






国科大现代信息检索——期末复习
第1讲 布尔检索
IR基本概念
·文档集Collection:固定数目文档
·目标:返回的与用户需求相关的文档
·相关性Relevance:反应对象匹配程度
布尔检索
利用AND OR NOT操作符将词项连接起来的查询(与或非)
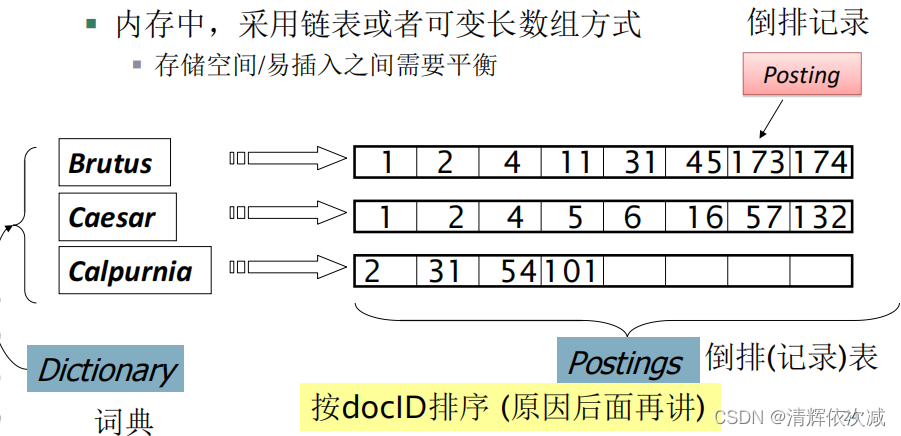
倒排索引
词项-文档(term-doc)关联矩阵

关联向量:每一列对应一篇文档,每个项对应文档中有无该词项
每一行对应一个词项,每个项对应词项在文档中是否出现
倒排索引
DF:每个词项出现的文档数目
词典+倒排记录表
布尔查询的处理
AND 对倒排记录表求交集
OR 求倒排记录并集
NOT 取非
查询优化:按照df表从小到大的顺序处理,每次从最小的开始合并
有作业
第2-1讲 索引构建
基于排序的索引构建
在构建索引时,每次解析一篇文档,因此对于每个词项而言,其倒排记录表不到最后一篇文档都是不完整的。
如果每个 (termID, docID)对占用 8个字节, 那么处理大规模语料需要大量的空间。
一般内存的容量比较小,没有办法将前面产生的倒排记录表全部放在内存中,需要在磁盘上存储中间结果。
BSBI算法
将所有记录划分为每个大小约为10M的块,收集每一块的倒排记录,排序,将倒排索引写入硬盘,最后将不同的分块合并为一个大的倒排索引。
SPIMI算法
关键思想:
- 对每个块都产生一个独立的词典(不需要在块之间进行
term-termID的映射) - 对倒排记录表不排序,按照它们出现的先后顺序排列,只对词典排序(实际上由于指针的存在,倒排记录表没有排序的必要)。
在扫描文档的同时,直接在内存中维护一个不断更新的倒排索引。以对每个块生成一个完整的倒排索引,这些独立的索引最后合并成一个大索引,但此时没有全局词典提供词项-整数ID的映射,合并过程需要进行词项字符串比较
BSBI算法和SPIMI算法的主要区别
**BSBI算法:**在分块索引阶段,BSBI算法维护一个全局Term (String) – Termid (int) 的映射表,局部索引为Termid及其倒排记录表,仍然按词典顺序排序。
**SPIMI算法:**分块索引阶段与BSBI算法不同在于建立局部词典和索引,无需全局词典。在合并阶段,将局部索引两两合并,最后产生全局词典建立Term – Termid的映射。
使用文本预处理步骤可以大大减小系统所需要存储的倒排记录表的数目,从而提高索引构建和检索的速度
动态索引构建
第3讲 索引压缩
有损压缩:丢弃一些信息-很多常用的预处理步骤可以看成是有损压缩
无损压缩:所有信息都保留-索引压缩中通常都使用无损压缩
词典压缩
定长数组方式下的词典存储:每个词项需要20(字符串)+4(词频)+4(指向倒排索引表的指针)=28个字节。
将整部词典看成单一字符串:4(词频)+4(指向倒排索引表的指针)+3(指向字符串的指针,按照实际大小决定,例如8*400000个位置需要$log_2(8 * 400000)< 24 $位来表示)+8(每个字符串平均需要8个字节)=19个字节
按块存储,假设块大小k=4,此时每4个词项只需要保留1个词项指针,但是同时需要增加4个字节(比较短,1个字节就可以)来表示每个词项的长度,因此每4个词项需要3+4=7B,比之前的节省了12-7=5B
前端编码:每个块当中 (k = 4)会有公共前缀,可以采用前端编码方式继续压缩
如果使用词干还原,由于将同一词汇的不同形式还原到词根,因此前端编码的压缩效果有限
倒排记录表压缩
倒排记录表的压缩:两种经典编码VB和γ编码(注意对gap进行编码,第一个id,后面都是gap)
可变字节(VB)码:字节的后7位是间距的有效编码区,而第1位是延续位(continuation bit)。如果该位为1,则表明本字节是某个间距编码的最后一个字节,否则不是。
要对一个可变字节编码进行解码,可以读入一段字节序列,其中前面的字节的延续位都为0,而最后一个字节的延续位为1。
γ编码:
- 将G (Gap, 间隔) 表示成长度(length)和偏移(offset)两部分
- 偏移对应G的二进制编码,只不过将首部的1去掉(因为所有的编码第一位都是1)
- 长度部分给出的是偏移的位数,采用一元编码
- 手动计算的时候先计算偏移,再根据偏移计算长度
有作业
第4讲 通配查询与拼写矫正
通配查询:包含通配符*的查询
拼写校正:查询中存在错误时的处理
通配查询
mon*: 找出所有包含以 mon开头的词项的文档
*mon: 找出所有包含以*mon结尾的词项的文档
轮排索引
基本思想:
将每个通配查询旋转,使*出现在末尾
将每个旋转后的结果存放在词典中,即B-树中
使用轮排索引的查找过程
将查询进行旋转,将通配符旋转到右部
同以往一样查找B-树,得到匹配的所有词项,将这些词项对应的倒排记录表取出
问题:相对于通常的B-树,轮排索引(轮排树)的空间要大4倍以上 (经验值)
解决了通配符查询问题,结构简单,词典巨大
k-gram索引
枚举一个词项中所有连读的k个字符构成k-gram
过程:查询mon*
先执行布尔查询: $m AND mo AND on
该布尔查询会返回所有以前缀mon开始的词项 . . .
当然也可能返回许多伪正例(false positives),比如MOON。同前面的双词索引处理短语查询一样,满足布尔查询只是满足原始查询的必要条件。因此,必须要做后续的过滤处理
剩下的词项将在词项-文档倒排索引中查找文档
k-gram索引 vs. 轮排索引
k-gram索引的空间消耗小
轮排索引不需要进行后过滤
有作业(Jaccard)
Jaccard(A,B)= ∣ A ∩ B ∣ ∣ A ∪ B ∣ \frac{|A∩B|}{|A∪B|} ∣A∪B∣∣A∩B∣(A≠0 or B≠0)
拼写矫正
候选词评价: Damerau-Levenshtein编辑距离(与Levenshtein编辑距离有区别)
两个字符串的最小编辑距离。算法定义了四种操作:
Insertion (插入) informatin - information
Deletion (删除) informationn - information
Substitution (替换)infoemation - information
Transposition of two adjacent letters(两个相邻字母的交换)infromation- information
第五讲 检索评价
常用指标,位差值 NDCG 人工标记的数据少
评价指标
召回率(Recall): RR/(RR + NR),返回的相关结果数占实际相关结果总数的比率,也称为查全率,R∈ [0,1]
正确率(Precision): RR/(RR + RN),返回的结果中真正相关结果的比率,也称为查准率, P∈[0,1]
两个指标分别度量检索效果的某个方面,忽略任何一个方面都有失偏颇。两个极端情况:返回有把握的1篇,P=100%,但R极低;全部文档都返回,R=1,但P极低
F值= 2 P R P + R \frac{2PR}{P+R} P+R2PR
Fβ= ( 1 + β 2 ) P R β 2 P + R \frac{(1+\beta^2)PR}{\beta^2P+R} β2P+R(1+β2)PR ( β \beta β>1更重视召回率,反之更重视正确率)
E值=1- 1 + b 2 b 2 p + 1 R \frac{1+b^2}{\frac{b^2}{p}+\frac{1}{R}} pb2+R11+b2 (b>1表示更重视P,E=1-Fβ,b²= 1 β 2 \frac{1}{β²} β21)
PR曲线(正确率-召回率曲线)
插值:
对于t%,如果不存在该召回率点,则定义t%为从t%到(t+10)%中最大的正确率值。
**AP(平均正确率 Average Precision)**某个查询Q共有6个相关结果,某系统排序返回了5篇相关文档,其位置分别是第1,第2,第5,第10,第20位,则AP=(1/1+2/2+3/5+4/10+5/20+0)/6
有作业和例子
NDCG
每个文档不仅仅只有相关和不相关两种情况,而是有相关度级别,比如0,1,2,3。我们可以假设,对于返回结果:
§ 相关度级别越高的结果越多越好
§ 相关度级别越高的结果越靠前越好
Kappa指标判定不同判定人间一致性
P(A)=观察到的一致性判断比例
P(E)=随机下所期望的一致性判断比例(计算方法见例子)
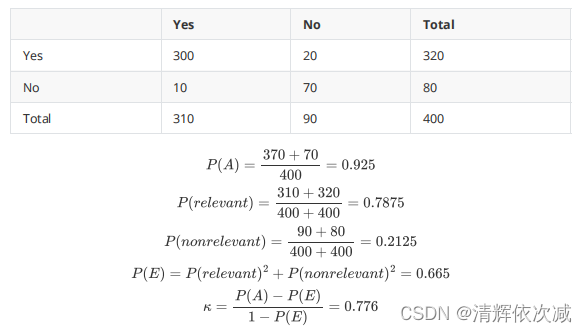
κ = P ( A ) − P ( E ) 1 − P ( E ) \kappa=\frac{P(A)-P(E)}{1-P(E)} κ=1−P(E)P(A)−P(E) 其在[ 2 3 \frac{2}{3} 32,1.0]时,判定结果可被接受
有作业
第6讲 文档评分、词项权重计算及向量空间模型
tf-idf cos 欧式距离
词袋模型 不考虑词在文档中出现顺序
词项频率tf ①原始tf值,词项在文档中出现次数
②对数词频 Wt,d={1+log10tft,d if tft,d>0
0 otherwise
tf-idf权重计算
词项t的文档频率dft:包含t的文档篇数
词项t的idf权重(逆文档频率): idft=log10 N d f t \frac{N}{df_t} dftN
词项t的tf-idf权重指tf与idft的乘积:
Wt,d=(1+log10tft,d)*log N d f t \frac{N}{df_t} dftN
向量空间模型
二值关联矩阵:1 or 0
**tf矩阵:**tf or 0
tf-idf矩阵:tf-idf or 0.00
欧氏距离判断相似空间:平方和开根
夹角大小判断相似空间:
c o s ( q , d ) = S I M ( q , d ) = q ⋅ d ∣ q ∣ ∣ d ∣ = ∑ i = 1 ∣ V ∣ q i d i ∑ i = 1 ∣ V ∣ q i 2 ∑ i = 1 ∣ V ∣ d i 2 cos(\mathbf{q},\mathbf{d})=SIM(\mathbf{q},\mathbf{d})=\frac{\mathbf{q}\cdot\mathbf{d}}{|\mathbf{q}||\mathbf{d}|}=\frac{\sum_{i=1}^{|V|}q_id_i}{\sqrt{\sum_{i=1}^{|V|}q_i^2}}\sqrt{\sum_{i=1}^{|V|}d_i^2} cos(q,d)=SIM(q,d)=∣q∣∣d∣q⋅d=∑i=1∣V∣qi2∑i=1∣V∣qidi∑i=1∣V∣di2
qi 是第i 个词项在查询q中的tf-idf权重
di是第i 个词项在文档d中的tf-idf权重
| q \mathbf{q} q | 和 | d \mathbf{d} d | 分别是 q和 d的长度
上述公式就是 q和 d的余弦相似度,或者说向量q和d的夹角的余弦
归一化
一个向量可以通过除以它的长度进行归一化处理
∣ ∣ x ∣ ∣ 2 = ∑ i x i 2 ||x||_2=\sqrt{\sum_i{x_i^2}} ∣∣x∣∣2=∑ixi2
归一化向量的余弦相似度等价于它们的点积(或内积)
c o n s ( q , d ) = q ⋅ d = ∑ i q i ⋅ d i cons(\mathbf{q},\mathbf{d})=\mathbf{q}\cdot\mathbf{d}=\sum_i{\mathbf{q_i}\cdot\mathbf{d_i}} cons(q,d)=q⋅d=∑iqi⋅di
如果 q \mathbf{q} q 和 d \mathbf{d} d 都是长度归一化后的向量
有作业
第7讲 相关反馈及查询扩展
§相关反馈的本质是将检索返回的文档的相关性判定(不同的判定来源:人工或非人工)作为返回信息,希望提升检索效果(召回率和正确率)。
§ 相关反馈常常用于查询扩展,所以提到相关反馈往往默认为有查询扩展
§而查询扩展的最初含义是对查询进行扩充,比如:car car automobile,近年来越来越向查询重构(query reformulation or refinement)偏移,即现在的查询扩展是指对原有查询进行修改。
§ 基于相关反馈(局部方法的代表)进行查询扩展/重构
§ 基于本讲的全局方法进行查询扩展/重构
§ 局部和全局方法相结合的方法(如LCA
相关反馈分类
用户相关反馈或显式相关反馈(User Feedback or Explicit Feedback):用户显式参加交互过程
**隐式相关反馈(Implicit Feedback):**系统跟踪用户的行为来推测返回文档的相关性,从而进行反馈。
伪相关反馈或盲相关反馈(Pseudo Feedback or Blind Feedback):没有用户参与,系统直接假设返回文档的前k篇是相关的,然后进行反馈。
Rocchio算法是向量空间模型中相关反馈的实现方式
有作业
查询扩展
局部查询扩展
使用外部资源进行查询扩展
选择性查询扩展
全局查询扩展
交互式查询扩展
基于词项相似度的查询扩展
使用WordNet进行查询扩展
搜索引擎中的查询扩展
第8、9讲 概率检索模型和语言模型
BIM模型(不考虑TF和文档长度)
BIM模型通过贝叶斯公式对所求条件概率P(R=1|Q,D)展
开进行计算。BIM是一种生成式(generative)模型
对每个Q定义排序(Ranking)函数RSV(Q,D):
log P ( R = 1 ∣ D ) P ( R = 0 ∣ D ) = log P ( D ∣ R = 1 ) P ( R = 1 ) / P ( D ) P ( D ∣ R = 0 ) P ( R = 0 ) / P ( D ) 正比于 log P ( D ∣ R = 1 ) P ( D ∣ R = 0 ) \log\frac{P(R=1|D)}{P(R=0|D)}=\log\frac{P(D|R=1)P(R=1)/P(D)}{P(D|R=0)P(R=0)/P(D)}正比于\log\frac{P(D|R=1)}{P(D|R=0)} logP(R=0∣D)P(R=1∣D)=logP(D∣R=0)P(R=0)/P(D)P(D∣R=1)P(R=1)/P(D)正比于logP(D∣R=0)P(D∣R=1)
P(R=1)和P(R=0)对同一Q是常数,不起作用
其中,P(D|R=1)、P(D|R=0)分别表示在相关和不相关情况下生成文档D的概率。Ranking函数显然是随着P(R=1|D)的增长而长。
多元贝努利分布
假设M=4(四个词项分别为 I you can fly),p1=0.7, p2=0.4,
p3=0.1, p4=0.05
§ 则: P(I can fly fly)=0.7*(1-0.4)0.10.05
多项式分布
§ 假定M=4 (四个词项分别为 I you can fly),p1=0.4,
p2=0.3, p3=0.2, p4=0.1
§ 则:P(I can fly fly)=P(X1=1,X2=0,X3=1, X4=2)
=C0.40.20.10.1
§ 其中C= =12
公式推导请自行借助搜索引擎
§ BIM计算过程:目标是求排序函数P(D|R=1)/P(D|R=0)
§ 首先估计或计算每个term分别在相关文档和不相关文档中的出现概率pi =P(t|R=1)及qi =P(t|R=0)
§ 然后根据独立性假设,将P(D|R=1)/P(D|R=0) 转
化为*pi和qi的某种组合,将pi和qi*代入即可求解。
BIM模型的优缺点
§ 优点:
§ BIM模型建立在数学基础上,理论性较强
§ 缺点:
§ 需要估计参数
§ 原始的BIM没有考虑TF、文档长度因素
§ BIM中同样存在词项独立性假设
§ BIM实质上是一个idf权重公式,仅考虑了全局信息,缺少局部信息。因此需要和TF权重配合使用
BM25模型
在大规模文本检索评测语料上被证明非常有效
BM25: Pros & Cons
§ 优点
§ 一定程度上的理论化模型
§ 基于二重泊松假设——适用于绝大多数文本语料上的IR检索应用
§ 实验证明有效
§ 缺点
§ 待调参数多且参数敏感性高
§ 必须去除停用词
BM25被视为现实应用中最好的IR模型之一。即便现在基于BERT预训练语言模型的方法可以获得更好的效果,仍然需要使用BM25进行无监督过滤来保证检索精度
语言模型基本假设
基于统计建模的IR模型: 假设
▪ 简化假设:查询和文档是同一类对象,(与实际并不相符!)
▪ 已经出现了一些不采用上述假设的SLMIR模型
▪ VSM也基于同一假设
▪ 简化假设:词项之间是独立的
▪ 同样,VSM中也采用了词项独立性假设
第10讲 文本分类
线性分类器:
朴素贝叶斯(位置独立性假设)
跟机器学习的朴素贝叶斯基本一致
0概率事件使用加一平滑
朴素贝叶斯在多次竞赛中胜出 (比如 KDD-CUP 97)
§ 相对于其他很多更复杂的学习方法,朴素贝叶斯对不相关特征更具鲁棒性
§ 相对于其他很多更复杂的学习方法,朴素贝叶斯对概念漂移(concept drift)更鲁棒(概念漂移是指类别的定义随时间变化)
§ 当有很多同等重要的特征时,该方法优于决策树类方法
§ 一个很好的文本分类基准方法 (当然,不是最优的方法)
§ 如果满足独立性假设,那么朴素贝叶斯是最优的 (文本当中并不成立,但是对某些领域可能成立)
§ (训练和测试)速度非常快
§ 存储开销少
§ NB分类是一种“线上”模型,测试样本生成概率需实时计算得到
朴素贝叶斯, 什么先验(类别的排行) 后验 (在类别里面特征分布情况) 线性非线性
Rocchio
基本思想
§计算每个类的中心向量
§中心向量是所有文档向量的算术平均
§将每篇测试文档分到离它最近的那个中心向量
μ ( c ) = 1 ∣ D c ∣ ∑ d ∈ D c v ( d ) \mathbf{\mu}(c)=\frac{1}{|D_c|}\sum_{d∈D_c}\mathbf{v}(d) μ(c)=∣Dc∣1∑d∈Dcv(d)
其中 Dc 是所有属于类别 c 的文档, 是文档d的向量空间表示
Rocchio性质
§Rocchio简单地将每个类别表示成其中心向量
§中心向量可以看成类别的原型(prototype)
§分类基于文档向量到原型的相似度或聚类来进行
§并不保证分类结果与训练集一致,即得到分类器后,不能保证训练集中的文档能否正确分类
Rocchio vs. 朴素贝叶斯
§很多情况下,Rocchio的效果不如朴素贝叶斯
§一个原因是,Rocchio算法不能正确处理非凸、多模式类别问题
§非凸规划:问题不能用凸函数描述。局部最优 不一定全局最优
感知机(Perceptron)也是线性分类器
非线性分类器
kNN分类器原理
§kNN = k nearest neighbors,k近邻
§k = 1 情况下的kNN (最近邻): 将每篇测试文档分给训练集中离它最近的那篇文档所属的类别。
§1NN 不很鲁棒—一篇文档可能会分错类或者这篇文档本身就很反常
§k > 1 情况下的kNN: 将每篇测试文档分到训练集中离它最近的k篇文档所属类别中最多的那个类别
§kNN的基本原理: 邻近性假设
§我们期望一篇测试文档d与训练集中d周围邻域 文档的类别标签一样。
kNN:问题
§不需要训练过程
§但是,文档的线性预处理过程和朴素贝叶斯的训练开销相当
§对于训练集来说我们一般都要进行预处理,因此现实当中kNN的训练时间是线性的。
§当训练集非常大的时候,kNN分类的精度很高
§如果训练集很小, kNN可能效果很差。
§kNN倾向于大类,可以将相似度考虑在内来缓解这个问题。
kNN不是线性分类器
§kNN分类决策取决于k个邻居类中的多数类
§类别之间的分类面是分段线性的
§但是一般来说,很难表示成线性分类器

有作业
第11、 12 、13讲 BERT
Bert在信息检索上有什么优缺点?
Bert在什么环节计算资源消耗大?
-
计算资源消耗:bert模型是一个相对较大的模型,具有数亿个参数。因此,为了训练和使用bert模型,需要大量的计算资源和时间。
-
学习不足问题:尽管bert模型在大规模语料库上进行了预训练,但在某些任务上,它可能会出现学习不足的问题,导致性能下降。否定学习能力差。
-
处理长文本困难:bert模型只能处理长度较短的文本,而不能直接处理超过512个标记的文本。
-
预训练数据集限制:bert模型的预训练数据集主要来自于英文等大型英语语料库,并且对其他语言的支持相对较少,这可能会影响其在其他语言上的性能表现。
解决方法:
模型压缩技术可以有效的减少模型部署所需的资源,其中稀疏通过移除部分权重,使得模型中的计算可以从稠密计算转换为稀疏计算,从而达到减少内存占用,加快计算速度的效果。同时,稀疏相比于其他模型压缩方法(结构化剪枝/量化),可以在保证模型精度的情况下达到更高的压缩率,更加合适拥有大量参数的大模型。
第17讲 Web搜索
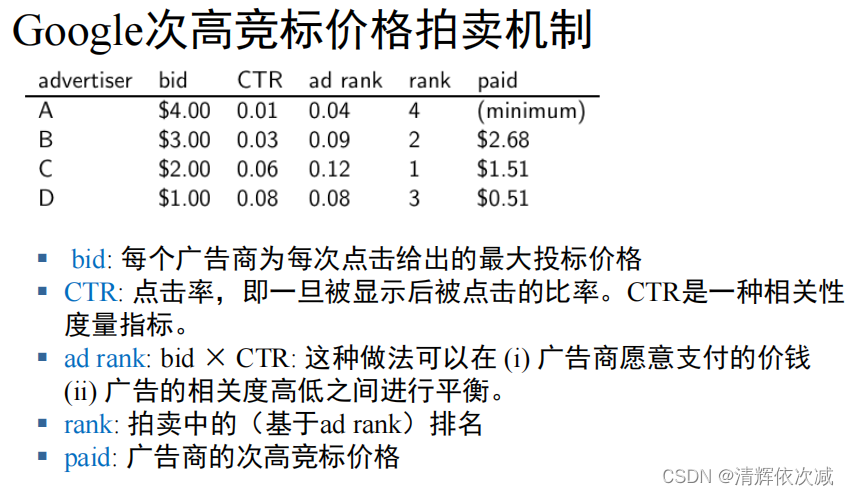
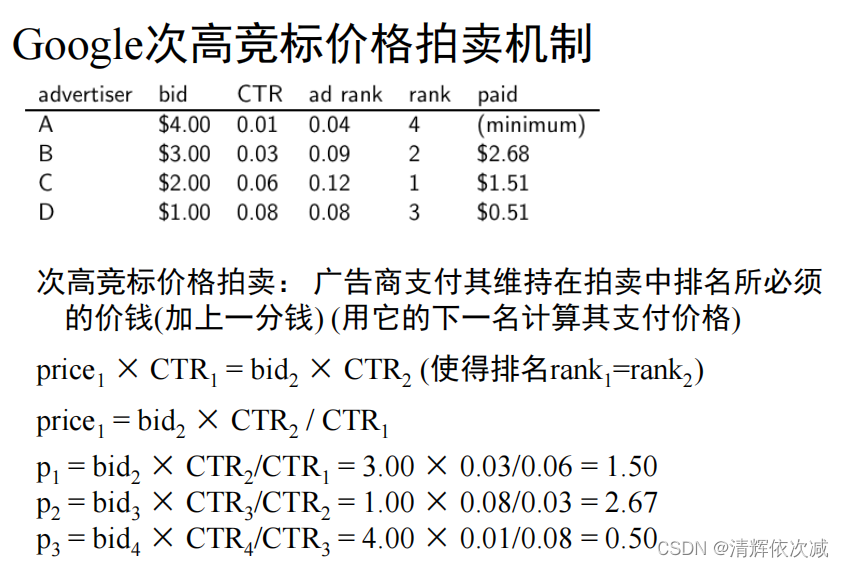
基本概念 最高价原则优缺点,爬虫 鲁棒性 协议

不是三赢!
1.关键词套现
2.商标侵权


信息爬取
采集器必须做到
礼貌性
▪ 不要高频率采集某个网站
▪ 仅仅采集robots.txt所规定的可以采集的网页
鲁棒性
▪ 能够处理采集器陷阱、重复页面、超大页面、超大网站、动态页面等问题
任意一个采集器应该做到
▪ 能够进行分布式处理
▪ 支持规模的扩展:能够通过增加机器支持更高的采集速度
▪ 优先采集高质量网页
▪ 能够持续运行:对已采集网页进行更新
第18讲 链接分析
PageRank : 一个著名的基于链接分析的排序算法(Google)
▪ HITS : 另一个著名的基于链接分析的排序算法(IBM)
计算过程请参见:https://blog.csdn.net/weixin_43829117/article/details/121771622
PageRank vs. HITS
▪ 网页的PageRank与查询主题无关,可以事先算好,因此适合于大型搜索引擎的应用。
▪ 网页的Pagerank是一种静态评分,需要与查询相关的评分结合进行网页排序
▪ HITS算法的计算与查询主题相关,检索之后再进行计算,因此,不适合于大型搜索引擎
大模型在信息检索领域的问题
请参见:https://blog.csdn.net/lzz10081203/article/details/134493624
其他复习资料:
果壳公众号里现代信息检索的例卷
国科大现代信息检索三次作业
















 5621
5621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











