







自定义实现MR 的二次排序
在一个数据文件中,首先按照key排序。
在key相同的情况下,按照value大小排序的情况称为二次排序。
- 自定义key :NewKey实现比较规则
- 自定义GroupingComparator方法
比较过程
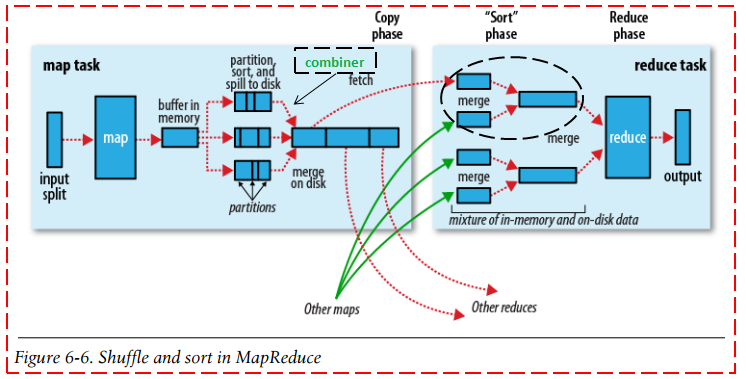
map阶段:
开始产生输出时,并不是直接写在磁盘上,而是写在缓冲区里(默认大小100M),当达到0.8时后台进程溢写到磁盘,(这些都可配置)。在缓冲区溢写到磁盘的过程中会进行排序和分组,溢写的磁盘文件也是很多的小文件组成,在这些小文件中都是排序和分组后的结果。在reduce端到map端读取文件之前,这些小文件还要进行合并成一个大文件,合并成大文件的过程也进行了排序和分组。reduce阶段:
读取多个map产生的结果文件到内存,按照相同的分区信息进行重组,按顺序对重组后的文件进行处理。结束后输出到磁盘文件。
combiner过程应该在map阶段产生大文件后进行
partitioner过程应该由MRAppMaster主导,map进行完后向MRAppMaster进行汇报,MRAppMaster通知各个
reducer到map产生的结果文件的具体位置读取数据
详细代码
NewKey
package com.wowSpark.secondarySort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class NewKey implements WritableComparable<NewKey> {
private int first;
private int second;
public int getFirst() {
return first;
}
public int getSecond() {
return second;
}
public void set(int first, int second) {
this.first = first;
this.second = second;
}
@Override
public void readFields(DataInput in) throws IOException {
first = in.readInt();
second = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(first);
out.writeInt(second);
}
//对key排序时,调用这个compareTo方法
@Override
public int compareTo(NewKey o) {
if (first != o.first) {
return first - o.first;
} else if (second != o.second) {
return second - o.second;
} else {
return 0;
}
}
//新定义的类应该重写下面两个方法
@Override
public int hashCode() {
return first+"".hashCode() + second+"".hashCode();
}
@Override
public boolean equals(Object first) {
if (first instanceof NewKey){
NewKey r = (NewKey) first;
return r.first == this.first && r.second == this.second;
}else{
return false;
}
}
}
GroupingComparator
package com.wowSpark.secondarySort;
import com.wowSpark.secondarySort.NewKey;
import org.apache.hadoop.io.RawComparator;
import org.apache.hadoop.io.WritableComparator;
public class GroupingComparator implements RawComparator<NewKey>{
@Override
public int compare(NewKey o1, NewKey o2) {
int l = o1.getFirst();
int r = o2.getFirst();
return l == r ? 0 : (l < r ? 1 : 1);
}
//一个字节一个字节的比,直到找到一个不相同的字节时比较这个字节的大小作为两个字节流的大小比较结果。
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return WritableComparator.compareBytes(b1, s1, Integer.SIZE/8, b2, s2, Integer.SIZE/8);
}
/**
*
//第二种方法,继承WritableComparator
public static class GroupingComparator extends WritableComparator
{
protected GroupingComparator()
{
super(NewKey.class, true);
}
@Override
//Compare two WritableComparables.
public int compare(WritableComparable w1, WritableComparable w2)
{
NewKey nk1 = (NewKey) w1;
NewKey nk2 = (NewKey) w2;
int l = nk1.getFirst();
int r = nk2.getFirst();
return l == r ? 0 : (l < r ? -1 : 1);
}
}
*/
}
自定义Mapper类
package com.wowSpark.secondarySort;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<LongWritable, Text, NewKey, IntWritable>{
private NewKey key = new NewKey();
private IntWritable value = new IntWritable();
@Override
protected void map(LongWritable inKey, Text inValue, Context context)
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(inValue.toString());
int first = 0;
int second = 0;
if(tokenizer.hasMoreTokens()){
first = Integer.parseInt(tokenizer.nextToken());
if(tokenizer.hasMoreTokens()) second = Integer.parseInt(tokenizer.nextToken());
key.set(first, second);
value.set(second);;
context.write(key, value);
}
}
}自定义Reducer类
package com.wowSpark.secondarySort;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<NewKey, IntWritable, Text, IntWritable>{
private final Text first = new Text();
private final Text SEPARATOR = new Text("^^^^^^^^^^^");
@Override
protected void reduce(NewKey newkey, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
context.write(SEPARATOR, null);
first.set(Integer.toString(newkey.getFirst()));
for(IntWritable val: values){
context.write(first, val);
}
}
}main方法
package com.wowSpark.secondarySort;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Driver {
public static void main(String[] args) throws Exception {
//获取JOB对象
//Configuration conf = new Configuration();
Job job = Job.getInstance();
job.setJarByClass(Driver.class);
FileSystem.newInstance(new URI("hdfs://h1:9000"), new Configuration()).delete(new Path("hdfs://h1:9000/mr/out"), true);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(NewKey.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setGroupingComparatorClass(GroupingComparator.class);
FileInputFormat.setInputPaths(job, "hdfs://h1:9000/mr/data.dat");
FileOutputFormat.setOutputPath(job, new Path("hdfs://h1:9000/mr/out"));
System.out.println(job.waitForCompletion(true)? 0 : 1);
}
}
参考:
【1】 http://blog.csdn.net/wowSpark/article/details/49616083 < Exception>
【2】 http://download.csdn.net/detail/wowspark/9236975 <源码下载>















 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









