







基于判别特征学习的跨视角步态识别
paper题目:Cross-View Gait Recognition by Discriminative Feature Learning
paper是中国科学院大学发表在TIP 2019的工作
paper地址:链接
Abstract
最近,由于卷积神经网络(CNN)的强大能力,基于深度学习的跨视角步态识别变得流行。当前的深度学习方法通常依赖于广泛用于人脸识别任务的损失函数,例如对比损失和三元组损失。这些损失函数存在难负样本挖掘的问题。本文提出了一种稳健、有效且与步态相关的损失函数,称为角中心损失 (ACL),用于学习判别步态特征。所提出的损失函数对不同的局部部分和时间窗口大小具有鲁棒性。与为每个身份学习一个中心的中心损失不同,所提出的损失函数为同一身份的每个角度学习多个子中心。仅惩罚锚点特征和相应的交叉视角子中心之间的最大距离,从而实现更好的类内紧凑性。还提出通过局部特征提取器和时间注意力模型来提取判别性的时空特征。提出了一种简化的空间变换器网络来定位人体合适的水平部位。提取每个水平部分的局部步态特征,然后将其连接为描述符。引入长短期记忆(LSTM)单元作为时间注意力模型来学习每个帧的注意力分数,例如,更多地关注判别帧,而不是质量差的帧。时间注意力模型显示出比时间平均池化或步态能量图像 (GEI) 更好的性能。通过结合这三个方面,在几个跨视角步态识别基准上取得了最先进的结果。
I. INTRODUCTION
步态是一种行为生物特征,定义为一个人走路的方式。与面部和虹膜等常见的生物特征相比,步态可以应用于远距离和非合作的情况。步态识别的一个典型应用是监视场景中的嫌疑人检索。步态识别已在丹麦 [1] 和英国 [2] 用于证据收集。
步态可能对某些因素很敏感,包括视角、衣服、步行速度、鞋子和携带状态。其中,视角变化是一个非常棘手的问题,因为不同视角会引入外观差异。步态能量图像 (GEI) [3] 是沿时间维度的平均轮廓,已被广泛用作时空步态特征。可以减少剪影中的噪声,同时也可以减少动态信息。对于没有视角变化的情况,基于 GEI 计算 L2 距离可以取得很好的效果。另一个更简单的情况是多视角步态识别。这意味着gallery中提供了来自多个视角的步态序列。probe视角经常可以在gallery中找到对应的视角,降低了识别难度。然而,在真实的监控案例中,很难在多个视角中捕获步态序列。仅提供一个gallery视角的跨视角步态识别对于缓解缺少注册视角是必要的。因此,主体内的变化通常大于主体间的变化,这使得问题变得非常困难。本文中专注于跨视角步态识别。
跨视角步态识别的方法可以分为两类:基于模型的和基于外观的。基于模型的方法尝试重建人的 3D 模型 [4]、[5]。这通常依赖于多个高分辨率相机。成像距离也受到限制,这限制了它的潜在用途。另一方面,基于外观的方法从普通监控摄像头的原始视频中提取特征。这减轻了对高端捕获设备的需求。但是,模型经常受到外观变化的影响。这里的方法属于基于外观的方法,因为只依赖于二元步态轮廓或 GEI 的序列。
基于外观的方法可以进一步分为两类:判别方法和生成方法。判别方法旨在直接从数据中学习视图不变的特征。这些方法包括线性判别分析 (LDA) [6]、Rank-SVM [7] 和 CNN 方法 [8]-[11]。特征表示对于步态识别非常重要。以前的非深度学习方法通常依赖于手工制作的特征,例如 GEI [3] 或计时步态图像 (CGI) [12]。耦合切片对齐是非深度学习方法中最有效的方法之一[13],它首先构建一定数量的切片,每个切片由一个样本及其类内和类间组成。类最近邻,然后为每个patch设计一个目标函数,以平衡cross-view类内紧凑性和cross-view类间可分离性,最后将所有局部独立的patch合并为一个统一的目标函数。Ben等人还探索了用于跨视角步态识别的通用张量表示框架 [14]。他们的方法基于张量耦合映射的三个标准,即耦合多线性局部保留准则、耦合多线性边缘 Fisher 准则和耦合多线性判别分析准则。这种方法非常有利,因为它避免了样本不足的问题。他们还首次分析了收敛性[14]。
深度学习方法直接从原始数据中学习判别特征表示或度量,并在步态识别方面取得了可喜的成果。Wu等人[9] 通过具有时间输入的 3D CNN 学习成对相似性。Takemura等人[11] 通过在大规模跨视角数据集上优化基于 CNN 的方法的输入、输出和损失函数,进一步改进了 [9] 的成对相似性学习方法。 GEINet [10] 使用多类分类方法从 GEI 中学习带有 softmax 损失的步态特征。生成方法通常将步态特征从不同条件转换为相同条件以实现更好的匹配。Yu等人 [15] 构建了一个编码器-解码器网络,将 GEI 图像转换为常见条件。还引入了生成对抗网络(GAN)[16],以将任意步态条件转换为带有正常服装的侧视图条件 [17]。He等人 [18] 提出了用于学习特定视图的特征表示的多任务生成对抗网络(MGAN)。然而,生成方法在准确性方面并不一定是最优的,因为它们本质上是针对不同条件下步态特征的合成[11]。
基于深度学习的方法在应用于跨视图步态识别时会遇到几个问题。
(1) 人脸识别中广泛使用的损失函数不能保证步态识别的令人满意的性能。现有方法 [9]-[11] 使用 softmax 损失、对比损失或三重损失来进行跨视角步态识别。这些损失函数要么存在判别问题,要么存在抽样问题。发现很少有特定于步态的损失函数。在损失函数的设计过程中,视角信息经常被忽略。例外是[18],它学习了特定于视角的特征表示。
(2) 时空特征学习无法捕获详细的步态特征。大多数现有方法依赖于整个身体而不是局部部分作为输入。尽管 [19] 和 [20] 考虑了部分选择,但这些方法通常忽略视角更改。对于跨视角步态识别,有判别的身体部位会有所不同。还提出了一些方法来捕获时间步态特征。 [21]、[22] 使用 3D 卷积来模拟步态序列的动态特征。 [23] 和 [24] 中使用长短期记忆 (LSTM) 单元来模拟人类关键点的运动。然而,由于这些方法使用的时间窗较短,动态步态特征可能会丢失。
为了克服这些问题,可以借鉴人脸识别、人物再识别和动作识别的思路。在人脸识别中,中心损失[25]和基于特征归一化的方法[26]-[28]被提出来学习更好的判别特征。在行人重识别中,空间特征学习方法包括空间显著性匹配[29]、基于部分的学习[30]、[31]和掩码引导学习[32]已被证明是有效的。这些方法迫使模型关注有判别的部分,而不是背景或全局人体。对于动作识别,可以使用时间建模,例如 C3D [33]、LSTM [34] 和双流网络 [35]。
因此,本文专注于跨视图步态识别的判别损失函数和时空特征学习。
(1) 受人脸识别损失函数的启发,提出了一种鲁棒、有效且与步态相关的损失函数,称为角中心损失,具有以下优点。鲁棒性:所提出的损失函数只有一个主要的超参数来控制主体内的紧凑性,从而减轻了对超参数网格搜索的需求。它对步态识别中的不同局部部分和时间窗口大小具有鲁棒性。它还避免了对比损失和三元组损失的采样问题。有效:仔细评估了几个最先进的损失函数,作者发现所提出的损失函数对于小型和大型数据集都表现良好。步态相关:为相同身份的每个角度学习子中心。中心的更新策略遵循在训练时有效的标准反向传播。仅惩罚锚点特征与相应的跨视图子中心之间的最大距离,这与跨视图步态识别设置相匹配。
(2) 作者提出了一种有效的时空特征学习方法。对于空间特征学习,我们发现与全局特征和统一局部特征相比,具有学习分区的局部特征可以获得更好的性能。通过分析不同身体部位的结果,我们得出结论,头部和大腿对于跨视图步态识别很重要。对于时间特征学习,我们提出了一个 LSTM 注意力模型来学习每一帧的注意力权重。时空特征被组合为步态序列的最终特征表示。在这些特征向量上计算余弦相似度。
我们将我们的主要贡献总结如下。
针对 softmax 损失中的低区分度和对比/三元组损失中的难负挖掘问题,我们提出了一种鲁棒、有效且与步态相关的损失函数,用于跨视角步态识别。我们还比较了步态识别的不同损失函数。
对于粗略的时空特征提取问题,学习有效的时空特征,通过学习的水平分区和 LSTM 注意力模型进一步提高性能。
针对步态识别准确率相对较低的问题,我们结合上述方面,在包括 CASIA-B、OULP 和 OUMVLP 在内的多个基准上实现了 state-of-the-art 的性能。
III. PROPOSED METHOD
A. Overall Framework
图 1 显示了总体框架。所提出的方法可以在步态相关损失函数的监督下提取时空特征。轮廓被一个可学习的分区分成 4 个水平部分。每个水平部分都被送入一个单独的 CNN。 LSTM 注意力模型用于在帧级 CNN 上输出注意力分数。帧级特征由每个部分的注意力权重平均。在训练阶段,这些不同的加权特征被输入到单独的损失函数中。在测试阶段,每个部分的加权特征连接在一起作为特征向量。为验证和识别任务计算这些特征向量之间的余弦相似度。

图 1. 我们方法的总体框架。提出了角度中心损失来学习判别特征。学习的分区和 LSTM 时间注意模型用于提取时空步态特征。
B. Review of Loss Functions
我们首先回顾了人脸识别中使用的几个损失函数。
经典的损失函数是softmax loss,公式如下:
L
s
=
−
∑
i
=
1
m
log
e
W
y
i
T
x
i
+
b
y
i
∑
j
=
1
n
e
W
j
T
x
i
+
b
j
L_{s}=-\sum_{i=1}^{m} \log \frac{e^{\boldsymbol{W}_{y_{i}}^{T} \boldsymbol{x}_{i}+b_{y_{i}}}}{\sum_{j=1}^{n} e^{\boldsymbol{W}_{j}^{T} \boldsymbol{x}_{i}+b_{j}}}
Ls=−i=1∑mlog∑j=1neWjTxi+bjeWyiTxi+byi
其中
x
i
∈
R
d
\boldsymbol{x}_{i} \in \mathbb{R}^{d}
xi∈Rd表示第
i
i
i个深度特征,属于第
y
i
y_{i}
yi类。
d
d
d是特征维度。
W
j
∈
R
d
\boldsymbol{W}_{j} \in \mathbb{R}^{d}
Wj∈Rd表示最后一个全连接层中权重
W
∈
R
d
×
n
\boldsymbol{W} \in \mathbb{R}^{d \times n}
W∈Rd×n的第
j
j
j列,
b
∈
R
n
\boldsymbol{b} \in \mathbb{R}^{n}
b∈Rn是偏置项。批量大小和类数分别为
m
m
m和
n
n
n。
在人脸识别中,已经证明通过 softmax 损失学习到的特征只是可分离的,而不是可判别的 [25]。因此提出中心损失来学习具有以下公式的判别特征:
L
c
=
1
2
∑
i
=
1
m
∥
x
i
−
c
y
i
∥
2
2
L_{c}=\frac{1}{2} \sum_{i=1}^{m}\left\|\boldsymbol{x}_{i}-\boldsymbol{c}_{y_{i}}\right\|_{2}^{2}
Lc=21i=1∑m∥xi−cyi∥22
其中
c
y
i
\boldsymbol{c}_{y_{i}}
cyi代表第
y
i
y_{i}
yi个类中心。中心损失会惩罚锚特征与其对应的类中心之间的距离。
c
y
i
\boldsymbol{c}_{y_{i}}
cyi的更新计算如下:
Δ
c
j
=
∑
i
=
1
m
δ
(
y
i
=
j
)
(
c
j
−
x
i
)
1
+
∑
i
=
1
m
δ
(
y
i
=
j
)
(
3
)
c
j
t
+
1
=
c
j
t
−
α
Δ
c
j
t
\begin{aligned} \Delta \boldsymbol{c}_{j} &=\frac{\sum_{i=1}^{m} \delta\left(y_{i}=j\right)\left(\boldsymbol{c}_{j}-\boldsymbol{x}_{i}\right)}{1+\sum_{i=1}^{m} \delta\left(y_{i}=j\right)}\quad(3) \\ \boldsymbol{c}_{j}^{t+1} &=\boldsymbol{c}_{j}^{t}-\alpha \Delta \boldsymbol{c}_{j}^{t} \end{aligned}
Δcjcjt+1=1+∑i=1mδ(yi=j)∑i=1mδ(yi=j)(cj−xi)(3)=cjt−αΔcjt
如果满足条件,则
δ
\delta
δ (condition
)
=
1
)=1
)=1,如果不满足,则
δ
(
\delta(
δ( condition
)
=
0
)=0
)=0。为了避免由于少量错误标记的样本引起的大扰动,引入了
α
\alpha
α来控制中心的学习率。
仅使用中心损失是不够的,因为中心几乎不会根据其公式而改变,因此损失可能为零。中心损失应与softmax损失一起使用,以形成如下目标函数:
L
=
L
s
+
λ
L
c
L=L_{s}+\lambda L_{c}
L=Ls+λLc
其中标量
λ
\lambda
λ用于平衡两个损失函数。通过 softmax 损失,特征是可分离的。并且随着中心损失,特征变得具有判别力。
C. Weight Normalization and Feature Normalization
最近的研究 [26]-[28] 表明了特征归一化和权重归一化的有效性。通过固定偏置项
b
j
=
0
b_{j}=0
bj=0,目标 logit [61] 可以重写如下:
W
j
T
x
i
=
∥
W
j
∥
∥
x
i
∥
cos
θ
j
\boldsymbol{W}_{j}^{T} \boldsymbol{x}_{i}=\left\|\boldsymbol{W}_{j}\right\|\left\|\boldsymbol{x}_{i}\right\| \cos \theta_{j}
WjTxi=∥Wj∥∥xi∥cosθj
为了消除
W
\boldsymbol{W}
W的影响,我们固定
∥
W
j
∥
=
1
\left\|\boldsymbol{W}_{j}\right\|=1
∥Wj∥=1. 如上所述,相似度通常被计算为与特征的 L2 范数无关的余弦相似度。然后将特征向量固定为
∥
x
∥
=
s
\|\boldsymbol{x}\|=s
∥x∥=s。特征和权重归一化将消除径向变化并推动每个特征分布在超球面流形上。然而,比例因子
s
s
s很难选择。尽管在 [26] 和 [27] 中可以给出下限,但超参数通常是根据经验设置的,用于人脸识别。
D. Angle Center Loss
在中心损失中,每个类的中心以统计方式更新,如公式 3 所示。我们注意到中心损失相对于
c
j
\boldsymbol{c}_{j}
cj的梯度可以通过当前的自动微分框架(如 MXNet [62])来计算。因此更新策略可以简化为标准的小批量随机梯度下降(SGD)算法:
c
j
t
+
1
=
c
j
t
−
α
∂
L
c
∂
c
j
(
7
)
\boldsymbol{c}_{j}^{t+1}=\boldsymbol{c}_{j}^{t}-\alpha \frac{\partial L_{c}}{\partial \boldsymbol{c}_{j}}\quad(7)
cjt+1=cjt−α∂cj∂Lc(7)
与原始中心损失相比,差异可能是中心的学习率和权重衰减。学习率应固定为
α
\alpha
α,并且应禁用中心参数的权重衰减以应对中心损失的原始形式。通过这些修改,我们可以获得更好的效率和与原始中心损失相似的性能。这样的效率使我们能够处理具有更多中心的情况,例如,如下所述的子中心。
对于步态识别,中心损失平等地对待身份的每个视角。换句话说,来自同一身份的所有视角都被推送到同一中心。在本文中,我们为相同身份的每个视角引入了子中心。
y
i
y_{i}
yi类和
a
k
a_{k}
ak角的子中心可以写成
c
y
i
a
k
\boldsymbol{c}_{y_{i}} a_{k}
cyiak。这样,中心的总数扩大为:
N
s
u
b
=
N
v
∗
N
c
N_{s u b}=N_{v} * N_{c}
Nsub=Nv∗Nc
其中
N
s
u
b
N_{s u b}
Nsub代表所有子中心的数量,
N
v
N_{v}
Nv代表视角数量,
N
c
N_{c}
Nc代表所有身份的数量。
我们为这些副中心提出了一个硬性积极的挖掘策略。如图 2 所示,anchor 特征
x
i
\boldsymbol{x}_{i}
xi与其对应的 cross-view 子中心之间的距离可以计算如下:
D
(
x
i
,
c
y
i
a
k
)
=
∥
x
i
−
c
y
i
a
k
∥
2
D\left(\boldsymbol{x}_{i}, \boldsymbol{c}_{y_{i} a_{k}}\right)=\left\|\boldsymbol{x}_{i}-\boldsymbol{c}_{y_{i} a_{k}}\right\|_{2}
D(xi,cyiak)=∥xi−cyiak∥2
选择角度之间的最大距离作为损失。距离较小的其他角度被屏蔽。这样,损失函数可以写成如下形式:
L
c
=
1
2
∑
i
=
1
m
D
(
x
i
,
c
y
i
a
k
)
2
s.t.
argmax
a
k
,
a
k
≠
a
i
D
(
x
i
,
c
y
i
a
k
)
\begin{aligned} &L_{c}=\frac{1}{2} \sum_{i=1}^{m} D\left(\boldsymbol{x}_{i}, \boldsymbol{c}_{y_{i} a_{k}}\right)^{2} \\ &\text { s.t. } \operatorname{argmax}_{a_{k}, a_{k} \neq a_{i}} D\left(\boldsymbol{x}_{i}, \boldsymbol{c}_{y_{i} a_{k}}\right) \end{aligned}
Lc=21i=1∑mD(xi,cyiak)2 s.t. argmaxak,ak=aiD(xi,cyiak)
等式 7 中的更新策略可以看作是学习中心的有效措施,尤其是对于更多中心或复杂损失函数。但是,它不对性能负责。硬挖掘策略学习了更好的类内紧凑性,因此可能对性能有益。原始中心损失、简化中心损失和角度中心损失之间的比较将在表二中给出。
对于步态识别,每个身份通常只有有限数量的训练样本。这可能会导致基于分类的方法严重过度拟合。通过对每个身份内部的指标进行建模,与中心损失相比,我们能够学习更好的主体内分布。由于子中心与角度相关,因此提出的损失函数称为角度中心损失(ACL)。在 [63] 中,还提出了一种新的损失函数,通过为每个身份引入子中心来进行跨视角行人重识别。主要区别在于子中心的更新策略。在这项工作中,所有子中心都通过基于迭代的优化进行更新。我们的方法仅使用随机梯度下降 (SGD) 算法更新最难的子中心。因此,它可以学习更好的主体内变化并且更有效。
E. Local Gait Features
人体分区已在以前的工作中使用,包括基于模型的方法和基于外观的方法。 Lee 和 Grimson [64] 将轮廓划分为 7 个区域,并使用椭圆来拟合每个区域。里达等人。 [19]通过组套索将人体分为4个部分,以选择最具辨别力的人体部分。罗卡努贾曼等人。 [20] 使用了 5 部分的分区,并声称头部、腰部和小腿区域的重要性。这些作品依赖于非均匀分区,因此我们受到启发,将多个 CNN 用于不同的非均匀部分。
图 3 说明了所提出的局部特征提取网络。我们为每个局部部分训练多个单独的 CNN。该方法类似于 [31] 中用于行人重识别的基于部分的卷积基线 (PCB) 模型。差异有 2 。
(1) 在 [31] 中,局部特征是从共享的全局骨干网络中提取的。对于步态识别,我们不共享主干网络。步态轮廓或 GEI 在图像级别被划分为 N 个水平部分。然后为每个部分训练一个分类器。请注意,这些用于不同部分的 CNN 不共享参数。该模型必须仅使用局部而不是全身来对主体的身份进行分类。局部特征被连接为最终描述符,可以看作是[65]中描述的分层特征编码。
(2) 我们学习使用简化的空间变换器网络 [56] 而不是 [31] 中提出的统一水平分区来定位信息部分。
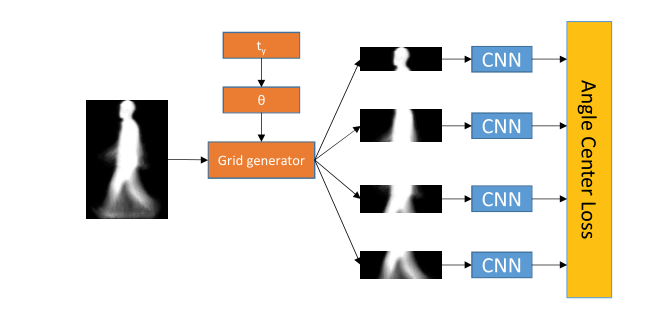
图 3 局部特征提取。通过简化的空间变换网络,人体被分成四个不同的水平部分。
局部特征的相等组合有两个原因。 (1)避免错位问题。在步态识别中,虽然 GEI/剪影大致对齐,但由于分割质量低,仍然存在不匹配问题。姿势估计可能有助于额外的计算。如图 4 所示,对于真正的一对,全局特征可能完全不同,而局部特征可以保留腿部区域的相似性。 (2)局部特征相辅相成。与全局特征相比,特征融合可以提取有判别的细粒度特征。应该注意的是,相等组合是一个微不足道的设置,它在行人重识别方面取得了可喜的结果[31]。关于不同部分的加权组合的进一步研究将在讨论小节中给出。
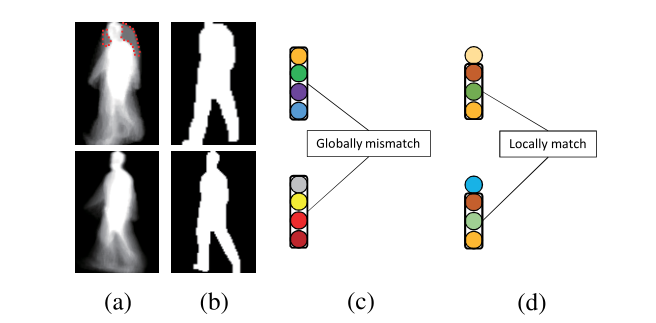
图 4 全局特征与连接局部特征的比较。 (a) 真正的 GEI。注意头部区域的差异。 (b) 真正的剪影。 © 全局特征不匹配。 (d) 连接的局部特征是局部匹配的。
原始空间变换器网络通过定位网络学习仿射变换。变换包括裁剪、平移、旋转、缩放和倾斜。在 [9] 中,包括旋转和缩放在内的数据增强方法并没有提高性能。然后将转换约束如下:
A
θ
=
[
1
0
0
0
1
t
y
]
A_{\theta}=\left[\begin{array}{lll} 1 & 0 & 0 \\ 0 & 1 & t_{y} \end{array}\right]
Aθ=[10010ty]
其中
t
y
t_{y}
ty表示垂直平移。约束变换可以看作是一种水平注意力模型,它定位了人体的信息部分。由于大多数步态轮廓都已正确归一化,因此无需像 [55] 中那样添加额外的定位网络来学习每个图像的变换。我们只为每个水平定位器设置一个参数
t
y
t_{y}
ty。使用可微分图像采样算法[56],可以以端到端的方式学习平移参数。在本文中,选择了 4 个定位器。直接从随机初始化中使用这些空间变换器网络将导致发散。每个定位器都被初始化,使得注意力部分与手工制作的统一分区相同。然后网络可以学习可变形的局部注意力部分。在测试时,模型使用学习的分区提取局部特征。
F . T emporal Gait Features
虽然 GEI 经常被用作步态识别的特征,但它同时丢失了时间信息。在动作识别或基于视频的行人重识别中,动态时间特征是重要的线索。沿时间维度的级联特征可以保留每一帧的每个详细特征。gallery和probe的步态周期无法正确对齐。在时间维度上平均特征是一种消除错位的简单方法。融合的特征可以看作是特征层面的另一种 GEI。然而,简单的平均池化不足以捕捉复杂的动态特征,因为它只取几个静态特征的平均值。我们引入了一个基于 LSTM 的时间注意力模型来学习每一帧的时间分数。
图 5 说明了所提出的时间注意模型。我们引入长短期记忆(LSTM)单元来学习时间注意力,因为这些单元可以记住步态序列的先前信息。 LSTM模型的维度为1,起到attention score的作用。由于注意力机制没有直接的标签,因此必须从数据本身中学习时间注意力。与 [66] 类似,我们通过 2DCNN 提取帧级特征
f
t
f_{t}
ft,其中
f
t
f_{t}
ft是帧
t
t
t的 2DCNN 特征。然后添加一个 LSTM 层的新分支以引起注意力。对于
T
T
T帧的输入步态序列,LSTM 层输出
T
T
T帧的激活作为分数。然后将这些分数沿时间轴进行 L1 归一化,如下所示。
a
t
=
s
t
∑
i
=
1
T
s
i
a_{t}=\frac{s_{t}}{\sum_{i=1}^{T} s_{i}}
at=∑i=1Tsist
其中
a
t
a_{t}
at是第
t
t
t帧的 L1 归一化注意力得分,
s
i
s_{i}
si是第
i
i
i帧的得分值。 L1 归一化确保序列的注意力分数之和等于 1。
通过捕获这些时间注意力分数,步态序列的整体特征表示可以重写如下。
f
s
=
∑
t
=
1
T
a
t
f
t
f_{s}=\sum_{t=1}^{T} a_{t} f_{t}
fs=t=1∑Tatft
其中
f
s
f_{s}
fs表示整个序列的特征。请注意,当
a
t
=
1
/
T
a_{t}=1 / T
at=1/T时,公式会退化为平均时间池化,它平等地对待每一帧。在注意力模型的帮助下,算法更加关注那些有判别的帧,从而提高了整体性能。
参考文献
[1] P . K. Larsen, E. B. Simonsen, and N. Lynnerup, “Gait analysis in forensic medicine,” J. Forensic Sci., vol. 53, no. 5, pp. 1149–1153, 2008.
[2] I. Bouchrika, M. Goffredo, J. Carter, and M. Nixon, “On using gait in forensic biometrics,” J. Forensic Sci., vol. 56, no. 4, pp. 882–889, 2011.
[3] J. Man and B. Bhanu, “Individual recognition using gait energy image,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 28, no. 2, pp. 316–322, Feb. 2006.
[4] G. Zhao, G. Liu, H. Li, and M. Pietikainen, “3D gait recognition using multiple cameras,” in Proc. Int. Conf. Autom. Face Gesture Recognit., 2006, pp. 529–534.
[5] G. Ariyanto and M. S. Nixon, “Model-based 3D gait biometrics,” in Proc. Int. Joint Conf. Biometrics, 2011, pp. 1–7.
[6] D. L. Swets and J. Weng, “Using discriminant eigenfeatures for image retrieval,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 18, no. 8, pp. 831–836, Aug. 1996.
[7] R. Martín-Félez and T. Xiang, “Uncooperative gait recognition by learning to rank,” Pattern Recognit., vol. 47, no. 12, pp. 3793–3806, Dec. 2014.
[8] Z. Wu, Y . Huang, and L. Wang, “Learning representative deep features for image set analysis,” IEEE Trans. Multimedia, vol. 17, no. 11, pp. 1960–1968, Nov. 2015.
[9] Z. Wu, Y . Huang, L. Wang, X. Wang, and T. Tan, “A comprehensive study on cross-view gait based human identification with deep CNNs,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 2, pp. 209–226, Feb. 2016.
[10] K. Shiraga, Y . Makihara, D. Muramatsu, T. Echigo, and Y . Yagi, “GEINet: View-invariant gait recognition using a convolutional neural network,” in Proc. IEEE Int. Conf. Biometrics, Jun. 2016, pp. 1–8.
[11] N. Takemura, Y . Makihara, D. Muramatsu, T. Echigo, and Y . Y agi, “On input/output architectures for convolutional neural network-based cross-view gait recognition,” IEEE Trans. Circuits Syst. Video Technol., to be published.
[12] C. Wang, J. Zhang, L. Wang, J. Pu, and X. Y uan, “Human identification using temporal information preserving gait template,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 34, no. 11, pp. 2164–2176, Nov. 2012.
[13] X. Ben, C. Gong, P . Zhang, X. Jia, Q. Wu, and W. Meng, “Coupled patch alignment for matching cross-view gaits,” IEEE Trans. Image Process., vol. 28, no. 6, pp. 3142–3157, Jun. 2019.
[14] X. Ben, C. Gong, P . Zhang, R. Y an, Q. Wu, and W. Meng, “Coupled bilinear discriminant projection for cross-view gait recognition,” IEEE Trans. Circuits Syst. Video Technol., to be published.
[15] S. Y u, H. Chen, Q. Wang, L. Shen, and Y . Huang, “Invariant feature extraction for gait recognition using only one uniform model,” Neurocomputing, vol. 239, pp. 81–93, May 2017.
[16] I. J. Goodfellow et al., “Generative adversarial nets,” in Proc. Adv. Neural Inf. Process. Syst., 2014, pp. 2672–2680.
[17] S. Y u, H. Chen, E. B. G. Reyes, and N. Poh, “GaitGAN: Invariant gait feature extraction using generative adversarial networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), Jul. 2017, pp. 532–539.
[18] Y . He, J. Zhang, H. Shan, and L. Wang, “Multi-task GANs for viewspecific feature learning in gait recognition,” IEEE Trans. Inf. Forensics Security, vol. 14, no. 1, pp. 102–113, Jan. 2019.
[19] I. Rida, X. Jiang, and G. L. Marcialis, “Human body part selection by group lasso of motion for model-free gait recognition,” IEEE Signal Process. Lett., vol. 23, no. 1, pp. 154–158, Jan. 2016.
[20] M. Rokanujjaman, M. A. Hossain, and M. R. Islam, “Effective part selection for part-based gait identification,” in Proc. Int. Conf. Elect. Comput. Eng., 2012, pp. 17–19.
[21] T. Wolf, M. Babaee, and G. Rigoll, “Multi-view gait recognition using 3D convolutional neural networks,” in Proc. IEEE Int. Conf. Image Process., Sep. 2016, pp. 4165–4169.
[22] D. Thapar, A. Nigam, D. Aggarwal, and P. Agarwal, “VGR-Net: A view invariant gait recognition network,” in Proc. IEEE Int. Conf. Identity, Secur., Behav. Anal. (ISBA), Jan. 2018, pp. 1–8.
[23] Y . Feng, Y . Li, and J. Luo, “Learning effective gait features using LSTM,” in Proc. IEEE Int. Conf. Pattern Recognit., Dec. 2016, pp. 325–330.
[24] R. Liao, C. Cao, E. B. Garcia, S. Yu, and Y . Huang, “Pose-based temporal-spatial network (PTSN) for gait recognition with carrying and clothing variations,” in Proc. Chin. Conf. Biometric Recognit., 2017, pp. 474–483.
[25] Y . Wen, K. Zhang, Z. Li, and Y . Qiao, “A discriminative feature learning approach for deep face recognition,” in Proc. Eur. Conf. Comput. Vis., 2016, pp. 499–515.
[26] Y . Liu, H. Li, and X. Wang, “Rethinking feature discrimination and polymerization for large-scale recognition,” 2017, arXiv:1710.00870. [Online]. Available: https://arxiv.org/abs/1710.00870
[27] H. Wang et al., “CosFace: Large margin cosine loss for deep face recognition,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 5265–5274.
[28] J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “ArcFace: Additive angular margin loss for deep face recognition,” 2018, arXiv:1801.07698. https://arxiv.org/abs/1801.07698



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











