







浅读一下美团视觉智能部提出的YOLOV6:专用于工业应用的单阶段目标检测框架
目前该项目已经开源:https://github.com/meituan/YOLOv6,但是没有看到相应的论文,然后去找了一下。
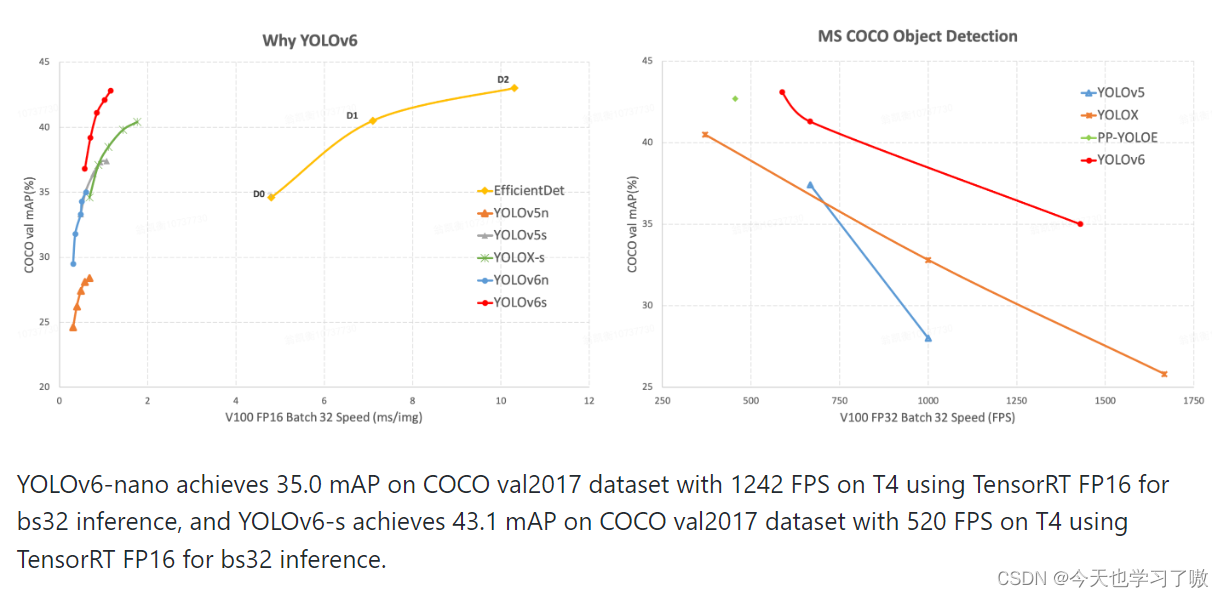
虽然没有更详细的论文介绍,不过人家代码已经开源了,还是值得看看的。
一、相关知识:
1.1、FP16和FP32?
当前Pytorch的默认存储数据类型是整数INT64(8字节),浮点数FP32(4字节),PyTorch Tensor的默认类型为单精度浮点数FP32。随着模型越来越大,加速训练模型的需求就产生了。
在深度学习模型中使用FP32主要存在几个问题:
- 模型尺寸大,训练的时候对显卡的显存要求高;
- 模型训练速度慢;
- 模型推理速度慢。
解决方案就是使用低精度计算对模型进行优化。
与单精度浮点数float32(32bit,4个字节)相比,半精度浮点数float16仅有16bit,2个字节组成。使用FP16可以解决或者缓解上面FP32的两个问题:显存占用更少:通用的模型FP16占用的内存只需原来的一半,训练的时候可以使用更大的batchsize,计算速度更快。
一般采用混合精度(AMP, Automatic mixed precision),用半精度可能对acc的影响较大,Pytorch原生支持自动混合精度训练(torch.cuda.amp),AMP 训练能在 Tensor Core GPU (Tensor Core是一种矩阵乘累加的计算单元,每个Tensor Core每个时钟执行64个浮点混合精度操作,FP16矩阵相乘和FP32累加)上实现更高的性能并节省多达 50% 的内存,主要节省的还是内存开销问题,在实际测试中,训练时间并没有节省。低精度计算也是未来深度学习的一个重要趋势。
二、改进
2.1 Hardware-friendly Backbone
之前的YOLO系列模型主干都是采用的CSPNet,采用了多分支的方式和残差结构,如下图中yolox的主干:
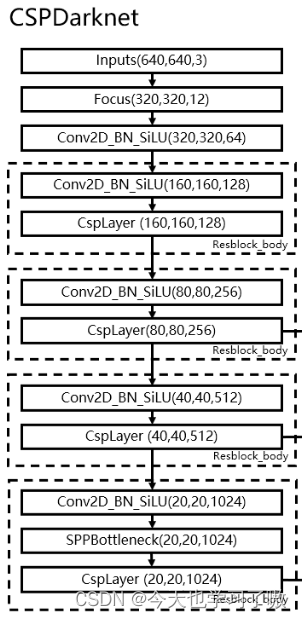
对于 GPU 等硬件来说,这种结构会一定程度上增加延时,同时减小内存带宽利用率。图 2 为计算机体系结构领域中的 Roofline Model介绍图,显示了硬件中计算能力和内存带宽之间的关联关系。
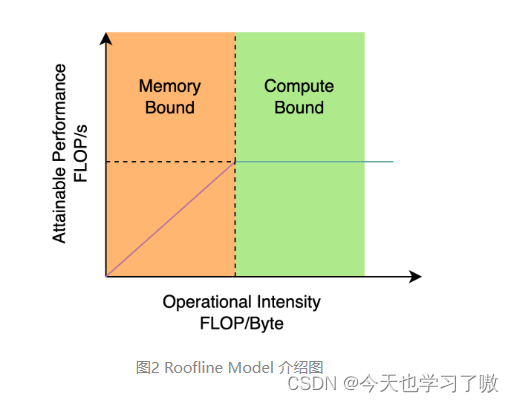
基于硬件感知神经网络设计的思想,综合考虑硬件计算能力、内存带宽、编译优化特性、网络表征能力等。
2.1.1 RepVGG style 结构:
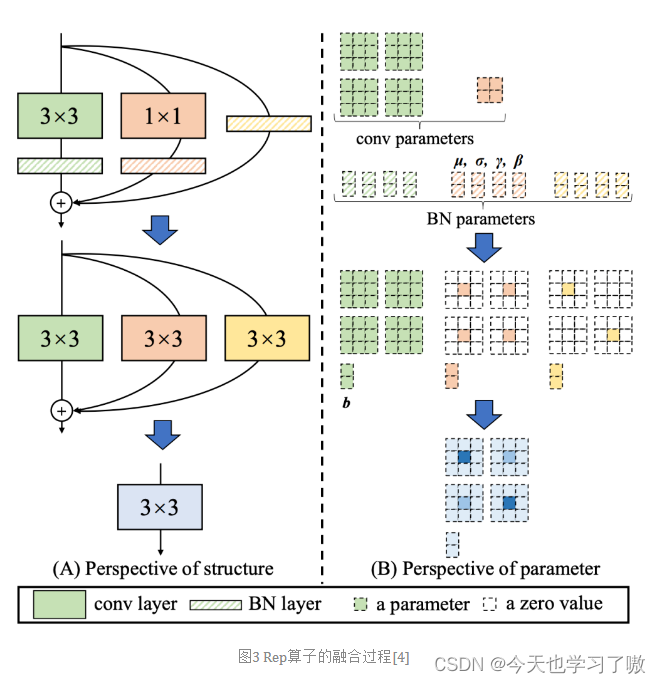
RepVGG为每一个3×3的卷积添加平行了一个1x1的卷积分支和恒等映射的分支。这种结构就构成了构成一个RepVGG Block。
该结构在训练时具有多分支拓扑,而在实际部署时可以等效融合为单个 3x3 卷积的一种可重参数化的结构(融合过程如下图 3 所示)。通过融合成的 3x3 卷积结构,可以有效利用计算密集型硬件计算能力(比如 GPU),同时也可获得 GPU/CPU 上已经高度优化的 NVIDIA cuDNN 和 Intel MKL 编译框架的帮助。
具体结构为:
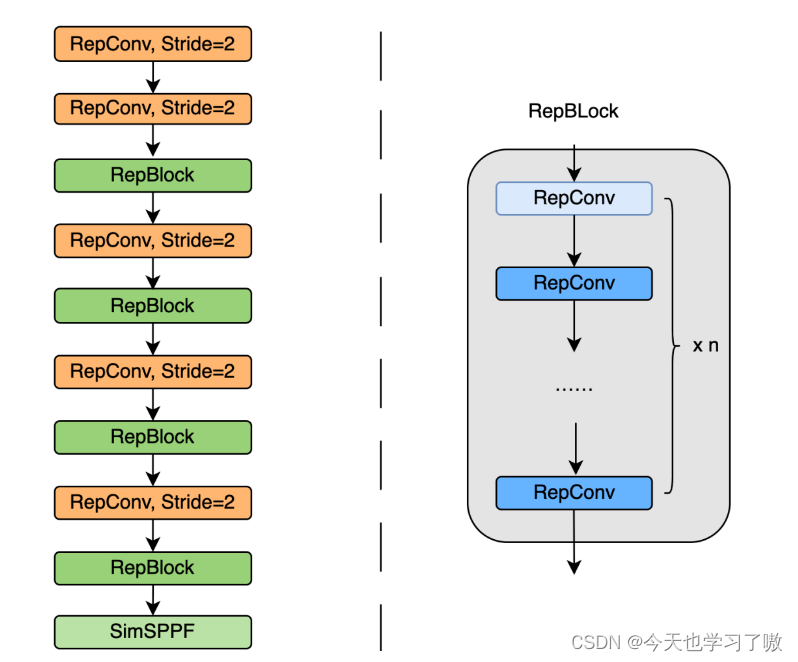
将 Backbone 中 stride=2 的普通 Conv 层替换成了 stride=2 的 RepConv层。同时,将原始的 CSP-Block 都重新设计为 RepBlock,其中 RepBlock 的第一个 RepConv 会做 channel 维度的变换和对齐。
另
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









