







背景
最近在使用hadoop的distcp传输文件时,在不想占用yarn上集群资源使用local传输,测试无论如何设置参数map都是1,所以阅读了一下distcp是如何提交mr的,以解决可以并行提交该作业。
一.Distcp提交mr过程
1.Distcp.main()入口
/**
* Main function of the DistCp program. Parses the input arguments (via OptionsParser),
* and invokes the DistCp::run() method, via the ToolRunner.
* @param argv Command-line arguments sent to DistCp.
*/
public static void main(String argv[]) {
int exitCode;
try {
DistCp distCp = new DistCp();
Cleanup CLEANUP = new Cleanup(distCp);
ShutdownHookManager.get().addShutdownHook(CLEANUP,
SHUTDOWN_HOOK_PRIORITY);
exitCode = ToolRunner.run(getDefaultConf(), distCp, argv);
}
catch (Exception e) {
LOG.error("Couldn't complete DistCp operation: ", e);
exitCode = DistCpConstants.UNKNOWN_ERROR;
}
System.exit(exitCode);
}
我们在命令行执行hadoop distcp url url 时最后会进入DistCp.main()中
2.ToolRunner.run()
public static int run(Configuration conf, Tool tool, String[] args)
throws Exception{
if (CallerContext.getCurrent() == null) {
CallerContext ctx = new CallerContext.Builder("CLI").build();
CallerContext.setCurrent(ctx);
}
if(conf == null) {
conf = new Configuration();
}
GenericOptionsParser parser = new GenericOptionsParser(conf, args);
//set the configuration back, so that Tool can configure itself
tool.setConf(conf);
//get the args w/o generic hadoop args
String[] toolArgs = parser.getRemainingArgs();
return tool.run(toolArgs);
}
解析hadoop配置文件及在提交命令时的distcp添加的参数
3.tool.run()
public int run(String[] argv) {
if (argv.length < 1) {
OptionsParser.usage();
return DistCpConstants.INVALID_ARGUMENT;
}
try {
//缓存distcp提交参数
context = new DistCpContext(OptionsParser.parse(argv));
checkSplitLargeFile();
setTargetPathExists();
LOG.info("Input Options: " + context);
} catch (Throwable e) {
LOG.error("Invalid arguments: ", e);
System.err.println("Invalid arguments: " + e.getMessage());
OptionsParser.usage();
return DistCpConstants.INVALID_ARGUMENT;
}
try {
execute();
} catch (InvalidInputException e) {
LOG.error("Invalid input: ", e);
return DistCpConstants.INVALID_ARGUMENT;
} catch (DuplicateFileException e) {
LOG.error("Duplicate files in input path: ", e);
return DistCpConstants.DUPLICATE_INPUT;
} catch (AclsNotSupportedException e) {
LOG.error("ACLs not supported on at least one file system: ", e);
return DistCpConstants.ACLS_NOT_SUPPORTED;
} catch (XAttrsNotSupportedException e) {
LOG.error("XAttrs not supported on at least one file system: ", e);
return DistCpConstants.XATTRS_NOT_SUPPORTED;
} catch (Exception e) {
LOG.error("Exception encountered ", e);
return DistCpConstants.UNKNOWN_ERROR;
}
return DistCpConstants.SUCCESS;
}
tool是个接口有很多实现类, 这里在Distcp的开始就创建了实现类的对象,并初始化传递参数的对象类 DistCpContext 所以我们进入DistCp.run()
4.execute提交作业
public Job execute() throws Exception {
Preconditions.checkState(context != null,
"The DistCpContext should have been created before running DistCp!");
Job job = createAndSubmitJob();
if (context.shouldBlock()) {
waitForJobCompletion(job);
}
return job;
}
创建和提交job
5.createAndSubmitJob()
public Job createAndSubmitJob() throws Exception {
assert context != null;
assert getConf() != null;
Job job = null;
try {
synchronized(this) {
//Don't cleanup while we are setting up.
metaFolder = createMetaFolderPath();
jobFS = metaFolder.getFileSystem(getConf());
//创建job
job = createJob();
}
prepareFileListing(job);
//提交job
job.submit();
submitted = true;
} finally {
if (!submitted) {
cleanup();
}
}
String jobID = job.getJobID().toString();
job.getConfiguration().set(DistCpConstants.CONF_LABEL_DISTCP_JOB_ID,
jobID);
LOG.info("DistCp job-id: " + jobID);
return job;
}
5.1job的创建
private Job createJob() throws IOException {
String jobName = "distcp";
String userChosenName = getConf().get(JobContext.JOB_NAME);
if (userChosenName != null)
jobName += ": " + userChosenName;
Job job = Job.getInstance(getConf());
job.setJobName(jobName);
job.setInputFormatClass(DistCpUtils.getStrategy(getConf(), context));
job.setJarByClass(CopyMapper.class);
configureOutputFormat(job);
job.setMapperClass(CopyMapper.class);
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputFormatClass(CopyOutputFormat.class);
job.getConfiguration().set(JobContext.MAP_SPECULATIVE, "false");
job.getConfiguration().set(JobContext.NUM_MAPS,
String.valueOf(context.getMaxMaps()));
context.appendToConf(job.getConfiguration());
return job;
}
MapReduce作业参数设置
这里出现了我们关注的map个数的参数,key JobContext.NUM_MAPS 可以看到这个配置为mapreduce.job.maps;我们在提交distcp命令时,会把参数项目初始化到这个对象里,这里的getMaxMaps() 就是 -m指定的值,具体的命令为:
hadoop distcp -m x url1 url2
5.2job的提交
在看一下作业是如何提交,从上边创建可以看出是可以设置map个数的
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
connect();
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
在这里可以看到,在提交作业前做了还做了几件事情,一是设置作态,选择API,还有就是一个连接,我们在看一下这个连接具体是做的什么事情
5.2.1判断提交模式
private synchronized void connect()
throws IOException, InterruptedException, ClassNotFoundException {
if (cluster == null) {
cluster =
ugi.doAs(new PrivilegedExceptionAction<Cluster>() {
public Cluster run()
throws IOException, InterruptedException,
ClassNotFoundException {
return new Cluster(getConfiguration());
}
});
}
}
这里其实就是初始化了一个cluster对象,让我们在看看这cluster具体是什么
public Cluster(Configuration conf) throws IOException {
this(null, conf);
}
public Cluster(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
this.conf = conf;
this.ugi = UserGroupInformation.getCurrentUser();
initialize(jobTrackAddr, conf);
}
初始化job和配置
private void initialize(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
//初始化Provider
initProviderList();
final IOException initEx = new IOException(
"Cannot initialize Cluster. Please check your configuration for "
+ MRConfig.FRAMEWORK_NAME
+ " and the correspond server addresses.");
if (jobTrackAddr != null) {
LOG.info(
"Initializing cluster for Job Tracker=" + jobTrackAddr.toString());
}
for (ClientProtocolProvider provider : providerList) {
LOG.debug("Trying ClientProtocolProvider : "
+ provider.getClass().getName());
ClientProtocol clientProtocol = null;
try {
if (jobTrackAddr == null) {
clientProtocol = provider.create(conf);
} else {
clientProtocol = provider.create(jobTrackAddr, conf);
}
if (clientProtocol != null) {
clientProtocolProvider = provider;
client = clientProtocol;
LOG.debug("Picked " + provider.getClass().getName()
+ " as the ClientProtocolProvider");
break;
} else {
LOG.debug("Cannot pick " + provider.getClass().getName()
+ " as the ClientProtocolProvider - returned null protocol");
}
} catch (Exception e) {
final String errMsg = "Failed to use " + provider.getClass().getName()
+ " due to error: ";
initEx.addSuppressed(new IOException(errMsg, e));
LOG.info(errMsg, e);
}
}
if (null == clientProtocolProvider || null == client) {
throw initEx;
}
}
首先初始化了initProvider ,创建符合条件ClientProtocol
initProvider 的初始化
static Iterable<ClientProtocolProvider> frameworkLoader =
ServiceLoader.load(ClientProtocolProvider.class);
private volatile List<ClientProtocolProvider> providerList = null;
private void initProviderList() {
if (providerList == null) {
synchronized (frameworkLoader) {
if (providerList == null) {
List<ClientProtocolProvider> localProviderList =
new ArrayList<ClientProtocolProvider>();
try {
for (ClientProtocolProvider provider : frameworkLoader) {
localProviderList.add(provider);
}
} catch(ServiceConfigurationError e) {
LOG.info("Failed to instantiate ClientProtocolProvider, please "
+ "check the /META-INF/services/org.apache."
+ "hadoop.mapreduce.protocol.ClientProtocolProvider "
+ "files on the classpath", e);
}
providerList = localProviderList;
}
}
}
}
从上边代码可以看出,首先把 ClientProtocolProvider的实现类都添加到frameworkLoader 对象中,在次循环frameworkLoader 添加到providerList ,目前ClientProtocolProvider实现只有两个
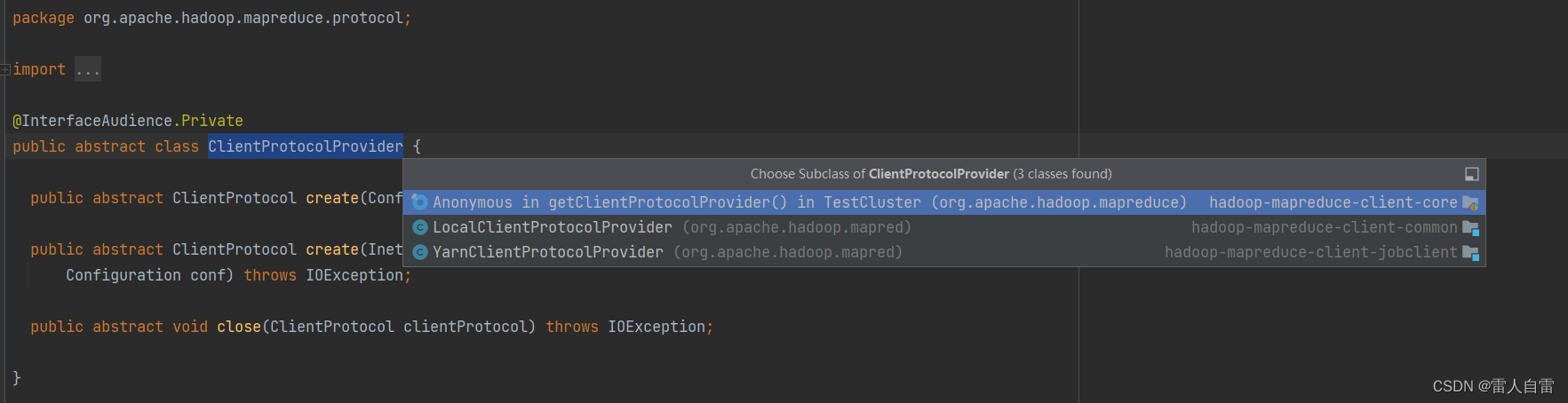
我们应该用的local模式 查看一下create方法
@Override
public ClientProtocol create(Configuration conf) throws IOException {
String framework =
conf.get(MRConfig.FRAMEWORK_NAME, MRConfig.LOCAL_FRAMEWORK_NAME);
if (!MRConfig.LOCAL_FRAMEWORK_NAME.equals(framework)) {
return null;
}
conf.setInt(JobContext.NUM_MAPS, 1);
return new LocalJobRunner(conf);
}
答案就在此处了,在选择local时,就把map数设置成1 了,导致前边 -m参数无效
6.LocalJobRunner如何工作
回到5.2中查看job的提交,submitter.submitJobInternal(Job.this, cluster);
6.1submitJobInternal()
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException{
//validate the jobs output specs
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate" +
"data spill is enabled");
}
copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
//在client中以设置好了map数, 所以此处的maps业务1
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
int maxMaps = conf.getInt(MRJobConfig.JOB_MAX_MAP,
MRJobConfig.DEFAULT_JOB_MAX_MAP);
if (maxMaps >= 0 && maxMaps < maps) {
throw new IllegalArgumentException("The number of map tasks " + maps +
" exceeded limit " + maxMaps);
}
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList<String> trackingIds = new ArrayList<String>();
for (Token<? extends TokenIdentifier> t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// Write job file to submit dir
writeConf(conf, submitJobFile);
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, job.getCredentials());
//client的类的作业提交
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}
job作业的参数设置,最后还是交给client做真正的作业执行
6.2LocalJobRunner 作业的提交
public org.apache.hadoop.mapreduce.JobStatus submitJob(
org.apache.hadoop.mapreduce.JobID jobid, String jobSubmitDir,
Credentials credentials) throws IOException {
Job job = new Job(JobID.downgrade(jobid), jobSubmitDir);
job.job.setCredentials(credentials);
return job.status;
}
这不没有什么操作,查看Job
6.3Job对象初始化
public Job(JobID jobid, String jobSubmitDir) throws IOException {
this.systemJobDir = new Path(jobSubmitDir);
this.systemJobFile = new Path(systemJobDir, "job.xml");
this.id = jobid;
JobConf conf = new JobConf(systemJobFile);
this.localFs = FileSystem.getLocal(conf);
String user = UserGroupInformation.getCurrentUser().getShortUserName();
this.localJobDir = localFs.makeQualified(new Path(
new Path(conf.getLocalPath(jobDir), user), jobid.toString()));
this.localJobFile = new Path(this.localJobDir, id + ".xml");
// Manage the distributed cache. If there are files to be copied,
// this will trigger localFile to be re-written again.
localDistributedCacheManager = new LocalDistributedCacheManager();
localDistributedCacheManager.setup(conf);
// Write out configuration file. Instead of copying it from
// systemJobFile, we re-write it, since setup(), above, may have
// updated it.
OutputStream out = localFs.create(localJobFile);
try {
conf.writeXml(out);
} finally {
out.close();
}
this.job = new JobConf(localJobFile);
// Job (the current object) is a Thread, so we wrap its class loader.
if (localDistributedCacheManager.hasLocalClasspaths()) {
setContextClassLoader(localDistributedCacheManager.makeClassLoader(
getContextClassLoader()));
}
profile = new JobProfile(job.getUser(), id, systemJobFile.toString(),
"http://localhost:8080/", job.getJobName());
status = new JobStatus(id, 0.0f, 0.0f, JobStatus.RUNNING,
profile.getUser(), profile.getJobName(), profile.getJobFile(),
profile.getURL().toString());
jobs.put(id, this);
if (CryptoUtils.isEncryptedSpillEnabled(job)) {
try {
int keyLen = conf.getInt(
MRJobConfig.MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS,
MRJobConfig
.DEFAULT_MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS);
KeyGenerator keyGen =
KeyGenerator.getInstance(INTERMEDIATE_DATA_ENCRYPTION_ALGO);
keyGen.init(keyLen);
Credentials creds =
UserGroupInformation.getCurrentUser().getCredentials();
TokenCache.setEncryptedSpillKey(keyGen.generateKey().getEncoded(),
creds);
UserGroupInformation.getCurrentUser().addCredentials(creds);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating encrypted spill key", e);
}
}
this.start();
}
解析参数和设置一些需要的目录参数
6.4start()
public void run() {
JobID jobId = profile.getJobID();
JobContext jContext = new JobContextImpl(job, jobId);
org.apache.hadoop.mapreduce.OutputCommitter outputCommitter = null;
try {
outputCommitter = createOutputCommitter(conf.getUseNewMapper(), jobId, conf);
} catch (Exception e) {
LOG.info("Failed to createOutputCommitter", e);
return;
}
try {
//根据job参数切分rtask个数
TaskSplitMetaInfo[] taskSplitMetaInfos =
SplitMetaInfoReader.readSplitMetaInfo(jobId, localFs, conf, systemJobDir);
int numReduceTasks = job.getNumReduceTasks();
outputCommitter.setupJob(jContext);
status.setSetupProgress(1.0f);
Map<TaskAttemptID, MapOutputFile> mapOutputFiles =
Collections.synchronizedMap(new HashMap<TaskAttemptID, MapOutputFile>());
List<RunnableWithThrowable> mapRunnables = getMapTaskRunnables(
taskSplitMetaInfos, jobId, mapOutputFiles);
//设置最终的map 和reduce个数
initCounters(mapRunnables.size(), numReduceTasks);
//创建map线程池
ExecutorService mapService = createMapExecutor();
//运行map task 任务
runTasks(mapRunnables, mapService, "map");
try {
if (numReduceTasks > 0) {
List<RunnableWithThrowable> reduceRunnables = getReduceTaskRunnables(
jobId, mapOutputFiles);
ExecutorService reduceService = createReduceExecutor();
runTasks(reduceRunnables, reduceService, "reduce");
}
} finally {
for (MapOutputFile output : mapOutputFiles.values()) {
output.removeAll();
}
}
// delete the temporary directory in output directory
outputCommitter.commitJob(jContext);
status.setCleanupProgress(1.0f);
if (killed) {
this.status.setRunState(JobStatus.KILLED);
} else {
this.status.setRunState(JobStatus.SUCCEEDED);
}
JobEndNotifier.localRunnerNotification(job, status);
} catch (Throwable t) {
try {
outputCommitter.abortJob(jContext,
org.apache.hadoop.mapreduce.JobStatus.State.FAILED);
} catch (IOException ioe) {
LOG.info("Error cleaning up job:" + id);
}
status.setCleanupProgress(1.0f);
if (killed) {
this.status.setRunState(JobStatus.KILLED);
} else {
this.status.setRunState(JobStatus.FAILED);
}
LOG.warn(id, t);
JobEndNotifier.localRunnerNotification(job, status);
} finally {
try {
fs.delete(systemJobFile.getParent(), true); // delete submit dir
localFs.delete(localJobFile, true); // delete local copy
// Cleanup distributed cache
localDistributedCacheManager.close();
} catch (IOException e) {
LOG.warn("Error cleaning up "+id+": "+e);
}
}
}
作业的提交运行都在这里啦,最后看一下 map是如何并行运行的
6.5标题createMapExecutor()
protected synchronized ExecutorService createMapExecutor() {
// Determine the size of the thread pool to use
int maxMapThreads = job.getInt(LOCAL_MAX_MAPS, 1);
if (maxMapThreads < 1) {
throw new IllegalArgumentException(
"Configured " + LOCAL_MAX_MAPS + " must be >= 1");
}
maxMapThreads = Math.min(maxMapThreads, this.numMapTasks);
maxMapThreads = Math.max(maxMapThreads, 1); // In case of no tasks.
LOG.debug("Starting mapper thread pool executor.");
LOG.debug("Max local threads: " + maxMapThreads);
LOG.debug("Map tasks to process: " + this.numMapTasks);
// Create a new executor service to drain the work queue.
ThreadFactory tf = new ThreadFactoryBuilder()
.setNameFormat("LocalJobRunner Map Task Executor #%d")
.build();
ExecutorService executor = HadoopExecutors.newFixedThreadPool(
maxMapThreads, tf);
return executor;
}
根据 LOCAL_MAX_MAPS =mapreduce.local.map.tasks.maximum 和 job中的map个数 来确定最后线程池的个数,maptask使用这个线程池运行
二.扩展local MR 并行运行map
由上可知,MR 在选择模式时,在local模式中,写死了map的个数,导致不能修改map个数了,所以我们在扩展一个接口,去掉该限制;这既没有对源码任何修改,添加自定义的类包即可解决。
1.如何定义接口
ClientProtocol是Protocol一定的接口,查看到源码中定义的实现类都在resources/META-INF/services定义了接口文件,所以我们也按照此方式扩展
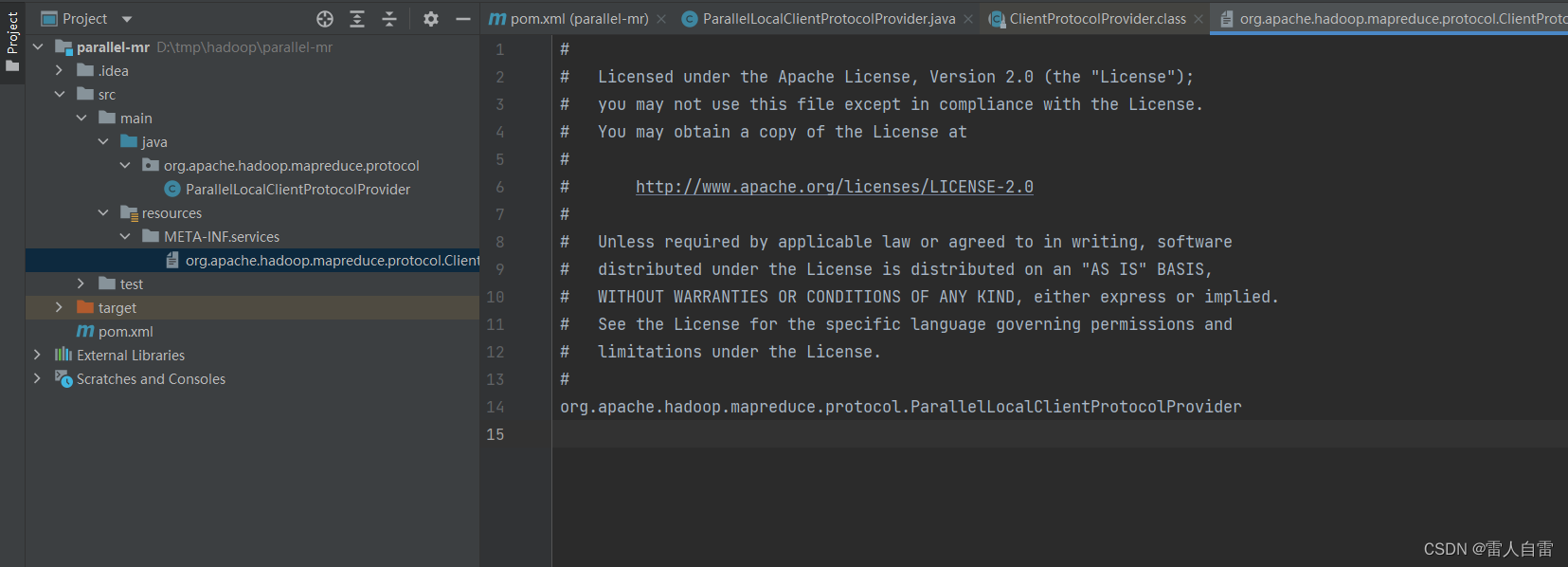
2.重新LocalClientProtocolProvider实现
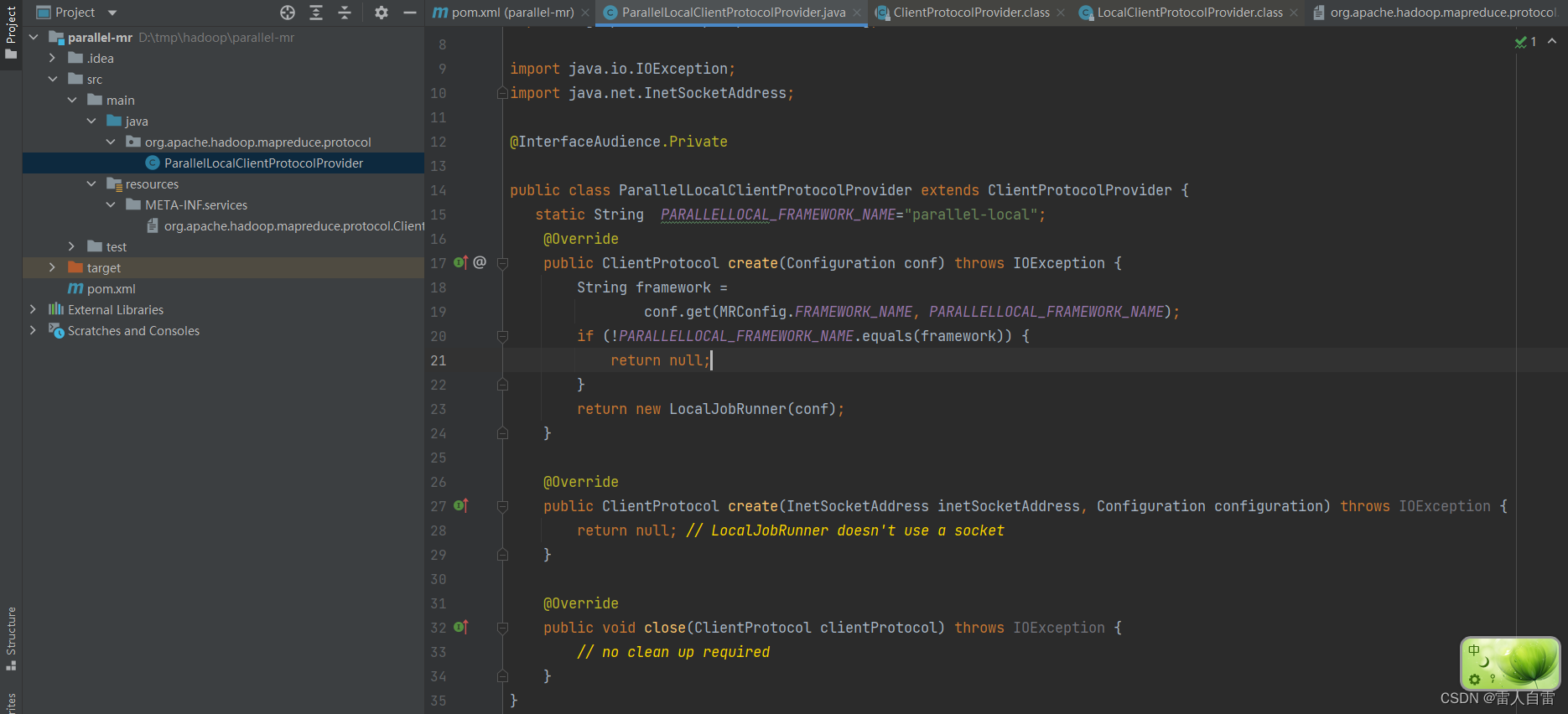
这里只是去掉了map的限制
3.安装部署
编译上述项目,将扩展的jar放在lib下,然后修改 mapred-site.xml中的mapreduce.framework.name=parallel-local 再次提交distcp命令即可















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









