







在我的一篇博客中
http://blog.csdn.net/wowotuo/article/details/46841395 提到如何处理带中文字符的CSV文件.
这期,我将继续探讨一下这个问题。
在Julia中,readcsv(或更底层的readdlm)是处理CSV文件的基础性的函数。
下面,我们分几种情况带中文字符的CSV来探讨应如何处理这些情况。
一、仅首行有中文字符的: skipstart =1
比如,我们有一个这样的CSV文件:
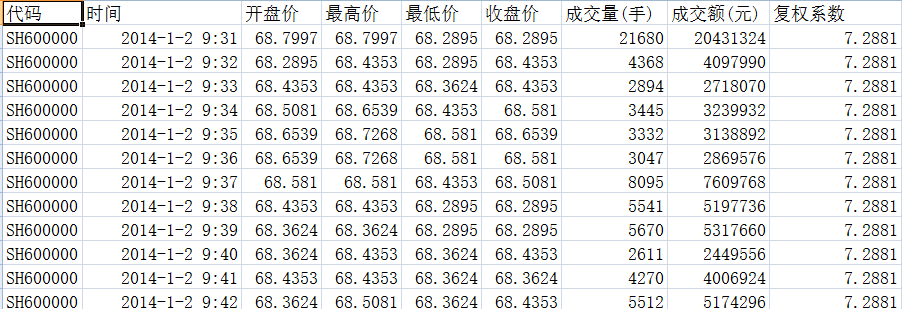
很显然,第一行有不少的中文字符。
那么,我们用readcsv是否可以处理这样的文件?
思路是,正常情况下,如果
dd =readcsv(path) # 报错 invalid Substring index 函数将会报错,无法认别其中的乱码。因此,我们调整一下,我们把无法识别的字符将其跳过,避免函数强制报错。这样,我们还是可以读出中间的内容的。
需要注意的是,在这种情况下,CSV的行数较原来文件少一行。
path ="C:\\Users\\Administrator\\Desktop\\SH600000.csv";
@time dd =readcsv(path,skipstart=1)二、列和行中都有中文字符的
比如,有一个10行10列的CSV文件:
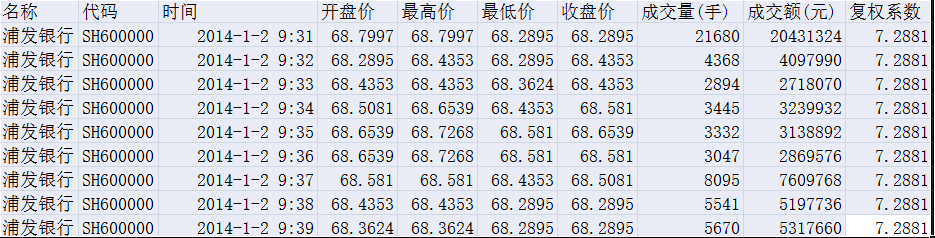
可以根据其中的行和列情况,
path ="C:\\Users\\Administrator\\Desktop\\SH600000_1.csv";
@time dd =readcsv(path,ignore_invalid_chars=true,skipstart=1)
row,col =size(dd); # row =9,col =10 将减少一行!这样,其中的第一行和第一列报错的问题将会被忽略掉,但是,第一列的内容仍然在,只是无法读出。
println(dd[1,1]) # 将报错,“UnicodeError: invalid character index”
aa =dd[1,1] # 只要涉及到dd[1,1]的,就会报错。三、只有列中有中文字符CSV,
如,一个9 行10列的CSV文件:
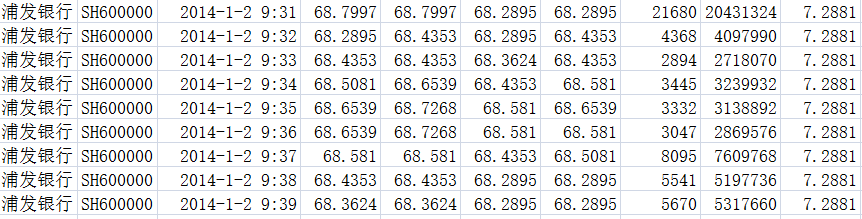
此时,就不能用skipstart了,因为表头没有。所以
path ="C:\\Users\\Administrator\\Desktop\\SH600000_2.csv";
@time dd =readcsv(path,ignore_invalid_chars=true)
row,col =size(dd); # row =9,col =10
总结一下:关键性的参数选择是把skipstart =1 和ignore_invalid_chars=true。















 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









