









Wasserstein 距离可与 Kullback-Leibler 散度相媲美,实现知识蒸馏
paper是大连理工大学发表在NIPS 2024的工作
paper title:Wasserstein Distance Rivals Kullback-Leibler Divergence for Knowledge Distillation
Abstract
自从 Hinton 等人的开创性工作以来,基于 KullbackLeibler 散度 (KL-Div) 的知识蒸馏一直占据主导地位,最近它的变体也取得了令人瞩目的表现。然而,KL-Div 只比较老师和学生对应类别的概率,而缺乏跨类别比较的机制。此外,KL-Div 在应用于中间层时存在问题,因为它无法处理不重叠的分布,并且不知道底层流形的几何形状。为了解决这些缺点,我们提出了一种基于 Wasserstein 距离 (WD) 的知识蒸馏方法。具体来说,我们提出了一种基于离散 WD 的逻辑蒸馏方法 WKD-L,它执行跨类别概率比较,因此可以明确利用类别之间的丰富相互关系。此外,我们引入了一种特征蒸馏方法 WKD-F,它使用参数方法来建模特征分布,并采用连续 WD 从中间层传输知识。对图像分类和目标检测的综合评估表明:(1) 对于逻辑蒸馏,WKD-L 的表现优于非常强大的 KL-Div 变体;(2) 对于特征蒸馏,WKD-F 优于 KL-Div 同类产品和最先进的竞争对手。
1 Introduction
知识蒸馏 (KD) 旨在将知识从具有大容量的高性能教师模型转移到轻量级的学生模型。在过去的几年中,它吸引了越来越多的关注并在深度学习中取得了巨大进步,广泛应用于视觉识别和物体检测等领域 [1]。在他们的开创性工作中,Hinton 等人 [2] 引入了 Kullback-Leibler 散度 (KL-Div) 进行知识蒸馏,其中学生的类别概率预测被限制为与老师的类别概率预测相似。从那时起,KL-Div 在 logit 蒸馏中占据主导地位,最近它的变体 [3; 4; 5] 取得了令人瞩目的表现。此外,这种 logit 蒸馏方法与许多从中间层迁移知识的先进方法是互补的 [6; 7; 8]。
尽管取得了巨大的成功,KL-Div 仍有两个缺点阻碍了教师知识的充分迁移。首先,KL-Div 仅比较教师和学生之间相应类别的概率,缺乏进行跨类别比较的机制。然而,现实世界中的类别表现出不同程度的视觉相似性,例如,哺乳动物物种(如狗和狼)看起来彼此更相似,而与汽车和自行车等人工制品在视觉上截然不同。深度神经网络 (DNN) 可以区分数千个类别 [9],因此对类别之间的复杂关系了如指掌,如图 1a 所示。不幸的是,由于其类别到类别的性质,经典的 KD [2] 及其变体 [3; 4; 5] 无法明确利用这种丰富的跨类别知识。

(a) 现实世界中的类别在特征空间中表现出丰富的相互关系 (IR),例如,狗靠近其他哺乳动物,但远离汽车等人工制品。我们将成对的 IR 量化为类别之间的特征相似性。放大后效果最佳。
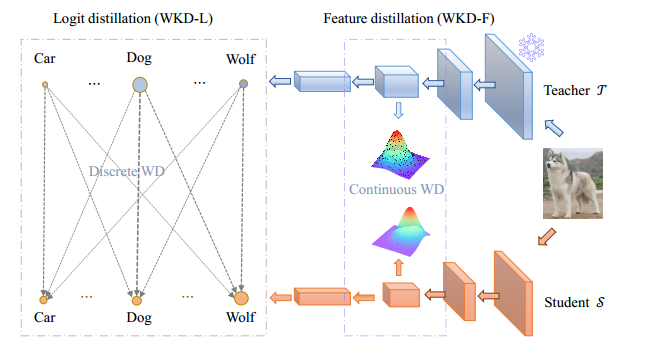
(b)对于逻辑蒸馏,离散 WD 通过利用成对 IR 进行跨类别比较,而 KL-Div 是类别到类别的度量,缺乏使用此类 IR 的机制(参见图 2)。对于特征蒸馏,我们使用高斯进行分布建模,使用连续 WD 进行知识迁移。
图 1:基于 Wasserstein 距离 (WD) 的知识提炼方法。为了有效利用丰富的类别相互关系 (a),我们提出了基于离散 WD 的逻辑蒸馏 (WKD-L) (b),以匹配教师和学生之间的预测分布。此外,我们引入了一种基于连续 WD (WKD-F) (b) 的特征蒸馏方法,其中我们让学生模仿教师的参数特征分布。在 (a) 中,100 个类别的特征根据通过 t-SNE 获得的 2D 嵌入通过相应的图像显示;有关此可视化的详细信息,请参阅第 A.1 节。
其次,KL-Div 难以从中间层提取知识。图像的深层特征通常维度较高且尺寸较小,因此在特征空间中分布非常稀疏 [10,第 2 章]。这不仅使 KL-Div 所需的非参数密度估计(例如直方图)由于维数灾难而变得不可行,而且还会导致 KL-Div 无法处理的不重叠离散分布 [11]。人们可以求助于参数化、连续方法(例如高斯)来对特征分布进行建模。然而,KL-Div 及其变体在测量连续分布之间的差异性方面的能力有限,因为它不是度量 [12] 并且不知道底层流形的几何结构 [13]。
Wasserstein 距离 (WD) [14],也称为 Earth Mover 距离 (EMD) 或最优传输,有可能解决 KL-Div 的局限性。两个概率分布之间的 WD 通常定义为将一个分布转换为另一个分布的最小成本。一些研究已经探索使用 WD 从中间层进行知识迁移 [15; 16]。具体来说,他们基于离散 WD 测量老师和学生之间小批量图像的差异,这涉及以软方式进行实例之间的比较,未能利用跨类别的关系。此外,他们主要寻求非参数方法来建模分布,在性能上落后于最先进的基于 KL-Div 的方法。
为了解决这些问题,我们提出了一种基于 Wasserstein 距离的知识蒸馏方法,我们称之为 WKD。如图 1b 所示,该方法适用于 logits(WKD-L)以及中间层(WKD-F)。在 WKD-L 中,我们使用离散 WD 进行知识传递,以最小化教师和学生预测概率之间的差异。通过这种方式,我们执行跨类别比较,有效地利用类别之间的相互关系 (IR),与经典 KL-Div 中的类别间比较形成鲜明对比。 我们建议使用中心核对齐 (CKA) [17; 18] 来量化类别 IR,它可以测量任何一对类别之间的特征相似性。
对于 WKD-F,我们将 WD 引入中间层以从特征中浓缩知识。与 logits 不同,中间层不涉及类概率。因此,我们让学生直接匹配老师的特征分布。由于 DNN 特征的维度很高,非参数方法(例如直方图)由于维数灾难而不可行 [10,第 2 章],我们选择参数方法来建模分布。具体来说,我们使用最广泛使用的连续分布之一(即高斯),它在给定特征估计的 1 和 2 阶矩时具有最大熵 [19,第 1 章]。高斯之间的 WD 可以以封闭形式计算,并且是底层流形上的黎曼度量 [20]。
我们将贡献总结如下。
- 我们提出了一种基于离散 WD 的逻辑蒸馏方法 (WKD-L)。它可以通过跨类别比较教师和学生的预测概率来利用类别之间的丰富相互关系,从而克服类别间 KL 散度的缺点。
- 我们将连续 WD 引入中间层进行特征蒸馏 (WKD-F)。它可以有效地利用高斯黎曼空间的几何结构,优于几何不敏感的 KL 散度。
- 在图像分类和物体检测任务上,WKD-L 的表现都优于非常强大的基于 KL-Div 的逻辑蒸馏方法,而 WKD-F 是 KL-Div 同行和特征蒸馏竞争对手的主管。它们的结合进一步提高了性能。
2 WD for Knowledge Transfer
给定一个预训练的高性能教师模型 T \mathcal{T} T,我们的任务是训练一个轻量级的学生模型 S \mathcal{S} S,使其能够从教师模型中蒸馏知识。因此,学生模型的监督来自于两个方面:一方面是通过交叉熵损失与GT标签进行监督,另一方面是通过接下来的两个部分所描述的蒸馏损失,来自于教师模型的监督。
2.1 Discrete WD for Logit Distillation
类别之间的相互关系(IRs)。如图1a所示,真实世界中的类别在特征空间中表现出复杂的拓扑关系。例如,哺乳动物物种之间较为接近,而与人工制品或食物之间的距离较远。此外,同一类别的特征聚集并形成分布,而相邻类别的特征有重叠,无法完全分离。因此,我们提出基于CKA [18] 来量化类别间的相互关系(IRs),CKA是一种归一化的Hilbert-Schmidt独立性准则(HSIC),它通过将特征映射到再生核希尔伯特空间(RKHS)[21]中,来建模两组特征的统计关系。
给定类别 C i \mathcal{C}_i Ci的 b b b个训练样本,我们计算矩阵 X i ∈ R u × b \mathbf{X}_i \in \mathbb{R}^{u \times b} Xi∈Ru×b,其中第 k k k列表示从DNN倒数第二层输出的第 k k k个示例的特征。然后,我们计算核矩阵 K i ∈ R b × b \mathbf{K}_i \in \mathbb{R}^{b \times b} Ki∈Rb×b,采用某种正定核,例如线性核,其中 K i = X i T X i \mathbf{K}_i=\mathbf{X}_i^T \mathbf{X}_i Ki=XiTXi, T T T表示矩阵的转置。除了线性核外,我们还可以选择其他核,例如多项式核和RBF核(详细信息见附录A.1)。类别 C i \mathcal{C}_i Ci和 C j \mathcal{C}_j Cj之间的IR定义为:
IR ( C i , C j ) = HSIC ( C i , C j ) HSIC ( C i , C i ) HSIC ( C j , C j ) , HSIC ( C i , C j ) = 1 ( b − 1 ) 2 tr ( K i H K K j H ) \operatorname{IR}\left(\mathcal{C}_i, \mathcal{C}_j\right)=\frac{\operatorname{HSIC}\left(\mathcal{C}_i, \mathcal{C}_j\right)}{\sqrt{\operatorname{HSIC}\left(\mathcal{C}_i, \mathcal{C}_i\right)} \sqrt{\operatorname{HSIC}\left(\mathcal{C}_j, \mathcal{C}_j\right)}}, \operatorname{HSIC}\left(\mathcal{C}_i, \mathcal{C}_j\right)=\frac{1}{(b-1)^2} \operatorname{tr}\left(\mathbf{K}_i \mathbf{H K} \mathbf{K}_j \mathbf{H}\right) IR(Ci,Cj)=HSIC(Ci,Ci)HSIC(Cj,Cj)HSIC(Ci,Cj),HSIC(Ci,Cj)=(b−1)21tr(KiHKKjH)
其中, H = I − 1 b 11 1 T \mathbf{H}=\mathbf{I}-\frac{1}{b} \mathbf{1 1} \mathbf{1}^T H=I−b1111T是中心化矩阵, I \mathbf{I} I表示单位矩阵, 1 \mathbf{1} 1表示全1向量;tr表示矩阵的迹。 IR ( C i , C j ) ∈ [ 0 , 1 ] \operatorname{IR}\left(\mathcal{C}_i, \mathcal{C}_j\right) \in[0,1] IR(Ci,Cj)∈[0,1] 对各向同性的缩放和正交变换是不变的。注意,计算IR的成本可以忽略不计,因为我们只需要事先计算一次。由于教师模型更为知识丰富,我们使用教师模型计算类别间的相互关系,表示为 IR T ( C i , C j ) \operatorname{IR}^{\mathcal{T}}\left(\mathcal{C}_i, \mathcal{C}_j\right) IRT(Ci,Cj)。
除了CKA,两个类别原型之间的余弦相似度也可以用来量化IRs。在实践中,一个类别的原型可以通过该类别样本特征的平均值来计算。或者,DNN模型的softmax分类器所关联的权重向量也可以视为各个类别的原型 [22]。
损失函数。给定一张输入图像(实例),我们令 z = [ z i ] ∈ R n \mathbf{z}=\left[z_i\right] \in \mathbb{R}^n z=[zi]∈Rn 为对应的DNN模型的logits,其中 i ∈ S n ≜ { 1 , ⋯ , n } i \in S_n \triangleq\{1, \cdots, n\} i∈Sn≜{1,⋯,n} 表示第 i i i类的索引。预测的类别概率 p = [ p i ] \mathbf{p}=\left[p_i\right] p=[pi] 通过softmax函数 σ \sigma σ 和温度 τ \tau τ 计算,即 p i = σ ( z τ ) i ≜ exp ( z i / τ ) / ∑ j ∈ S n exp ( z j / τ ) p_i=\sigma\left(\frac{\mathbf{z}}{\tau}\right)_i \triangleq \exp \left(z_i / \tau\right) / \sum_{j \in S_n} \exp \left(z_j / \tau\right) pi=σ(τz)i≜exp(zi/τ)/∑j∈Snexp(zj/τ)。我们用 p T \mathbf{p}^{\mathcal{T}} pT 和 p S \mathbf{p}^{\mathfrak{S}} pS 分别表示教师模型和学生模型的预测类别概率。经典的KD [2] 是一种实例化的方法,它测量给定相同输入图像时, p T \mathbf{p}^{\mathcal{T}} pT 和 p S \mathbf{p}^{\mathfrak{S}} pS 之间的差异:
D K L ( p T ∥ p S ) = ∑ i p i T log ( p i T / p i S ) \mathrm{D}_{\mathrm{KL}}\left(\mathbf{p}^{\mathcal{T}} \| \mathbf{p}^{\mathcal{S}}\right)=\sum_i p_i^{\mathcal{T}} \log \left(p_i^{\mathcal{T}} / p_i^{\mathfrak{S}}\right) DKL(pT∥pS)=i∑piTlog(piT/piS)
KL-Div (2) 仅比较老师和学生之间对应于同一类别的预测概率,本质上缺乏进行跨类别比较的机制,如图 2 所示。虽然在梯度反向传播过程中,由于 softmax 函数的原因,一个类别的概率会影响其他类别的概率,但这种隐性影响并不显著,最重要的是,它不能像 (1) 中描述的那样明确地利用成对相互关系的丰富知识。
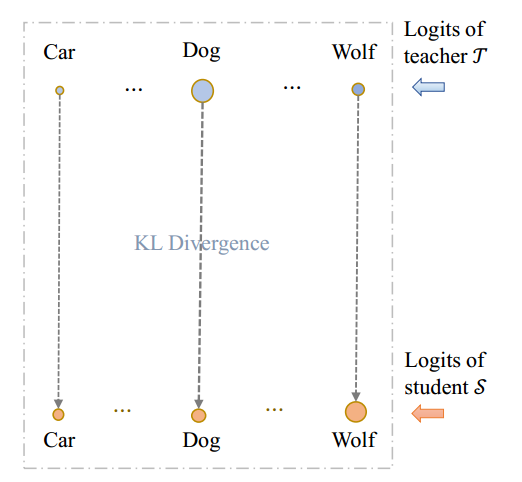
图 2:KL-Div 无法进行跨类别比较。与图 1b(左)中的 WD 进行比较。
与KL散度相比,WD执行类别间的比较,因此自然地利用了类别间的相互关系,如图1b(左)所示。我们将离散WD表示为一个带有熵正则化的线性规划 [23]:
D W D ( p T , p S ) = min q i j ∑ i , j c i j q i j + η q i j log q i j s.t. q i j ≥ 0 , ∑ j q i j = p i T , ∑ i q i j = p j S , i , j ∈ S n \begin{aligned} & \mathrm{D}_{\mathrm{WD}}\left(\mathbf{p}^{\mathfrak{T}}, \mathbf{p}^{\mathfrak{S}}\right)=\min _{q_{i j}} \sum_{i, j} c_{i j} q_{i j}+\eta q_{i j} \log q_{i j} \\ & \text { s.t. } q_{i j} \geq 0, \sum_j q_{i j}=p_i^{\mathfrak{T}}, \sum_i q_{i j}=p_j^{\mathfrak{S}}, i, j \in S_n \end{aligned} DWD(pT,pS)=qijmini,j∑cijqij+ηqijlogqij s.t. qij≥0,j∑qij=piT,i∑qij=pjS,i,j∈Sn
其中 c i j c_{i j} cij 和 q i j q_{i j} qij 分别表示每单位质量的运输成本和在从 p i T p_i^{\mathcal{T}} piT 到 p j S p_j^{\mathcal{S}} pjS 之间移动概率质量的运输量; η \eta η 是正则化参数。我们通过将相似度度量 IRs 转换为距离度量,使用常见的高斯核 [10, Chap. 6] 来定义成本 c i j c_{i j} cij,即 c i j = 1 − exp ( − κ ( 1 − IR T ( C i , C j ) ) ) c_{i j}=1-\exp \left(-\kappa\left(1-\operatorname{IR}^{\mathcal{T}}\left(\mathcal{C}_i, \mathcal{C}_j\right)\right)\right) cij=1−exp(−κ(1−IRT(Ci,Cj))),其中 κ \kappa κ 是一个可以控制 IR 锐化程度的参数。在特征空间中, IR T ( C i , C j ) \operatorname{IR}^{\mathcal{T}}\left(\mathcal{C}_i, \mathcal{C}_j\right) IRT(Ci,Cj) 越小,两个类别之间的运输成本越低。因此,WKD-L 的损失函数为
L ~ W K D − L = D W D ( p T , p s ) \tilde{\mathcal{L}}_{\mathrm{WKD}-\mathrm{L}}=\mathrm{D}_{\mathrm{WD}}\left(\mathbf{p}^{\mathcal{T}}, \mathbf{p}^{\mathfrak{s}}\right) L~WKD−L=DWD(pT,ps)
近期的研究 [3] 揭示了目标类别(即目标类别的概率)和非目标类别在训练中的作用不同:前者与训练样本的难度相关,而后者包含显著的“暗知识”。已证明这种分离有助于平衡它们的作用,并大大改进了经典的KD [3; 4]。受此启发,我们也考虑类似的分离策略。令 t t t 为目标类别的索引, z \ t J = [ z i J ] ∈ R n − 1 , i ∈ S n \ { t } \mathbf{z}_{\backslash t}^{\mathcal{J}}=\left[z_i^{\mathcal{J}}\right] \in \mathbb{R}^{n-1}, i \in S_n \backslash\{t\} z\tJ=[ziJ]∈Rn−1,i∈Sn\{t} 为教师模型的非目标类别logits。我们像之前一样对 z \ t T \mathbf{z}_{\backslash t}^{\mathcal{T}} z\tT 进行归一化,得到教师的非目标类别概率 p \ t T = [ p i T ] \mathbf{p}_{\backslash t}^{\mathcal{T}}=\left[p_i^{\mathcal{T}}\right] p\tT=[piT]。在这种情况下,我们的损失函数包含两个部分:
L W K D − L = λ D W D ( p \ t J , p \ t S ) + L t , L t = − σ ( z J ) t log σ ( z S ) t \mathcal{L}_{\mathrm{WKD}-\mathrm{L}}=\lambda \mathrm{D}_{\mathrm{WD}}\left(\mathbf{p}_{\backslash t}^{\mathcal{J}}, \mathbf{p}_{\backslash t}^{\mathcal{S}}\right)+\mathcal{L}_{\mathrm{t}}, \quad \mathcal{L}_{\mathrm{t}}=-\sigma\left(\mathbf{z}^{\mathcal{J}}\right)_t \log \sigma\left(\mathbf{z}^{\mathcal{S}}\right)_t LWKD−L=λDWD(p\tJ,p\tS)+Lt,Lt=−σ(zJ)tlogσ(zS)t
其中 λ \lambda λ 是权重。
2.2 Continuous WD for Feature Distillation
由于DNN的中间层输出的特征维度高且尺寸小,非参数方法(例如直方图和核密度估计)不可行。因此,我们使用广泛使用的参数化方法之一(即高斯分布)来进行分布建模。
特征分布建模。给定一个输入图像,考虑由DNN模型某个中间层输出的特征图,其空间高度、宽度和通道数分别为 h , w h, w h,w 和 l l l。我们将特征图重塑为矩阵 F ∈ R l × m \mathbf{F} \in \mathbb{R}^{l \times m} F∈Rl×m,其中 m = h × w m=h \times w m=h×w,第 i i i 列 f i ∈ R l \mathbf{f}_i \in \mathbb{R}^l fi∈Rl 表示一个空间特征。对于这些特征,我们估计其一阶矩 μ = 1 m ∑ i f i \boldsymbol{\mu}=\frac{1}{m} \sum_i \mathbf{f}_i μ=m1∑ifi 和二阶矩 Σ = 1 m ∑ i ( f i − μ ) ( f i − μ ) T \boldsymbol{\Sigma}=\frac{1}{m} \sum_i\left(\mathbf{f}_i-\boldsymbol{\mu}\right)\left(\mathbf{f}_i-\boldsymbol{\mu}\right)^T Σ=m1∑i(fi−μ)(fi−μ)T。我们通过均值向量 μ \boldsymbol{\mu} μ 和协方差矩阵 Σ \boldsymbol{\Sigma} Σ 来建模输入图像的特征分布,表示为一个高斯分布:
N ( μ , Σ ) = 1 ∣ 2 π Σ ∣ 1 / 2 exp ( − 1 2 ( f − μ ) T Σ − 1 ( f − μ ) ) \mathcal{N}(\boldsymbol{\mu}, \boldsymbol{\Sigma})=\frac{1}{|2 \pi \boldsymbol{\Sigma}|^{1 / 2}} \exp \left(-\frac{1}{2}(\mathbf{f}-\boldsymbol{\mu})^T \boldsymbol{\Sigma}^{-1}(\mathbf{f}-\boldsymbol{\mu})\right) N(μ,Σ)=∣2πΣ∣1/21exp(−21(f−μ)TΣ−1(f−μ))
其中 ∣ ⋅ ∣ |\cdot| ∣⋅∣ 表示矩阵的行列式。
我们直接从主干网络估计教师的高斯分布。对于学生,与以前的技术 [24;25;26] 一样,使用投影层来变换特征,使其大小与教师的特征兼容。然后使用投影仪生成的变换特征来计算学生的分布。我们选择高斯进行分布建模,因为它对于给定的一阶和二阶矩具有最大熵 [19,第 1 章],并且具有闭式 WD,即黎曼度量 [20]。
损失函数。设高斯分布 N T ≜ N ( μ T , Σ T ) \mathcal{N}^{\mathcal{T}} \triangleq \mathcal{N}\left(\boldsymbol{\mu}^{\mathcal{T}}, \boldsymbol{\Sigma}^{\mathcal{T}}\right) NT≜N(μT,ΣT) 为教师的特征分布。同样,学生的分布用 N S \mathcal{N}^{\mathcal{S}} NS 表示。两者之间的连续Wasserstein距离(WD)定义为:
D W D ( N T , N S ) = inf q ∫ R l ∫ R l ∥ f T − f S ∥ 2 q ( f T , f S ) d f T d f S \mathrm{D}_{\mathrm{WD}}\left(\mathcal{N}^{\mathcal{T}}, \mathcal{N}^{\mathcal{S}}\right)=\inf _q \int_{\mathbb{R}^l} \int_{\mathbb{R}^l}\left\|\mathbf{f}^{\mathcal{T}}-\mathbf{f}^{\mathcal{S}}\right\|^2 q\left(\mathbf{f}^{\mathcal{T}}, \mathbf{f}^{\mathcal{S}}\right) d \mathbf{f}^{\mathcal{T}} d \mathbf{f}^{\mathcal{S}} DWD(NT,NS)=qinf∫Rl∫Rl fT−fS 2q(fT,fS)dfTdfS
其中 f T \mathbf{f}^{\mathcal{T}} fT 和 f S \mathbf{f}^{\mathcal{S}} fS 是高斯变量, ∥ ⋅ ∥ \|\cdot\| ∥⋅∥ 表示欧氏距离;联合分布 q q q 受到约束,要求其边缘分布为 N T \mathcal{N}^{\mathcal{T}} NT 和 N S \mathcal{N}^{\mathcal{S}} NS。最小化上述式子(7)得到以下封闭形式的距离 [14]:
D W D ( N T , N S ) = D mean ( μ T , μ S ) + D cov ( Σ T , Σ S ) \mathrm{D}_{\mathrm{WD}}\left(\mathcal{N}^{\mathcal{T}}, \mathcal{N}^{\mathcal{S}}\right)=\mathrm{D}_{\text {mean }}\left(\boldsymbol{\mu}^{\mathcal{T}}, \boldsymbol{\mu}^{\mathcal{S}}\right)+\mathrm{D}_{\operatorname{cov}}\left(\boldsymbol{\Sigma}^{\mathcal{T}}, \boldsymbol{\Sigma}^{\mathcal{S}}\right) DWD(NT,NS)=Dmean (μT,μS)+Dcov(ΣT,ΣS)
其中 D mean ( μ T , μ S ) = ∥ μ T − μ S ∥ 2 \mathrm{D}_{\text {mean }}\left(\boldsymbol{\mu}^{\mathcal{T}}, \boldsymbol{\mu}^{\mathcal{S}}\right)=\left\|\boldsymbol{\mu}^{\mathcal{T}}-\boldsymbol{\mu}^{\mathcal{S}}\right\|^2 Dmean (μT,μS)= μT−μS 2,而 D cov ( Σ T , Σ S ) = tr ( Σ T + Σ S − 2 ( ( Σ J ) 1 2 Σ S ( Σ T ) 1 2 ) 1 2 ) \mathrm{D}_{\operatorname{cov}}\left(\boldsymbol{\Sigma}^{\mathcal{T}}, \boldsymbol{\Sigma}^{\mathcal{S}}\right)=\operatorname{tr}\left(\boldsymbol{\Sigma}^{\mathcal{T}}+\boldsymbol{\Sigma}^{\mathcal{S}}-2\left(\left(\boldsymbol{\Sigma}^{\mathcal{J}}\right)^{\frac{1}{2}} \boldsymbol{\Sigma}^{\mathcal{S}}\left(\boldsymbol{\Sigma}^{\mathcal{T}}\right)^{\frac{1}{2}}\right)^{\frac{1}{2}}\right) Dcov(ΣT,ΣS)=tr(ΣT+ΣS−2((ΣJ)21ΣS(ΣT)21)21),其中上标 1 2 { }^{\frac{1}{2}} 21 表示矩阵的平方根。由于从高维特征估计的协方差矩阵往往是病态的 [27],我们在对角线添加一个小的正数(1e-5)。我们还考虑对角协方差矩阵,在这种情况下, D cov ( Σ T , Σ S ) = \mathrm{D}_{\operatorname{cov }}\left(\boldsymbol{\Sigma}^{\mathcal{T}}, \boldsymbol{\Sigma}^{\mathcal{S}}\right)= Dcov(ΣT,ΣS)= ∥ δ T − δ S ∥ 2 \left\|\boldsymbol{\delta}^{\mathcal{T}}-\boldsymbol{\delta}^{\mathcal{S}}\right\|^2 δT−δS 2,其中 δ T \boldsymbol{\delta}^{\mathcal{T}} δT 是由协方差矩阵 Σ T \boldsymbol{\Sigma}^{\mathcal{T}} ΣT 的对角线元素的平方根构成的标准差向量。稍后我们将比较高斯(Full)和高斯(Diag),它们分别具有完整和对角协方差矩阵。为了平衡均值和协方差的作用,我们引入均值-协方差比率 γ \gamma γ 并定义损失为:
L W K D − F = γ D mean ( μ T , μ S ) + D c o v ( Σ T , Σ S ) \mathcal{L}_{\mathrm{WKD}-\mathrm{F}}=\gamma \mathrm{D}_{\text {mean }}\left(\boldsymbol{\mu}^{\mathcal{T}}, \boldsymbol{\mu}^{\mathcal{S}}\right)+\mathrm{D}_{\mathrm{cov}}\left(\boldsymbol{\Sigma}^{\mathcal{T}}, \boldsymbol{\Sigma}^{\mathcal{S}}\right) LWKD−F=γDmean (μT,μS)+Dcov(ΣT,ΣS)
我们可以使用空间金字塔池化(SPP)策略 [28; 29; 6] 来增强表示能力。具体来说,我们将特征图划分为一个 k × k k \times k k×k 的空间网格,为网格的每个单元计算一个高斯分布,然后逐个单元匹配教师和学生的高斯分布。
KL-Div [30] 和对称 KL-Div(即 Jeffreys 散度)[31] 均具有高斯函数的闭式表达式 [32],可用于知识迁移。然而,它们不是度量 [12],不知道高斯函数 [13] 空间的几何形状,即黎曼空间。相反,DWD 是测量内在距离的黎曼度量 [20]。请注意,G2DeNet [33] 提出了一种利用基于李群的几何形状的高斯函数度量,可用于定义蒸馏损失。除了高斯函数,还可以使用拉普拉斯分布和指数分布来建模特征分布。最后,虽然直方图或核密度估计不可行,但仍然可以使用概率质量函数 (PMF) 来建模特征分布,并相应地使用离散 WD 来定义蒸馏损失。有关这些方法的详细信息,请参见 A.2 节。
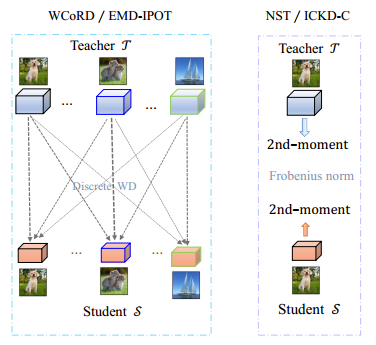
图 3:WCoRD /EMD+IPOT 和 NST/ICKD-C 的图表。
A.2 Distributions Modeling for WKD-F
回顾,对于输入图像,DNN某一层输出的特征图为3D形式,其空间高度、宽度和通道数分别为 h , w h, w h,w 和 l l l。我们将特征图重塑为矩阵 F ∈ R l × m \mathbf{F} \in \mathbb{R}^{l \times m} F∈Rl×m,其中 m = h × w m = h \times w m=h×w;我们将第 i i i 列记为特征 f i ∈ R l \mathbf{f}_i \in \mathbb{R}^l fi∈Rl,将第 j j j 行(转置后)记为特征 f ^ j ∈ R m \widehat{\mathbf{f}}_j \in \mathbb{R}^m f j∈Rm。在 WKD-F 中,我们估计通道的一阶矩 μ ∈ R l \boldsymbol{\mu} \in \mathbb{R}^l μ∈Rl 和二阶矩 Σ ∈ R l × l \boldsymbol{\Sigma} \in \mathbb{R}^{l \times l} Σ∈Rl×l:
μ = 1 m ∑ i = 1 m f i , Σ = 1 m ∑ i = 1 m ( f i − μ ) ( f i − μ ) T \boldsymbol{\mu}=\frac{1}{m} \sum_{i=1}^m \mathbf{f}_i, \quad \boldsymbol{\Sigma}=\frac{1}{m} \sum_{i=1}^m\left(\mathbf{f}_i-\boldsymbol{\mu}\right)\left(\mathbf{f}_i-\boldsymbol{\mu}\right)^T μ=m1i=1∑mfi,Σ=m1i=1∑m(fi−μ)(fi−μ)T
这些统计量用于构建参数化高斯分布 N ( μ , Σ ) \mathcal{N}(\boldsymbol{\mu}, \boldsymbol{\Sigma}) N(μ,Σ)。为了度量高斯分布之间的差异,我们使用Wasserstein距离(WD),它是一种黎曼度量。我们更倾向于使用具有对角协方差的高斯分布(Diag),而不是具有完整协方差的高斯分布(Full),因为前者在计算上更高效并且表现更好,如表3a所示。
G 2 \mathbf{G}^2 G2 DeNet。与WD不同,Wang等人[33]提出了一种名为 G 2 \mathrm{G}^2 G2 DeNet 的方法,该方法考虑高斯分布空间的李群结构,并将高斯分布嵌入到对称正定矩阵(SPD)的空间中:
N ( μ , Σ ) ↦ [ Σ + μ μ T μ μ T 1 ] 1 2 \mathcal{N}(\boldsymbol{\mu}, \boldsymbol{\Sigma}) \mapsto\left[\begin{array}{cc} \boldsymbol{\Sigma}+\boldsymbol{\mu} \boldsymbol{\mu}^T & \boldsymbol{\mu} \\ \boldsymbol{\mu}^T & 1 \end{array}\right]^{\frac{1}{2}} N(μ,Σ)↦[Σ+μμTμTμ1]21
因此,两高斯分布之间的差异定义为教师模型和学生模型高斯嵌入之间的欧氏距离。
ICKD-C 和 NST。ICKD-C [6] 使用原始通道的二阶矩来探索特征的通道间相关性,即:
M = 1 m ∑ i = 1 m f i f i T \mathbf{M}=\frac{1}{m} \sum_{i=1}^m \mathbf{f}_i \mathbf{f}_i^T M=m1i=1∑mfifiT
与通道级统计不同,NST [35] 使用原始空间的一阶矩 μ ^ ∈ R m \widehat{\mu} \in \mathbb{R}^m μ ∈Rm 和二阶矩 M ^ ∈ R m × m \widehat{\mathbf{M}} \in \mathbb{R}^{m \times m} M ∈Rm×m 来描述分布:
μ ^ = 1 l ∑ j = 1 l f ^ j , M ^ = 1 l ∑ j = 1 l f ^ j f ^ j T \widehat{\boldsymbol{\mu}}=\frac{1}{l} \sum_{j=1}^l \widehat{\mathbf{f}}_j, \quad \widehat{\mathbf{M}}=\frac{1}{l} \sum_{j=1}^l \widehat{\mathbf{f}}_j \widehat{\mathbf{f}}_j^T μ =l1j=1∑lf j,M =l1j=1∑lf jf jT
高斯分布(Diag)之间的KL散度
令
μ
=
[
μ
1
,
⋯
,
μ
l
]
T
\boldsymbol{\mu}=\left[\mu_1, \cdots, \mu_l\right]^T
μ=[μ1,⋯,μl]T 为均值,
δ
=
[
δ
1
,
⋯
,
δ
l
]
T
\boldsymbol{\delta}=\left[\delta_1, \cdots, \delta_l\right]^T
δ=[δ1,⋯,δl]T 为高斯分布(Diag)的方差。在这种情况下,KL散度和对称KL散度均有封闭形式:
D K L ( N T ∥ N S ) = 1 2 ∑ i ( μ i T − μ i S δ i S ) 2 + ( δ i T δ i S ) 2 − 2 log δ i T δ i S − 1 D S y m K L ( N T ∥ N S ) = 1 2 ∑ i ( μ i T − μ i S ) 2 ( ( 1 δ i T ) 2 + ( 1 δ i S ) 2 ) + ( δ i S δ i T ) 2 + ( δ i T δ i S ) 2 − 2 \begin{aligned} \mathbf{D}_{\mathrm{KL}}\left(\mathcal{N}^{\mathcal{T}} \| \mathcal{N}^{\mathcal{S}}\right) & =\frac{1}{2} \sum_i\left(\frac{\mu_i^{\mathcal{T}}-\mu_i^{\mathcal{S}}}{\delta_i^{\mathcal{S}}}\right)^2+\left(\frac{\delta_i^{\mathcal{T}}}{\delta_i^{\mathcal{S}}}\right)^2-2 \log \frac{\delta_i^{\mathcal{T}}}{\delta_i^{\mathcal{S}}}-1 \\[10pt] \mathbf{D}_{\mathrm{Sym} \mathrm{KL}}\left(\mathcal{N}^{\mathcal{T}} \| \mathcal{N}^{\mathcal{S}}\right) & =\frac{1}{2} \sum_i\left(\mu_i^{\mathcal{T}}-\mu_i^{\mathcal{S}}\right)^2\left(\left(\frac{1}{\delta_i^{\mathcal{T}}}\right)^2+\left(\frac{1}{\delta_i^{\mathcal{S}}}\right)^2\right)+\left(\frac{\delta_i^{\mathcal{S}}}{\delta_i^{\mathcal{T}}}\right)^2+\left(\frac{\delta_i^{\mathcal{T}}}{\delta_i^{\mathcal{S}}}\right)^2-2 \end{aligned} DKL(NT∥NS)DSymKL(NT∥NS)=21i∑(δiSμiT−μiS)2+(δiSδiT)2−2logδiSδiT−1=21i∑(μiT−μiS)2((δiT1)2+(δiS1)2)+(δiTδiS)2+(δiSδiT)2−2
其中 T \mathcal{T} T 和 S \mathcal{S} S 分别表示教师和学生模型。
拉普拉斯分布之间的KL散度
假设特征
f
=
[
f
1
,
⋯
,
f
l
]
T
∈
R
l
\mathbf{f}=\left[f_1, \cdots, f_l\right]^T \in \mathbb{R}^l
f=[f1,⋯,fl]T∈Rl 的各分量统计上相互独立,则
f
\mathbf{f}
f 的拉普拉斯分布为:
L
(
μ
,
v
)
=
∏
i
1
2
v
i
exp
(
−
∣
f
i
−
μ
i
∣
v
i
)
L(\boldsymbol{\mu}, \boldsymbol{v}) = \prod_i \frac{1}{2 v_i} \exp \left(-\frac{\left|f_i-\mu_i\right|}{v_i}\right)
L(μ,v)=i∏2vi1exp(−vi∣fi−μi∣)
其中
μ
\boldsymbol{\mu}
μ 是均值,
v
=
[
ν
1
,
⋯
,
ν
l
]
T
\boldsymbol{v}=\left[\nu_1, \cdots, \nu_l\right]^T
v=[ν1,⋯,νl]T 是尺度参数。在这种情况下,KL散度为 [53]:
D K L ( L T ∥ L S ) = ∑ i log ν i S ν i T + ∣ μ i T − μ i S ∣ ν i S + ν i T ν i S exp ( − ∣ μ i T − μ i S ∣ ν i T ) − 1 \mathbf{D}_{\mathrm{KL}}\left(L^{\mathcal{T}} \| L^{\mathcal{S}}\right) = \sum_i \log \frac{\nu_i^{\mathcal{S}}}{\nu_i^{\mathcal{T}}}+\frac{\left|\mu_i^{\mathcal{T}}-\mu_i^{\mathcal{S}}\right|}{\nu_i^{\mathcal{S}}}+\frac{\nu_i^{\mathcal{T}}}{\nu_i^{\mathcal{S}}} \exp \left(-\frac{\left|\mu_i^{\mathcal{T}}-\mu_i^{\mathcal{S}}\right|}{\nu_i^{\mathcal{T}}}\right)-1 DKL(LT∥LS)=i∑logνiTνiS+νiS μiT−μiS +νiSνiTexp(−νiT μiT−μiS )−1
指数分布之间的KL散度
在独立性假设下,特征
f
\mathbf{f}
f 的指数分布为:
E
(
β
)
=
∏
i
β
i
exp
(
−
β
i
f
i
)
E(\boldsymbol{\beta}) = \prod_i \beta_i \exp \left(-\beta_i f_i\right)
E(β)=i∏βiexp(−βifi)
其中
β
=
[
β
1
,
⋯
,
β
l
]
T
\beta=\left[\beta_1, \cdots, \beta_l\right]^T
β=[β1,⋯,βl]T 是速率参数。对于指数分布,KL散度的形式为 [53]:
D K L ( E T ∥ E S ) = ∑ i log β i T β i S + β i S β i T − 1 \mathbf{D}_{\mathrm{KL}}\left(E^{\mathcal{T}} \| E^{\mathcal{S}}\right) = \sum_i \log \frac{\beta_i^{\mathcal{T}}}{\beta_i^{\mathcal{S}}}+\frac{\beta_i^{\mathcal{S}}}{\beta_i^{\mathcal{T}}}-1 DKL(ET∥ES)=i∑logβiSβiT+βiTβiS−1
非参数概率质量分布(PMD)
尽管由于维度灾难的限制,非参数方法(例如直方图或核密度估计)不可行,我们仍可以使用概率质量函数(PMF)进行分布建模。具体地,给定一组特征
f
i
,
i
=
1
,
…
,
m
\mathbf{f}_i, i=1, \ldots, m
fi,i=1,…,m,特征的PMF形式如下:
p f = ∑ i = 1 m p f i ψ ( f i ) , p f i = 1 m \mathbf{p}_{\mathbf{f}}=\sum_{i=1}^m p_{\mathbf{f}_i} \psi\left(\mathbf{f}_i\right), \quad p_{\mathbf{f}_i}=\frac{1}{m} pf=i=1∑mpfiψ(fi),pfi=m1
其中 ψ ( f i ) \psi\left(\mathbf{f}_i\right) ψ(fi) 表示Kronecker函数,当 f = f i \mathbf{f}=\mathbf{f}_i f=fi 时等于1,否则等于0。令 p f T / p f S \mathbf{p}_{\mathbf{f}}^{\mathcal{T}} / \mathbf{p}_{\mathbf{f}}^{\mathcal{S}} pfT/pfS 为教师模型/学生模型的PMF,我们可以使用离散Wasserstein距离(WD)来度量它们之间的差异,即 D W D ( p f T , p f S ) \mathrm{D}_{\mathrm{WD}}\left(\mathbf{p}_{\mathbf{f}}^{\mathcal{T}}, \mathbf{p}_{\mathbf{f}}^{\mathcal{S}}\right) DWD(pfT,pfS);特征 f i T \mathbf{f}_i^{\mathcal{T}} fiT 和 f j S \mathbf{f}_j^{\mathcal{S}} fjS 之间的运输成本 c i j c_{i j} cij 计算为:
c i j = 1 − cos ( f i T , f j S ) c_{i j}=1-\cos \left(\mathbf{f}_i^{\mathcal{T}}, \mathbf{f}_j^{\mathcal{S}}\right) cij=1−cos(fiT,fjS)
需要注意的是,KL散度不适用于PMF,因为它无法处理不重叠的分布 [11]。
值得注意的是:
-
高斯分布空间是一个黎曼空间,其中Wasserstein距离(WD)是内在的距离度量 [20],而KL散度及其对称版本则不是 [12],因此它们无法感知几何结构 [13]。
-
通道或空间二阶矩的空间是对称正定矩阵的流形,而不是欧几里得空间 [38; 39]。因此,Frobenius范数并不是内在的距离度量 [35; 6],无法有效利用流形的几何结构。


















 1587
1587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











