目标 : 数据的分组聚合
目标 : 1 . 统计美国和中国的星巴克数量
2 . 统计中国每个省份星巴克数量
# 分组 data.groupby(by = “分组对象”)
# 根据某一列进行分组,分成一个个大元组,元组第一维是分组标签元素 , 第二维是数据
#------------------------------------------------------------------------------
import numpy as np
import pandas as pd
#------------------------------------------------------------------------------
def printf(t):
print(t)
print('-' * 80)
#------------------------------------------------------------------------------
path = "F:\All date\starbucks_store_worldwide.csv"
data = pd.read_csv(path)
# printf(data.head(0))
# printf(data.info())
#----------------1.统计美国和中国的星巴克数量-----------------------------------
# 比较中美星巴克数量(用索引去实现)
printf(len(data[data["Country"] == 'CN']))
printf(len(data[data["Country"] == 'US']))
#------------------------------------------------------------------------------
# 比较中美星巴克数量(用分组去实现)
to = data.groupby(by = "Country")
#------------------------------------------------------------------------------
# printf(type(to)) #看看分组后的类型是 DataFrameGroupBy 根据某一维分组的DataFrame
#------------------------------------------------------------------------------
#DataFrameGroupBy 可以进行 遍历
# printf(to)
# for i in to:
# printf(i)
#------------------------------------------------------------------------------
#DataFrameGroupBy 也可以进行 聚合
# ls = to.count()
ls = to["Brand"].count() #取出某一维数据不缺失的计数
# printf(type(ls))
printf(ls["CN"]) #ls的类型是 Serious
printf(ls["US"])
#----------------2.统计中国各个省份星巴克数量-----------------------------------
#先把 CN 的数据取出来
datacity = data[data["Country"] == "CN"]
# printf(datacity)
datacity = datacity.groupby(by = "State/Province")["Brand"].count()
printf(datacity)
#-----------------3.多条件分组的使用--------------------------------------------
# 用 country 和 State/Province 两个索引进行多条件分组
Ldata = data.groupby(by = ["Country" , "State/Province"])["Brand"].count()
#双标签的 Serious
# printf(type(Ldate))
printf(Ldata)
#Seroius -> DateFrame
# 在 DataFrame 中用选取多行的形式选取一行,使结果变成 DataFrame
Ldata = data.groupby(by = ["Country" , "State/Province"])[["Brand"]].count()
printf(Ldata)
数据的索引
各种索引操作
查看 index
赋值 index
set_index
#------------------------------------------------------------------------------
def printf(t):
print(t)
print('-' * 80)
#------------------------------------------------------------------------------
import numpy as np
import pandas as pd
data = pd.DataFrame(np.arange(12).reshape(3,4) , index = list("abc") , columns = ['A' , 'B' , 'C','D']);
printf(data)
#------------------------------------------------------------------------------
key1 = data.index
printf(key1)
#------------------------------------------------------------------------------
#指定index
data.index = list("xfs")
printf(data.index)
#------------------------------------------------------------------------------
# 这样写会报错 , 修改索引的时候不允许切片操作
# data.index[1] = "h"
# printf(data.index)
#------------------------------------------------------------------------------
#指定某一列为索引 set_index drop 指定列是否保留
data = data.set_index("C" , drop = False)
printf(data)
#------------------------------------------------------------------------------
#设置复合索引
data = data.set_index(['C' , 'D'] , drop = False)
printf(data)
数据的索引
各种索引操作
1.用不同的操作取出多索引Dataframe 的数据
2. swaplevel 交换多索引Dataframe 的索引
#------------------------------------------------------------------------------
def printf(t):
print(t)
print('-' * 80)
#------------------------------------------------------------------------------
import numpy as np
import pandas as pd
#------------------------------------------------------------------------------
d1 = pd.DataFrame({'a' : range(7) , 'b' : range(7,0,-1) , 'c' : ['one','one','one','two','two','two','two'],'d' : list("hjkimno") , 'e' : range(1,15,2)})
printf(d1)
d1 = d1.set_index(['c','d'])
printf(d1)
# Dataframe 和 Serious 索引的区别 : Serious 可以直接索引 , 但是 Dataframe 需要借助 loc 方法
# Dataframe 取出 11
a = d1.loc["two"].loc["n"]['e']
printf(a)
# Serious 取出 11
a = d1['e']['two']['n']
printf(a)
#------------------------------------------------------------------------------
d = d1.swaplevel('c','d')
printf(d)
#------------------------------------------------------------------------------
数据的分组聚合作图
目标 : 1 . 呈现店铺总数排名前十的国家
#------------------------------------------------------------------------------
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib as mtb
#------------------------------------------------------------------------------
def printf(t):
print(t)
print('-' * 80)
#------------------------------------------------------------------------------
mtb.rcParams['font.sans-serif'] = ["SimHei"]
mtb.rcParams["axes.unicode_minus"] = False
#------------------------------------------------------------------------------
path = "F:\All date\starbucks_store_worldwide.csv"
data = pd.read_csv(path)
# 这里的提取数据是关键
data = data.groupby(by = "Country")['Brand'].count().sort_values(ascending = False).head(10)
# printf(data)
# data 的类型是 Serious , 可以直接用 index 和 values 做直方图
_x = data.index
_y = data.values
plt.figure(figsize = (15,5) , dpi = 80)
plt.bar(_x , _y , width = 0.5, color = "#FF7F50" )
plt.xlabel("国家名称")
plt.ylabel("店铺总数(个)")
plt.title("店铺总数排名前十的国家")
plt.grid(alpha = 0.3 , color = "#000000")
plt.show()
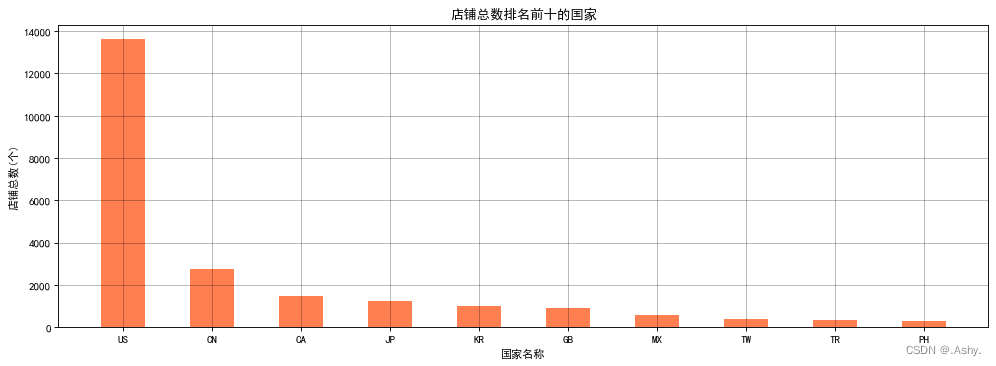
目标 : 2 . 呈现中国店铺数量排前三十的城市
#------------------------------------------------------------------------------
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib as mtb
#------------------------------------------------------------------------------
def printf(t):
print(t)
print('-' * 80)
#------------------------------------------------------------------------------
mtb.rcParams['font.sans-serif'] = ["SimHei"]
mtb.rcParams["axes.unicode_minus"] = False
#------------------------------------------------------------------------------
path = "F:\All date\starbucks_store_worldwide.csv"
data = pd.read_csv(path)
# 这里的提取数据是关键
data = data[data['Country'] == 'CN']
data = data.groupby(by = "City")['Brand'].count().sort_values(ascending = False).head(30)
# printf(data)
# data 的类型是 Serious , 可以直接用 index 和 values 做直方图
_x = data.index
_y = data.values
plt.figure(figsize = (15,5) , dpi = 80)
plt.bar(_x , _y , width = 0.5, color = "#FF7F50" )
plt.xticks(rotation = 45)
plt.xlabel("城市名称")
plt.ylabel("店铺总数(个)")
plt.title("中国店铺数量排前三十的城市")
plt.grid(alpha = 0.3 , color = "#000000")
plt.show()
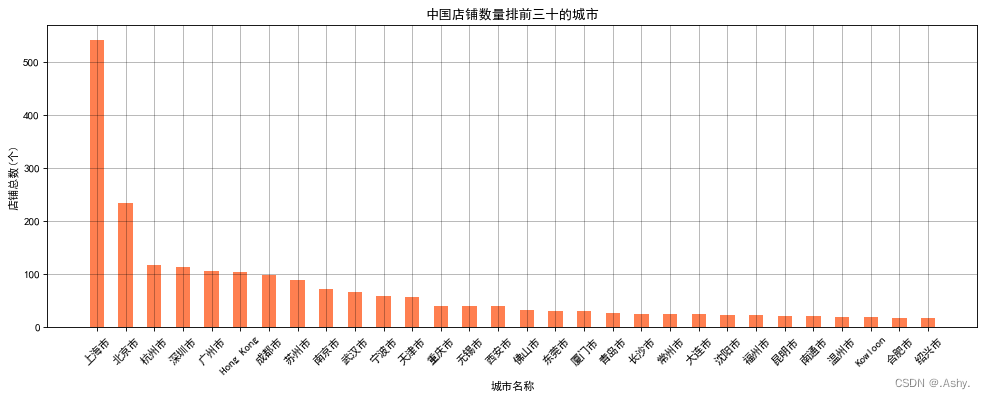
目标 : 1. 不同年份书的数量
#------------------------------------------------------------------------------
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib as mtb
#------------------------------------------------------------------------------
def printf(t):
print(t)
print('-' * 80)
#------------------------------------------------------------------------------
mtb.rcParams['font.sans-serif'] = ["SimHei"]
mtb.rcParams["axes.unicode_minus"] = False
#------------------------------------------------------------------------------
path = "F://All date//books.csv"
data = pd.read_csv(path)
# printf(data.info())
data = data[pd.notnull(data["original_publication_year"])]
data = data.groupby(by = "original_publication_year")["id"].count()
data = data[data > 100] #去除离群点
# printf(type(data))
_x = data.index
_y = data.values
plt.figure(figsize = (15,5) , dpi = 80)
plt.bar(_x , _y , width = 0.5, color = "#FF7F50" )
plt.xlabel("年份")
plt.ylabel("数量")
plt.title("不同年份书的数量")
plt.grid(alpha = 0.3 , color = "#000000")
plt.show()
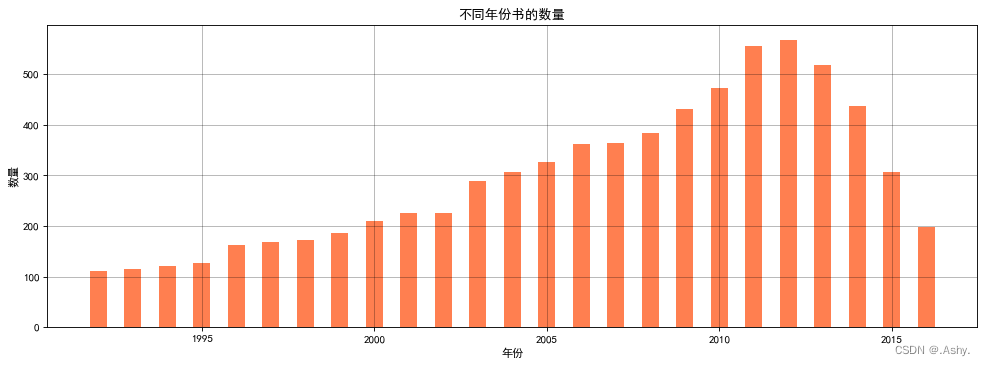
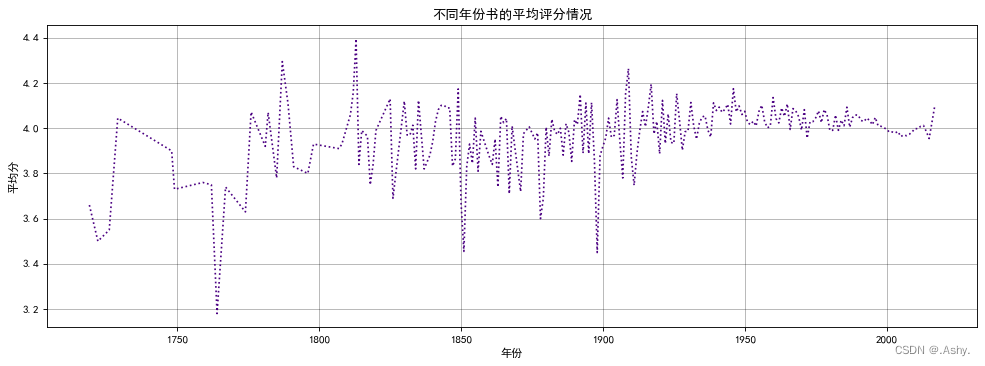
目标 : 2. 不同年份书的平均评分情况
#------------------------------------------------------------------------------
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib as mtb
#------------------------------------------------------------------------------
def printf(t):
print(t)
print('-' * 80)
#------------------------------------------------------------------------------
mtb.rcParams['font.sans-serif'] = ["SimHei"]
mtb.rcParams["axes.unicode_minus"] = False
#------------------------------------------------------------------------------
path = "F://All date//books.csv"
data = pd.read_csv(path)
# printf(data.info())
data = data[pd.notnull(data["original_publication_year"])]
data = data[data["original_publication_year"] > 1700]
data = data.groupby(by = "original_publication_year")["average_rating"].mean()
# printf(type(data))
_x = data.index
_y = data.values
plt.figure(figsize = (15,5) , dpi = 80)
plt.plot(_x , _y , label = "自己" , color = "#4B0082" , linestyle = ':')
plt.xlabel("年份")
plt.ylabel("平均分")
plt.title("不同年份书的平均评分情况")
plt.grid(alpha = 0.3 , color = "#000000")
plt.show()
























 4446
4446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











