







- 寻宝须知
A. 大数据背景
不夸张的说,这是一个数据泛滥的年代,特别是物联网的兴起、移动计算技术的发展、各类传感器等嵌入系统的广泛应用都使得人类取得的数据量在短时间内激增。这样就积累了大量的历史数据,有的甚至已沉睡多年,他们还有价值吗,是不是应该像清空垃圾那样删掉它们?
我们知道“以史为鉴”,历史是一面镜子对人类发展起到辅助和推动作用。个人觉得不同时期的数据也是一面镜子,虽然不能像历史事件那样直观反映出某种规律,但如果我们稍加分析就会发现,数据中隐含了一些规律或者规则,这对我们来说可能相当有价值。
比如:大家耳熟能详的例子就是沃尔玛超市从顾客的历史购物单数据中发现了在美国超市购买尿布的年轻的父亲同时可能购买啤酒的概率为40%左右,超市摆放商品时候就可以考虑将二者摆放同一个货架上,引导消费者购物从而提高了销量。国内电商淘宝根据数据分析用户的购买趋向,百度利用大数据分析用户的搜索趋向等等。
能做到这个从数据中寻找到有价值规则的工具就是今天给大家聊的经典数据挖掘算法之关联规则挖掘算法。
B. 什么是规则
其实我们“寻宝”就是找寻规则,我们理解的规则就如:“如果… 那么…(If…Then…)”,前者为条件,后者为结果。
假设在一个有4000个顾客的购物单数据中,统计有723人同时购买了冷冻食品和面包,有788人只购买了冷冻食品,那么产生的规则就是: frozen foods=t 788 ==> bread and cake=t 723 conf:(0.92),表示如果购买冷冻食品的人中,有92%的人会同时购买面包。
C. 什么规则我们会感兴趣?
按照我们的兴趣度从高到低,分为以下四种情况:
A经常发生,发生的时候B伴随发生的概率很高。
A很少出现,但是一旦出现B出现的概率很高。
A经常发生,发生的时候B伴随发生的概率一般。
A很少出现,出现之后B出现的概率一般。
D. 规则对数据要求
要想得到有价值的规则,有个重要前提就是数据必须是真实的数据,没有污染的。一般情况下会针对各个数据库中的数据进行数据抽取,去掉干扰数据(数据表中为null的或者用户随意填写的或者不合法的值等等),为挖掘规则算法提供基本保障。
2. 寻宝工具之关联规则挖掘
A. 与算法几个相关的概念
定义1: 支持度(support)
支持度s是事务数据库D中包含A U B的事务百分比,通俗说就是A和B同时出现的概率。
定义2: 置信度(confidence)
可信度为事务数据库D中包含A的事务中同时也包含B的百分比,它是概率P(B|A),即confidence(A B)=P(B|A),通俗说就是A,B同时出现的数目除以A出现的数目。
定义3: 频繁项集
支持度大于等于用户给定的最小支持度阈值(minsup)的项集称为频繁项目集(简称频集),或者大项目集。所有的频繁K-项集记为LK。这里的K是从1到n的。n的取值与数据库表中列的数目有关,需要分析的属性越多,这个值可能就越大。
B. Apriori算法的执行流程
最著名的关联规则挖掘算法就是Apriori算法了,它本身就是一个不断迭代的找寻频繁项集的过程,如下步骤:
1. 首先我们需要设定一个最小支持度Minimum support值和最小置信度Minimum confidence值(这两个值需要根据不同数据情况由行业专家给定参考值)。
2. 经过算法的第一次迭代,对事务数据库进行一次扫描,计算出D中所包含的每个项目出现的次数,生成候选1-项集的集合C1。
3. 根据设定的最小支持度,从C1中确定频繁1-项集L1。
4. 由L1产生候选2-项集C2,然后扫描事务数据库对C2中的项集进行计数。
5. 根据最小支持度,从候选集C2中确定频繁集L2。
6. 逐步根据频繁K(K=2,3…n)项集产生候选K+1项集,继续扫描数据库,寻找频繁K+1项集,直到找不到频繁项集为止。
注意,因为每一次根据候选项集寻找频繁项集时,都要扫描数据库,为了提高效率,可以在扫描之前根据某些定理(即频繁集的子集也一定是频繁集)去掉一些明显不符合条件的候选项集。
C. 基于Java的开源挖掘工具Weka
1.首先安装weka,之后打开分析软件
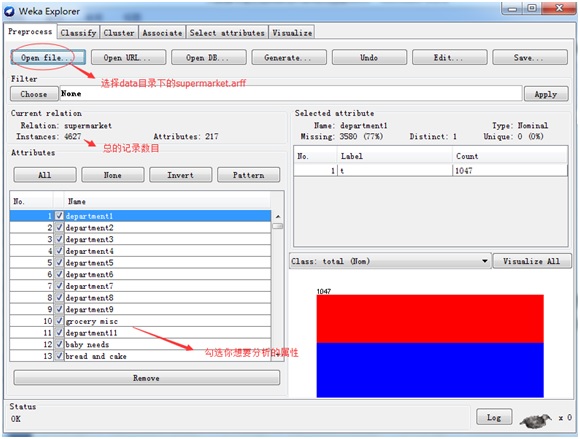
2.选择Explorer选项,并准备数据,weka本身自带了一些数据样本,WEKA存储数据的格式是ARFF(Attribute-Relation File Format)文件,这是一种ASCII文本文件。在它安装目录下的data 中。比如我们选择Supermarket.arff数据样本:
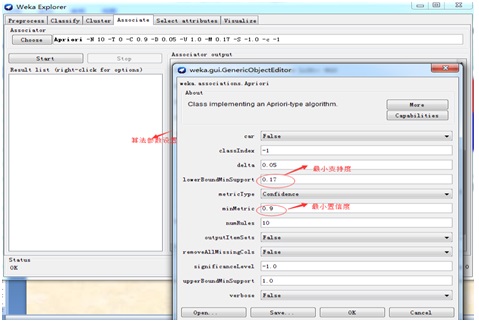
3.选择Associate选项进行Apriori算法的支持度和置信度等参数设置
4.点击start按钮,开始挖掘关联规则,结果在右边显示。
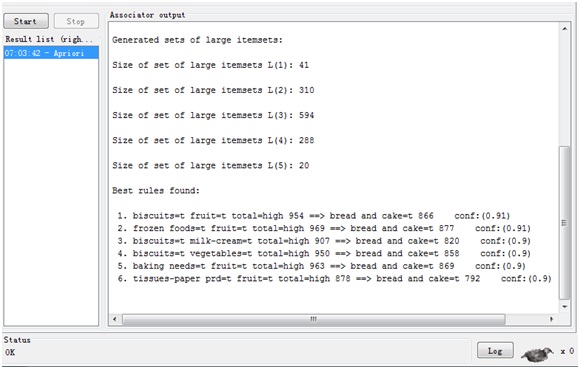
结果中我们看到每一条都是最终产生的规则,比如第一条:biscuits=t fruit=t total=high 954 ==> bread and cake=t 866 conf:(0.91),表示有954人购买了饼干和水果,有866人同时购买了饼干,水果和面包,也就是在购买饼干和水果的人当中,又购买面包的概率是91%,即为最后的置信度,也符合我们开始设置的0.9。
特别注意:这里的支持度和置信度的设置不是随意设置的,也不是说支持度和置信度设置的越高就越好,需要根据不同的行业专家的经验来进行设定才能得到有价值的规则。比如要分析癌症发病和地域,生活习惯,性别等等的关系,我们支持度就应该设置的很低,因为病人当中癌症发病率很低,我们关心的是置信度,来判断与那个因素关联密切,这当中的价值无须赘述。
D. Java开发环境中使用Weka
因为本身weka就是java开源项目,我们只需在项目中导入weka.jar,然后调用后者的API即可。
上面的分析实例用Java实现代码如下:
public class WekaDemo {
public static void main(String[] args) throws Exception {
// load data
File inputFile = new File("C:\\Program Files\\Weka-3-6\\data\\supermarket.arff");//数据样本文件
ArffLoader atf = new ArffLoader();
atf.setFile(inputFile);
Instances data = atf.getDataSet(); // 读入数据文件
data.setClassIndex(-1);//设置分类属性,由于这并非分类算法可以设置为-1
// build associator
Apriori apriori = new Apriori();
apriori.setClassIndex(data.classIndex());
apriori.setLowerBoundMinSupport(0.17);//设置最小支持度
apriori.setMinMetric(0.9);//设置最小置信度
apriori.buildAssociations(data);//开始根据设置参数进行挖掘
// output associator
System.out.println(apriori);//打印关联规则
}
}
运行结果和上面挖掘工具得到的一致。

深入学习挖掘算法参照论文:http://www.cqvip.com/read/read.aspx?id=30112881
数据挖掘决策支持系统项目原文:
http://wenku.baidu.com/link?url=rOCH52rOT1bUFBYlzFdVT8y_6uXKP9IPqGdPszpxfDWwmHT3sAmrmz41RX__DGbgetYM-EG0AfWDVluELG56N0wgAJrYRmane-xrsSGGm-e

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









