






学习意义
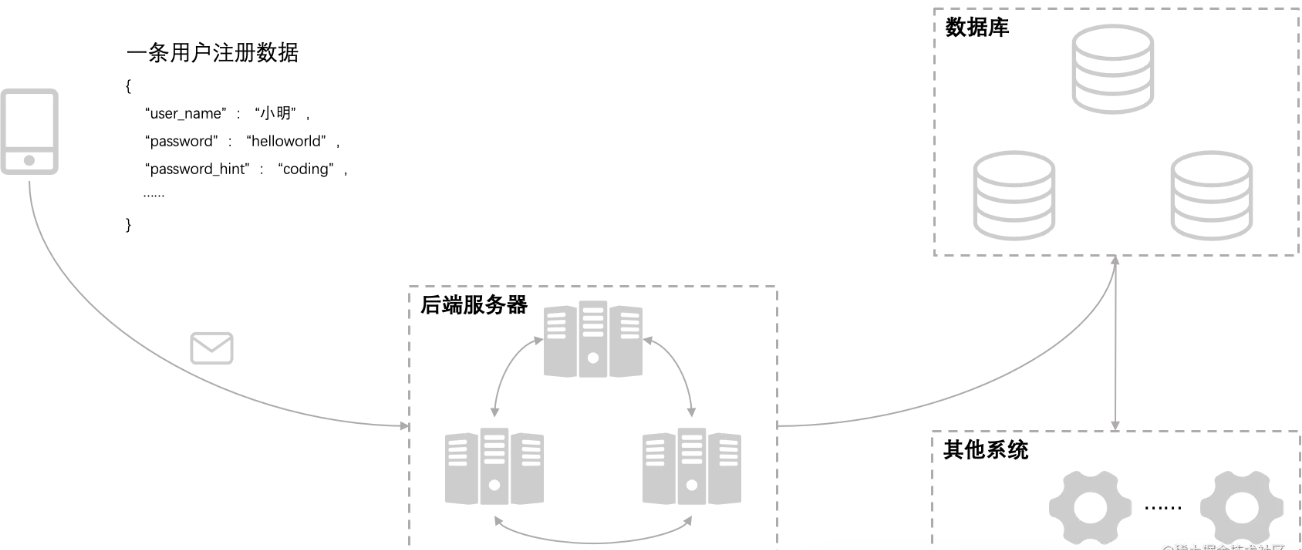
众所周知,无论是前端、后端,最终系统数据都会通过数据库系统进行读取和写入等操作,如下图所示,注册数据经过后端服务器最终进入数据库,因此可以认为数据库是系统的核心,特别是一旦涉及到高并发时,数据库可能成为系统的瓶颈,因此数据库的底层有必要深入学习,这里简单总结下基础数据库的底层实现,为后续深入学习数据库打下基础
背景知识
存储&数据库
存储系统包括:
-
块存储:存储软件栈里的底层系统,但接口过于朴素
-
文件存储:使用最广泛的存储系统,接口友好,实现五花八门
-
对象存储:公有云上的王牌产品,immutable语义加持
-
key-value存储:形式最灵活,存在大量的开源/黑盒产品
数据库系统包括:
-
关系型:基于关系和关系代数构建,一般支持事务和SQL访问,使用体验友好的存储产品
-
非关系型:结构和访问方式灵活,不同场景有不同的针对性产品
分布式架构包括:
-
数据分布策略:决定了数据怎么分布到集群里的多个物理节点,是否均匀,是否能做到高性能
-
数据复制协议:影响IO路径的性能、机器故障场景的处理方式
-
分布式事务算法:多个数据库节点协同保障一个事务的ACID特性的算法,通常基于2pc的思想设计
数据库结构
一条SQL语句在数据库中执行过程如图:
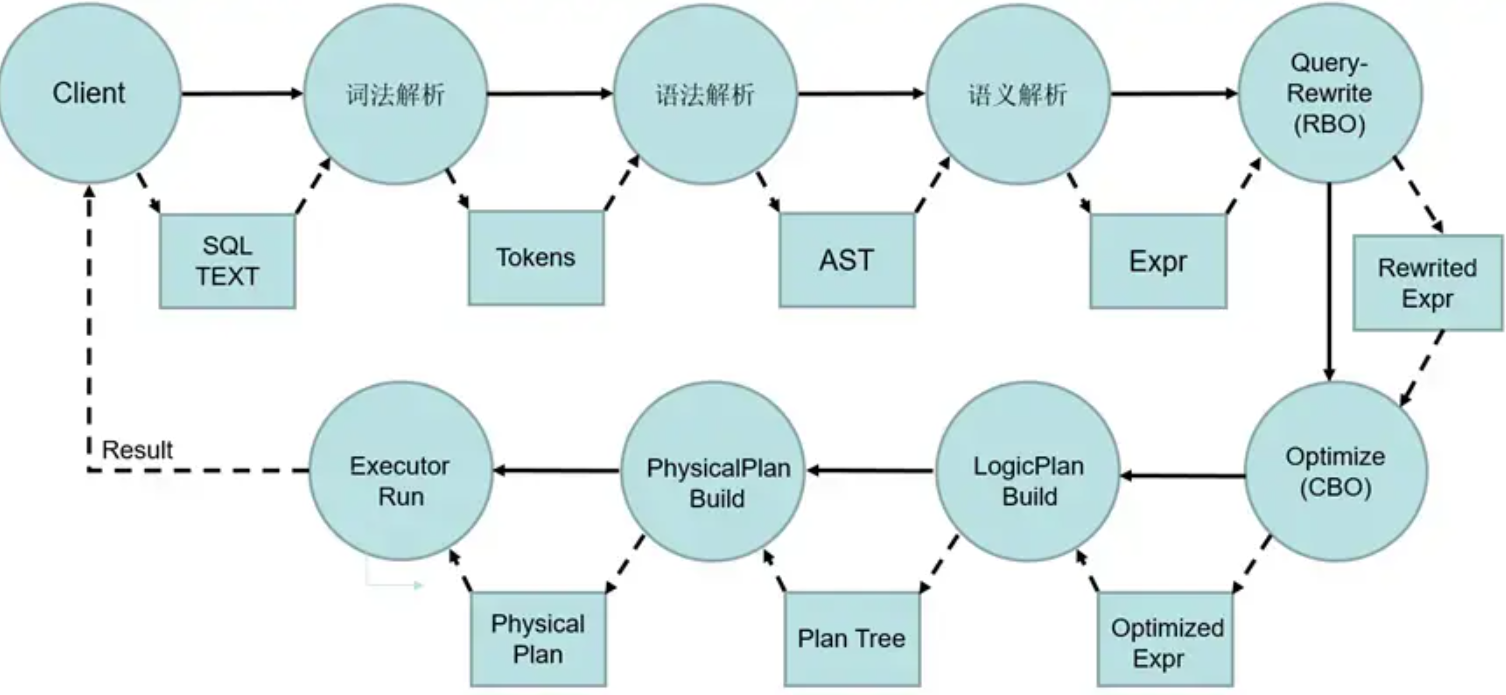
- 数据库接受客户端传的SQL语句文本
- 经过词法解析得到一组词条
- 经过语义解析得到语法树(Abstract Syntax Tree,AST)
- 经过语义解析得到表达式
- 经过规则优化(Rule-Based Optimization,RBO),主要是查询重写,表达式化简,谓词下推等
- 经过代价优化(Cost-Based Optimization,CBO)得最优查询表达式,即列举所有路径并计算各路径代价选择代价最小路径
- 构建逻辑计划再构建物理计划
- 执行期执行计划
- 返回结果
数据库包括三大引擎:
SQL引擎
- Parser:查询解析,生成语法树,并进行合法性校验(词法、语法、语义)
- Optimizer:根据语法树选择最优执行路径
- Executor:查询执行流程,真实的对数据进行处理
以sql语句为例说明:
SELECT a FROM test WHERE a > 4;
词法解析,sql语句被切割成词条:
| SELECT | a | FROM | test | WHERE | a | > | 4 |
|---|
语法解析将词条序列组合成各类语法短句,与既定的语法规则匹配,若匹配成功则生成对应的抽象语法树,否则报语法错误,既定规则:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cWzeHMib-1658938296741)(https://blog-1258366838.cos.ap-nanjing.myqcloud.com/view)]](https://img-blog.csdnimg.cn/0336232b155d4288a005e72f475a502a.png)
语法解析时,每次移到一个词条进行匹配,匹配上就规约操作,否则继续移,直到所有词条移完且成功规约则解析完毕,生成对应语法树。以上面词条为例:移到SELECT无规约且剩余词条,继续移到a,a可规约成tartet_list,用tartet_list替代词条a,移到FROM,继续移动到test规约成from_list替代词条test,然后from和from_list还可以规约成from_clause,继续规约移到WHERE,继续移到a规约成expr替代a,继续移到>,继续移进4可规约成expr替代4,此时expr>expr可规约成a_expr,用a_expr替代之,where和a_expr规约成where_clause,最终SELECT和target_list和from_clause和where_clause规约成simple_select_clause,解析完生成对应的语法树
语义分析是对语法树(AST)进行有效性审查,如表、列、列类型、函数、表达式等进行检查。继续上面为例会审查三个地方:
- from_clause:审查语句中的表test是否存在
- target_list:审查a列是否是from子句某个关系或视图的属性
- where_clause:审查a列是否是from子句某个关系或视图的属性且a列的类型是否能进行>4的比较操作
语义解析结束后会生成对应表达式供优化器使用
事务引擎
实现事务ACID四大特性
事务的概念:事务是个数据库操作命令序列,要么都执行要么不执行,是整体不可分割的逻辑单元,通过事务整体性保证数据一致性
事务的ACID特性:
-
原子性:事务不可再分割,事务中的操作要么都发生或都不发生
-
一致性:事务开始前和结束后,数据库的完整性约束没有被破坏
-
隔离性:并发环境中不同事务独立,不依赖于或影响其他事务
-
持久性:事务完成后,对数据库的更改便持久的保存在数据库之中,并不会被回滚
事务间的4个影响(间接):
- 脏读:一个事务读取另一个事务未提交的数据,而这个数据有可能回滚
- 不可重复读:一个事务内两个相同的查询却返回不同数据。是由于查询时系统中其他事务修改的提交引起
- 幻读:一事务对一表中的数据修改,修改涉及到表中全部数据行。同时,另一事务也向表中插入一行新数据。则操作前一事务的用户会发现表中还有没有修改的数据行,就象发生幻觉
- 丢失更新:两事务同时读取同一记录,A先改,B也改记录(B不知道A改过),B提交数据后B的修改结果覆盖A的结果
事务间的四大隔离:
| 隔离 | 说明 | 作用 |
|---|---|---|
| 未提交读read uncommitted | 读未提交的数据 | 不解决脏读 |
| 提交读read committed | 读已提交的数据 | 可解决脏读,Oracle和SQL Server默认隔离级别 |
| 可重复读repeatable read | 重复读取 | 可解决脏读和不可重复读 ,mysql默认隔离级别 |
| 串行读serializable | 串行化 | 相当于锁表,每次读写都需要获得表级共享锁,相互阻塞 |
事务控制语句:
- 开始事务:BEGIN 或 START TRANSACTION,显式地开启一个事务
- 提交事务:COMMIT 或 COMMIT WORK,对数据库进行的所有修改变为永久性的,set autocommit=0或1设置是否自动提交
- 回滚:ROLLBACK 或 ROLLBACK WORK,会结束用户的事务,并撤销正进行的所有未提交的修改
- 创建回滚点:SAVEPOINT S1,在事务中创建一回滚点s1,一事务中可有多个回滚点
- 回滚到回滚点:ROLLBACK TO [SAVEPOINT] S1,把事务回滚到标记点s1
存储引擎
存储数据、索引、日志
存储引擎是数据库将数据存储在文件系统中的存储方式或格式,每种存储引擎都使用不同存储机制、索引技巧并最终提供不同功能,存储引擎处于文件系统上,在数据保存到数据文件前会传输到存储引擎,之后按各存储引擎的存储格式进行存储
系统设计
项目分解
如下图是整个系统的各模块之间的交互,主要有Parser、Optimizer、Executor等,具体来说主要功能包括:
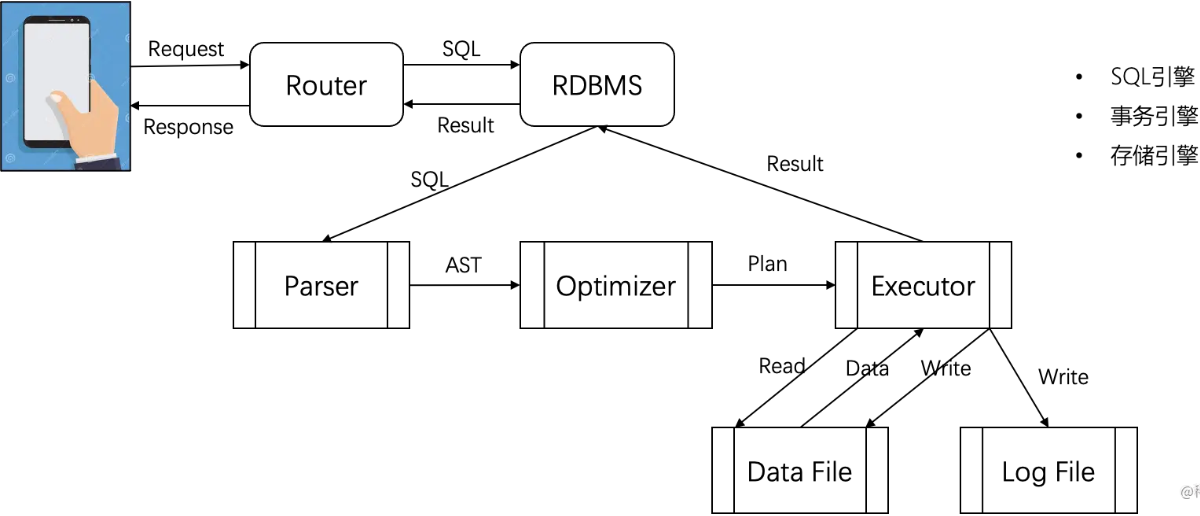
- SQL引擎:
- Parser:查询解析,生产语法树,并进行合法性校验
- Optimizer:由语法树选择最优执行路径
- Executor:基于火山模型查询执行流程
- 事务引擎:支持事务提交和回滚机制
- 存储引擎:
- 数据结构设计
- 索引结构设计
项目搭建
用CMake工具编写CMakeLists.txt文件,进行跨平台编译,参考链接,这里直接给出cmake文件
cmake_minimum_required(VERSION 3.8)
project(MyDB)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_COMPILER "g++")
set(CMAKE_CXX_FLAGS "-g -Wall -Werror -std=c++11")
set(CMAKE_CXX_FLAGS_DEBUG "-O0")
set(CMAKE_CXX_FLAGS_RELEASE "-O2 -DNDEBUG ")
set(CMAKE_INSTALL_PREFIX "install")
set(CMAKE_LIBRARY_OUTPUT_DIRECTORY
${CMAKE_BINARY_DIR}/lib)
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY
${CMAKE_BINARY_DIR}/bin)
include_directories(${CMAKE_SOURCE_DIR}/sql-parser/include)
add_subdirectory(src/main)
add_subdirectory(src/sql-parser-test)
SQL引擎设计
Parser
SQL的解析非常繁琐,直接使用开源的SQL解析器,因此只需将其编译成库并包含其头文件即可
由于sql-parser库只提供词法分析和语法分析,生成如下图不同查询树,不能进行语义分析,也就是合法性校验,因此对sql-parser库进行封装,增加语义分析功能
语义分析的核心逻辑是调用SQLParser::parse接口解析sql语句,并校验是否合法,调用checkStmtsMeta进行语法树语义分析,而该函数调用checkMeta根据不同语法树类别做不同校验
//语义分析
bool Parser::parseStatement(std::string query) {
result_ = new SQLParserResult;
SQLParser::parse(query, result_);//接口
//校验
if (result_->isValid()) {
return checkStmtsMeta();
} else {
std::cout << "[BYDB-Error] Failed to parse sql statement." << std::endl;
}
return true;
}
bool Parser::checkStmtsMeta() {
for (size_t i = 0; i < result_->size(); ++i) {
const SQLStatement* stmt = result_->getStatement(i);
if (checkMeta(stmt)) {
return true;
}
}
return false;
}
//根据不同类别做不同校验
bool Parser::checkMeta(const SQLStatement* stmt) {
switch (stmt->type()) {
case kStmtSelect:
return checkSelectStmt(static_cast<const SelectStatement*>(stmt));
case kStmtInsert:
return checkInsertStmt(static_cast<const InsertStatement*>(stmt));
case kStmtUpdate:
return checkUpdateStmt(static_cast<const UpdateStatement*>(stmt));
case kStmtDelete:
return checkDeleteStmt(static_cast<const DeleteStatement*>(stmt));
case kStmtCreate:
return checkCreateStmt(static_cast<const CreateStatement*>(stmt));
case kStmtDrop:
return checkDropStmt(static_cast<const DropStatement*>(stmt));
case kStmtTransaction:
case kStmtShow:
return false;
default:
std::cout << "[BYDB-Error] Statement type "
<< StmtTypeToString(stmt->type()) << " is not supported now."
<< std::endl;
}
return true;
}
这里以kStmtSelect为例简要说明,其他都差不多,具体可参考代码,若语句类型为select,则先获取表名,判断是否存在该表,否则继续判断select语句中的groupBy子句是否为空、是否支持UNION等操作,具体可参考代码,不在赘述
bool Parser::checkSelectStmt(const SelectStatement* stmt) {
TableRef* table_ref = stmt->fromTable;
Table* table = getTable(table_ref);
if (table == nullptr) {
std::cout << "[BYDB-Error] Can not find table "
<< TableNameToString(table_ref->schema, table_ref->name)
<< std::endl;
return true;
}
if (stmt->groupBy != nullptr) {
std::cout << "[BYDB-Error] Do not support 'Group By' clause" << std::endl;
return true;
}
if (stmt->setOperations != nullptr) {
std::cout << "[BYDB-Error] Do not support Set Operation like 'UNION', "
"'Intersect', ect."
<< std::endl;
return true;
}
if (stmt->withDescriptions != nullptr) {
std::cout << "[BYDB-Error] Do not support 'with' clause." << std::endl;
return true;
}
if (stmt->lockings != nullptr) {
std::cout << "[BYDB-Error] Do not support 'lock' clause." << std::endl;
return true;
}
if (stmt->selectList != nullptr) {
for (auto expr : *stmt->selectList) {
if (checkExpr(table, expr)) {
return true;
}
}
}
if (stmt->whereClause != nullptr) {
if (checkExpr(table, stmt->whereClause)) {
return true;
}
}
if (stmt->order != nullptr) {
for (auto order : *stmt->order) {
if (checkExpr(table, order->expr)) {
return true;
}
}
}
if (stmt->limit != nullptr) {
if (checkExpr(table, stmt->limit->limit)) {
return true;
}
if (checkExpr(table, stmt->limit->offset)) {
return true;
}
}
return false;
}
Optimizer
根据产生的查询树,生成对应的计划树,计划树由各基础算子组成,针对本项目中要求的场景,构造了如下基础算子:
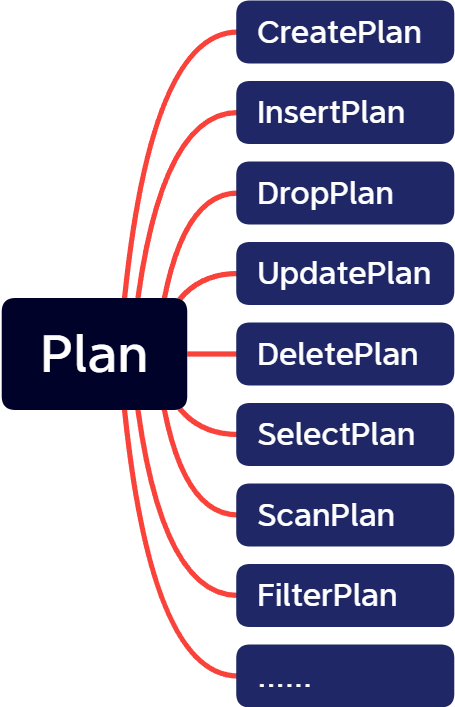
同样,根据不同类型,生成不同计划树
Plan* Optimizer::createPlanTree(const SQLStatement* stmt) {
switch (stmt->type()) {
case kStmtSelect:
return createSelectPlanTree(static_cast<const SelectStatement*>(stmt));
case kStmtInsert:
return createInsertPlanTree(static_cast<const InsertStatement*>(stmt));
case kStmtUpdate:
return createUpdatePlanTree(static_cast<const UpdateStatement*>(stmt));
case kStmtDelete:
return createDeletePlanTree(static_cast<const DeleteStatement*>(stmt));
case kStmtCreate:
return createCreatePlanTree(static_cast<const CreateStatement*>(stmt));
case kStmtDrop:
return createDropPlanTree(static_cast<const DropStatement*>(stmt));
case kStmtTransaction:
return createTrxPlanTree(static_cast<const TransactionStatement*>(stmt));
case kStmtShow:
return createShowPlanTree(static_cast<const ShowStatement*>(stmt));
default:
std::cout << "[BYDB-Error] Statement type "
<< StmtTypeToString(stmt->type()) << " is not supported now."
<< std::endl;
}
return nullptr;
}
比如一条UPDATE查询,对应的UpdatePlan计划树如下:
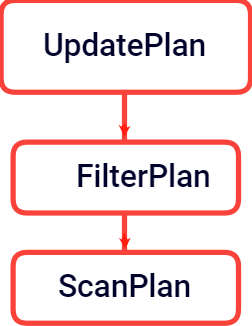
通过调用createUpdatePlanTree创建UpdatePlan计划树,代码如下:
Plan* Optimizer::createUpdatePlanTree(const UpdateStatement* stmt) {
Table* table = g_meta_data.getTable(stmt->table->schema, stmt->table->name);
Plan* plan;
ScanPlan* scan = new ScanPlan();
scan->type = kSeqScan;
scan->table = table;
plan = scan;
if (stmt->where != nullptr) {
Plan* filter = createFilterPlan(table->columns(), stmt->where);
filter->next = plan;
plan = filter;
}
UpdatePlan* update = new UpdatePlan();
update->table = table;
update->next = plan;
for (auto upd : *stmt->updates) {
size_t idx = 0;
update->values.push_back(upd->value);
for (auto col : *table->columns()) {
if (strcmp(upd->column, col->name) == 0) {
update->idxs.push_back(idx);
break;
}
idx++;
}
}
return update;
}
Executor
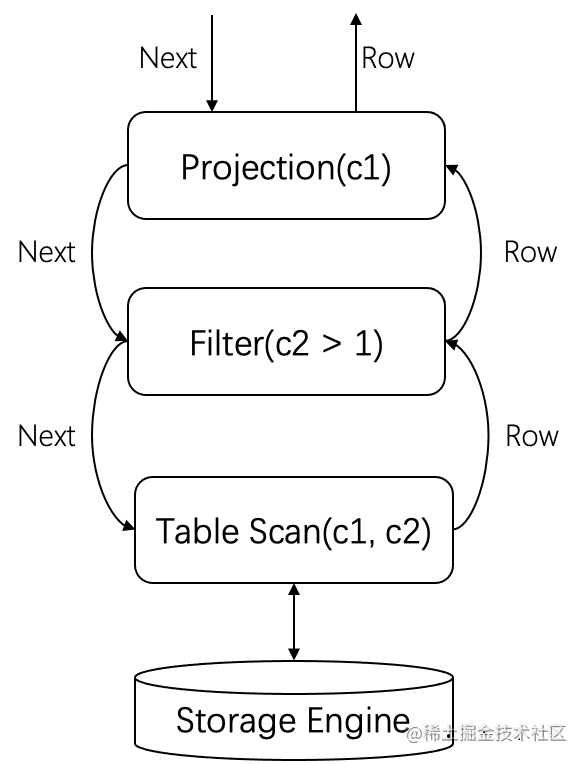
依赖计划树生成对应的执行树,每个Plan生成一个对应的Operator,生成如图Operator,代码如下:
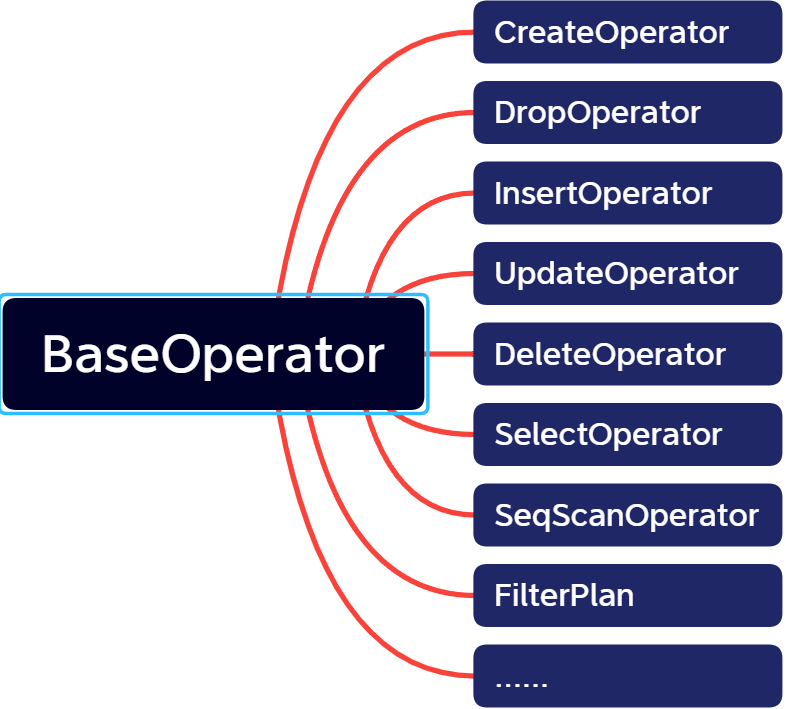
BaseOperator* Executor::generateOperator(Plan* plan) {
BaseOperator* op = nullptr;
BaseOperator* next = nullptr;
/* Build Operator tree from the leaf. */
if (plan->next != nullptr) {
next = generateOperator(plan->next);
}
switch (plan->planType) {
case kCreate:
op = new CreateOperator(plan, next);
break;
case kDrop:
op = new DropOperator(plan, next);
break;
case kInsert:
op = new InsertOperator(plan, next);
break;
case kUpdate:
op = new UpdateOperator(plan, next);
break;
case kDelete:
op = new DeleteOperator(plan, next);
break;
case kSelect:
op = new SelectOperator(plan, next);
break;
case kScan: {
ScanPlan* scan_plan = static_cast<ScanPlan*>(plan);
if (scan_plan->type == kSeqScan) {
op = new SeqScanOperator(plan, next);
}
break;
}
case kFilter:
op = new FilterOperator(plan, next);
break;
case kTrx:
op = new TrxOperator(plan, next);
break;
case kShow:
op = new ShowOperator(plan, next);
break;
default:
std::cout << "[BYDB-Error] Not support plan node "
<< PlanTypeToString(plan->planType);
break;
}
return op;
}
每个Operator调用next_.exec来调用下层Operator产生数据
class BaseOperator {
public:
BaseOperator(Plan* plan, BaseOperator* next) : plan_(plan), next_(next) {}
~BaseOperator() {}
virtual bool exec() = 0;
Plan* plan_;
BaseOperator* next_;
};
事务引擎
不考虑并发,且数据无需落盘持久化,事务引擎设计就变得简单。不需实现MVCC机制,只需能实现事务Commit和Rollback功能即可
这里实现一个undo stack的机制,每次更新一行数据,就把这行数据老的版本push到undo stack中。如果事务回滚,那么就从undo stack中把老版本的数据逐个pop出来,恢复到原有的数据中去
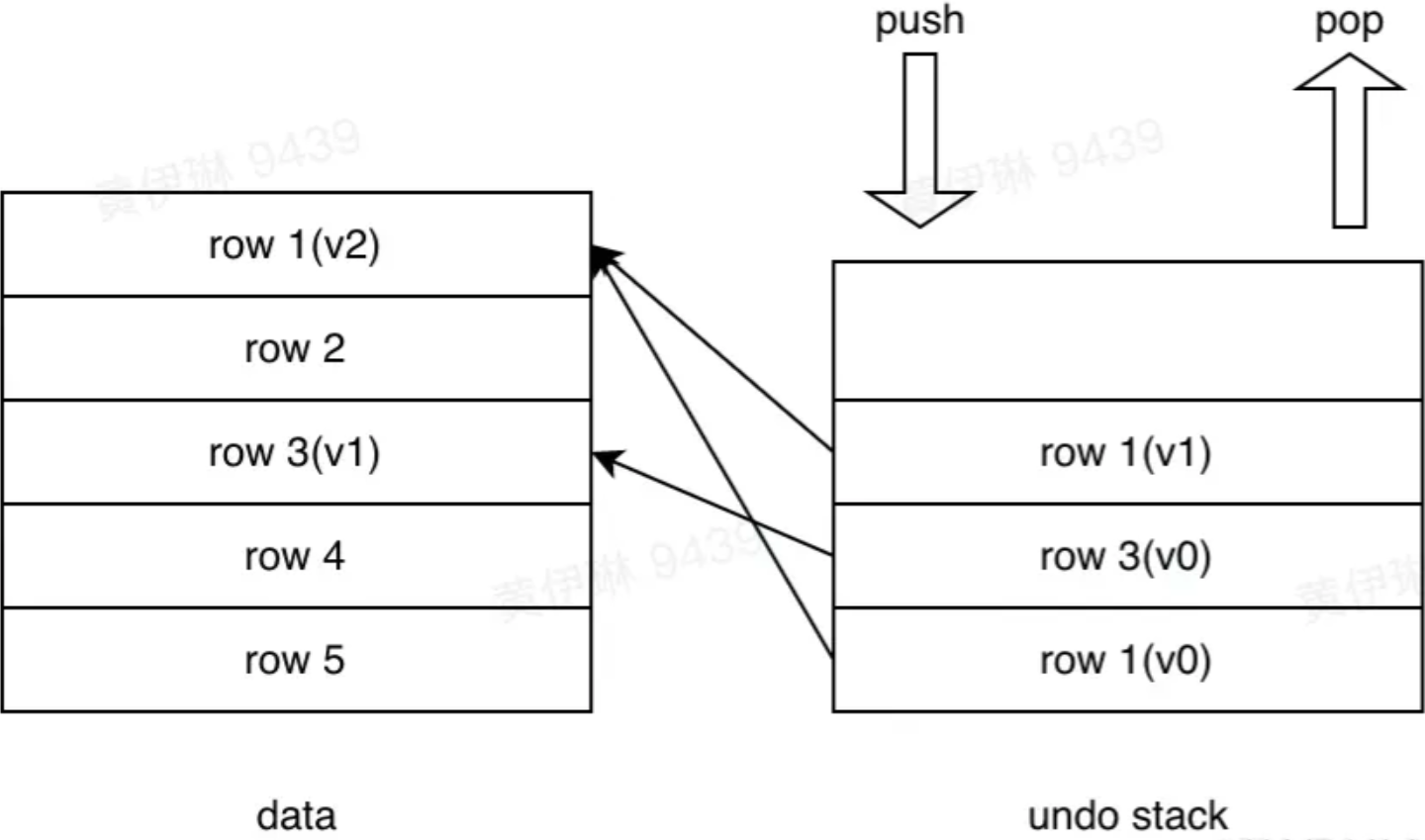
事务定义如下,有三种类型kInsertUndo、kDeleteUndo、kUpdateUndo::
enum UndoType { kInsertUndo, kDeleteUndo, kUpdateUndo };
struct Undo {
Undo(UndoType t)
: type(t), tableStore(nullptr), curTup(nullptr), oldTup(nullptr) {}
~Undo() {
if (type == kUpdateUndo) {
free(oldTup);
}
}
UndoType type;
TableStore* tableStore;
Tuple* curTup;
Tuple* oldTup;
};
class Transaction {
public:
Transaction() : inTransaction_(false) {}
~Transaction() {}
......
void begin();
void rollback();
void commit();
bool inTransaction() { return inTransaction_; }
private:
bool inTransaction_;
std::stack<Undo*> undoStack_;
};
extern Transaction g_transaction;
commit和rollback代码如下:
void Transaction::rollback() {
while (!undoStack_.empty()) {
auto undo = undoStack_.top();
TableStore* table_store = undo->tableStore;
undoStack_.pop();
switch (undo->type) {
case kInsertUndo:
table_store->removeTuple(undo->curTup);
break;
case kDeleteUndo:
table_store->recoverTuple(undo->oldTup);
break;
case kUpdateUndo:
memcpy(undo->curTup->data, undo->oldTup->data,
table_store->tupleSize() - TUPLE_HEADER_SIZE);
break;
default:
break;
}
delete undo;
}
inTransaction_ = false;
}
void Transaction::commit() {
while (undoStack_.empty()) {
auto undo = undoStack_.top();
TableStore* table_store = undo->tableStore;
undoStack_.pop();
if (undo->type == kDeleteUndo) {
table_store->freeTuple(undo->oldTup);
}
delete undo;
}
inTransaction_ = false;
}
存储引擎
数据结构
因为是内存态数据库,所以数据结构设计简单。每次申请一批记录内存,降低内存碎片化,提高内存效率。然后将这批记录的内存放到FreeList中。数据插入时,从FreeList中获取一块内存写入,并放入DataList。数据删除时,将数据从DataList归还到FreeList中,为方便这里使用双向链表
struct Tuple {
Tuple* prev;
Tuple* next;
uchar data[];
};
class TupleList {
public:
TupleList() {
head_ = static_cast<Tuple*>(malloc(sizeof(Tuple)));
tail_ = static_cast<Tuple*>(malloc(sizeof(Tuple)));
head_->next = tail_;
tail_->prev = head_;
head_->prev = nullptr;
tail_->next = nullptr;
}
......
private:
Tuple* head_;
Tuple* tail_;
};
class TableStore {
public:
TableStore(std::vector<ColumnDefinition*>* columns);
~TableStore();
......
TupleList freeList_;
TupleList dataList_;
};
索引设计
因为这里只要求实现等值匹配,所以用最简单的hash索引
总结
简单实现一个数据库原型,还非常粗糙,但对初学数据库底层原理还是很有帮助,能够对数据库原理有个整体概念,实际代码参考链接















 2098
2098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









