







在真正了解一个机器学习算法的时候,发现有许多概念还是很模糊这里整理了最小二乘法(Least Square)、最大似然估计( Maximum Likelihood Estimation)和最大后验估计的关系。
一、最小二乘法
最小二乘法的本质就是找到一个估计值,使实际值与估计值的距离最小。而为了度量最小距离,只要使实际值与估计值之差的平方最小就好,下面就是最小二乘的表达式损失函数cost function,我们的目标就是求θ。

求解方法是通过梯度下降算法,通过训练数据不断迭代得到最终的值。
最小二乘的主要应用场景为回归分析,因为回归常用平方损失作为损失函数。
二、似然函数的引出
我们从概率的角度考虑一下最小二乘求解原理,假设目标变量y和输入x的关系如下:
其中ε为误差项,假设服从正态分布,均值为0,标准差为σ,可以写成
这里要注意θ不是变量,不在条件中用“;”隔开。通过给定的θ和X求解Y就是我们的正常的概率思想,但是如果我们把这个方程看成是关于θ的方程时,就变成了似然方程:
似然函数与上面的概率方程的最大区别在于,关注的不再是事件发生的概率,而是已知事件发生的情况下希望知道对应的参数应该是多少,这和求概率恰恰相反。上面的式子还可以写成:
最大化L(θ)就是最大似然估计,但一般都会最大化log likelihood:
这时可以发现,此时的最大化似然函数和最初的最小二乘损失函数本质上是一样的。但是要注意这两者只是恰好有着相同的表达结果,实际并没有本质的联系。因为当likelihood用的是Gaussian的时候,由于Gaussian kernel里有个类似于Euclidean distance的东西,一求log就变成square loss了,导致解和OLSE(就是ordinary的最小二乘)是一样的。而碰巧刚接触MLE的时候基本都是gaussian假设,这才导致很多人分不清楚(这句话套用知乎上的解释)。
三、似然函数的解析
参考wiki上的定义似然函数的结果等于已知参数时的结果的概率值(这里注意L不是一个条件概率,通常用;隔开)
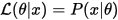
对于离散概率分布:
设X是参数为θ时服从离散概率分布p的随机变量,则:
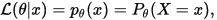
看成是θ的方程,称为似然函数。
对于连续概率分布则用密度函数衡量:
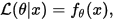
四、最大后验概率
这里就是引入了贝叶斯学派的理论了,关于贝叶斯学派和频率学派的区别参见知乎,我们就知道,贝叶斯学派主张一切都有一个先验概率。而且上面的似然函数推倒中频率学派把参数θ看作是固定而未知的常数,而样本是随机的,有关概率的运算都是针对样本X的分布。而贝叶斯学派把这个参数看作是随机变量,而样本X看作是固定的,重视的是参数θ的分布,通常是:通过参数的先验分布结合样本信息得到参数的后验分布。例子参见。















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









