







建表:
CREATE TABLE no6(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
age TINYINT,
money INT,
tel CHAR(11)
);
插入数据:
INSERT INTO no6 VALUES(NULL,'张三',30,2000,13565234121),(NULL,'李四',23,1000,13814526352),(NULL,'王五',40,8000,13913656352),(NULL,'赵六',33,8000,13913121234)
使用子查询为条件进行查询:
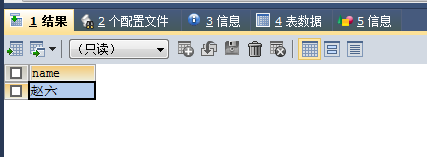
SELECT NAME FROM no6 WHERE age IN (SELECT age FROM no6 WHERE money >=2000) AND tel LIKE '%34'
随便写的哈,虽然这种子查询没有意义
更新、删除操作也可以使用子查询,但是子查询不能,更删操作表和子查询表不能相同:
操作与子查询是同一张表:
更新语句
UPDATE no6 SET money=(SELECT MAX(money) FROM no6)/2 WHERE id=(SELECT id FROM no6 ORDER BY money LIMIT 1)
报错:

删除语句
DELETE FROM no6 WHERE id=(SELECT id FROM no6 ORDER BY money LIMIT 1)
也是报错

更删no6表,子查询使用no5表
更新
UPDATE no6 SET money=(SELECT MAX(money) FROM no5)/2 WHERE id=(SELECT id FROM no5 ORDER BY money LIMIT 1)

删除
DELETE FROM no6 WHERE id=(SELECT id FROM no5 ORDER BY money LIMIT 1)

any、all、exists用法:
先插入几条数据
INSERT INTO no6 VALUES(NULL,'二蛋',35,1500,13565234121),(NULL,'大柱',28,3400,13814526352),(NULL,'铁头',42,9100,13913656352),(NULL,'小吴',37,4500,13913121234)

测试语句
SELECT money FROM no6 WHERE money>2000 AND money<6000
查询结果

就以这条语句为子查询(结果是3400-4500)为取值范围:
SELECT * FROM no6 WHERE money >ANY(SELECT money FROM no6 WHERE money>2000 AND money<6000)
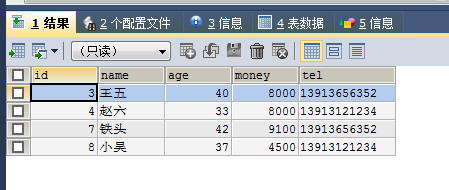
结果中有4500,没有3000。any是任意的意思,>any()的取值范围是大于括号里面的任意一个数,返回结果就是大于最小的数。
改成<any
SELECT * FROM no6 WHERE money <ANY(SELECT money FROM no6 WHERE money>2000 AND money<6000)
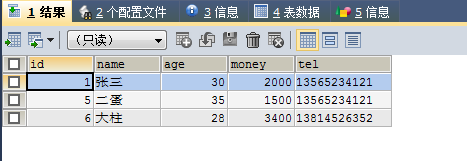
结果里面有3400,<any返回就是小于取值范围中的最大值。
再改成=any(any与some完全相同)
SELECT * FROM no6 WHERE money =ANY(SELECT money FROM no6 WHERE money>2000 AND money<6000)
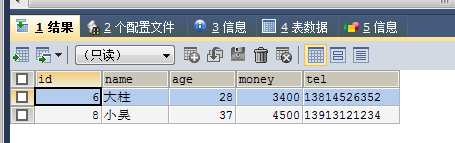
=any也就是返回取值范围内的任意值,=any相当于in,只是in的取值范围里可以直接放数字
把any改成all
SELECT * FROM no6 WHERE money =ALL (SELECT money FROM no6 WHERE money>2000 AND money<6000)
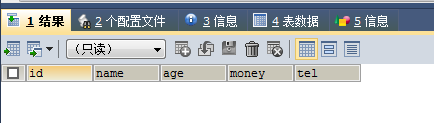
结果为空,=all只有在取值范围只有一条的情况下才生效。
改成>all
SELECT * FROM no6 WHERE money >ALL (SELECT money FROM no6 WHERE money>2000 AND money<6000)
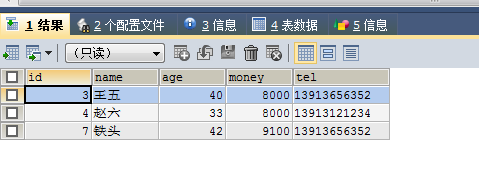
结果大于取值范围内的所有值。
改成<all
SELECT * FROM no6 WHERE money <ALL (SELECT money FROM no6 WHERE money>2000 AND money<6000)
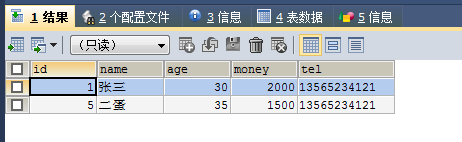
结果小于取值范围内的所有值。
改成<>all
SELECT * FROM no6 WHERE money <>ALL (SELECT money FROM no6 WHERE money>2000 AND money<6000)

not in相当于<>all,但是not in的取值范围可以直接以数字表示
SELECT * FROM no6 WHERE money NOT IN(3400,4500)

exists(),查看是否存在:
SELECT * FROM no6 WHERE EXISTS(SELECT * FROM no6 WHERE NAME='王八')
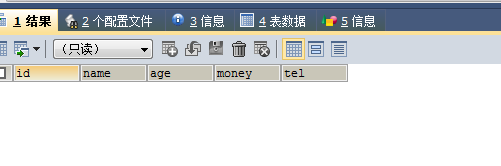
因为子查询结果不存在,查询不生效
SELECT * FROM no6 WHERE EXISTS(SELECT * FROM no6 WHERE NAME='大柱')

当子查询结果存在,查询生效。
多表连接:
先建表并插入数据
CREATE TABLE no7(
id INT PRIMARY KEY AUTO_INCREMENT,
sex CHAR(5) DEFAULT'男',
NAME VARCHAR(10),
address VARCHAR(20)
);
INSERT INTO no7 VALUES(NULL,'女','张三','八一路'),(NULL,'男','赵六','人民路'),(NULL,'男','小强','解放路'),(NULL,'女',NULL,'黄泉路');
多表连接

内连接示例:
SELECT * FROM no6 t1 JOIN no7 t2 ON t1.id=t2.id

返回结果是两表的交集。join前的inner可以省略,t1和t2是两张表的别名,用如下语句同样可以实现如上功能:
SELECT * FROM no6,no7 WHERE no6.id=no7.id
这是sql92语法,也就是连接条件和过滤条件都在一起(where后)。

指定字段进行查询的时候要注意两表是否有同名字段,如同名要说明是哪张表的:
SELECT t1.name,age,sex,t2.name FROM no6 t1 JOIN no7 t2 ON t1.id=t2.id

外连接分为左连接和右连接
外连接中的表分主次,不像内连接两表平等。
左连接示例:
SELECT * FROM no6 a LEFT OUTER JOIN no7 b ON a.id=b.id

左外连接返回结果是右表的一部分(交集)和左表的全部,join前的outer可以省略。
当如上查询语句加上右表关联字段为空的条件:
SELECT * FROM no6 a LEFT OUTER JOIN no7 b ON a.id=b.id WHERE b.id IS NULL

返回结果是左表减去交集后的剩余部分,也就是左表与右表的差集。
右外连接演示:
SELECT * FROM no6 a RIGHT JOIN no7 b ON a.id=b.id

返回结果为左表一部分(交集),右表全部。
语句后面加上条件左表关联字段为空:
SELECT * FROM no6 a RIGHT JOIN no7 b ON a.id=b.id WHERE a.id IS NULL
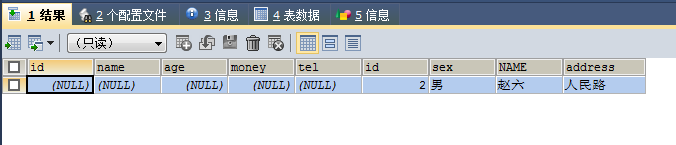
返回结果只有右表减去交集后剩余部分(右表与左表的差集)。
全连接:
mysql中是没有全连接的,但是我们可以用union实现,union用来实现多条select的语句的联合,可以把多条SELECT语句的结果组合到一个结果集合中。
先做个演示:
SELECT NAME FROM no6 WHERE id>1
UNION
SELECT NAME FROM no7 WHERE id>1;
union是默认去重的,union all不去重。union进行表连接可以变笛卡尔乘积为表之总和,也就是变乘法为加法
这两条语句没有union的时候是不能同时执行的,而现在的结果是怎么呢?

值得注意的是使用union的时候每条语句的查询字段数量要相同(在Oracle中要求类型也相同)。
全连接演示:
SELECT * FROM no6 a LEFT JOIN no7 b ON a.id=b.id
UNION
SELECT * FROM no6 a RIGHT JOIN no7 b ON a.id=b.id
语句也很简单,就是左连接和右连接用union联合,结果如下:

返回的是两张表的所有内容,也就是两表并集。
再用两张表的关联字段为空过滤掉两表交集:
SELECT * FROM no6 a LEFT JOIN no7 b ON a.id=b.id WHERE b.id IS NULL
UNION
SELECT * FROM no6 a RIGHT JOIN no7 b ON a.id=b.id WHERE a.id IS NULL
这两条查询语句之前都已经测试过了,左连接过滤掉交集返回结果是左表与右表差集,右连接过滤掉交集返回结果是右表与左表的差集。那么联合语句返回结果就是除了两表除了交集之外的所有内容,也就是两表的对称差集:

自连接:
自连接是一种特殊的连接,把一张表当成两张表使用,也就是自己连自己。
重建no7表,并插入数据:
CREATE TABLE no7(
id INT PRIMARY KEY AUTO_INCREMENT,
sex CHAR(5) DEFAULT'男',
NAME VARCHAR(10),
address VARCHAR(20),
cid INT
);
INSERT INTO no7 VALUES(NULL,'女','张三','八一路',4),(NULL,'男','赵六','人民路',3),(NULL,'男','小强','解放路',2),(NULL,'女',NULL,'黄泉路',1);

进行自连接查询:
SELECT a.id,a.name AS '正序名字',b.name AS '倒序名字' FROM no7 a INNER JOIN no7 b ON a.id=b.cid ORDER BY a.id

以表自身两个字段进行关联,然后以对同一个字段name进行了两次查询。
有一张图对各种表连接进行了说明,不是mysql的,所以仅供参考:
















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









