







弱监督人群计数:基于排序而非位置信息
ECCV2020

作者:
中国科学院大学
中国科学院大数据挖掘与知识管理重点实验室
中国科学院智能信息处理重点实验室
意大利-特兰托大学
1、摘要
在人群计数数据集中,位置标签是昂贵的,但它们没有被纳入评价指标。此外,现有的多任务方法采用高级任务来提高计算精度。这种研究趋势增加了对注释的需求。本文提出了一种弱监督 计数网络,在没有位置监督的情况下直接回归人群数量。此外,我们通过利用图像之间的关系来训练网络的计数能力。我们在计数网络中也提出了一种软标签分类网络,该网络根据人群数量对给定图像进行分类。排序网络驱动共享骨干CNN模型显式获得密度敏感能力。因此,该方法利用隐藏在人群中的信息,而不是学习额外的标签,如位置和角度,提高了计数的准确性。我们在三个人群计数数据集上评估我们提出的方法,我们的方法的性能优于完全监督的最先进的方法。
2、为什么不需要位置信息?
- 人群计数的标注通常是昂贵的。现有的计数数据集提供了每个实例的位置来训练计数网络,但在评估阶段没有考虑这些位置标签,性能指标仅评估人群数量的估计精度。
- 事实上,在不需要位置的情况下,可以通过其他经济的方式获得人群数量。例如,利用已收集的数据集,可以通过收集环境信息来获得人群数量,例如,检测空间中的干扰,或估计移动人群的数量。
- 几种方法[17,4,14,23]证明了在估计结果中人群数量与位置之间不存在紧密的联系。
3、本文贡献
- 提出了一个弱监督计数网络,它直接回归人群数量,没有位置标签的监督。
- 提出了一种软标签排序网络来方便计数任务,该网络根据图像的人群数量对图像进行排序。该框架改进了计数任务,不需要额外的标签,特别是昂贵的语义标签。
- 所提出的弱监督方法在三个数据集上优于完全监督的最新方法。
4、什么是软标签?
软标签具有高熵和提供更多的信息,采用瑞利分布来描述排序任务的复杂性。
目前生成概率举证P的ground truth的方法是生成一个硬标签:
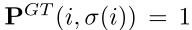
但是,排序任务很复杂,硬标签无法涵盖所有情况。例如,可能有几个候选项具有相似甚至相同的值。因此,我们提出了高熵的软标签来捕获传输概率。它们不仅在每个训练案例中提供比硬标签更多的信息,而且训练案例之间的梯度差异也小得多。
软标记引入瑞利分布来捕捉置换中元素与其相邻元素之间的关系。我们将一个元素与其相邻元素的排列差表示为Δ i+1 ,Δ i−1
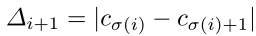
我们设置一个阈值,记为Δthr,表示网络的灵敏度。如果两个元素的差值小于阈值,则网络认为它们是相似的实例。运输矩阵的元素计算如下:
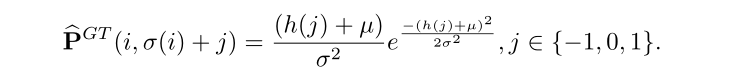
为了保证边的计算正确,在计算每个元素之前,我们先填充矩阵,计算完后再裁剪。两个运算的速率都是1。

5、Method
5.1 Regression Network

如图1所示,回归网络直接从整个框架回归人群数量。此外,该网络的前端提供金字塔状的特征向量,并与排序网络共享。
前端网络中的backbone:VGG-16的前13层

网络的前端需要对局部的和全局的人群密度敏感,因此,提出了用自适应池化层P,来提取一个金字塔状的特征向量。自适应池层由全局子簇层和局部子簇层组成。


5.2 Sorting Network

为了处理多帧,排序网络采用多分支网络提取金字塔特征向量。每个分支共享回归网络,而所有分支共享相同的参数。


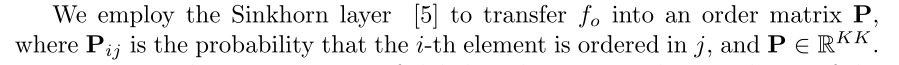
更重要的是,我们提出了一个软标签来描述排序任务的复杂性,它比硬标签提供了更多的信息。
5.3 Sinkhorn Operator
Sinkhorn Operator提出了求解最优传输问题。经过多次迭代,生成一个矩阵来捕捉两个分布之间的运输概率。由于该方法是可微的,近年来,人们将其与深度网络相结合来解决排序问题。
在所提出的排序网络中,我们使用一个Sinkhorn 层来生成顺序特征和顺序向量之间的传输矩阵。在Sinkhorn层中,我们首先通过以下方法对传输矩阵P进行初始化:

5.4 Training Method
我们使用一种直接的方法来训练回归网络和排序网络作为一个端到端结构。前10个卷积层是从预先训练过的vgg16中进行微调的。对于其他层,初始值来自于具有0.01标准偏差的高斯初始化。在学习速率固定的情况下,采用随机梯度下降法。
在对图像数据集和视频数据集进行训练时,我们采用了各种采样策略。这是因为视频监控场景更注重约束场景中行人流量的变化。使用图像数据集,我们从数据集中随机选择图像,并用其人群数量训练网络。对于视频数据集,我们首先随机选取同一场景的视频片段。然后我们在这些剪辑中随机选择图像
利用MSE损失来训练回归网络: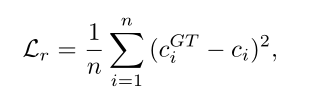
利用交叉熵损失来监督排序网络:
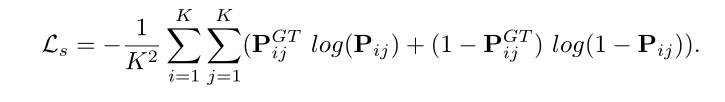
最终的损失为:
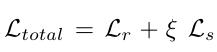
6、实验
在本节中,我们首先提供实现细节和评估指标。然后,在数据集上评估和比较我们的方法与之前的完全监督的最先进的方法[46,2,15,27,19,13]。在最后的小节中,我们介绍了在WorldExpo10数据集上的消融研究结果。
6.1 数据集
- WorldExpo10
- UCSD
- ShanghaiTech
6.2 在不同数据集上与完全监督方法的比较
6.2.1 在WorldExpo10数据集上
该训练集包含106个场景的3380个视频,其中3380帧使用了点标签。测试集有5个场景5个视频,标注了600帧。在每个训练剪辑中,我们随机选取3个场景相同的视频,以确保所选图像的人群数量具有足够的多样性。
我们将MAE的结果比较列在表1中,其中我们的方法达到9.6平均MAE。在没有位置监督的情况下,我们的方法优于完全监督的方法。

我们将来自内层的密度图可视化,并在图3 (a)中展示了一个成功的例子,其中回归结果具有低误差。而且,预测的阶数是正确的,每个预测都有很高的可信度。

在处理图3 (b)中的图像剪辑时,回归网络虽然能给出准确的估计,但是排序网络失败了。这是因为这些图像有相似的人群数量。实验证明,所提出的计数网络能够在没有位置监控的情况下准确地估计人群数量。此外,该分类网络能够对图像剪辑进行分类。

6.2.2 在UCSD数据集上
包含2000个画面,由监控摄像头拍摄,画面视角相同。表1总结了现有方法和我们方法的比较。在UCSD和WorldExpo10数据集上的结果证明,我们的方法在视频监控场景中的整体性能与全监督方法相当。
6.2.3 在ShanghaiTech数据集上
该数据集有1198幅不同视角和分辨率的图像。这个数据集有两个部分,分别是Part A和Part B。
我们的方法与有监督方法相比,我们的方法在B部分取得了相当的性能,而在A部分,我们的方法与其他方法有一定的差距。由于A部分的测试集的人群数分布与训练集的人群数分布存在显著差异,具体来说,测试集中的均值和标准方差分别为354.7和433.9,而训练集中的均值和标准方差分别为505.3和542.4。相反,B部分两个子集的人群数量分布相似。在测试集中,均值和标准方差分别为95.3和124.1,而在训练集中,均值和标准方差分别为94.0和123.2。非线性回归网络不能仅仅依靠人群编号标签来解决数据集分布不平衡的问题,需要更有力的监督,比如位置标签和透视标签。
6.3 消融实验

6.3.1 Only Sorting and Only Regression
单独训练排序网络时,排序准确率下降了35.3%。当我们单独训练回归网络时,回归精度下降了109.4%。实验证明,这两个任务是相互促进的。这是因为这两个任务都估计了人群数量,并且密切相关。
6.3.2 Soft-Label and Hard-Label
硬标签的每一行都是一个one-hot向量。分类准确率提高了13.4%,但是计数任务的性能下降了28.1%。这是因为软标签具有较高的熵,而分类网络很难预测准确的运输概率。软标签也包含更多的信息。因此,它们简化了计数任务以提高性能。
6.3.3 Different Backbones、Backbones、Frames Numbers

6.3.4 Different Sampling Methods

在计数网络中,我们采用各种池化聚类操作来提取特征。候选方法采用相同的采样率,但所有层使用自适应平均池层。改进后的网络性能下降了18.8%。这一结果表明,最大池化层在提取局部特征时效率更高。
在图4中,我们展示了一个例子,这是一个内部密度图。由于密度图是有噪声的,最大池化层提取的鉴别特征最多。同时,内部特征图不受人工密度图的监督。因此,该密度图的响应不是理想的高斯信号。得到的密度图保留了原始的语义信息。这一现象证实了计数网络不需要回归具有高斯核的实例位置,而专注于回归人群数量。因此,弱监管的人群计数是一个很有前途的研究方向。
7、结论
本文提出了一种无位置监督的弱监督计数方法。此外,我们还利用了图像之间的关系来提高计数的准确性。我们提出了一种新的软标签分类网络和计数网络,该网络根据人群数量对给定图像进行分类。我们对排序网络和回归网络进行端到端的训练。在训练时,排序网络驱动共享骨干CNN模型显式获得密度敏感能力。因此,该方法不是通过学习额外的标签,而是利用群体数量之间的信息来提高计数的准确性。在提出的排序网络中,我们提出了一个信息更丰富的软标签来捕捉排序任务的复杂性。我们在三个数据集上进行了实验,并将所提出的弱监督方法与全监督方法进行了比较。大量的实验结果证明了我们的方法的最新性能。在未来的工作中,我们将提出一个相应的弱监管基准,以方便这项工作。















 991
991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









