







 本文探讨了字符集在计算机中的作用,从ASCII码到多字节字符集如GB_2312,解释了多字节字符集的工作原理。随着全球化需求,Unicode应运而生,旨在统一各种字符编码,减少转换问题。文中还介绍了Unicode的17个平面和UTF-8、UTF-16、UTF-32等编码格式,以及字节序的概念。
本文探讨了字符集在计算机中的作用,从ASCII码到多字节字符集如GB_2312,解释了多字节字符集的工作原理。随着全球化需求,Unicode应运而生,旨在统一各种字符编码,减少转换问题。文中还介绍了Unicode的17个平面和UTF-8、UTF-16、UTF-32等编码格式,以及字节序的概念。
=======================事情是这样的==========================
在调试某程序时,发生了这样的错误:
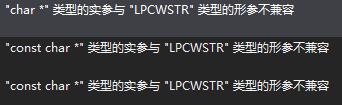
char 与 LPCWSTR 类型不兼容
搜索了一下发现是字符集的原因。
项目>>属性>>字符集>>使用多字节字符集
或者,每个字符串“xxxxx”改为_T("xxxxx"),char类型改为wchar_t 或者 LPCSTR
即可解决。
于是深入探究一下字符集的相关
=======================以下正文==============================
计算机中每一个字符都是由编码表示的。
我们最熟悉的 ASCII码:
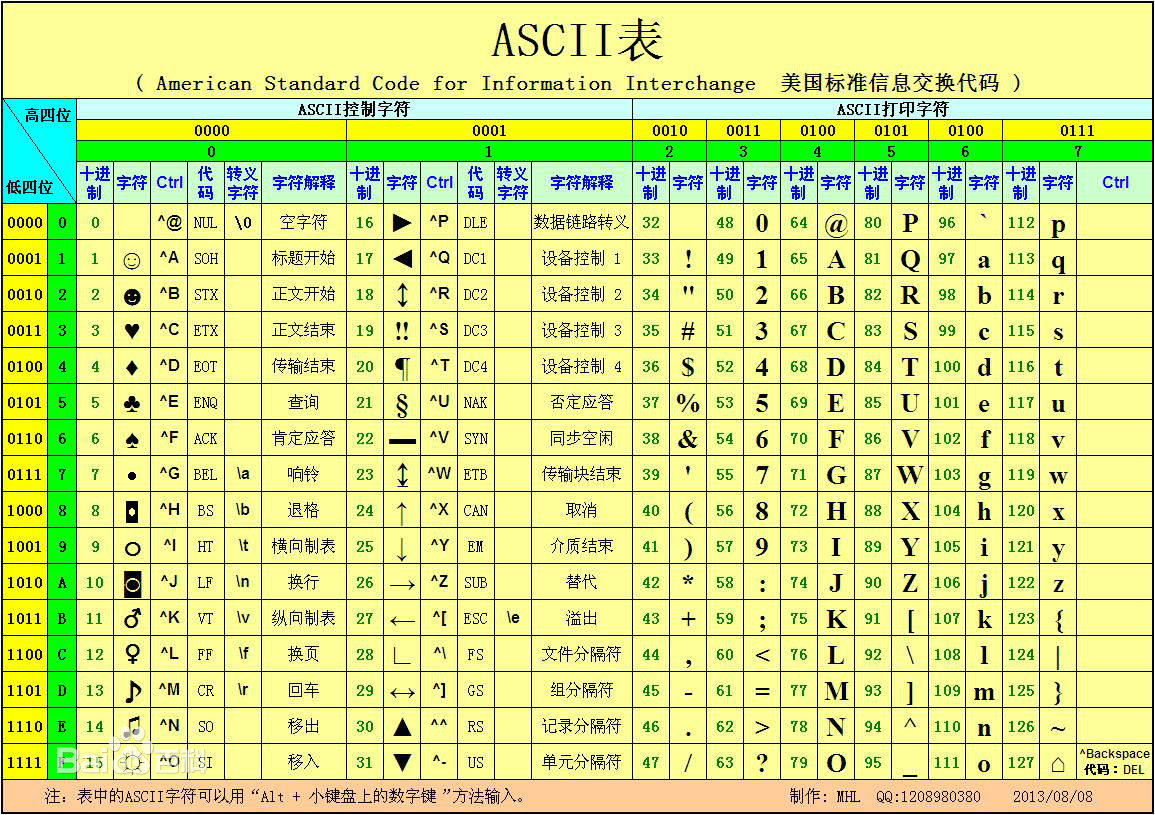
全称:American Standard Code for Information Interchange 美国标准信息交换代码
(一直以为是II是罗马数字2……)
该代码是由是由美国国家标准学会(American National Standard Institute , ANSI )制定的
后来,又进行了扩展,由最初的7位128个字符扩展到8位256个字符:
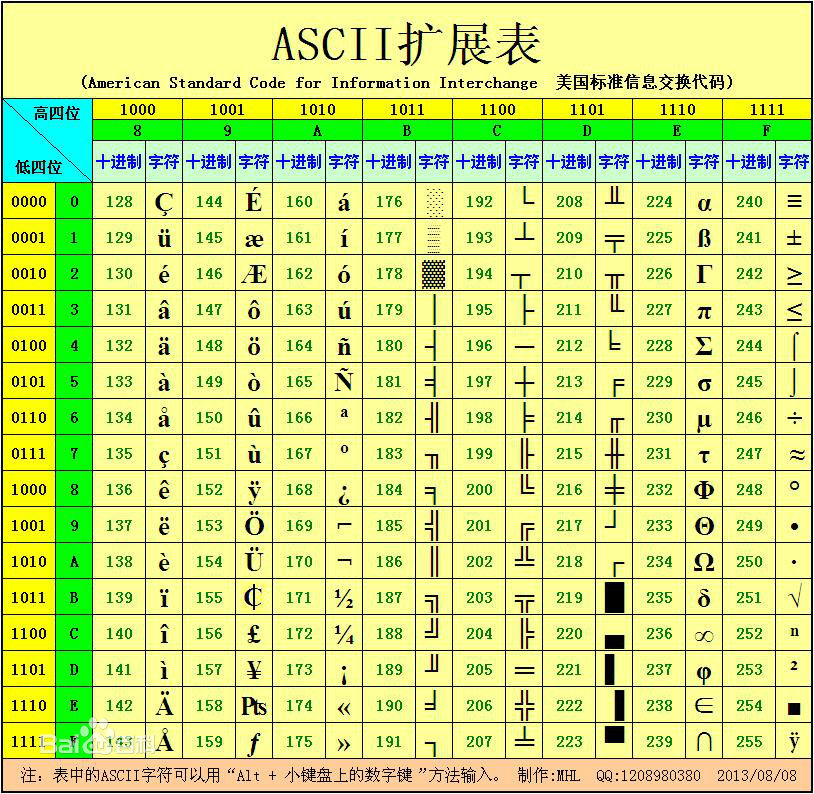
再后来,又有其他国家文字的加入,各国都需要有自己的字符集。
于是他们在ASCII的基础上,制定了自己的字符集,这些由ASCII派生出来的字符集都成为ASCI字符集,(这些字符集都是以7位128个字符的ASCII为基础)
正式的名称:MBCS(Multi-Byte Chactacter System,即多字节字符系统)
最常见的GB_2312就是其中之一。
以GB_2312为例:
GB_2312收录简化汉字及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共7445个图形字符。其中包括6763个汉字,其中一级汉字3755个,二级汉字3008个;包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
(科普:汉字大概6800个)
所谓 多字节字符集 的精髓就是,用多个字节的组合来表示代码。
例如:“连通”两个字的编码为:C1 AC CD A8
C1 AC 表示 “连”,
C1为leading byte 引导字节,可以理解为“区号”,当leading byte 小于128时,自动作为ASCII码进行处理。
AC为实际编码字节,可以理解为“位号”
分区表示:
GB_2312中对所收汉字进行了“分区”处理,每区含有94个汉字/符号。这种表示方式也称为区位码。
各区包含的字符如下:01-09区为特殊符号;16-55区为一级汉字,按拼音排序;56-87区为二级汉字,按部首/笔画排序;10-15区及88-94区则未有编码。
双字节表示
两个字节中前面的字节为第一字节,后面的字节为第二字节。习惯上称第一字节为“高字节”,而称第二字节为“低字节”。
“高位字节”使用了0xA1-0xF7(把01-87区的区号加上0xA0),“低位字节”使用了0xA1-0xFE(把01-94加上0xA0)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1950
1950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









