







目录
一、概述
MCP服务端当前支持两种与客户端的数据通信方式:标准输入输出(stdio) 和 基于Http的服务器推送事件(http sse)
1.1 标准输入输出(stdio)
原理: 标准输入输出是一种用于本地通信的传输方式。在这种模式下,MCP 客户端会将服务器程序作为子进程启动,双方通过约定的标准输入和标准输出(可能是通过共享文件等方法)进行数据交换。具体而言,客户端通过标准输入发送请求,服务器通过标准输出返回响应。。
适用场景: 标准输入输出方式适用于客户端和服务器在同一台机器上运行的场景(本地自行编写服务端或将别人编写的服务端代码pull到本地执行),确保了高效、低延迟的通信。这种直接的数据传输方式减少了网络延迟和传输开销,适合需要快速响应的本地应用。
1.2 基于Http的服务器推送事件(http sse)
原理: 客户端和服务端通过 HTTP 协议进行通信,利用 SSE 实现服务端向客户端的实时数据推送,服务端定义了/see与/messages接口用于推送与接收数据。这里要注意SSE协议和WebSocket协议的区别,SSE协议是单向的,客户端和服务端建立连接后,只能由服务端向客户端进行消息推送。而WebSocket协议客户端和服务端建立连接后,客户端可以通过send向服务端发送数据,并通过onmessage事件接收服务端传过来的数据。
适用场景: 适用于客户端和服务端位于不同物理位置的场景,尤其是对于分布式或远程部署的场景,基于 HTTP 和 SSE 的传输方式更合适。
二、MCP Server应用平台
这里面有很多已经开发好的mcp应用,可以拿来直接使用即可。
MCP Server平台发布的应用,80%以上,运行方式都是stdio,这种方式适合本地开发。
但是想在dify里面使用,一般都是sse方式,因为适合远程调用。即使是不同命名空间,不同的工作流依然可以调用,只要网络能联通,就没问题。
而且sse方式,只需要运行一次,就可以让成千上万个dify应用调用,还是很方便的。
三、python搭建mysql-mcp服务器
新建空目录Mysql_mcp_server_pro,新建2个文件.evn,server.py
.env文件内容如下:(替换你的实际信息)
MYSQL_HOST=192.168.20.128
MYSQL_PORT=3306
MYSQL_USER=root
MYSQL_PASSWORD=****
MYSQL_DATABASE=test这个是mysql连接信息
server.py
import os
import uvicorn
from mcp.server.sse import SseServerTransport
from mysql.connector import connect, Error
from mcp.server import Server
from mcp.types import Tool, TextContent
from starlette.applications import Starlette
from starlette.routing import Route, Mount
from dotenv import load_dotenv
def get_db_config():
"""从环境变量获取数据库配置信息
返回:
dict: 包含数据库连接所需的配置信息
- host: 数据库主机地址
- port: 数据库端口
- user: 数据库用户名
- password: 数据库密码
- database: 数据库名称
异常:
ValueError: 当必需的配置信息缺失时抛出
"""
# 加载.env文件
load_dotenv()
config = {
"host": os.getenv("MYSQL_HOST", "localhost"),
"port": int(os.getenv("MYSQL_PORT", "3306")),
"user": os.getenv("MYSQL_USER"),
"password": os.getenv("MYSQL_PASSWORD"),
"database": os.getenv("MYSQL_DATABASE"),
}
print(config)
if not all([config["user"], config["password"], config["database"]]):
raise ValueError("缺少必需的数据库配置")
return config
def execute_sql(query: str) -> list[TextContent]:
"""执行SQL查询语句
参数:
query (str): 要执行的SQL语句,支持多条语句以分号分隔
返回:
list[TextContent]: 包含查询结果的TextContent列表
- 对于SELECT查询:返回CSV格式的结果,包含列名和数据
- 对于SHOW TABLES:返回数据库中的所有表名
- 对于其他查询:返回执行状态和影响行数
- 多条语句的结果以"---"分隔
异常:
Error: 当数据库连接或查询执行失败时抛出
"""
config = get_db_config()
try:
with connect(**config) as conn:
with conn.cursor() as cursor:
statements = [stmt.strip() for stmt in query.split(";") if stmt.strip()]
results = []
for statement in statements:
try:
cursor.execute(statement)
# 检查语句是否返回了结果集 (SELECT, SHOW, EXPLAIN, etc.)
if cursor.description:
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall()
# 将每一行的数据转换为字符串,特殊处理None值
formatted_rows = []
for row in rows:
formatted_row = [
"NULL" if value is None else str(value)
for value in row
]
formatted_rows.append(",".join(formatted_row))
# 将列名和数据合并为CSV格式
results.append(
"\n".join([",".join(columns)] + formatted_rows)
)
# 如果语句没有返回结果集 (INSERT, UPDATE, DELETE, etc.)
else:
conn.commit() # 只有在非查询语句时才提交
results.append(f"查询执行成功。影响行数: {cursor.rowcount}")
except Error as stmt_error:
# 单条语句执行出错时,记录错误并继续执行
results.append(
f"执行语句 '{statement}' 出错: {str(stmt_error)}"
)
# 可以在这里选择是否继续执行后续语句,目前是继续
return [TextContent(type="text", text="\n---\n".join(results))]
except Error as e:
print(f"执行SQL '{query}' 时出错: {e}")
return [TextContent(type="text", text=f"执行查询时出错: {str(e)}")]
def get_table_name(text: str) -> list[TextContent]:
"""根据表的中文注释搜索数据库中的表名
参数:
text (str): 要搜索的表中文注释关键词
返回:
list[TextContent]: 包含查询结果的TextContent列表
- 返回匹配的表名、数据库名和表注释信息
- 结果以CSV格式返回,包含列名和数据
"""
config = get_db_config()
sql = "SELECT TABLE_SCHEMA, TABLE_NAME, TABLE_COMMENT "
sql += f"FROM information_schema.TABLES WHERE TABLE_SCHEMA = '{config['database']}' AND TABLE_COMMENT LIKE '%{text}%';"
return execute_sql(sql)
def get_table_desc(text: str) -> list[TextContent]:
"""获取指定表的字段结构信息
参数:
text (str): 要查询的表名,多个表名以逗号分隔
返回:
list[TextContent]: 包含查询结果的TextContent列表
- 返回表的字段名、字段注释等信息
- 结果按表名和字段顺序排序
- 结果以CSV格式返回,包含列名和数据
"""
config = get_db_config()
# 将输入的表名按逗号分割成列表
table_names = [name.strip() for name in text.split(",")]
# 构建IN条件
table_condition = "','".join(table_names)
sql = "SELECT TABLE_NAME, COLUMN_NAME, COLUMN_COMMENT "
sql += (
f"FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = '{config['database']}' "
)
sql += f"AND TABLE_NAME IN ('{table_condition}') ORDER BY TABLE_NAME, ORDINAL_POSITION;"
return execute_sql(sql)
def get_lock_tables() -> list[TextContent]:
sql = """SELECT
p2.`HOST` AS 被阻塞方host,
p2.`USER` AS 被阻塞方用户,
r.trx_id AS 被阻塞方事务id,
r.trx_mysql_thread_id AS 被阻塞方线程号,
TIMESTAMPDIFF(SECOND, r.trx_wait_started, CURRENT_TIMESTAMP) AS 等待时间,
r.trx_query AS 被阻塞的查询,
l.OBJECT_NAME AS 阻塞方锁住的表,
m.LOCK_MODE AS 被阻塞方的锁模式,
m.LOCK_TYPE AS '被阻塞方的锁类型(表锁还是行锁)',
m.INDEX_NAME AS 被阻塞方锁住的索引,
m.OBJECT_SCHEMA AS 被阻塞方锁对象的数据库名,
m.OBJECT_NAME AS 被阻塞方锁对象的表名,
m.LOCK_DATA AS 被阻塞方事务锁定记录的主键值,
p.`HOST` AS 阻塞方主机,
p.`USER` AS 阻塞方用户,
b.trx_id AS 阻塞方事务id,
b.trx_mysql_thread_id AS 阻塞方线程号,
b.trx_query AS 阻塞方查询,
l.LOCK_MODE AS 阻塞方的锁模式,
l.LOCK_TYPE AS '阻塞方的锁类型(表锁还是行锁)',
l.INDEX_NAME AS 阻塞方锁住的索引,
l.OBJECT_SCHEMA AS 阻塞方锁对象的数据库名,
l.OBJECT_NAME AS 阻塞方锁对象的表名,
l.LOCK_DATA AS 阻塞方事务锁定记录的主键值,
IF(p.COMMAND = 'Sleep', CONCAT(p.TIME, ' 秒'), 0) AS 阻塞方事务空闲的时间
FROM performance_schema.data_lock_waits w
INNER JOIN performance_schema.data_locks l ON w.BLOCKING_ENGINE_LOCK_ID = l.ENGINE_LOCK_ID
INNER JOIN performance_schema.data_locks m ON w.REQUESTING_ENGINE_LOCK_ID = m.ENGINE_LOCK_ID
INNER JOIN information_schema.INNODB_TRX b ON b.trx_id = w.BLOCKING_ENGINE_TRANSACTION_ID
INNER JOIN information_schema.INNODB_TRX r ON r.trx_id = w.REQUESTING_ENGINE_TRANSACTION_ID
INNER JOIN information_schema.PROCESSLIST p ON p.ID = b.trx_mysql_thread_id
INNER JOIN information_schema.PROCESSLIST p2 ON p2.ID = r.trx_mysql_thread_id
ORDER BY 等待时间 DESC;"""
return execute_sql(sql)
# 初始化服务器
app = Server("operateMysql")
@app.list_tools()
async def list_tools() -> list[Tool]:
"""列出可用的MySQL工具
返回:
list[Tool]: 工具列表,当前仅包含execute_sql工具
"""
return [
Tool(
name="execute_sql",
description="在MySQL8.0数据库上执行SQL",
inputSchema={
"type": "object",
"properties": {
"query": {"type": "string", "description": "要执行的SQL语句"}
},
"required": ["query"],
},
),
Tool(
name="get_table_name",
description="根据表中文名搜索数据库中对应的表名",
inputSchema={
"type": "object",
"properties": {
"text": {"type": "string", "description": "要搜索的表中文名"}
},
"required": ["text"],
},
),
Tool(
name="get_table_desc",
description="根据表名搜索数据库中对应的表结构,支持多表查询",
inputSchema={
"type": "object",
"properties": {
"text": {"type": "string", "description": "要搜索的表名"}
},
"required": ["text"],
},
),
Tool(
name="get_lock_tables",
description="获取当前mysql服务器InnoDB 的行级锁",
inputSchema={"type": "object", "properties": {}},
),
]
@app.call_tool()
async def call_tool(name: str, arguments: dict) -> list[TextContent]:
if name == "execute_sql":
query = arguments.get("query")
if not query:
raise ValueError("缺少查询语句")
return execute_sql(query)
elif name == "get_table_name":
text = arguments.get("text")
if not text:
raise ValueError("缺少表信息")
return get_table_name(text)
elif name == "get_table_desc":
text = arguments.get("text")
if not text:
raise ValueError("缺少表信息")
return get_table_desc(text)
elif name == "get_lock_tables":
return get_lock_tables()
raise ValueError(f"未知的工具: {name}")
sse = SseServerTransport("/messages/")
# Handler for SSE connections
async def handle_sse(request):
async with sse.connect_sse(
request.scope, request.receive, request._send
) as streams:
await app.run(streams[0], streams[1], app.create_initialization_options())
# Create Starlette app with routes
starlette_app = Starlette(
debug=True,
routes=[
Route("/sse", endpoint=handle_sse),
Mount("/messages/", app=sse.handle_post_message),
],
)
if __name__ == "__main__":
uvicorn.run(starlette_app, host="0.0.0.0", port=9000)四个工具方法
execute_sql
get_table_name
get_table_desc
get_lock_tables依赖
pip install mcp
pip install mysql-connector-python
pip install uvicorn
pip install python-dotenv
pip install starlette直接运行,如图所示,mcp服务器启动
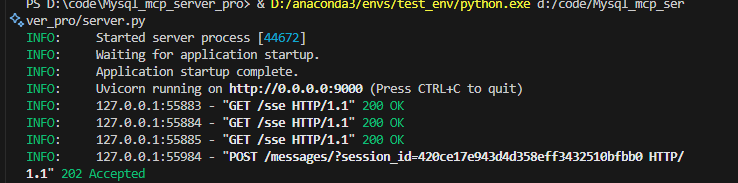
访问页面:http://127.0.0.1:9000/sse
四、 测试MCP应用
下载Cherry Studio客户端为例子,注意:必须是Cherry Studio最新版本Cherry Studio 官方网站 - 全能的AI助手
4.1客户端添加MCP
设置里添加
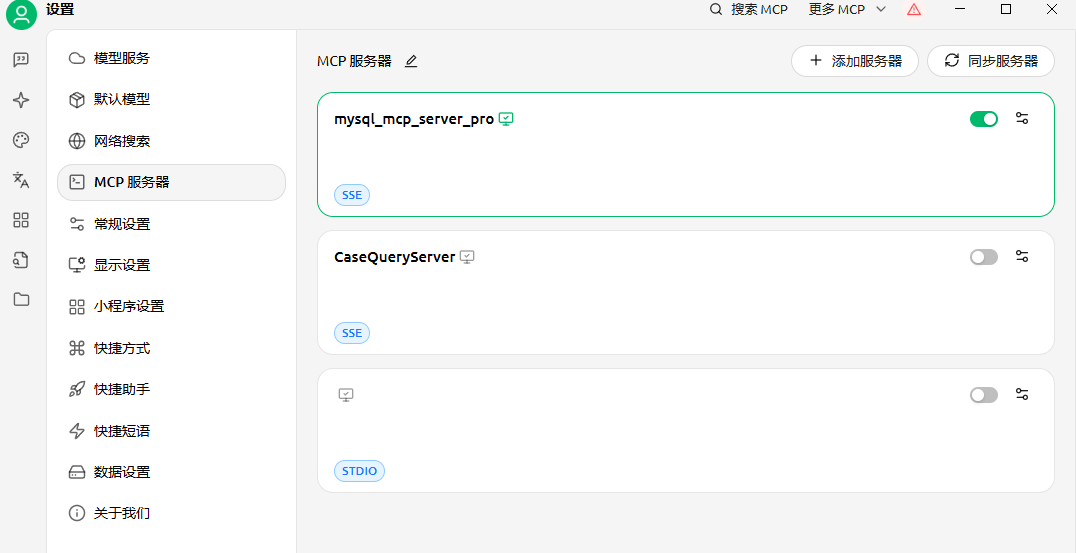
添加MCP服务器
输入名称:mysql_mcp_server_pro
类型:sse
URL:http://127.0.0.1:9000/sse
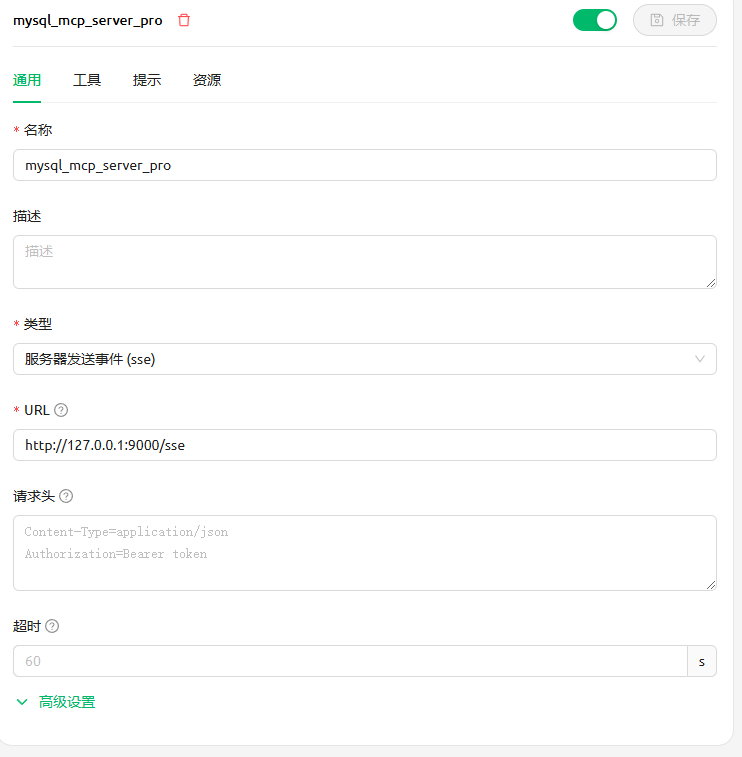
保存成功后,就可以看到工具列表
4.2新建助手测试mcp服务
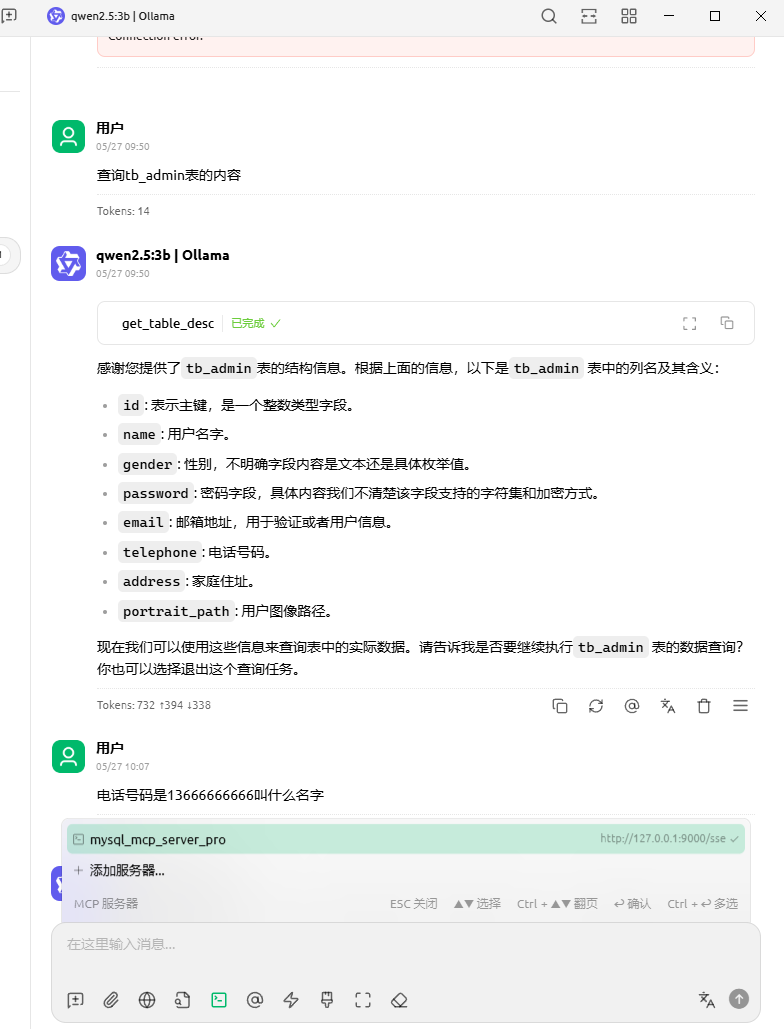
总结一下,AI模型调用MCP,还是很方便的。
有些时候AI模型做不到的,你可以自己写一个MCP应用。比如上面提到的查询mysql表数据,还有很多呢。
比如查询内部CRM系统,gitlab信息,内部业务系统,处理特定格式excel文件等等,都可以的。


















 390
390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









