







一、赛题概述及分析
1、背景介绍
邮政系统每天都会处理大量的信件,最为要紧的一环是要根据信件上的收信人邮编进行识别和分类,以便确定信件的投送地。原本这项任务是依靠大量的人工来进行,后来人们尝试让计算机来替代人工。然而,因为多数的邮编都是手写的数字,并且样式各异,所以没有统一编制的规则可以很好地用于识别和分类。
20世纪80年代,美国国家标准与技术研究所(National Institute of Standards and Technology,即NIST)建立了经典的MNIST数据集,该数据集由250个不同人手写的阿拉伯数字构成,其中50%是高中生,50%来自人口普查局的工作人员,测试集也是相同比例的手写数字数据。MNIST数据集是机器学习领域的一个经典数据集,该数据集包含6万张训练图像和1万张测试图像,其历史几乎和这个领域一样长,而且被人们深入研究。
该赛题的目的是为经典的基于手写阿拉伯数字集MNIST竞赛提供一个简单的扩展,且使用了最近发布的卡纳达语数字集。卡纳达语是印度西南部卡纳塔克邦的官方行政语言,该语言全球有近6000万人使用,根据印度宪法第344(1)和351条,卡纳达语是印度22种语言之一。该语言是使用官方的卡纳达语手迹编写的,该脚本是Brahmic家族的元音附标文字,其起源可追溯到Kadamba手迹(公元325-550),如图1、图2所示。

该数据集主要由印度班加罗尔65名志愿者手写制作而成,每位志愿者填写一张有32×40网格的A3纸,每张A3纸包含每个数字的128个实例,假设它足够大以捕获大多数自然志愿者的字体的变化,最后使用Konica Accurio-Press-C6085扫描仪以600点/英寸的分辨率扫描得到了65张4963×3509的png图像,处理后得到Kannada MNIST数据集。此外,除了主要数据集外,还有一个由另外8名20到40岁之间的志愿者额外的手写数据集(10KB的图像),称为“Dig-MNIST数据集”,该数据集是在非母语志愿者的帮助下创建的,在较小的表格上进行编写并且使用不同的扫描仪设置进行扫描,该测试集可用作域外的测试集,如图3所示。

不同的符号用于表示语言中的数字0~9,这些数字与当今世界许多地方流行的现代阿拉伯数字不同,与其他一些古老的数字系统不同,这些数字在卡纳塔克邦的日常生活中被大量使用,在印度普通车辆牌照上的普遍使用说明了这一点,如图4所示。

2、问题分析
与经典的MNIST手写数字识别问题类似,Kannada MNIST数据集也提供了一些手写数字的图片,图片一共有10类,分别对应数字0到9,与之不同的是,该数据集的数字是Kannada语中的数字。
该数据集的图像以像素点的形式给出,如何识别数据集中的数字也就是如何将手写数字的灰度图像(28像素×28像素)划分至0~9这10个类别中,因此该问题本质上是一个多分类问题。
本文将采用比较经典的4种机器学习算法来解决该问题,分别是逻辑回归、决策树、XGBoost和PCA-SVM算法,最后对各个算法所得结果及其性能进行比较分析,得出最优结果。
二、数据格式和预处理
1、数据格式
本赛题所使用的Kannada数字集的结构格式与MNIST相同,与之不同的是该赛题提交的结果会在公共测试集和私有(不可见)测试集上进行评分。该数据集的所有详细信息可在Prabhu, Vinay Uday于 2019年发表的论文[1]中查阅。
竞赛提供的数据文件为train.csv、test.csv和Dig-MNIST.csv,其中包含Kannada语言手写数字(0~9)的灰度图像。每个图像为28×28像素,总计784像素,每个像素取值为0~255之间(含)的整数,该值越大表示像素颜色越深。训练数据文件train.csv中有785列,第1列为标签列,其余列为图像的像素值即像素列,每个像素列有第1行均为pixel{x},其中x为0~783之间(含0和783)的整数。将x分解为x=i×28+j,i和j为0~27之间(含0和27)的整数,则可定位该像素在28×28像素矩阵的第i行、第j列(索引从0开始)。例如,pixel31表示从左数第4列,从上数第二行的像素。如果去掉“pixel”前缀,则像素组成图像如下:
赛题提供的数据集共4个文件,其大小和数据规格如表1所示。
| 文件名 | 文件大小 | 数据规格(行数, 列数) |
|---|---|---|
| Dig-MNIST.csv | 18.4MB | (10240, 785) |
| sample_submission.csv | 0.03MB | (5000, 2) |
| test.csv | 8.67MB | (5000, 785) |
| train.csv | 104.75MB | (60000, 785) |
2、数据预处理
观察整个数据集,不存在数据缺失等情况,训练和测试数据文件前几行如表2、表3所示。
| label | pixel0 | pixel1 | pixel2 | ... | pixel774 | pixel780 | pixel781 | pixel782 | pixel783 | |
| 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 |
| 3 | 3 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 |
| 4 | 4 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 |
将训练数据按标签类型,可看到每个标签类型有6000个训练样本,共60000个样本,如表4所示。
| id | pixel0 | pixel1 | pixel2 | ... | pixel774 | pixel780 | pixel781 | pixel782 | pixel783 | |
| 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 |
| 3 | 3 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 |
| 4 | 4 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 |
| label | |
| 0 | 6000 |
| 1 | 6000 |
| 2 | 6000 |
| 3 | 6000 |
| 4 | 6000 |
| 5 | 6000 |
| 6 | 6000 |
| 7 | 6000 |
| 8 | 6000 |
| 9 | 6000 |
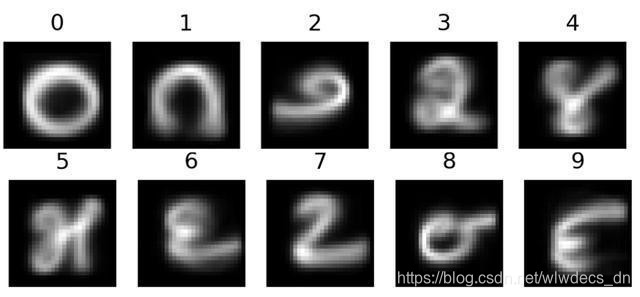
训练集每一类图片的前10张图片,共100张图片,如图5所示。

三、模型训练和识别
分类学习是最为常见的监督学习问题,并且其中的经典模型也最为广泛地被应用。本赛题属于多分类(Multiclass Classification)的问题,本文将利用多个常用算法模型分别来解决该问题,并对比各个模型得到的分类结果,利用准确率、召回评估其性能。
1、逻辑回归算法
逻辑回归(Logistic Regression),与它的名字恰恰相反,它是一个分类器而非回归方法,在一些文献里它也被称为logit回归、最大熵分类器(MaxEnt)、对数线性分类器等。
使用sklearn.linear_model中的LogisticRegression方法来训练逻辑回归分类器,其主要参数设置如下:
其中,C为正则化系数λ的倒数,float类型,默认为1.0,必须是正浮点型数,越小的数值表示越强的正则化;solver,选择用于求解最大化“似然对数”的算法,对于多分类问题,应使用“newton-cg”“sag”、“saga”“lbfgs”等,此处采用lbfgs;multi_class为多分类问题选择训练策略,设置为multinomial。设置好参数后进行训练并利用得到的模型对测试集进行数字识别,使用模型自带的评估函数进行准确性测评得到准确度为0.9655,用sklearn.metrics里面的classification_report模块对识别结果做更加详细的分析,得到结果如表5所示。可以看到,逻辑回归模型能够以比较高的准确度识别Kannada手写体数字,平均而言,各项指标都在97%上下,结果以混淆矩阵表示如图6所示。
| precision | recall | f1-score | support | |
| 0 | 0.96 | 0.96 | 0.96 | 1166 |
| 1 | 0.98 | 0.98 | 0.98 | 1235 |
| 2 | 0.99 | 0.99 | 0.99 | 1173 |
| 3 | 0.95 | 0.95 | 0.95 | 1219 |
| 4 | 0.97 | 0.98 | 0.98 | 1189 |
| 5 | 0.97 | 0.96 | 0.97 | 1216 |
| 6 | 0.96 | 0.93 | 0.95 | 1196 |
| 7 | 0.92 | 0.93 | 0.93 | 1154 |
| 8 | 0.98 | 0.98 | 0.98 | 1197 |
| 9 | 0.97 | 0.98 | 0.98 | 1255 |
| accuracy | 12000 | |||
| macro avg | 0.97 | 0.97 | 0.97 | 12000 |
| weighted avg | 0.97 | 0.97 | 0.97 | 12000 |

2、决策树算法
决策树是一种树型结构,其中每个内部节结点表示在一个属性上的测试,每一个分支代表一个测试输出,每个叶结点代表一种类别。 决策树学习是以实例为基础的归纳学习,其采用的是自顶向下的递归方法,基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子节点的处的熵值为零,此时每个叶结点中的实例都属于同一类。在决策树的算法中,建立决策树的关键,即在当前状态下选择哪个属性作为分类依据。根据不同的目标函数,建立决策树主要有ID3、C4.5和CART三种算法,主要的区别就是选择的目标函数不同,ID3使用的是信息增益,C4.5使用信息增益率,CART使用的是Gini系数,本文采用CART算法。参数设置如下:
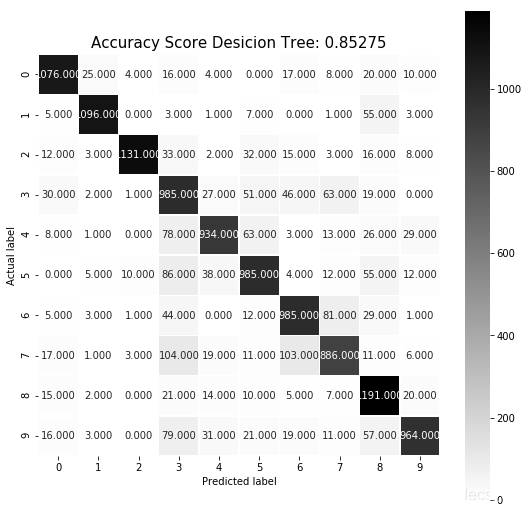
其中,max_depth为决策树最大深度,常用来解决过拟合,通常取值10-100之间,此处取10。使用模型自带的评估函数进行准确性测评得到准确度为0.85275,sklearn.metrics里面的classification_report模块对识别结果平均也在0.85左右,混淆矩阵如图7所示。
3、XGBoost算法
XGBoost实现的是一种通用的Tree Boosting算法,此算法的一个代表为梯度提升决策树(Gradient Boosting Decision Tree, GBDT),又名MART(Multiple Additive Regression Tree)。
GBDT的原理是,首先使用训练集和样本真值训练一棵树,然后使用这棵树预测训练集,得到每个样本的预测值,由于预测值与真值存在偏差,所以二者相减可以得到“残差”。接下来训练第二棵树,此时不再使用真值,而是使用残差作为标准答案。两棵树训练完成后,可以再次得到每个样本的残差,然后进一步训练第三棵树,以此类推。树的总棵数可以人为指定,也可以监控某些指标(例如验证集上的误差)来停止训练。设置模型参数如下:
其中,early_stopping_rounds为早期停止次数 ,假设为100,验证集的误差迭代到一定程度在100次内不能再继续降低,就停止迭代,此处设置为5。Verbose设置为True,则对evals中元素的评估结果会输出在结果中。
相比前2个算法,该算法明显需要的时间更长。等待大约10分钟后,迭代100次,得到精确度为95.76%,与逻辑回归算法性能相近,迭代结果较长,部分输出如图8所示。

4、基于PCA降维的SVM算法
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的学习算法就是求解凸二次规划的最优化算法。
PCA算法主要思路是:数据从原来的坐标系转换到新的坐标系,由数据本身决定。转换坐标系时,以方差最大的方向作为坐标轴方向,因为数据的最大方差给出了数据的最重要的信息。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选择与第一个新坐标轴正交且方差次大的方向。重复该过程,重复次数为原始数据的特征维数。
通过这种方式获得的新的坐标系,大部分方差都包含在前面几个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面的几个含有绝大部分方差的坐标轴。事实上,这样也就相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,也就实现了数据特征的降维处理。
利用sklearn.decomposition中提供的PCA模块进行模型构建,设置参数如下:
经过测试可以发现,该算法运行速度快,且准确度能达到0.99,如图9所示。

四、性能评估与对比
经过以上测试,四种方法对该Kannada MNIST数据集分类所得score情况总结如表6、图10所示。
| Model | Score | |
| 3 | PCA | 0.990833 |
| 0 | LogisticRegression | 0.960250 |
| 2 | XGBOOST | 0.957583 |
| 1 | Decision Tree | 0.852750 |

综上测试可以得到,基于PCA降维的SVM算法时间复杂度最小,运算耗费资源最少,能够达到的准确度越高,通过多次在测试数据test.csv上生成提交文件,并提交到Kaggle网站,最后综合得分也是该算法最优,最终达到的分数为0.97。
五、参考文献
[1] Prabhu, Vinay Uday, Sanghyun Han, Dian Ang Yap, Mihail Douhaniaris, Preethi Seshadri, and John Whaley. “Fonts-2-Handwriting: A Seed-Augment-Train framework for universal digit classification.” arXiv preprint arXiv:1905.08633 (2019). [ https://arxiv.org/abs/1905.08633 ]















 3766
3766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











