







矩阵乘法在深度学习中应用十分广泛,记录一下常见的矩阵乘法
常规方法
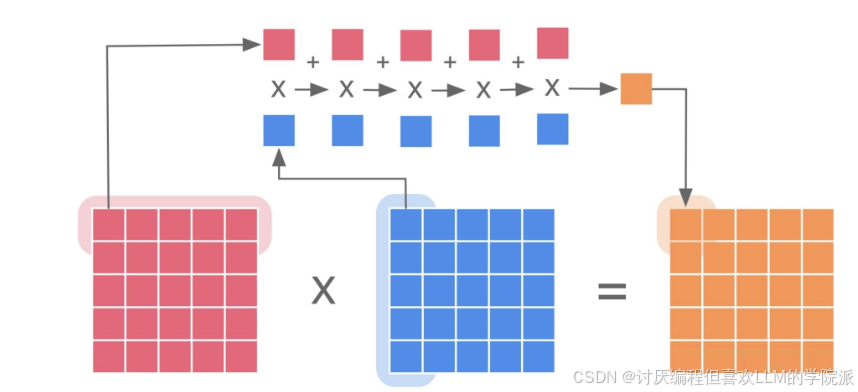
行乘列后相加
时间复杂度()
卷积优化
假设使用橙色矩阵作为Filter,蓝色为input特征图
使用卷积后会得到后面的图

但是通过对卷积核和输入特征图进行重新排列,可以将卷积操作转换成矩阵乘法。卷积核被展开成行向量,输入特征图也被转换为矩阵

卷积操作可以通过滑动窗口完成,但也可以通过重新排列成矩阵乘法的形式来加速计算。
Tiling技术
由于GPU中的 Global Memory 慢而 Shared Memory 快,通过将数据从 Global Memory 加载到 Shared Memory 中可以减少访问延迟,从而加快计算。
原理
将矩阵分成多个k*k的小块,在分布计算中,先将所需的块从GlobalMemory中加载到SharedMemory然后计算。
减少内存访问次数:假设每个块的大小是 K \times K ,那么通过将整个数据块加载到 Shared Memory 并反复使用,可以将 Global Memory 的访问次数减少 K 倍。这种方式可以有效降低内存访问延迟,提高数据重用率。
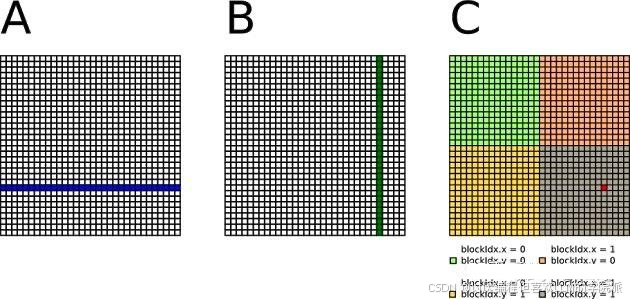
下图展示在GPU上使用矩阵乘时,通常将矩阵划分成多个小块(Tiles),每个块由多个线程来处理。每个线程块中的线程会将对应的小块数据加载到 Shared Memory 中,以减少对 Global Memory 的访问。这样可以加速计算,特别是对于大矩阵的乘法。
GEMM通用矩阵乘
通过将内存的复用来优化矩阵乘
实现技术
1. Loop 循环优化 (Loop tiling)
2. 多级缓存 (memory hierarchy)

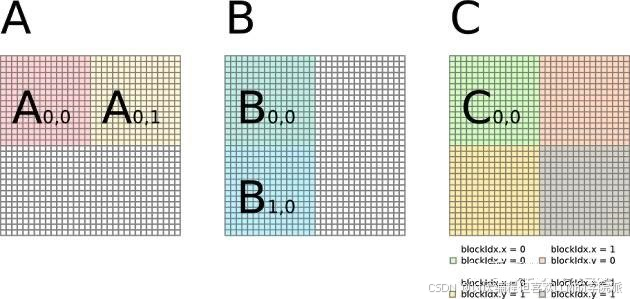
看图可知:
A先按照列分块,后按行分块后输入到L2cache中
B先按行分块输入到L3cache中,后按列分块,以此取到L1cache中进行计算
计算结果输出到寄存器中保存。
- Macro-Kernel(宏内核): Macro-kernel 是指高级别的循环结构,负责管理多个 micro-kernel 的执行。在矩阵乘法中,它通常用于处理大规模的矩阵计算,例如管理整个矩阵乘法的批处理过程。
- Micro-Kernel(微内核): Micro-kernel 是指低级别的循环结构,负责执行实际的矩阵乘法操作。它通常用于管理单个矩阵块的计算,以实现更细粒度的并行化和优化。
参考

















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









