







文章目录
- 16.Pandas的分层索引MultiIndex
- 17.Pandas的数据转换函数map&apply&applymap
- 18.Pandas怎样对每个分组应用apply函数
- 19.Pandas的stack和pivot实现数据透视
- 20.Pandas怎样快捷方便的处理日期数据
- 21.Pandas怎么处理日期索引的缺失
- 22.Pandas怎样实现Excel的vlookup并且在指定列后面输出?
- 23.Pandas怎样结合Pyecharts绘制折线图
- 24.Pandas结合Sklearn实现泰坦尼克存活率预测
- 25.Pandas处理分析网站原始访问日志
- 26.Pandas怎样找出最影响结果的那些特征?
- 27.Pandas的Categorical类型
- 28.Pandas的get_dummies用于机器学习的特征处理
- 29.Pandas使用explode实现一行变多行统计
- 30.Pandas计算同比环比指标的3种方法
16.Pandas的分层索引MultiIndex

import pandas as pd
%matplotlib inline
stocks = pd.read_excel('./datas/stocks/互联网公司股票.xlsx')
stocks.head(3)

stocks["公司"].unique()

stocks.index
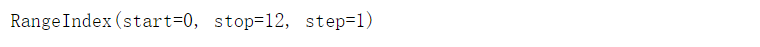
stocks.groupby('公司')["收盘"].mean()

16.1 Series的分层索引MultiIndex
ser = stocks.groupby(['公司', '日期'])['收盘'].mean()
空白代表使用上面的值

ser.index

unstack把二级索引变成列
ser.unstack()

ser.reset_index()

16.2 Series有多层索引MultiIndex怎样筛选数据
ser.loc['BIDU']

多层索引,可以用元组的形式筛选
ser.loc[('BIDU', '2019-10-02')]

ser.loc[:, '2019-10-02']

16.3 DataFrame的多层索引MultiIndex
stocks.head()

stocks.set_index(['公司', '日期'], inplace=True)

stocks.sort_index(inplace=True)

16.4 DataFrame有多层索引MultiIndex怎样筛选数据

stocks.loc['BIDU']

stocks.loc[('BIDU', '2019-10-02'), :]

stocks.loc[('BIDU', '2019-10-02'), '开盘']

stocks.loc[['BIDU', 'JD'], :]

stocks.loc[(['BIDU', 'JD'], '2019-10-03'), :]

stocks.loc[(['BIDU', 'JD'], '2019-10-03'), '收盘']

stocks.loc[('BIDU', ['2019-10-02', '2019-10-03']), '收盘']

slice(None)代表筛选这一索引的所有内容
stocks.loc[(slice(None), ['2019-10-02', '2019-10-03']), :]

stocks.reset_index()

17.Pandas的数据转换函数map&apply&applymap

17.1 map用于Series值的转换
实例:将股票代码英文转换成中文名字
Series.map(dict) or Series.map(function)均可

stocks["公司"].unique()
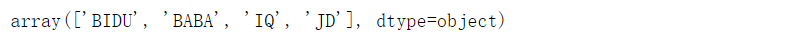
公司股票代码到中文的映射,注意这里是小写
dict_company_names = {
"bidu": "百度",
"baba": "阿里巴巴",
"iq": "爱奇艺",
"jd": "京东"
}
方法1:Series.map(dict)
stocks["公司中文1"] = stocks["公司"].str.lower().map(dict_company_names)

方法2:Series.map(function)
function的参数是Series的每个元素的值
stocks["公司中文2"] = stocks["公司"].map(lambda x : dict_company_names[x.lower()])

17.2 apply用于Series和DataFrame的转换
- Series.apply(function), 函数的参数是每个值
- DataFrame.apply(function), 函数的参数是Series
Series.apply(function)
function的参数是Series的每个值
stocks["公司中文3"] = stocks["公司"].apply(
lambda x : dict_company_names[x.lower()])

DataFrame.apply(function)
function的参数是对应轴的Series
注意这个代码:
1、apply是在stocks这个DataFrame上调用;
2、lambda x的x是一个Series,因为指定了axis=1所以Seires的key是列名,可以用x['公司']获取
stocks["公司中文4"] = stocks.apply(
lambda x : dict_company_names[x["公司"].lower()],
axis=1)

17.3 applymap用于DataFrame所有值的转换
sub_df = stocks[['收盘', '开盘', '高', '低', '交易量']]

将这些数字取整数,应用于所有元素
sub_df.applymap(lambda x : int(x))

直接修改原df的这几列
stocks.loc[:, ['收盘', '开盘', '高', '低', '交易量']] = sub_df.applymap(lambda x : int(x))

18.Pandas怎样对每个分组应用apply函数


演示:用户对电影评分的归一化
每个用户的评分不同,有的乐观派评分高,有的悲观派评分低,按用户做归一化
ratings = pd.read_csv(
"./datas/movielens-1m/ratings.dat",
sep="::",
engine='python',
names="UserID::MovieID::Rating::Timestamp".split("::")
)

实现按照用户ID分组,然后对其中一列归一化
def ratings_norm(df):
"""
@param df:每个用户分组的dataframe
"""
min_value = df["Rating"].min()
max_value = df["Rating"].max()
df["Rating_norm"] = df["Rating"].apply(
lambda x: (x-min_value)/(max_value-min_value))
return df
ratings = ratings.groupby("UserID").apply(ratings_norm)
ratings[ratings["UserID"]==1].head()

可以看到UserID1这个用户,Rating3是他的最低分,是个乐观派,我们归一化到0分;
fpath = "./datas/beijing_tianqi/beijing_tianqi_2018.csv"
df = pd.read_csv(fpath)
# 替换掉温度的后缀℃
df.loc[:, "bWendu"] = df["bWendu"].str.replace("℃", "").astype('int32')
df.loc[:, "yWendu"] = df["yWendu"].str.replace("℃", "").astype('int32')
# 新增一列为月份
df['month'] = df['ymd'].str[:7]
df.head()

def getWenduTopN(df, topn):
"""
这里的df,是每个月份分组group的df
"""
return df.sort_values(by="bWendu")[["ymd", "bWendu"]][-topn:]
df.groupby("month").apply(getWenduTopN, topn=1).head()

我们看到,grouby的apply函数返回的dataframe,其实和原来的dataframe其实可以完全不一样
19.Pandas的stack和pivot实现数据透视

19.1 经过统计得到多维度指标数据
非常常见的统计场景,指定多个维度,计算聚合后的指标
实例:统计得到“电影评分数据集”,每个月份的每个分数被评分多少次:(月份、分数1~5、次数)
df = pd.read_csv(
"./datas/movielens-1m/ratings.dat",
header=None,
names="UserID::MovieID::Rating::Timestamp".split("::"),
sep="::",
engine="python"
)

df["pdate"] = pd.to_datetime(df["Timestamp"], unit='s')

实现数据统计
df_group = df.groupby([df["pdate"].dt.month, "Rating"])["UserID"].agg(pv=np.size)

对这样格式的数据,我想查看按月份,不同评分的次数趋势,是没法实现的
需要将数据变换成每个评分是一列才可以实现
19.2使用unstack实现数据二维透视
目的:想要画图对比按照月份的不同评分的数量趋势
df_stack = df_group.unstack()

df_stack.plot()

unstack和stack是互逆操作
df_stack.stack().head(20)

19.3 使用pivot简化透视
df_reset = df_group.reset_index()

df_pivot = df_reset.pivot("pdate", "Rating", "pv")

df_pivot.plot()

pivot方法相当于对df使用set_index创建分层索引,然后调用unstack
19.4 stack、unstack、pivot的语法



20.Pandas怎样快捷方便的处理日期数据


问题:怎样统计每周、每月、每季度的最高温度?
(1)读取天气到DataFrame

(2)将日期列转换成pandas日期
df.set_index(pd.to_datetime(df["ymd"]), inplace=True)

df.index

DatetimeIndex是Timestamp的列表形式
df.index[0]
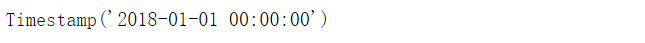
(3)方便的对DatatimeIndex进行查询
筛选固定的某一天
df.loc['2018-01-05']

日期区间
df.loc['2018-01-05':'2018-01-10']

按月份前缀筛选
df.loc['2018-03']

按年份前缀筛选
df.loc["2018"].head()

(4)方便的获取周、月、季度
Timestamp、DatetimeIndex支持大量的属性可以获取日期分量:
https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#time-date-components
周数字列表
df.index.week

月数字列表
df.index.month

季度数字列表
df.index.quarter
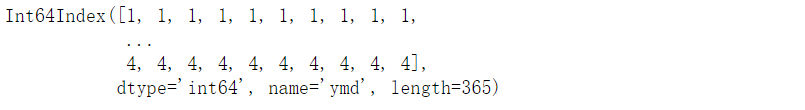
(5)统计每周、每月、每个季度的最高温度
每周
df.groupby(df.index.week)["bWendu"].max().head()

df.groupby(df.index.week)["bWendu"].max().plot()

每月
df.groupby(df.index.month)["bWendu"].max()

df.groupby(df.index.month)["bWendu"].max().plot()

每个季度
df.groupby(df.index.quarter)["bWendu"].max()

df.groupby(df.index.quarter)["bWendu"].max().plot()

21.Pandas怎么处理日期索引的缺失
可以用两种方法实现:
- DataFrame.reindex,调整dataframe的索引以适应新的索引
- DataFrame.resample,可以对时间序列重采样,支持补充缺失值
import pandas as pd
%matplotlib inline
df = pd.DataFrame({
"pdate": ["2019-12-01", "2019-12-02", "2019-12-04", "2019-12-05"],
"pv": [100, 200, 400, 500],
"uv": [10, 20, 40, 50],
})
df

df.set_index("pdate").plot()

21.1 使用pandas.reindex方法
(1)将df的索引变成日期索引
df_date = df.set_index("pdate")
df_date

df_date.index
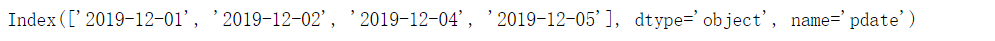
将df的索引设置为日期索引
df_date = df_date.set_index(pd.to_datetime(df_date.index))
df_date

df_date.index
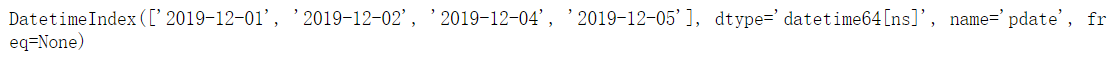
(2)使用pandas.reindex填充缺失的索引
生成完整的日期序列
pdates = pd.date_range(start="2019-12-01", end="2019-12-05")
pdates
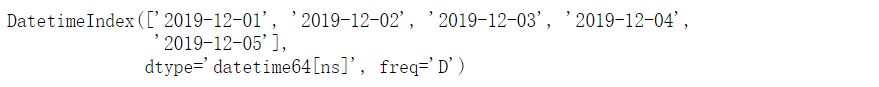
df_date_new = df_date.reindex(pdates, fill_value=0)
df_date_new

df_date_new.plot()

21.2 使用pandas.resample方法
(1)先将索引变成日期索引
df_new2 = df.set_index(pd.to_datetime(df["pdate"])).drop("pdate", axis=1)
df_new2

(2)使用DataFrame的resample的方法按照天重采样

由于采样会让区间变成一个值,所以需要指定mean等采样值的设定方法
df_new2 = df_new2.resample("D").mean().fillna(0)

resample的使用方式
df_new2.resample("2D").mean()

22.Pandas怎样实现Excel的vlookup并且在指定列后面输出?

(1)读取两个数据表
学生成绩表
df_grade = pd.read_excel("./course_datas/c23_excel_vlookup/学生成绩表.xlsx")
df_grade.head()

学生信息表
df_sinfo = pd.read_excel("./course_datas/c23_excel_vlookup/学生信息表.xlsx")
df_sinfo.head()

目标:怎样将第二个“学生信息表”的姓名、性别两列,添加到第一个表“学生成绩表”,并且放在第一个表的“学号”列后面?
(2)实现两个表的关联
只筛选第二个表的少量的列
df_sinfo = df_sinfo[["学号", "姓名", "性别"]]
df_sinfo.head()

df_merge = pd.merge(left=df_grade, right=df_sinfo, left_on="学号", right_on="学号")
df_merge.head()

(3)调整列的顺序
df_merge.columns
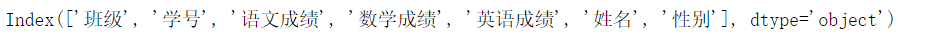
问题:怎样将’姓名’, '性别’两列,放到’学号’的后面?
将columns变成python的列表形式
new_columns = df_merge.columns.to_list()
new_columns
按逆序insert,会将"姓名","性别"放到"学号"的后面
for name in ["姓名", "性别"][::-1]:
new_columns.remove(name)
new_columns.insert(new_columns.index("学号")+1, name)

df_merge = df_merge.reindex(columns=new_columns)
df_merge.head()

(4)输出
df_merge.to_excel("./course_datas/c23_excel_vlookup/合并后的数据表.xlsx", index=False)
23.Pandas怎样结合Pyecharts绘制折线图
(1)读取数据
xlsx_path = "./datas/stocks/baidu_stocks.xlsx"
df = pd.read_excel(xlsx_path, index_col="datetime", parse_dates=True)
df.head()

df.index
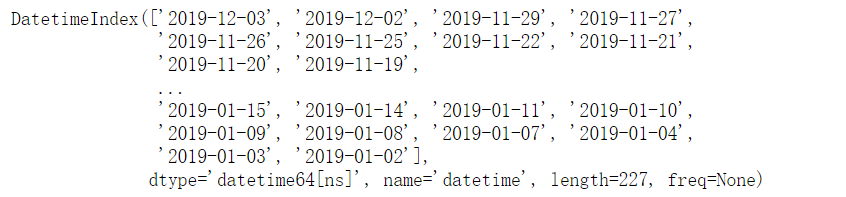
df.sort_index(inplace=True)
df.head()

(2)使用Pyecharts绘制折线图
from pyecharts.charts import Line
from pyecharts import options as opts
折线图
line = Line()
x轴
line.add_xaxis(df.index.tolist())
每个y轴
line.add_yaxis("开盘价", df["open"].round(2).tolist())
line.add_yaxis("收盘价", df["close"].round(2).tolist())
图表配置
line.set_global_opts(
title_opts=opts.TitleOpts(title="百度股票2019年"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross")
)
渲染数据
line.render_notebook()

24.Pandas结合Sklearn实现泰坦尼克存活率预测
处理步骤:
- 输入数据:使用Pandas读取训练数据(历史数据,特点是已经知道了这个人最后有没有活下来)
- 训练模型:使用Sklearn训练模型
- 使用模型:对于一个新的不知道存活的人,预估他存活的概率
在这里插入代码片
(1)读取数据
df_train = pd.read_csv("./datas/titanic/titanic_train.csv")
df_train.head()

其中,Survived==1代表这个人活下来了、==0代表没活下来;其他的都是这个人的信息和当时的仓位、票务情况
我们只挑选两列,作为预测需要的特征
feature_cols = ['Pclass', 'Parch']
X = df_train.loc[:, feature_cols]
X.head()

单独提取是否存活的列,作为预测的目标
y = df_train.Survived
y.head()

(2)训练模型
from sklearn.linear_model import LogisticRegression
创建模型对象
logreg = LogisticRegression()
实现模型训练
logreg.fit(X, y)
logreg.score(X, y)
0.6879910213243546
(3)使用模型
找一个历史数据中不存在的数据
X.drop_duplicates().sort_values(by=["Pclass", "Parch"])

预测这个数据存活的概率
logreg.predict([[2, 4]])
array([1])
logreg.predict_proba([[2, 4]])
array([[0.35053893, 0.64946107]])
25.Pandas处理分析网站原始访问日志
(1)读取数据、清理、格式化
import pandas as pd
import numpy as np
显示所有的列
pd.set_option('display.max_colwidth', -1)
from pyecharts import options as opts
from pyecharts.charts import Bar,Pie,Line
# 读取整个目录,将所有的文件合并到一个dataframe
data_dir = "./datas/crazyant/blog_access_log"
df_list = []
import os
for fname in os.listdir(f"{data_dir}"):
df_list.append(pd.read_csv(f"{data_dir}/{fname}", sep=" ", header=None, error_bad_lines=False))
df = pd.concat(df_list)
df.head()

df = df[[0, 3, 6, 9]].copy()
df.head()

df.columns = ["ip", "stime", "status", "client"]
df.head()

df.dtypes

(2)统计爬虫spider的访问比例,输出柱状图
df["is_spider"] = df["client"].str.lower().str.contains("spider")
df.head()

df_spider = df["is_spider"].value_counts()
df_spider

bar = (
Bar()
.add_xaxis([str(x) for x in df_spider.index])
.add_yaxis("是否Spider", df_spider.values.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="爬虫访问量占比"))
)
bar.render_notebook()

(3)统计http状态码的访问占比,输出饼图
df_status = df.groupby("status").size()
df_status

list(zip(df_status.index, df_status))

pie = (
Pie()
.add("状态码比例", list(zip(df_status.index, df_status)))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render_notebook()

(4)统计按小时、按天的PV/UV流量趋势,输出折线图
df["stime"] = pd.to_datetime(df["stime"].str[1:], format="%d/%b/%Y:%H:%M:%S")
df.head()

df.set_index("stime", inplace=True)
df.sort_index(inplace=True)
df.head()

df.index

# 按小时统计
df_pvuv = df.resample("H")["ip"].agg([np.size, pd.Series.nunique])
df_pvuv.head()

line = (
Line()
.add_xaxis(df_pvuv.index.tolist())
.add_yaxis("PV", df_pvuv["size"].tolist())
.add_yaxis("UV", df_pvuv["nunique"].tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="PVUV数据对比"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross")
)
)
line.render_notebook()

# 按每6个小时统计
df_pvuv = df.resample("6H")["ip"].agg([np.size, pd.Series.nunique])


# 按天统计
df_pvuv = df.resample("D")["ip"].agg([np.size, pd.Series.nunique])
df_pvuv.head()


26.Pandas怎样找出最影响结果的那些特征?
泰坦尼克号沉船事件中,最影响生死的因素有哪些?
26.1 导入数据
import pandas as pd
import numpy as np
# 特征最影响结果的K个特征
from sklearn.feature_selection import SelectKBest
# 卡方检验,作为SelectKBest的参数
from sklearn.feature_selection import chi2
df = pd.read_csv("./datas/titanic/titanic_train.csv")
df.head()

df = df[["PassengerId", "Survived", "Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]].copy()
df.head()

26.2 数据清理和转换
(1)查看是否有空值列
df.info()

(2)给Age列填充平均值
df["Age"] = df["Age"].fillna(df["Age"].median())

(3)将性别列变成数字
# 性别
df.Sex.unique()

df.loc[df["Sex"] == "male", "Sex"] = 0
df.loc[df["Sex"] == "female", "Sex"] = 1

(4)给Embarked列填充空值,字符串转换成数字
# Embarked
df.Embarked.unique()

# 填充空值
df["Embarked"] = df["Embarked"].fillna(0)
# 字符串变成数字
df.loc[df["Embarked"] == "S", "Embarked"] = 1
df.loc[df["Embarked"] == "C", "Embarked"] = 2
df.loc[df["Embarked"] == "Q", "Embarked"] = 3

26.3 找出特征
(1)将特征列和结果列拆分开
y = df.pop("Survived")
X = df

y.head()

(2)使用卡方检验选择topK的特征
# 选择所有的特征,目的是看到特征重要性排序
bestfeatures = SelectKBest(score_func=chi2, k=len(X.columns))
fit = bestfeatures.fit(X, y)
(3)按照重要性顺序打印特征列表
df_scores = pd.DataFrame(fit.scores_)
df_scores

df_columns = pd.DataFrame(X.columns)
df_columns

# 合并两个df
df_feature_scores = pd.concat([df_columns,df_scores],axis=1)
# 列名
df_feature_scores.columns = ['feature_name','Score'] #naming the dataframe columns
# 查看
df_feature_scores

df_feature_scores.sort_values(by="Score", ascending=False)

27.Pandas的Categorical类型

(1)读取数据
df = pd.read_csv("./datas/movielens-1m/users.dat",
sep="::",
engine="python",
header=None,
names="UserID::Gender::Age::Occupation::Zip-code".split("::"))

df.info()

df.info(memory_usage="deep")

df_cat = df.copy()
df_cat.head()

(2)使用Categorical类型降低存储量
df_cat["Gender"] = df_cat["Gender"].astype("category")
df_cat.info(memory_usage="deep")

df_cat.head()

df_cat["Gender"].value_counts()

(3)提升运算速度
%timeit df.groupby("Gender").size()
564 µs ± 10.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit df_cat.groupby("Gender").size()
324 µs ± 5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
28.Pandas的get_dummies用于机器学习的特征处理

(1)读取数据
df_train = pd.read_csv("./datas/titanic/titanic_train.csv")
df_train.head()

df_train.drop(columns=["Name", "Ticket", "Cabin"], inplace=True)
df_train.head()

df_train.info()

特征说明:
- 数值特征:Fare
- 分类-有序特征:Age
- 分类-普通特征:PassengerId、Pclass、Sex、SibSp、Parch、Embarked
Survived为要预测的Label
(2)分类有序特征可以用数字的方法处理
# 使用年龄的平均值,填充空值
df_train["Age"] = df_train["Age"].fillna(df_train["Age"].mean())
df_train.info()

(3)普通无序分类特征可以用get_dummies
# series
pd.get_dummies(df_train["Sex"]).head()

注意,One-hot-Encoding一般要去掉一列,不然会出现dummy variable trap,因为一个人不是male就是femal,它俩有推导关系 https://www.geeksforgeeks.org/ml-dummy-variable-trap-in-regression-models/
# 便捷方法,用df全部替换
needcode_cat_columns = ["Pclass","Sex","SibSp","Parch","Embarked"]
df_coded = pd.get_dummies(
df_train,
# 要转码的列
columns=needcode_cat_columns,
# 生成的列名的前缀
prefix=needcode_cat_columns,
# 把空值也做编码
dummy_na=True,
# 把1 of k移除(dummy variable trap)
drop_first=True
)

(4)机器学习模型训练
y = df_coded.pop("Survived")
y.head()

X = df_coded
X.head()

from sklearn.linear_model import LogisticRegression
# 创建模型对象
logreg = LogisticRegression(solver='liblinear')
# 实现模型训练
logreg.fit(X, y)

logreg.score(X, y)
0.8148148148148148
29.Pandas使用explode实现一行变多行统计
(1)读取数据
df = pd.read_csv(
"./datas/movielens-1m/movies.dat",
header=None,
names="MovieID::Title::Genres".split("::"),
sep="::",
engine="python"
)

问题:怎样实现这样的统计,每个题材有多少部电影?
解决思路:
- 将Genres按照分隔符|拆分
- 按Genres拆分成多行
- 统计每个Genres下的电影数目
(2)将Genres字段拆分成列表
df.info()

# 当前的Genres字段是字符串类型
type(df.iloc[0]["Genres"])
str
# 新增一列
df["Genre"] = df["Genres"].map(lambda x:x.split("|"))

# Genre的类型是列表
print(df["Genre"][0])
print(type(df["Genre"][0]))

df.info()

(3)使用explode将一行拆分为多行
语法:pandas.DataFrame.explode(column)
将dataframe的一个list-like的元素按行复制,index索引随之复制
df_new = df.explode("Genre")

(4)实现拆分后的题材的统计
%matplotlib inline
df_new["Genre"].value_counts().plot.bar()

30.Pandas计算同比环比指标的3种方法

30.1 读取连续3年的天气数据
import pandas as pd
%matplotlib inline
fpath = "./datas/beijing_tianqi/beijing_tianqi_2017-2019.csv"
df = pd.read_csv(fpath, index_col="ymd", parse_dates=True)

# 替换掉温度的后缀℃
df["bWendu"] = df["bWendu"].str.replace("℃", "").astype('int32')

# 新的df,为每个月的平均最高温
df = df[["bWendu"]].resample("M").mean()
# 将索引按照日期升序排列
df.sort_index(ascending=True, inplace=True)

df.index

df.plot()

30.2 pandas.Series.pct_change
pct_change方法直接算好了"(新-旧)/旧"的百分比
官方文档地址:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.pct_change.html
df["bWendu_way1_huanbi"] = df["bWendu"].pct_change(periods=1)
df["bWendu_way1_tongbi"] = df["bWendu"].pct_change(periods=12)

30.3 pandas.Series.shift
shift用于移动数据,但是保持索引不变
官方文档地址:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.shift.html
# 见识一下shift做了什么事情
# 使用pd.concat合并Series列表变成一个大的df
pd.concat(
[df["bWendu"],
df["bWendu"].shift(periods=1),
df["bWendu"].shift(periods=12)],
axis=1
).head(15)

# 环比
series_shift1 = df["bWendu"].shift(periods=1)
df["bWendu_way2_huanbi"] = (df["bWendu"]-series_shift1)/series_shift1
# 同比
series_shift2 = df["bWendu"].shift(periods=12)
df["bWendu_way2_tongbi"] = (df["bWendu"]-series_shift2)/series_shift2

30.4 pandas.Series.diff
pandas.Series.diff用于新值减去旧值
pd.concat(
[df["bWendu"],
df["bWendu"].diff(periods=1),
df["bWendu"].diff(periods=12)],
axis=1
).head(15)

# 环比
series_diff1 = df["bWendu"].diff(periods=1)
df["bWendu_way3_huanbi"] = series_diff1/(df["bWendu"]-series_diff1)
# 同比
series_diff2 = df["bWendu"].diff(periods=12)
df["bWendu_way3_tongbi"] = series_diff2/(df["bWendu"]-series_diff2)
















 751
751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









