







一、DOM解析:
一)XML格式:
1.第一行:<?xml version="1.0" encoding = "UTF-8"?>
2.注释:<!-- -->
二)解析的技术
包括DOM解析xml和SAX解析xml.
三)DOM解析(Document Object Model的缩写):
1.特点:
全部读到内存,当容量>10M时,就不能解析了。
把XML映射成一个倒挂的树。
2.步骤:
1)创建解析器工厂对象
2)由解析器工厂对象创建解析器对象。
2)由解析器对象对指定XML文件进行解析,构建相应的DOM树,创建Document对象。
3)以Document对象为起点对DOM树的节点进行增删改查操作。
范例:
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DOMTest {
public static void main(String[] args) {
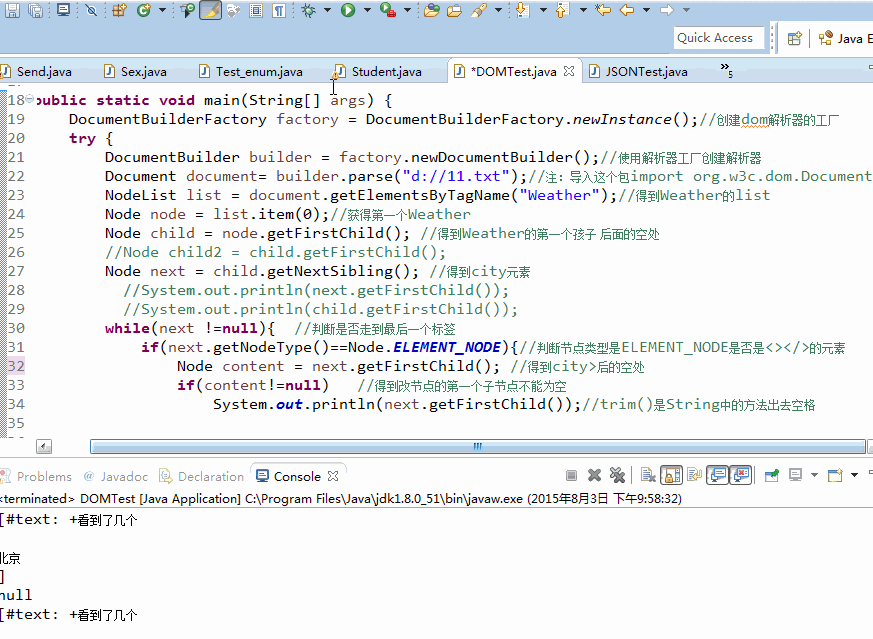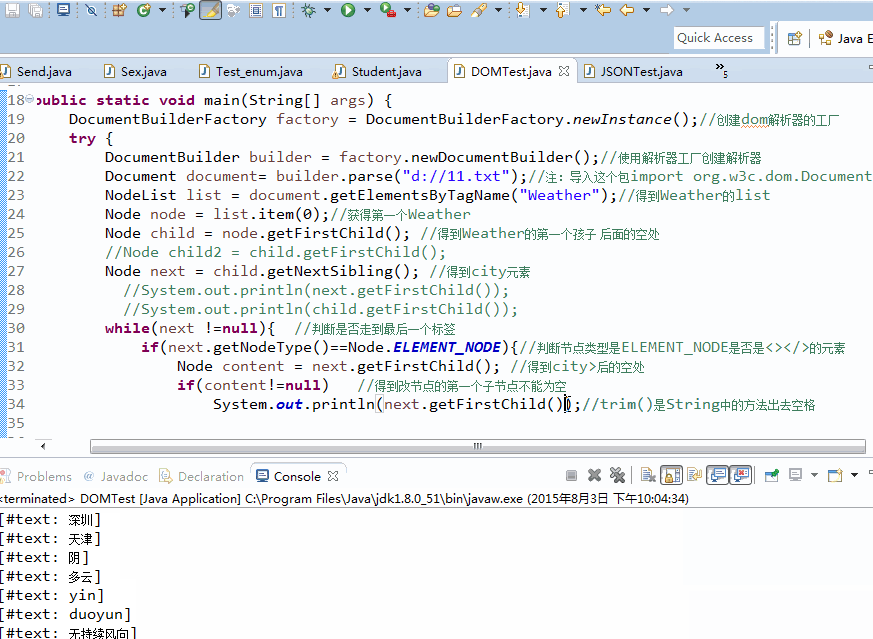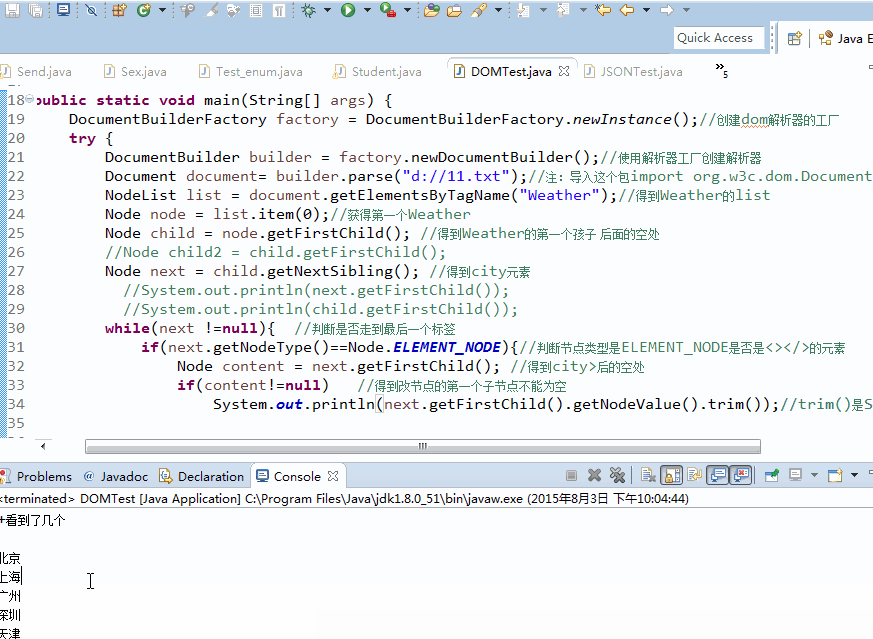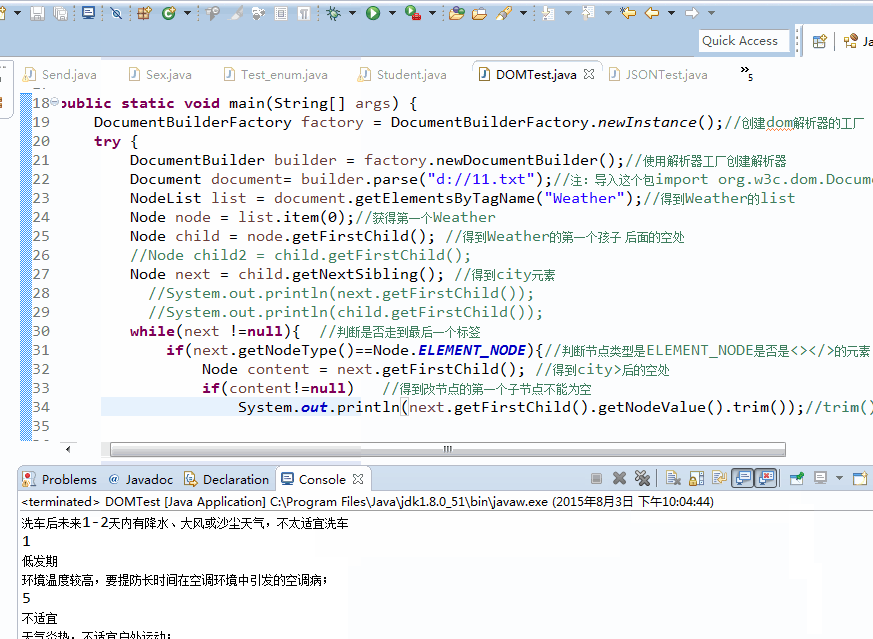
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();//创建dom解析器的工厂
try {
DocumentBuilder builder = factory.newDocumentBuilder();//使用解析器工厂创建解析器
Document document= builder.parse("d://11.txt");//注:导入这个包import org.w3c.dom.Document;
NodeList list = document.getElementsByTagName("Weather");//得到Weather的list
Node node = list.item(0);//获得第一个Weather
Node child = node.getFirstChild(); //得到Weather的第一个孩子 后面的空处
//Node child2 = child.getFirstChild();
Node next = child.getNextSibling(); //得到city元素
//System.out.println(next.getFirstChild());
//System.out.println(child.getFirstChild());
while(next !=null){ //判断是否走到最后一个标签
if(next.getNodeType()==Node.ELEMENT_NODE){//判断节点类型是ELEMENT_NODE是否是<></>的元素
Node content = next.getFirstChild(); //得到city>后的空处
if(content!=null) //得到改节点的第一个子节点不能为空
System.out.println(next.getFirstChild().getNodeValue().trim());//trim()是String中的方法出去空格
}
next = next.getNextSibling(); //继续得到下一个标签
}
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}演示:
解释: node :是第一个Weather child 是node的第一个孩子:wearher后面的空处,到下个<之前的位置。
next是空处的下一个节点即– content 是next的孩子,即中间的一块。 方法: 嵌套式:
先找到,得到第一个孩子(后面的空),得到孩子的下一个(即嵌套的<>元素,) 不嵌套:
获得此元素后,得到其第一个孩子(后面的空),判断不为空后,得到其值getNodeValue()
二、SAX解析:
一)SAXParserHandler类:
1.重写方法:
startDocument() 和 endDocument()是事件在文档起始处和结束处被激发。
startElement()和endElement()事件是在遇到起始标记时被激发的。
characters()事件是在遇到字符数据时被激发的。
2.步骤:
1)创建SAXParserFactory的实例
2)创建SAXParser的实例
3)创建SAXParserHandler类
4)使用parse()方法解析XML文档
//先定义一个类继承DefaultHandler
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAXHander extends DefaultHandler{ //注:导入的是import org.xml.sax.helpers.DefaultHandler;
@Override
public void startDocument() throws SAXException {
// TODO Auto-generated method stub
super.startDocument();
}
@Override
public void endDocument() throws SAXException {
// TODO Auto-generated method stub
super.endDocument();
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
// TODO Auto-generated method stub
super.startElement(uri, localName, qName, attributes);
System.out.println("标签开始!"); //开始标签出现被激发
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
// TODO Auto-generated method stub
super.endElement(uri, localName, qName);
System.out.println("标签结束!"); //结束标签出现时被激发
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
// TODO Auto-generated method stub
super.characters(ch, start, length);
System.out.println(new String(ch,start,length));//出现文档正文被激发此方法,在此方法中输出文档操作
} //继承DefaultHandler
}
public class TestSAX {
public static void main(String[] args) {
SAXParserFactory factory = SAXParserFactory.newInstance(); //建工厂对象
try {
SAXParser parser = factory.newSAXParser(); //建立SAX解析对象
SAXHander hander = new SAXHander(); //建hander解析对象
**parser.parse(new File("d:\\11.txt"),hander);**//进行解析
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch(IOException e){
e.printStackTrace();
}
}
}结果: 标签开始!
标签开始!
- #text标签开始!
+看到了几个北京
标签结束!
标签开始! 上海 标签结束! 老师讲解的延伸例子:

三、JSON解析:
注:使用前加jar包,右键—>在BuildPath–>Add External –
一)JSON格式:
- {}表示JSONObject : 放元素用put方法
- []表示JSONArray 数组:放元素用add方法
- 其中的格式是 key:value
- 获取用getJSON—方法
范例:
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
public class JSONTest {
public static void main(String[] args) {
String json = creatJSON();//调用建立JSON的方法
JSONObject obj = JSONObject.fromObject(json); //显示json时,建立对象用fromObject方法
System.out.println(obj.getString("city")); //获得标签名为city的值
JSONObject today = obj.getJSONObject("today");
JSONArray array = today.getJSONArray("index");//由于数组index是在object “today”中,所以先得到today
for(int i =0;i<array.size();i++){
JSONObject obj1 = array.getJSONObject(i);
System.out.println(obj1.getString("name"));
}
}
private static String creatJSON(){
JSONObject obj = new JSONObject(); //JSONobject类创建时用new方法
obj.put("city", "北京");
obj.put("cityid", "123");
JSONObject today = new JSONObject();
today.put("date", "2015-08-03");
today.put("week", "星期一");
JSONObject index1 = new JSONObject();
index1.put("name", "感冒");
JSONObject index2 = new JSONObject(); //object用put方法
index2.put("name", "防晒");
JSONObject index3 = new JSONObject();
index3.put("name", "炎热");
JSONArray arr = new JSONArray(); //先定义好内部,外部包装
arr.add(index1); //数组用add方法
arr.add(index2);
arr.add(index3);
today.put("index", arr);
obj.put("today", today);
System.out.println(obj.toString());
return obj.toString();
}
}
结果:
{“city”:”北京”,”cityid”:”123”,”today”:{“date”:”2015-08-03”,”week”:”星期一”,”index”:[{“name”:”感冒”},{“name”:”防晒”},{“name”:”炎热”}]}}
北京
感冒
防晒
炎热














 57
57











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









