






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
一、什么是数据库引擎?
数据库引擎是用于储存、处理和保护数据的核心服务。它可以控制访问权限并快速处理事务从,从而满足大多数的企业内需要处理大量数据的应用程序的要求
二、MySQL的引擎有哪些?
mysql常用的引擎有四种,分别是(1):MyISAM存储引擎、(2)InnoDB存储引擎、(3):MEMORY存储引擎、(4)MERGE存储引擎
其中
(1):MyISAM存储引擎:不支持事务、也不支持外键,优势是访问速度快,对事务完整性没有 要求或者以select,insert为主的应用基本上可以用这个引擎来创建表
支持3种不同的存储格式,分别是:静态表;动态表;压缩表
静态表:表中的字段都是非变长字段,这样每个记录都是固定长度的,优点存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多(因为存储时会按照列的宽度定义补足空格)ps:在取数据的时候,默认会把字段后面的空格去掉,如果不注意会把数据本身带的空格也会忽略。
动态表:记录不是固定长度的,这样存储的优点是占用的空间相对较少;缺点:频繁的更新、删除数据容易产生碎片,需要定期执行OPTIMIZE TABLE或者myisamchk-r命令来改善性能
压缩表:因为每个记录是被单独压缩的,所以只有非常小的访问开支
(2)InnoDB存储引擎*
该存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM引擎,写的处理效率会差一些,并且会占用更多的磁盘空间以保留数据和索引。
InnoDB存储引擎的特点:支持自动增长列,支持外键约束
(3):MEMORY存储引擎
Memory存储引擎使用存在于内存中的内容来创建表。每个memory表只实际对应一个磁盘文件,格式是.frm。memory类型的表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。
MEMORY存储引擎的表可以选择使用BTREE索引或者HASH索引,两种不同类型的索引有其不同的使用范围
hash索引的适用范围及缺陷
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
Hash索引缺点: 那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持;
1、只用于 = 或<=>操作符的等式比较。
2、优化器不能使用hash索引加速order by操作;
3、当~ mysql不能确定在两个值之间大约多少行。若将一个myisam表改为hash索引的memory表时,会影响一些查询的执行效率。
4、只能使用整个关键字搜索一行。
BTREE索引
适用于 >、<、>=、<=、between、!=或者<> ,或者 like ‘parent’(parent不以通配符开始)操作符。
(4)MERGE存储引擎
Merge存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,merge表本身并没有数据,对merge类型的表可以进行查询,更新,删除操作,这些操作实际上是对内部的MyISAM表进行的。
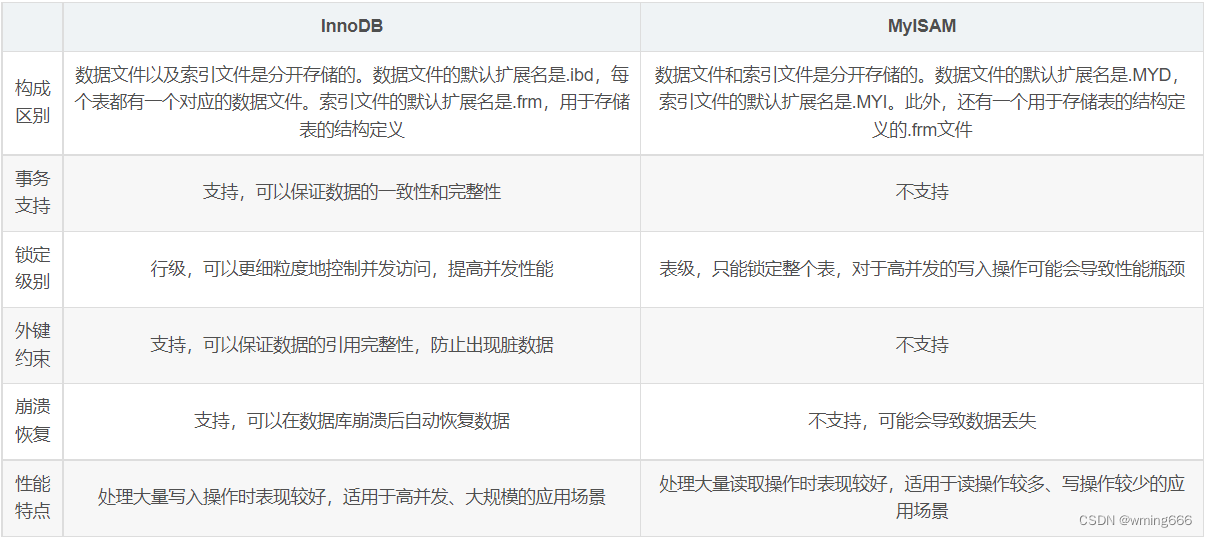
三、InnoDB和MyISAM的区别
四、创建对象的几种方式
| 方式 | 是否调用了构造函数 |
|---|---|
| 使用new关键字 | 是 |
| 使用Class类的newInstance方法 | 是 |
| 使用Constructor类的newInstance方法 | 是 |
| 使用clone方法 | 否 |
| 使用反序列化方法 | 否 |
1、使用new关键字
这是最简单的创建对象的方式,通过new可以调用任意的构造器
Student s = new Student();
2、使用Class类的newInstance方法(反射)
Employee emp2 = (Employee) Class.forName("org.programming.mitra.exercises.Employee").newInstance();
//或者
Employee emp2 = Employee.class.newInstance();
- 使用Constructor类的newInstance方法
和Class类的newInstance方法很像, java.lang.reflect.Constructor类里也有一个newInstance方法可以创建对象。我们可以通过这个newInstance方法调用有参数的和私有的构造函数。
Constructor<Employee> constructor = Employee.class.getConstructor();
Employee emp3 = constructor.newInstance();
- 使用clone方法
无论何时我们调用一个对象的clone方法,jvm就会创建一个新的对象,将前面对象的内容全部拷贝进去。用clone方法创建对象并不会调用任何构造函数。
要使用clone方法,我们需要先实现Cloneable接口并实现其定义的clone方法。
Employee emp4 = (Employee) emp3.clone();
- 使用反序列化
当我们序列化和反序列化一个对象,jvm会给我们创建一个单独的对象。在反序列化时,jvm创建对象并不会调用任何构造函数。
为了反序列化一个对象,我们需要让我们的类实现Serializable接口。
ObjectInputStream in = new ObjectInputStream(new FileInputStream("data.obj"));
Employee emp5 = (Employee) in.readObject();














 69
69











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









