







(1)线性回归于逻辑斯蒂回归联系与区别
线性回归:线性回归是根据样本X各个维度的Xi的线性叠加(线性叠加的权重系数wi就是模型的参数)来得到预测值的Y,然后最小化所有的样本预测值Y与真实值y‘的误差来求得模型参数。我们看到这里的模型的值Y是样本X各个维度的Xi的线性叠加,是线性的。
然后再来看看我们这里的logistic回归模型,模型公式是: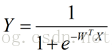
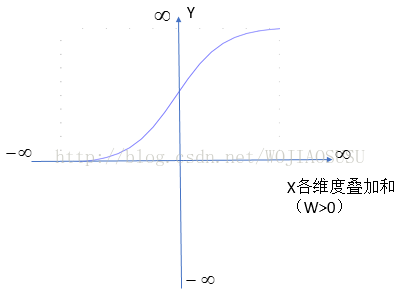
我们看到Y的值大小不是随X叠加和的大小线性的变化了,而是一种平滑的变化,这种变化在x的叠加和为0附近的时候变化的很快,而在很大很大或很小很小的时候,X叠加和再大或再小,Y值的变化几乎就已经很小了。当X各维度叠加和取无穷大的时候,Y趋近于1,当X各维度叠加和取无穷小的时候,Y趋近于0。
线性回归是一个回归问题,而逻辑斯蒂回归是一个分类问题。
(2)二项逻辑斯蒂回归
二项逻辑斯蒂回归模型:二项逻辑斯蒂回归模型是一种分类模型,由条件概率分布P(Y|X)表示。
逻辑斯蒂回归模型:二项逻辑斯蒂回归模型是如下的条件概率分布:
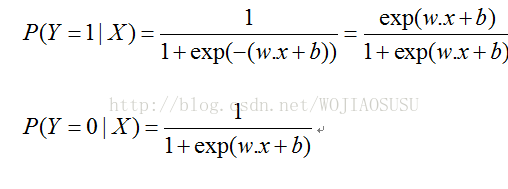
为了方便,架构权值向量w与输入向量加以扩充,即
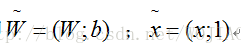
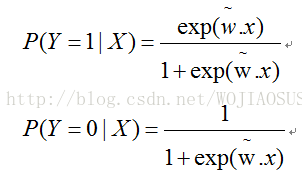
一个事件的几率是该事件发生的概率与该事件不发生的概率的比值。例如一个事件发生的概率是P,那么不发生的概率是(1-P),那么该事件的几率是p/(1-p)。该事件的对数几率是
Logit(p)=log(p/(1-p)
对逻辑斯蒂回归而言,就是
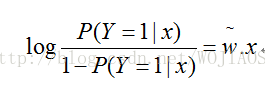
输出Y=1的对数几率是输入x的线性函数,或者说,输出Y=1的对数几率是由输入x的线性函数表示的模型。
模型的参数估计如图所示:样本服从伯努利分布,求得似然函数,取对数即可。

逻辑斯蒂回归损失函数:对数损失。

总结:与线性回归模型不同而是,样本X的各维线性叠加和与样本标签y不在是线性关系。而是呈现出一种逻辑斯蒂分布的关系(这句话可能有点欠妥)。假设样本服从伯努利分布(0-1)分布,然后求得满足该分布的似然函数,最终求得似然函数的最大值。整体思想就是极大似然函数,而取对数只是方便求解的一种数学手段而已。
回归问题的基本步骤:
(1) 寻找h函数。即模型函数。
(2) 构造损失函数
(3) 求解使得损失函数最小的参数。各种优化算法。
在进行数据拟合时,还可以根据需要选择是否增加L1或者L2惩罚项。
如果选择L1范数,Logistic回归会得到系数模型,因此可以用来进行特征选择。
简单的利用sklearn来泡一个例子。
# -*- coding: utf-8 -*-
from __future__ import division
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from sklearn.metrics import precision_recall_curve, roc_curve, auc
from sklearn.cross_validation import StratifiedKFold
data = pd.read_csv('C:\\Users\scl\\Desktop\\machine\machinelearninginaction\\Ch05\\testSet.txt', sep=' ', \
skiprows=0, names=['score1','score2','result']) #利用pandas里面的函数读取训练集,前两行不读入
score_data = data.loc[:,['score1','score2']]#获取分数
result_data = data.result#获取结果
clf = LogisticRegression(penalty='l1',dual=False,tol=0.000001,C=2.0,class_weight='balanced',
random_state=1024,solver='liblinear',max_iter=10000, verbose=0,n_jobs=-1)
p = 0
for i in xrange(10):
x_train, x_test, y_train, y_test = \
train_test_split(score_data, result_data, test_size = 0.2)#进行交叉验证
model = clf
model.fit(x_train, y_train)
predict_y = model.predict(x_test)
p += np.mean(predict_y == y_test)
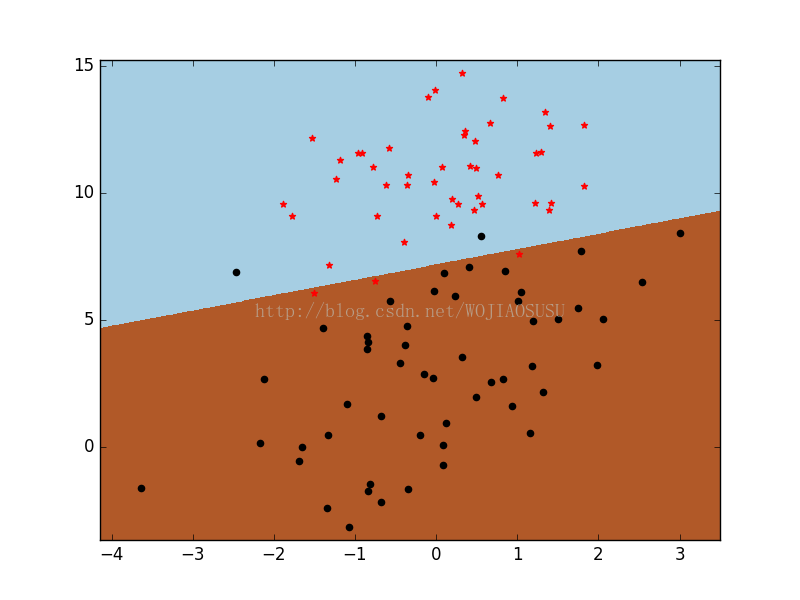
# 绘制图像
pos_data = data[data.result == 1].loc[:,['score1','score2']]
neg_data = data[data.result == 0].loc[:,['score1','score2']]
h = 0.02
x_min, x_max = score_data.loc[:, ['score1']].min() - .5, score_data.loc[:, ['score1']].max() + .5
y_min, y_max = score_data.loc[:, ['score2']].min() - .5, score_data.loc[:, ['score2']].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
# 绘制边界和散点
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
plt.scatter(x=pos_data.score1, y=pos_data.score2, color='black', marker='o')
plt.scatter(x=neg_data.score1, y=neg_data.score2, color='red', marker='*')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()
# 模型表现
answer = model.predict_proba(x_test)[:,1]
precision, recall, thresholds = precision_recall_curve(y_test, answer)
report = answer > 0.5
print(classification_report(y_test, report, target_names = ['neg', 'pos']))
print("average precision:", p/100)














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









