







1. 函数与栈帧
当我们调用一个函数时,CPU会在栈空间开辟一小块区域,这个函数的局部变量都在这一小块区域里存活。当函数调用结束,这一块区域里的局部变量就会被回收。
所以,帧栈本质上是一个函数的活动记录。当某个函数正在执行事,他的活动记录就会存在,当函数执行结束时,活动记录也会被销毁。
不过,要注意的是,当一个函数执行的时候,它可以调用其他函数,这个时候它的帧栈还是存在的。
2.递归
说到递归,大家基本上都能想到一个最经典的问题:汉诺塔。汉诺塔问题是这样的:有3根柱子,即为A,B,C。其中A柱子上有n个盘子,从上到下的编号依次为1到n,且上面的盘子一定比下面的盘子小。要求一次只能移动一只盘子,且大的盘子不能压在小的盘子上,那么将所有的盘子从A移动到C总共要走多少步。代码如下:
#include <stdio.h>
/**
* 将编号n 的柱子从 src 移动到 dst
* @param src
* @param dst
* @param n
*/
void move(char src, char dst, char n) {
printf("move plate %d from %c to %c\n", n, src, dst);
}
/**
* 将 src 借助 help 搬到 dst n 代表一共要搬的盘子的总数
* @param src
* @param dst
* @param help
* @param n
*/
void hanoi(char src, char dst, char help, char n) {
if (n == 1) {
move(src, dst, 1);
return;
}
// 将n-1 个盘子从A借助C 搬到 B
hanoi(src, help, dst, n - 1);
// 将第n 个盘子 从A 直接 搬到 C
move(src, dst, n);
hanoi(help, dst, src, n - 1);
}
int main() {
hanoi('A', 'C', 'B', 3);
return 0;
}
从指令的角度理解栈
int fac(int n){
return n==1? 1: n*fac(n-1);
}
上面是一个用递归的写法求阶乘的例子,源码比较简单,我们用gcc 对其进行编译,然后用objdump 对其反编译,观察它编译后的机器码。
gcc -o fac fac.c
objdump -d fac
得到的汇编如下
0000000100003f40 <_fac>:
100003f40: 55 pushq %rbp
100003f41: 48 89 e5 movq %rsp, %rbp
100003f44: 48 83 ec 10 subq $16, %rsp
100003f48: 89 7d fc movl %edi, -4(%rbp)
100003f4b: 83 7d fc 01 cmpl $1, -4(%rbp)
100003f4f: 0f 85 0d 00 00 00 jne 0x100003f62 <_fac+0x22>
100003f55: b8 01 00 00 00 movl $1, %eax
100003f5a: 89 45 f8 movl %eax, -8(%rbp)
100003f5d: e9 1c 00 00 00 jmp 0x100003f7e <_fac+0x3e>
100003f62: 8b 45 fc movl -4(%rbp), %eax
100003f65: 89 45 f4 movl %eax, -12(%rbp)
100003f68: 8b 7d fc movl -4(%rbp), %edi
100003f6b: 83 ef 01 subl $1, %edi
100003f6e: e8 cd ff ff ff callq 0x100003f40 <_fac>
100003f73: 89 c1 movl %eax, %ecx
100003f75: 8b 45 f4 movl -12(%rbp), %eax
100003f78: 0f af c1 imull %ecx, %eax
100003f7b: 89 45 f8 movl %eax, -8(%rbp)
100003f7e: 8b 45 f8 movl -8(%rbp), %eax
100003f81: 48 83 c4 10 addq $16, %rsp
100003f85: 5d popq %rbp
100003f86: c3 retq
100003f87: 66 0f 1f 84 00 00 00 00 00 nopw (%rax,%rax)
0000000100003f90 <_main>:
100003f90: 55 pushq %rbp
100003f91: 48 89 e5 movq %rsp, %rbp
100003f94: 48 83 ec 10 subq $16, %rsp
100003f98: c7 45 fc 00 00 00 00 movl $0, -4(%rbp)
100003f9f: bf 0a 00 00 00 movl $10, %edi
100003fa4: e8 97 ff ff ff callq 0x100003f40 <_fac>
100003fa9: 31 c0 xorl %eax, %eax
100003fab: 48 83 c4 10 addq $16, %rsp
100003faf: 5d popq %rbp
100003fb0: c3 retq
第一行是将当前栈基址指针存到栈顶
第二行是把栈指针保存到栈基址寄存器,这两行的作用是把当前函数的栈帧创建在调用者的栈帧之下。保存调用者的栈基址是为了在return时可以恢复这个寄存器
第三行是把栈向下增长0x10,这是为了给局部变量预留空间。从这里,你可以看出来运行fac函数是要消耗栈空间的。
试想一下,如果我们不加n==1的判断,那么fac函数就无法正常返回,会一直递归,这样栈上就会出现很多fac的帧栈,会造成栈空间耗尽,出现StackOverflow。**这里的原理是,操作系统会在栈空间的尾部设置一个禁止读写的页,一旦栈增长到尾部,操作系统就可以通过中断探知程序在访问栈末端。
第四行是把变量n存到栈上。其中变量n一开始是存储在寄存器edi中的,存储的目标地址是栈基址加上0x4的位置,也就是这个函数帧栈的第一个局部变量的位置。变量n在寄存器edi中是X86的ABI决定的,第一个整型参数一定要使用edi来传递。
第5行将变量n 与常量0x1进行比较。在第6行,如果比较的结果不相等,程序会跳到 0x100003f62 位置继续执行。
0x100003f62 这块代码就是把n-1 送到edi寄存器中,然后再次调用fac函数重复上面步骤
3.理解协程
协程是比线程更轻量的执行单元。进程和线程的调度都是有操作系统复负责的,而协程则是由执行单元相互协商进行调度的,所以它的切换发生在用户态。只有前一个协程主动地执行yield函数,让出cpu使用权,下一个协程才能得到调度。
因为程序自己负责协程的调度,所以大多数时候,我们可以让不那么忙的协程少参与调度,从而提升整个程序的吞吐量,而不是像进程那样,没有繁重任务的进程,也有可能被换进来执行。
协程的切换和调度所耗费的资源是最少的,Go语言把协程和IO多路复用结合在一起,提供了非常便捷的IO接口,使得协程的概念深入人心。
从操作协同和Web Server 演进的历史来看,先是多进程系统的出现,然后出现了多线程系统,最后才是协程被大规模使用,这个演进背后的逻辑就是执行单元需要越来越轻量,以支持更大的并发总数。
协程的核心是在用户态切换栈来执行。每个协程都拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。
目前主流语言基本上都选择多线程作为并发设施,与线程相关的概率是抢占式多任务,而与协程相关的是协作式多任务。不管是进程还是线程,每次阻塞,切换都需要陷入系统调用,先让CPU执行操作系统的调度程序,然后再由调度程序决定哪一个线程继续执行。
由于抢占式的调度执行顺序无法确定,我们使用线程时需要非常小心地处理同步问题,而协程完全不存在这个问题。因为协作式的任务调度,是要用户自己来负责任务的让出的。如果一个人物不主动让出,其他任务就不会得到调度。这是协程的一个弱点,但是如果使用得当,这其实可以是一个很强大的有点。
4.进程是怎么调度和切换的。
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main(){
pid_t pid;
if(!(pid = fork())){
printf("I am child process\n");
_exit(0);
}else{
printf("I am father process\n");
wait(pid);
}
return 0;
}
在上面的代码中,fork是一个系统调用,用于创建进程,如果其返回值为0,则代表当前进程是子进程,如果其返回自不为0,则代表当前进程是父进程,而这个返回值就是子进程的进程id.
父进程在打印完以后,并没有立即退出,而是调用wait函数等待子进程退出。由于进程的调度执行是操作系统负责的,具有很大的随机性,所以父进程和子进程谁先退出我们不能确定。为了避免子进变成孤儿进程,我们采用让父进程等待子进程退出的办法,对两个进程进行同步。
为什么一次fork后,会有两种不同的返回值。这是因为fork方法本质上在系统里创建了2个栈,这两个栈一个是父进程的,一个是子进程的。创建的时候,子进程完全"继承"了父进程的所有数据,包括栈上的数据。父子进程栈的情况如图所示:
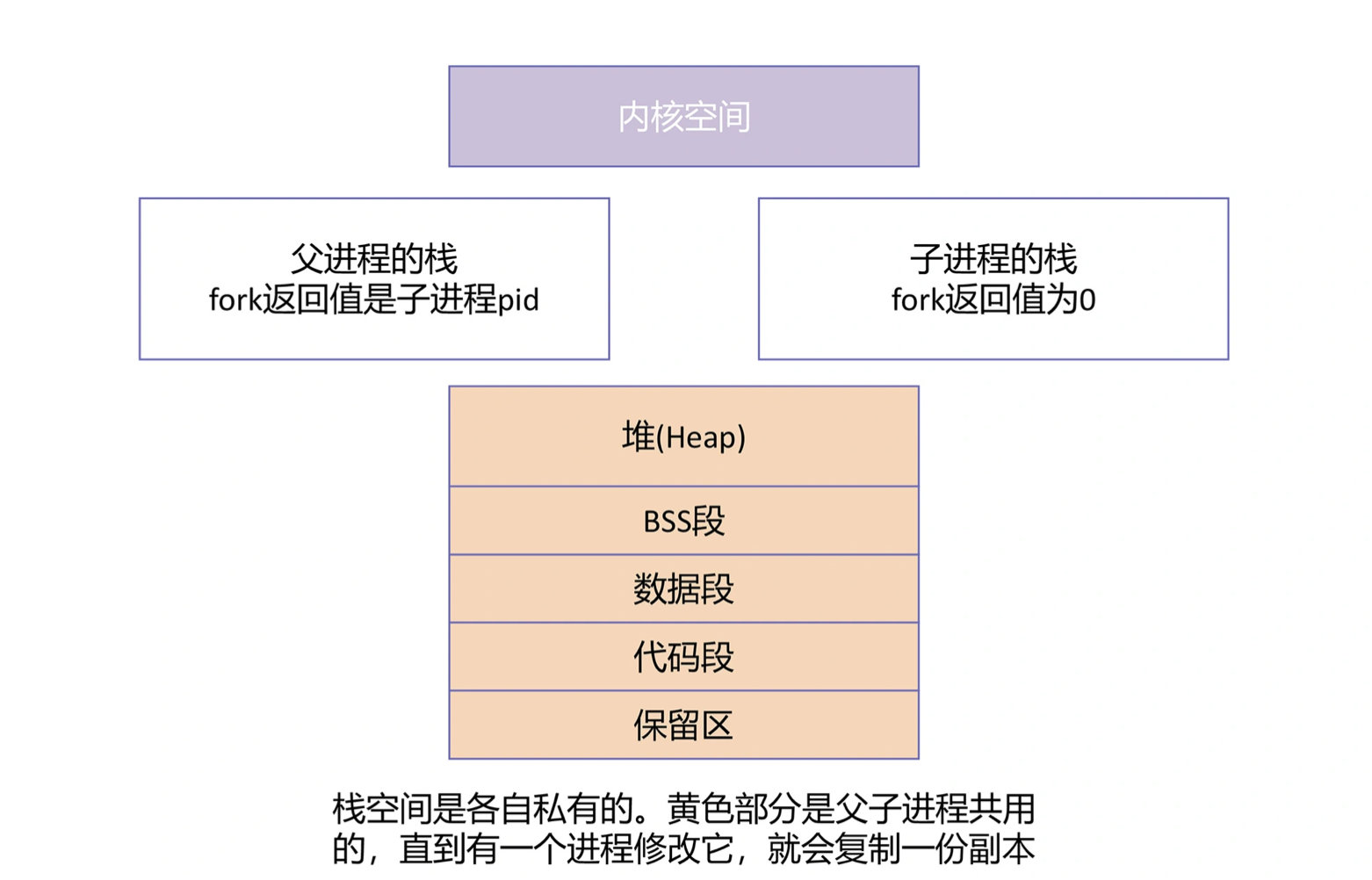
上图中,只要有一个进程对栈进行修改,栈就会复制一份,然后父子进程各自持有一份。
接着,操作系统就会接管2个进程的调度。当父进程得到调度时,父进程栈上是fork函数的帧,当CPU执行fork的ret语句时,返回值就是子进程的id.而当子进程得到调度时,rsp这个栈指针就会指向子进程的栈,子进程的栈上也同样是fork函数的frame,它执行返回值是0.
5.用户态和内核态是怎么切换的
操作系统内核在运行时,肯定也需要栈的,这个栈称为内核栈,它与应用程序使用的用户态栈是不同的,只有更高权限的内核代码才能访问它。而内核态与用户态的相互切换,其中最重要的就是两个栈的切换。
中断发生时,CPU需要根据跳转的特权级别,去一个特定的结构中,去的目标特权级对应的starck段选择子和栈顶指针,并分别送入ss寄存器和rsp寄存器,这就完成了一次栈的切换。然后,ip寄存器跳入终端服务程序开始执行,中断服务程序会把当前CPU中所有的寄存器,也就是程序的上下文都保存在栈上,这就意味着用户态的CPU状态其实是有中断服务程序在系统栈上进行维护的。
一般来说,当程序因为call指令或者int 指令进行跳转的时候,只需要把下一条指令的地址放在栈上,供被调用者执行ret指令使用,这样可以便与返回到调用函数中继续执行。
















 2886
2886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











