







b站刘二大人 传送门:06.逻辑斯蒂回归_哔哩哔哩_bilibili
pytorch提供了很多数据集,下面代码是个demo
注意自己电脑的路径!!
# PyTorch 甚至提供了很多数据包 # train 表示是用训练集还是测试集 import torchvision train_set = torchvision.datasets.MNIST(root='D:\set',train=True,download=True) test_set = torchvision.datasets.MNIST(root='D:\set',train=False,download=True) import torchvision train_set1 = torchvision.datasets.CIFAR10(root='D:\set',train=True,download=True) test_set1 = torchvision.datasets.CIFAR10(root='D:\set',train=False,download=True)
这一节的本质是:分类问题!!
而前面几节的本质是回归问题,我们采用简单的数据集
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[0],[0],[1]])
这里我们输入的是x,计算的是 y_hat=1的概率
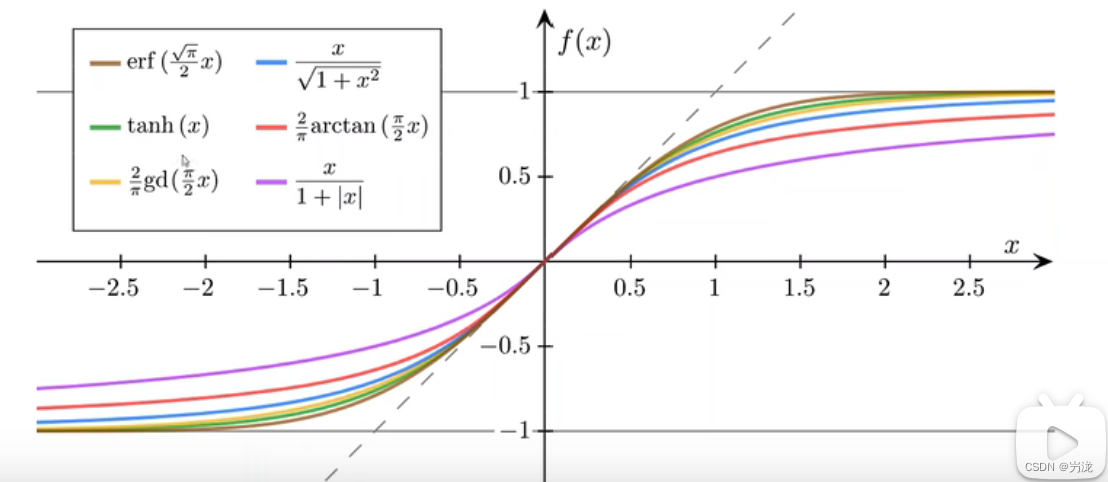
y_hat属于[0,1],于是我们找一个映射,从实数映射到[0,1]
我们可以使用多种饱和函数进行映射,用的最多的是logistic function
我们的loss函数也需要发生改变,先前是y_hat-y是一个数值
而现在y_hat和y的值表示的是,P=(class=1),是一个概率,所以y_hat和y的差值表示的是分布的差异
在概率论中会讲,下面给出一种评估概率分布差异的公式:BCE Loss 交叉熵
loss=-(ylog y_hat+(1-y)log (1-y_hat))
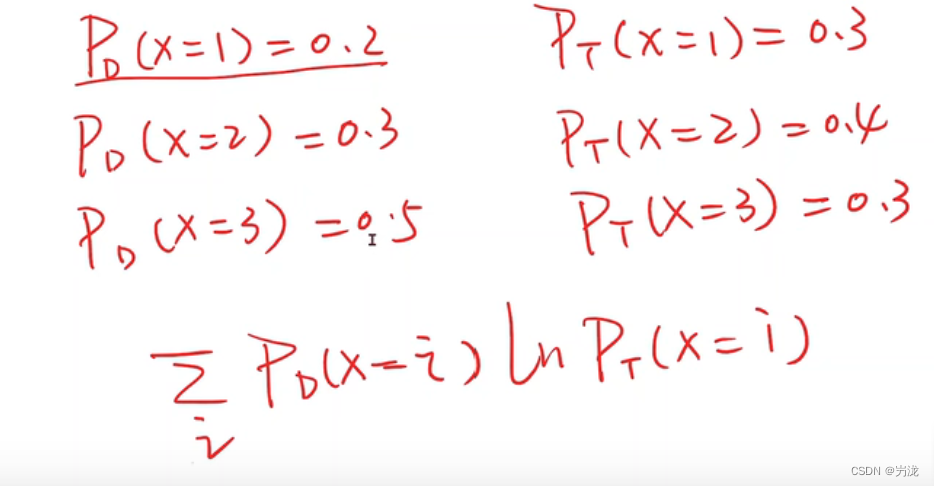

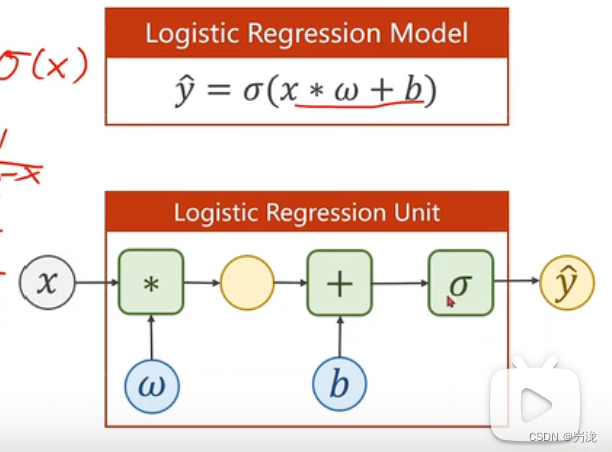
我们的计算图如下:
import torch # 1 x_data = torch.Tensor([[1.0],[2.0],[3.0]]) y_data = torch.Tensor([[0],[0],[1]]) # 改变了 # 2 class LogisticRegressionModel(torch.nn.Module): def __init__(self): super(LogisticRegressionModel,self).__init__() self.linear = torch.nn.Linear(1,1) self.sigmoid = torch.nn.Sigmoid() def forward(self,x): y_pred = self.sigmoid(self.linear(x)) # 多了一个sigmoid,计算图多了一步 return y_pred model = LogisticRegressionModel() # 3 criterion = torch.nn.BCELoss(reduction='sum') optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 损失函数也变了 # 4 for epoch in range(1000): y_pred = model(x_data) loss = criterion(y_pred, y_data) print(epoch,loss.item()) optimizer.zero_grad() loss.backward() optimizer.step()
可以画个图:
import numpy as np import matplotlib.pyplot as plt x=np.linspace(0,10,200) x_t=torch.Tensor(x).view((200,1)) y_t=model(x_t) y=y_t.data.numpy() plt.plot(x,y) plt.plot([0,10],[0.5,0.5],c='r') plt.xlabel('Hours') plt.ylabel('Probability of Pass') plt.grid() plt.show()
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









