






主要讲和TransE,TransH代码的区别,前两篇文章的链接
初始化向量
与前两种方法不同的是,relation和entity的向量长度(dimension)不是统一的。而引入了一个Mr的矩阵,将entity映射到relation的平面中

代码中的Wr表示的就是Mr矩阵
Wr_vec = new double[relation_num][entity_dimension][relation_dimension];
Wr_copy = new double[relation_num][entity_dimension][relation_dimension];
for (int i = 0; i < relation_num; i++) {
for (int j = 0; j < entity_dimension; j++) {
for (int k = 0; k < relation_dimension; k++) {
Wr_vec[i][j][k] = (j == k) ? 1 : 0;
Wr_copy[i][j][k] = (j == k) ? 1 : 0;
}
}
}
relation_vec = new double[relation_num][relation_dimension];
relation_copy = new double[relation_num][relation_dimension];
for (int i = 0; i < relation_num; i++) {
for (int j = 0; j < relation_dimension; j++) {
relation_vec[i][j] = uniform(-1, 1);
relation_copy[i][j] = relation_vec[i][j];
}
}
entity_vec = new double[entity_num][entity_dimension];
entity_copy = new double[entity_num][entity_dimension];
for (int i = 0; i < entity_num; i++) {
for (int j = 0; j < entity_dimension; j++) {
entity_vec[i][j] = uniform(-1, 1);
entity_copy[i][j] = entity_vec[i][j];
}
}计算分数

static double calc_sum(int head, int tail, int relation) {
double[] e1_vec = new double[relation_dimension];
double[] e2_vec = new double[relation_dimension];
for (int i = 0; i < entity_dimension; i++) {
e1_vec[i] = 0;
e2_vec[i] = 0;
for (int j = 0; j < relation_dimension; j++) {
e1_vec[i] += Wr_vec[relation][i][j] * entity_vec[head][i];
e2_vec[i] += Wr_vec[relation][i][j] * entity_vec[tail][i];
}
}
double sum = 0, tmp;
for (int i = 0; i < relation_dimension; i++) {
tmp = e2_vec[i] - e1_vec[i] - relation_vec[relation][i];
sum += sqr(tmp);
}
sum=sqrt(sum);
return sum;
}eturn sum;
}梯度下降
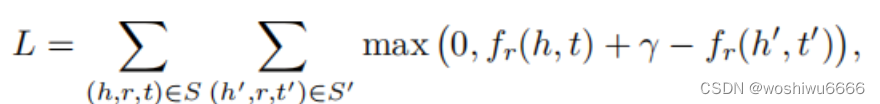
private static void gradient(int head, int tail, int relation, double beta) {
for (int i = 0; i < entity_dimension; i++) {
double Wrh = 0;
double Wrt = 0;
for (int j = 0; j < relation_dimension; j++) {
Wrh += Wr_vec[relation][i][j] * entity_vec[head][j];
Wrt += Wr_vec[relation][i][j] * entity_vec[tail][j];
}
double x = 2 * (Wrt - Wrh - relation_vec[relation][i]);
for (int j = 0; j < relation_dimension; j++) {
Wr_copy[relation][i][j] -= beta * learning_rate * (entity_vec[head][j] - entity_vec[tail][j]);
entity_copy[head][j] -= beta * learning_rate * Wr_vec[relation][i][j];
entity_copy[tail][j] += beta * learning_rate * Wr_vec[relation][i][j];
}
relation_copy[relation][i] -= beta * learning_rate * x;
}
}标准化

norm(relation_copy[fb_r.get(i)]);
norm(entity_copy[fb_h.get(i)]);
norm(entity_copy[fb_l.get(i)]);
norm(entity_copy[j]);
norm(entity_copy[fb_h.get(i)], Wr_vec[fb_r.get(i)]);
norm(entity_copy[fb_l.get(i)], Wr_vec[fb_r.get(i)]);
norm(entity_copy[j], Wr_vec[fb_r.get(i)]); static void norm(double[] a, double[][] Wr) {
while (true) {
double sum = 0;
for (int i = 0; i < entity_dimension; i++) {
double temp = 0;
for (int j = 0; j < relation_dimension; j++) {
temp += Wr[i][j] * a[j];
}
sum += sqr(temp);
}
if (sum > 1) {
for (int i = 0; i < entity_dimension; i++) {
double temp = 0;
for (int j = 0; j < relation_dimension; j++) {
temp += Wr[i][j] * a[j];
}
temp *= 2;
for (int j = 0; j < relation_dimension; j++) {
// double copy = Wr[j][i];
Wr[i][j] -= learning_rate * temp * a[j];
a[j] -= learning_rate * temp * Wr[i][j];
}
}
} else {
break;
}
}
}














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









