







要整一个每天获取一批公众号发布的文章数据
大致流程如下
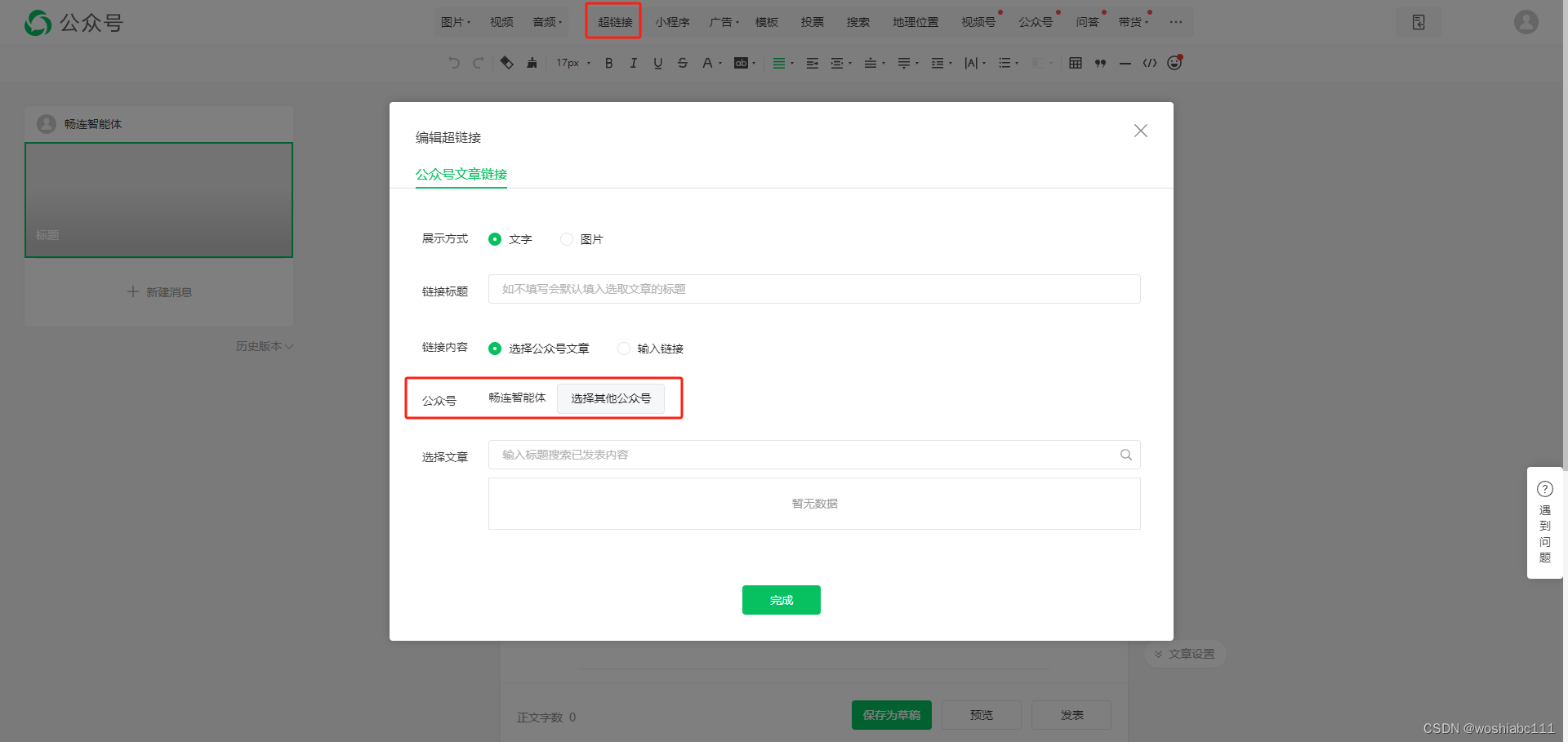
登录公众号后台—>创建图文—>点击超链接,即可选择公众号
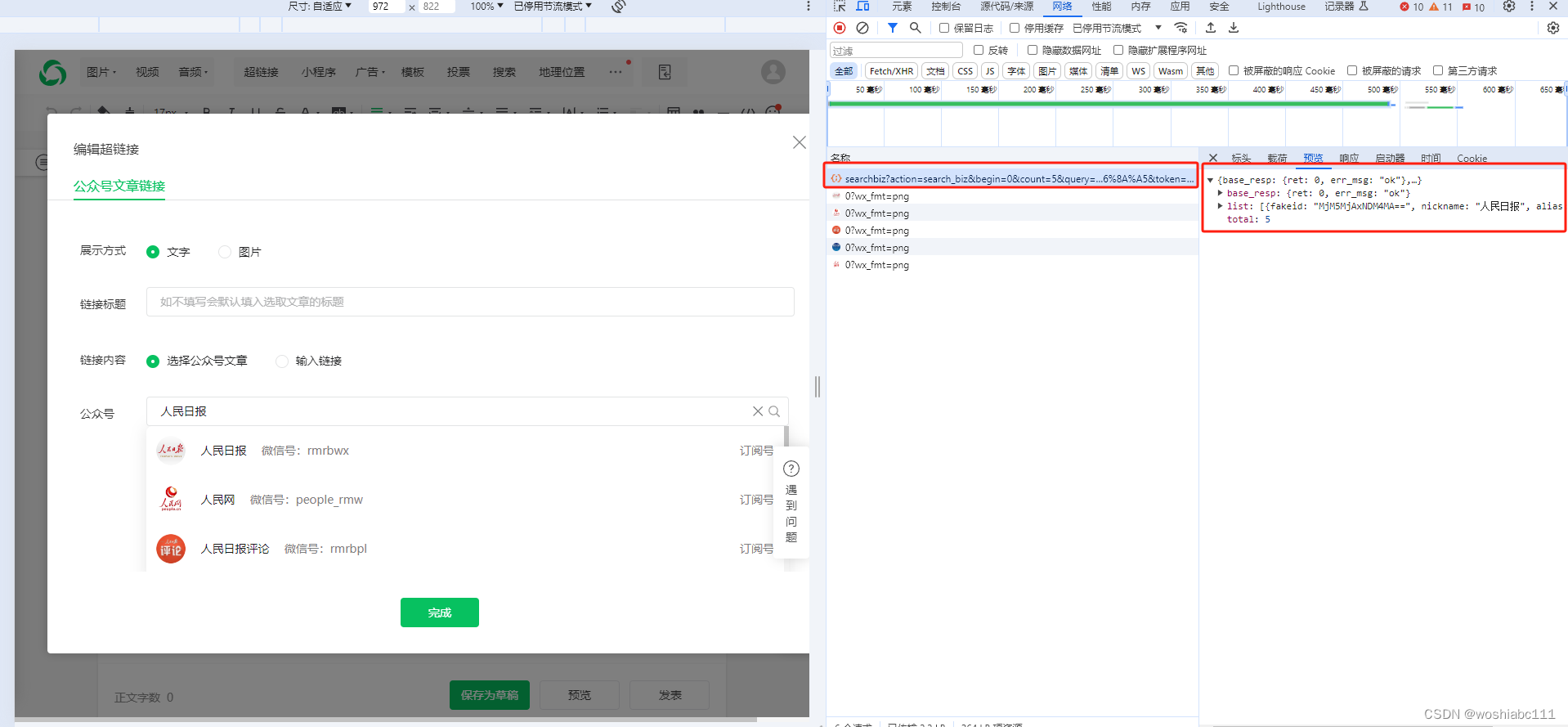
浏览器F12可看到访问地址
https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query=%E4%BA%BA%E6%B0%91%E6%97%A5%E6%8A%A5&token=1125413991&lang=zh_CN&f=json&ajax=1
里面的query参数就是你要查找的公众号名称
但是token长时间使用会失效,访问频率过高会被限制。
1.token获取
使用selenium通过chromedriver打开chrome浏览器每小时刷新页面保证能获取到最新的token和cookies信息保存到userMsg.txt文件中方便读取
#通过selenium打开Chrome浏览器用户扫码登录后页面定时刷新给token保活
#pip install selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from selenium.webdriver import ActionChains
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import json
chrome_option = Options()
chrome_option.set_capability("goog:loggingPrefs", {"performance": "ALL"})
driver = webdriver.Chrome(options=chrome_option)
driver.get('https://mp.weixin.qq.com')#用户登录后自己扫码
locator = (By.ID, 'js_index_menu')#判断用户是否扫码加载出了公众号菜单列表
WebDriverWait(driver, 120, 0.5).until(EC.presence_of_element_located(locator))#等待120秒,120秒内未扫码失效
print('login')
wait = WebDriverWait(driver, 10)
element = driver.find_element(By.ID, "js_index_menu")
def getNewToken(driver):
driver.refresh()#刷新页面
print('----------------------------打印cookies信息----------------------------------------')
# 获取当前页面的所有cookie
cookies = driver.get_cookies()
agent = driver.execute_script("return navigator.userAgent")
token = ''
cookieValue = ''
for cookie in cookies:
cookieValue = cookieValue+cookie['name']+'='+cookie['value']+';'
# 获取网络日志
logs = driver.get_log("performance")
for item in logs:
StrMsg = item['message']
data = json.loads(StrMsg)
method = data['message']['method']
if method == 'Network.responseReceived' :
tokenUrl = data['message']['params']['response']['url']
if 'cgi-bin/home' in tokenUrl:
print(tokenUrl)
parts = tokenUrl.split('&')
for cs in parts:
if 'token' in cs:
tokenArray = cs.split('=')
token = tokenArray[1]
break
return agent,cookieValue,token
while True:
strings = getNewToken(driver)
print(strings[0])#useragent
print(strings[1])#cookieValue
print(strings[2])#token
# 要保存的文本数据
userMsg = strings[0]+'*'+strings[1]+'*'+strings[2]
# 使用with语句打开一个文件,'w'表示写入模式,会覆盖已有文件或创建新文件
with open('userMsg.txt', 'w', encoding='utf-8') as file:
# 写入数据到文件
file.write(userMsg)
print("数据已成功写入文件")
time.sleep(3600)#小时刷新一次token信息3600
2.获取数据
先找到每个公众号的fakeid根据fakeid查找公众号文章列表。
再通过获取token和cookies查找公众号文章列表信息。
(注:时间间隔随机且要大于1分组否则会因为访问频率过高被封)
#微信公众号文章列表信息获取
import requests
import json
import time
import pymysql
from datetime import datetime
import logging
import random
# 创建一个logger
logger = logging.getLogger('my_logger')
logger.setLevel(logging.DEBUG) # 设置日志级别
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('app.log', encoding='utf-8') # 日志文件名
# 定义handler的输出格式
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
# 给logger添加handler
logger.addHandler(fh)
nowDate = datetime.now()
fmt_nowDate = nowDate.strftime("%Y-%m-%d")
#!!!数据库链接需要调整
mydatabase = pymysql.connect(host='localhost',
user='root',
password='123456',
database='ry',
charset='utf8mb4')
cursor = mydatabase.cursor()
try:
logger.info('******' + fmt_nowDate + '获取公众号文章开始********')
cursor.execute(
'SELECT id,base_media_name,fakeid FROM `media_account_manager` where `type_id` = 469 AND `status` = 3 and fakeid like \'%==%\''
)
result = cursor.fetchall()
for row in result:
random_integer = random.randint(60, 90)
time.sleep(random_integer) #循环间隔取60~90之间的随机数模拟用户操作
m_id = row[0]
gzh_name = row[1]
fakeid = row[2]
with open('userMsg.txt', 'r') as file:
content = file.read()
# 输出文件内容
usermsg = content.split('*')
useragent = usermsg[0]
cookieValue = usermsg[1]
token = usermsg[2]
#token = '48610794'
#cookieValue = 'appmsglist_action_3282528637=card; appmsglist_action_3897702210=card; appmsglist_action_3942684155=card; appmsglist_action_3013859857=card; RK=Ic/IKoyCW8; ptcz=183c000cfa10f540fa96f31c2abbad57770359bbc057be607856ff3a3fe91870; ua_id=kmDjlXf74NXdKWYfAAAAAKqesCSosS5sVUo4IYNaZW8=; wxuin=09083550457399; mm_lang=zh_CN; ptui_loginuin=549970894; pgv_pvid=7540307232; noticeLoginFlag=1; remember_acct=18627794529%40163.com; rand_info=CAESIHR1T2y4irHHqNUPcg04M4aksmmV4jIIF7Y9hJqo2JcJ; slave_bizuin=3942684155; data_bizuin=3942684155; bizuin=3942684155; data_ticket=/4MJazfCrCOh7PfSURyqG/mvDPGZACkoIHmwzc3QBbzlAjuzax9U/ku7ESYBho44; slave_sid=UWROS0k3TTJPUG5VUUF0UjUwSUt3eXpnTm90OHM3a3I3TF9sVGNUNU04MlViVk51TGRLOGhUcTZtZVlaaklVR2hRa3lqSjVEdkNpb05OWUdQREhtclU0NkhLNUwzcHFyN3pBNGtsY3FKc1ZkbkFKbElrdXkzN2trZ2M4SldodEgzT3owOEcxUGM0ZnpQSE00; slave_user=gh_50811555d4b3; xid=050290e4161e1ad62b569ecb78f5083b; _clck=3942684155|1|fmq|0; _clsk=1yo2xeu|1718701616094|4|1|mp.weixin.qq.com/weheat-agent/payload/record'
headers = {"Cookie": cookieValue, "User-Agent": useragent}
urlmain = "https://mp.weixin.qq.com/cgi-bin/appmsgpublish?sub=list&search_field=null&begin=0&count=5&query=&fakeid=" + fakeid + "&type=101_1&free_publish_type=1&sub_action=list_ex&token=" + token + "&lang=zh_CN&f=json&ajax=1"
responsemain = requests.get(urlmain, headers=headers, verify=False)
if responsemain.status_code == 200:
response_data2 = responsemain.json()
#print(response_data2)
get_List = response_data2['publish_page'] #获取列表文件
json_object = json.loads(get_List)
json_obj_list = json_object['publish_list']
for item in json_obj_list:
print('-----------------------------------------------------')
json_object2 = json.loads(item['publish_info'])
appmsgex_list = json_object2['appmsgex'] #每日发布文章的集合
for item2 in appmsgex_list:
print('=====文章列表======')
title = item2['title']
print(title)
ctime = item2['update_time']
local_time = time.localtime(ctime)
date_str = time.strftime("%Y-%m-%d", local_time)
print(date_str)
now = datetime.now()
formatted_date = now.strftime("%Y-%m-%d")
createDate = datetime.strptime(date_str, "%Y-%m-%d").date()
nowDate = datetime.strptime(formatted_date,
"%Y-%m-%d").date()
#如果循环出的第一篇文章日期就小于当天日期则跳出循环
if createDate < nowDate:
break
#如果是当日发布的信息则保存到数据库中
if date_str == formatted_date:
print(date_str) #公众号文章更新时间
link = item2['link']
print(link)
#time.sleep(60)#等待10秒降低访问频率
#responselink = requests.get(link, headers=headers, verify=False)
#text = responselink.text
text = ''
insert_query = "INSERT INTO `ry`.`media_content`(`title`, `pub_date`, `url`, `content`, `media_id`, `media_name`,`type_id`,`platform`) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)"
# 执行插入操作
cursor.execute(
insert_query,
(title, date_str, link, text, m_id, gzh_name, '469', '微信自动抓取'))
# 提交事务
mydatabase.commit()
except Exception as e:
logger.info('******公众号获取发生错误********')
logger.info(e)
logger.info(response_data2)
logger.info('******公众号:' + gzh_name + ',数据获取异常******')
else:
logger.info('******' + fmt_nowDate + '获取公众号文章结束********')
finally:
mydatabase.close()















 1539
1539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









