






本文来自微信公众号“大数据”,特此说明,觉得写的相当的不错,故以此方式记录。
近年来机器学习、AI领域随着深度神经网络(DNN)的崛起而迎来新一波的春天,尤其最近两年无论学界还是业界,或是各大媒体,甚至文盲老百姓都言必称“智能”。关于这方面,可讨论的东西实在太多太多,我不想写成一本厚厚的书,所以在此仅以机器学习在计算机视觉和图像领域的人脸识别应用作为一个例子,来陪着大家看看这场热潮、浮华背后有哪些被专家学者们忽视或轻视,但却有着根本性重要的东西,并同时提出本领域的若干值得展开的创新性研究方向。好了,废话少说,且看DNN的大戏上演。
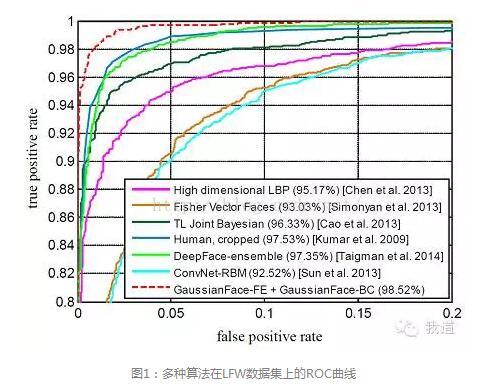
2014年对于人脸识别领域来讲可谓是“欢欣鼓舞”的一年,在LFW数据集(labeled faces in the wild)上的评测结果被连续“刷表”,首先是Facebook的AI Lab发表论文DeepFace报告了accuracy达到97.25%,紧接着Face++的《Learning Deep Face Representation》小小胜出达到97.3%,结果板凳还没坐热就被香港中文大学的Xiaoou Tang和Xiaogang Wang实验室的GaussianFace刷到了98.52%,宣称首次超越了“人类的识别能力”(97.53%)。然后,此次在新加坡VISVA 2014 winter-school上看到Xiaogang Wang报告,他们最新的DeepID2将上述记录刷到了99.15%。下图1是引自GaussianFace一文,作为展示各大新近算法那“优美”ROC曲线的一个示例。
可以想象,各大科技媒体、投资机构、业界巨头等都将目光、热忱投向了AI领域,仿佛双目所及都是满满的“$_$”;各大砖家学者、大虾菜鸟也都或奔走相告、粉墨登场如巡回演唱般,或摩拳擦掌、疯狂涌入想着趁热沾沾光、分一杯羹。
古人云,“不知者不罪”,对于那些不懂AI、机器学习以及深度神经网络(后简称DNN)理论及方法的人还情有可原,但是那些具备多年知识积淀和实战经验的砖家们,我就分不清他们是真的“too young too naive”还是另有原因了。在这场浮华背后,我为大家拨开云雾,看看那些被忽视或掩盖起来的本质问题。
1 unfair comparison各大研究机构论文中报告的accuracy,通常都会同时与其它的多个算法系统进行对比,但是这些对比是unfair的!因为它们在模型的训练阶段,使用的training data差别迥异,而且绝大多数image都是不在LFW数据集里面out-set data。众所周知,欲对比算法、模型的优劣,必先固定训练数据集与测试数据集,为各candidates营造公平的周边条件和评价准绳。
2 算法之间的性能差异未经统计检验——不靠谱
“拍拍脑袋,设计了一个新算法,一顿coding之后,放到XXX数据集上一跑,做个10-fold cross validation,拿着accuracy rate跟其它论文方法一对比,发现有0.5个百分点的提升,于是欣喜若狂、普大喜奔、paper满天飞”……这就是计算机视觉领域乃至整个AI领域的现状。然而,学过统计的人都应该提这样的问题:“算法A与算法B的差异,究竟是随机因素引起的波动,还是具有统计显著性的?它们的output error rate波动特性如何?……”这本身又可以看成一个假设检验问题,例如可使用ANOVA、F-test、t-检验等来研究,看看是否在 (=0.05)显著性水平上,算法A优于算法B这个假设是可接受的。但可笑的是,从未见有人用这种“科学”态度和精神来对待这些“科学问题”!
3 人脸识别算法性能超越人类?——我读书少,你别骗我
假设某算法A在某数据集X上的accuracy比某“人”的识别结果高,能断言算法A优于“人类”的识别性能吗?请别欺我没学过统计。这个问题有点类似上述问题2,但是稍微更复杂点。
对于一个具体的人,例如张三,他的decision model可以简记为“算法B”。而“人类”是一个类属概念,可以认为是很多不同的decision models构成的model-class。好吧,至此在我有限的知识范围内,纵观数学和计算机学界还没有人提出过一个合理的metric(度量),来评价一个算法A与某个“模型族”的性能差异,以及该差异的统计检验指标……

然而对于另一类应用,例如biometric(生物身份识别),那就千万马虎不得了。打个比方某银行推出了“刷脸取钱”的快捷服务,就是你往ATM机前一站,它能自动识别你是张三还是李四,然后验证通过就咔咔吐出一堆钞票,确实挺酷。现在拿目前最先进的算法DeepID2来看,号称accuracy 99%。于是张三在ATM机前多晃悠几十次,就没准碰上被误识别为李四,毕竟1%的概率嘛(这是个戏谑的概数,严谨来说不是这个值,此处暂且按下不表),然后把李四账户的钱全卷跑了。
通常,在金融系统中,要求在0.1%的FAR(false accept rate)下verification rate达到99%,才可以投入实用。而根据最新的研究发现,在FAR=0.1%的约束下,目前最好的算法verification rate=41.66%,还远远达不到实用的地步。
至此,我所理解的全世界专家们孜孜不倦地追求high accuracy的算法,应该是要应用到类似biometric这样的严肃场合。那么问题来了,他们为何不直接采用这类场合通用的评价标准“verification rate @ low FAR”,却笼统地用了个掩耳盗铃的accuracy。
很多技术论坛以及国际学术会议上,都常常听到某些“看起来像是”砖家大神的,吐沫横飞地讲着“用DNN可以让机器实现全自动地学习,并超越人类handcrafted的特征和方法”,抑或是言必称DNN多么多么复杂,不把自己显得高大上誓不罢休。其实在我看来,DNN是非常非常简单的一个东西,它的外在的、看似复杂的样子也只是由内在的很多简单的组件加在一起所展现出来的表面的繁杂而已(在此暂不展开说)。而且更重要的是,说handcrafted或启发式方法不好,那纯粹是一种恶意的诋毁。
首先,DNN本身的结构中,layer的数量、每个layer的node数、卷积层与全连接层的组合模式、卷积kernel的大小、max-pooling层的位置、输出层的log-transform、输入层的数据模式等等,无一不是handcrafted。除了结构和参数,就连训练方法中也融入了很多启发式的设置,例如采用drop-out来缓解耦合与过拟合,又如神经元之间以及相邻layer之间的locality-influence方式来帮助增强稀疏化。
其次,除了DNN外,无论logistic regression(LR)还是SVM或是其它很多模型,都是人类智慧的结晶,是非常美的东西。例如LR中sigmod函数(也常被用于DNN)的平滑、对称和双边饱和特性,又如SVM的最大间隔原理和VC维理论所刻画的简单性原理,这些都是极其符合自然美学的设计,也彰显了大繁至简。其实将最大间隔与VC维的理念融入DNN,寻找结合点,也是很值得研究的方向之一,直觉能够为DNN带来再一次的不小的提升。
此外,还有值得一提的是,DNN的高层网络中,某些神经元的刺激响应模式类似图3a所示,对人脸和猫脸的轮廓会输出极大响应值。联想PCA人脸识别方法中的eigenface,如图3b所示,其实两者存在很多相似的地方,这绝非偶然。实际上,DNN在某种意义上可以理解为一种级联的变换或encoder,在information loss和对非线性的处理能力上增强了;而PCA是一种线性变换,对于数据的非线性特性和丰富的细节,描述能力较差(information loss较大),所以出现图3这样的差别就不难理解了。在某种意义上可以把DNN看做“非线性化的PCA”。事实上,笔者思考和粗略提出了clustering-based PCA以及multi-stage residual-boosting PCA方法,感兴趣的读者可以交流并一起尝试研究,或许可以揭示DNN与PCA的某些内在关联。
















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









