










项目来源
最近,有个做管线检测的朋友在进行内业工作的时候,需要将原始检测报告里的表格信息转换到标准模版下(转换前后的表格样式不同,且只需要转换有用的信息,其中还包含了图片)。
转换前一个表格就是一个片区的检测内容,一段时间累积下来,要转换的表格少则几千,多则上万。之前他们内业就是,人工将需要的内容从原始报告中,复制到标准模版中,过程费时费力,一般都是一个小组进行十几天的内业工作才能完成。由此产生了这次项目需求,具体要求如下:
原始报告样式:
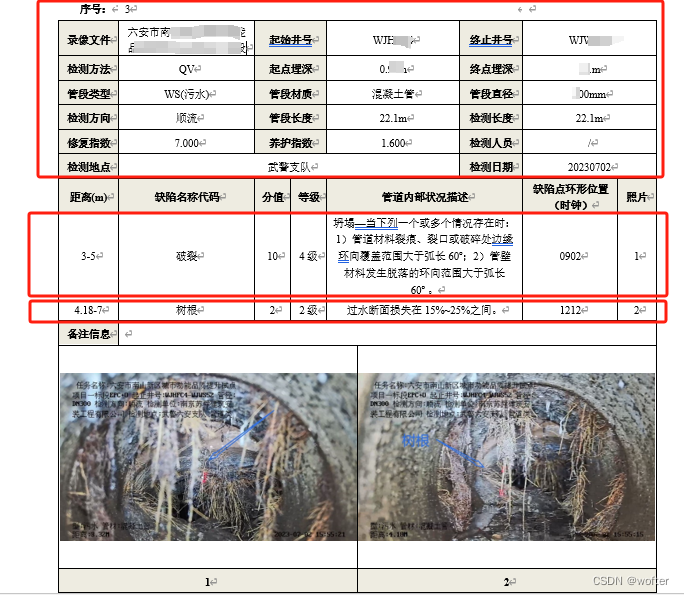
需要转换成的标准样式:

设计思路与核心代码
可以简单的理解就是把原始报告中需要的信息转换到标准模版中,并对应的插入图片。鉴于原始报告中单元格的排列横纵交叉,并且伴有不定个数的图片,所以可以对思路进行拆解
- 横向单元格标题与内容提取 ,对于横向单元格来说,可以看到奇数列为标题,偶数列为对应的内容,也由此容易想到可以用字典来存储数据;
data_dict = {} # 用于存储标题与值的字典
for row in table1.rows[start_index:end_index]:
cells = [cell.text.strip() for cell in row.cells]
for i in range(0, len(cells) - 1, 2): # 遍历奇数索引的标题
title = cells[i]
value = cells[i + 1] # 偶数索引的值
if title == value:
value = cells[i + 2]
# 将值添加到标题对应的列表中
data_dict.setdefault(title, value)
- 纵向单元格标题与内容提取 ,对于纵向来说,第九行为标题,接下来几行都是标题对应的值(几张图片就有几行值);
def extract_more_data(table2, start_number, end_number):
headers = [] # 存储表头
data = [] # 存储数据
for cell in table2.rows[7].cells:
headers.append(cell.text.strip())
for row in table2.rows[start_number:end_number]:
row_data = {}
for i, cell in enumerate(row.cells):
header = headers[i]
value = cell.text.strip()
# 如果值为空,则忽略此列
if value != "":
row_data[header] = value
else:
row_data[header] = "/"
# 只添加非空行数据
if len(row_data) > 0:
data.append(row_data)
return headers, data
- 图片提取 ,对于图片的转换也是模拟word文档中的复制粘贴功能。由于本项目涉及到的复制粘贴操作量较大,而且频繁打开word,容易引发读写错误,所以决定对图片采取缓存的形式;
def extract_images(document, output_folder):
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
image_count = 1
# 遍历文档中的所有内联形状并提取图片
for inline_shape in document.inline_shapes:
blip = inline_shape._inline.graphic.graphicData.pic.blipFill.blip
rel_id = blip.embed
pic_rel = document.part.related_parts[rel_id]
# 构造按顺序编号的图片文件名并保存
image_name = os.path.join(output_folder, f'image_{image_count}.png')
with open(image_name, 'wb') as f:
f.write(pic_rel.blob)
image_count += 1
return image_count
- 表格内容写入,为了将提取的文字内容插入到新的标准模版中,需要对原始报告的标题和标准模版的标题做个映射。然后通过键值对取值写入,例:
for g in range(len(sum_tables_data)):
con_dict = sum_tables_data[g]
# 管段编号
cell1 = table_after[g].cell(0, 1)
paragraph1 = cell1.paragraphs[0]
content1 = con_dict.get('起始井号') + "-" + con_dict.get('终止井号')
run1 = paragraph1.add_run(content1)
- 对应图片插入 ,根据缓存中的图片的文件名进行读取插入
def insert_image_into_cell(document, insert_path):
tables = document.tables
x = len(tables)
for i in range(len(tables)):
# 假设我们要在第row行第column列插入图片
target_cell = tables[i].cell(row, column)
# 图片路径
image_path = r'./picture/image_{}.png'.format(i + 1)
# 在指定单元格插入图片并设置水平居中
paragraph = target_cell.add_paragraph()
run = paragraph.add_run()
run.add_picture(image_path, width=Inches(2.9), height=Inches(2))
paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 保存文档
document.save(insert_path)
- 项目打包 ,开发完成后,将其打包成.exe可执行文件,方便执行任务
pyinstaller --onefile --icon=icon.ico main.py
#icon.ico为图标路径,可以作为软件的展现形式,main.py替换成你自己的主函数名称
效果展示
小编最后将项目打包成.exe文件,双击即可运行,对于参数进行了封装,自己填入需要处理的原始报告的文件绝对路径
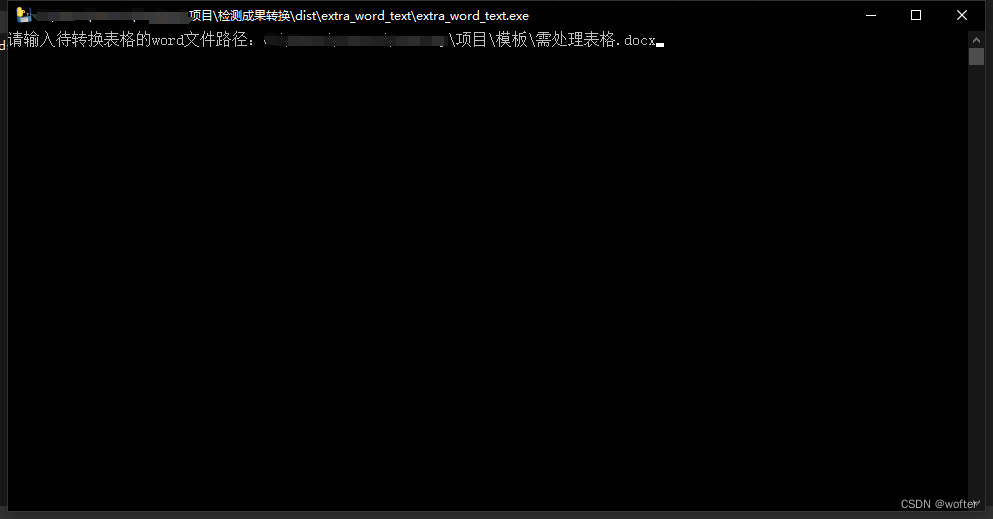
填入文件路径,直接回车便可执行,执行结束后窗口自动关闭
一点思考
小编在自己的程序中加入了任务耗时计算的代码,测试了98个原始报告表格,转换共耗时5秒,这样来说一万个表格大概需要十分钟的时间。当然代码还有可以优化的地方,达到耗时更短的效果,也可以自己做个GUI,更方便操作。
有任何疑问或者指教,欢迎评论或者私信交流。

















 6451
6451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









