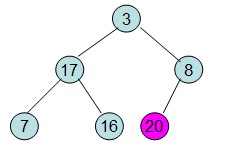 此时3位于堆顶不满堆的性质,则需调整继续调整
此时3位于堆顶不满堆的性质,则需调整继续调整









(以上分析出自http://www.cnblogs.com/dolphin0520/archive/2011/10/06/2199741.html)
(3)自己编写的C++程序:
#include <iostream>
#include<stdio.h>
using namespace std;
//堆排序
//整理节点time:O(lgn)
template<typename T>
void MaxHeapify(T *arry,int size,int element)
{
int lchild=element*2+1,rchild=lchild+1;//左右子树
while(rchild<size)//子树均在范围内
{
if(arry[element]>=arry[lchild]&&arry[element]>=arry[rchild])//如果比左右子树都大,完成整dada理
{
return;
}
if(arry[lchild]>=arry[rchild])//如果左边最大
{
swap(arry[element],arry[lchild]);//把左面的提到上面
element=lchild;//循环时整理子树
}
else//否则右面最大
{
swap(arry[element],arry[rchild]);//同理
element=rchild;
}
lchild=element*2+1;
rchild=lchild+1;//重新计算子树位置
}
if(lchild<size && arry[lchild]>arry[element])//只有左子树且子树大于自己
{
swap(arry[lchild],arry[element]);
}
return;
}
//堆排序time:O(nlgn)
template<typename T>
void HeapSort(T *arry,int size)
{
int i;
for(i=size-1;i>=0;i--)//从子树开始整理树
{
MaxHeapify(arry,size,i);
}
while(size>0)//拆除树
{
swap(arry[size-1],arry[0]);//将根(最大)与数组最末交换
size--;//树大小减小
MaxHeapify(arry,size,0);//整理树
}
return;
}
void main()
{
int a[7] = {9,6,4,3,2,2,10};
int a1[7];
int n = sizeof(a)/sizeof(int);
HeapSort(a,7);
for( int i=0;i<n;i++)
cout << a[i] << " ";
cout << endl;
system("pause");
}
2. 插入排序
(1)基本思想:
插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外,而第二部分就只包含这一个元素。在第一部分排序后,再把这个最后元素插入到此刻已是有序的第一部分里的位置
(2)具体算法描述如下:
⒈ 从第一个元素开始,该元素可以认为已经被排序
⒉ 取出下一个元素,在已经排序的元素序列中从后向前扫描
⒊ 如果该元素(已排序)大于新元素,将该元素移到下一位置
⒋ 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
⒌ 将新元素插入到下一位置中
⒍ 重复步骤2~5
(3)算法的性能:
算法适用于少量数据的排序,时间复杂度为O(n^2),是稳定的排序方法。
(4)伪代码:
INSERTION-SORT(A)
for j=2 to length[A]
do key=A[j]
//InsertA[j] into the sorted sequenceA[1..j-1].
i=j-1
while i>0 andA[i] >key
do A[i+1] =A[i]
i=i-1
A[i+1] =key
(4)C++:
#include <iostream>
#include<stdio.h>
using namespace std;
void insertion_sort(int *a, int n)
{
int j;
int key;
for( int i=1;i<n;i++)
{
key = a[i];
j = i - 1;
while(j>=0 && a[j]>key)
{
a[j+1] = a[j];
j = j - 1;
}
a[j+1] = key;
}
}
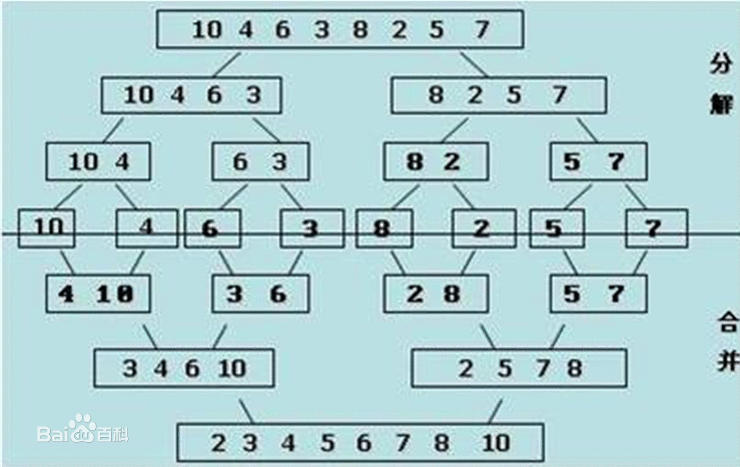
3. 归并排序
(1)基本思想
归并排序,其的基本思路就是将数组分成二组A,B,如果这二组组内的数据都是有序的,那么就可以很方便的将这二组数据进行排序。如何让这二组组内数据有序了?归并排序是建立在归并操作上的一种有效的排序算法。
该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
可以将A,B组各自再分成二组。依次类推,当分出来的小组只有一个数据时,可以认为这个小组组内已经达到了有序,然后再合并相邻的二个小组就可以了。这样通过先递归的分解数列,再合并数列就完成了归并排序。
归并过程为:比较a[i]和a[j]的大小,若a[i]≤a[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到r中从下标k到下标t的单元。
下面举例说明:
自己编写的C++代码:
#include <iostream>
#include<stdio.h>
using namespace std;
void merge(int a[], int a1[], int s , int m ,int n)
{
int i = s;
int j = m + 1 ;
int k = s;
while(i <= m && j <= n)
{
if(a[i]<a[j])
a1[k++] = a[i++];
else
a1[k++] = a[j++];
}
if(i<=m)
{
while(i<=m)
a1[k++] = a[i++];
}
else
{
while(j<=n)
a1[k++] = a[j++];
}
for(int t = s;t<=n;t++)
a[t] = a1[t];
}
void merge_sort(int a[], int a1[], int s , int n)
{
if( s<n )
{
int m = (s+n)/2;
merge_sort(a,a1,s,m);
merge_sort(a,a1,m+1,n);
merge(a,a1,s,m,n);
}
}
4. 非随机快速排序
(1)基本思想
快速排序(Quicksort)是对冒泡排序的一种改进。由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
举例说明:

(2)伪代码:
#include <iostream>
#include<stdio.h>
using namespace std;
int Partition(int *a,int p,int q)
{
int x = a[p];
int i = p;
int temp;
for(int j = p+1; j<=q; j++)
{
if(a[j]<=x)
{
i++;
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
temp = a[p];
a[p] = a[i];
a[i] = temp;
return i;
}
void Quicksort(int *a,int p,int q)
{
if( p < q )
{
int r = Partition(a,p,q);
Quicksort(a,p,r-1);
Quicksort(a,r+1,q);
}
}















 1068
1068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









