







图的存储结构
顶点位置与邻接点位置只是一个相对概念。
任何一个顶点都可以看成是第一个顶点,任一顶点的邻接点之间也不存在次序关系。

上图为同一个图,顶点位置不同,造成表象不一样。
任意两个顶点之间都可能存在联系,所以无法以数据元素在内存中的物理位置来表示元素之间的关系。也就是说,不能用简单的顺序存储结构来表示。
如果采用多重链表的方式,以一个数据域和多个指针组成的结点表示图中的一个顶点,可以实现,但存在问题。
各个顶点的度数相差很大,按度数最大的顶点设计结点结构会造成很多存储单元的浪费;而按照每个顶点自己的度数设计不同的顶点结构,又带来操作的不便。
五种不同的存储结构
邻接矩阵
图是由顶点和边或弧两部分组成。自然地考虑分两个结构分别存储。
- 顶点不分大小、主次,用一维数组来存储
- 边或弧由于是顶点与顶点之间的关系,一维搞不定,所以用二维数组存储
以上就是邻接矩阵的方案。
图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
无向图邻接矩阵
设图G有n个顶点,则邻接矩阵是一个n*n的方阵,定义为:

无向图邻接矩阵实例如下:

arc[1][3] = 0 是因为v1到v3的边不存在。因为是无向图,所以v3到v1的边也不存在。
所以无向图的边数组是一个对称矩阵。
对称矩阵:n阶矩阵的元满足aij = aji,(0<= i,j <= n)。即从矩阵的左上角到右下角的主对角线为轴,右上角的元与左下角相对应的元全都是相等的。
根据矩阵,可以很容易知道图中的信息。
- 非常容易判断任意两顶点是否有边无边
- 某个顶点的度,就是顶点vi在邻接矩阵中第i行(或第i列)的元素之和。比如v1的度就是1 + 0 + 1 + 0 = 2
- 求顶点vi的所有邻接点,就是将矩阵中第i行元素扫描一遍,arc[i][j]为1就是邻接点。
有向图邻接矩阵
有向图邻接矩阵实例如下:
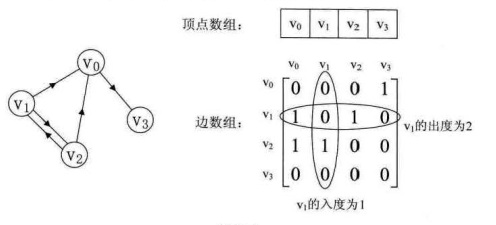
有向图讲究入度和出度。顶点v1的入度为1,正好是第v1列各数之和。顶点v2的出度为2,即第v1行的各数之和。
判断vi到vj是否存在弧,只需要查找矩阵中arc[i][j]是否为1即可。
要求vi的所有邻接点就是将矩阵第i行元素扫描一遍,查找arc[i][j]为1的顶点。
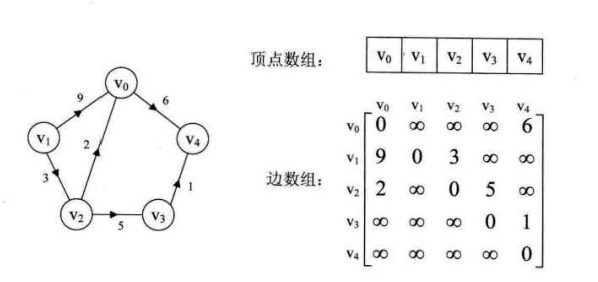
网的邻接矩阵
回顾:带权的图叫做网。
网的邻接矩阵需要存下权。
设G为网,有n个顶点,则邻接矩阵是一个n*n的方阵,定义为:

- Wij表示(vi,vj)或<vi,vj>上的权值。
- ∞是计算机允许的,大于所有边上权值的值,也是一个不可能的极限值
有向网邻接矩阵
无向图邻接矩阵创建实现
public class GraphTest {
String[] scanfVertex = {"A","B","C","D","E","F","G"};
//输入权值,默认使用0
int scanfValue = 0;
//i,j为输入边的下标
int i,j = 0;
void createMGraph(Graph graph){
graph.numVertexes = 7;
graph.numEdges = 9;
//输入顶点
for(int i = 0;i<scanfVertex.length;i++){
graph.verxs[i] = scanfVertex[i];
}
//用顶点初始化邻接矩阵 默认复制无穷大
for(int i = 0;i<graph.verxs.length;i++){
for(int j = 0;j<graph.verxs.length;j++){
//初始化无穷
graph.arc[i][j] = graph.INFINITY;
}
}
//读入numEdges条边,建立邻接矩阵
for(int k = 0;k<graph.numEdges;k++){
graph.arc[i][j] = scanfValue;
//无向图矩阵对称
graph.arc[i][j] = graph.arc[j][i];
}
}
}
//无向图数据结构
class Graph{
String vertexType;//顶点类型
int edge;//边上权值
static final int MAXVEX = 10;//最大顶点数
static final int INFINITY = 65535;//65535代表无穷
String[] verxs = new String[MAXVEX];//顶点表
int[][] arc = new int[MAXVEX][MAXVEX];//邻接矩阵,可看做边表
int numVertexes,numEdges;//图中当前的顶点数和边数
}
总结:邻接矩阵a[i][j],i是矩阵纵向下标,j是矩阵横向下标。
邻接表
邻接矩阵缺点:对于边数相对顶点较少的图,这种结构是存在对存储空间的极大浪费。
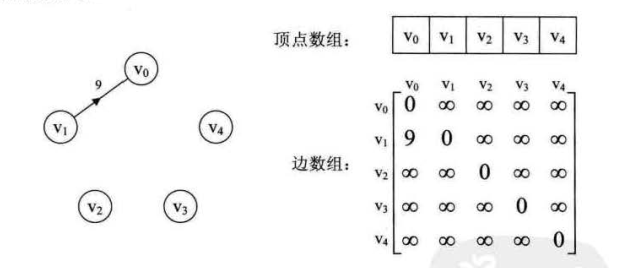
上图邻接矩阵中除了arc[1][0]有权值外,没有其他弧,其他的存储空间都浪费掉了。
回顾:线性表中,顺序存储结构存在预先分配内存可能造成存储空间浪费的问题,于是引出了链式存储的结构。
同样可以考虑对边或弧使用链式存储的方式来避免空间浪费的问题。
同样适用于图的存储。我们把数组与链表相结合的存储方法称为邻接表(Adjacency List)。
邻接表原理:
- 顶点用一维数组存储。顶点也可以用单链表存储,不过数组更容易读取顶点信息,更加方便。在顶点数组中,每个数据元素还需要存储指向第一个邻接点的指针,便于查找该顶点的边信息。
- 图中每个顶点v1的所有邻接点构成一个线性表,邻接点的个数不定,所以用单链表存储;无向图称为顶点v1的边表,有向图则称为顶点v1作为弧尾的出边表。
无向图邻接表
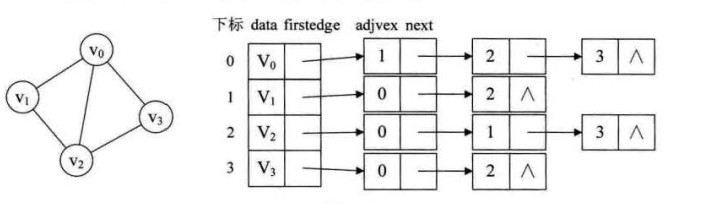
如上就是一个无向图的邻接表结构
边表结点由adjvex和next两个域组成。
- adjvex邻接点域,存储某顶点的邻接点在顶点表中的下标
- next存储指向边表中下一个结点的指针
比如v1顶点与v0、v2互为邻接点,则在v1的边表中,adjvex分别为v0的0和v2的2。
- 某个顶点的度,查找这个顶点边表中结点的个数
- 判断顶点vi到vj是否存在边,只需要测试顶点vi的边表中adjvex是否存在vj的下标j就可以了
- 求顶点的所有邻接点,对顶点边表进行遍历
有向图邻接表

以上为有向图邻接表
可以算出某顶点的入度和出度,判断两顶点是否存在弧也很容易实现。
带权的网图,在边表结点定义中增加一个weight的数据域,存储权信息即可。

/**
* 邻接表实现
* @author jiaxinxiao
*
*/
public class GraphAdjList {
static final int MAX = 10;
static final int INIT_VALUE = 5;
static final String INIT_STRING_VALUE = "string";
VertexNode[] vertexNodes = new VertexNode[MAX];
int numVertexes,numEdges;//顶点数和边数
void createAlgraph(GraphAdjList graphAdjList){
//初始化
graphAdjList.numVertexes = INIT_VALUE;
graphAdjList.numEdges = INIT_VALUE;
//读入顶点信息,建立顶点表
for(int i=0;i<numVertexes;i++){
vertexNodes[i].data = INIT_STRING_VALUE;//输入顶点信息
vertexNodes[i].firstEdge = null;//边表置为空表
}
//回顾:此处用到了单链表创建中讲解到的头插法
for(int k=0;k<numEdges;k++){
//输入边上顶点序号
int i = INIT_VALUE;
int j = INIT_VALUE;
EdgeNode eNode = new EdgeNode();
eNode.adjvex = j;//邻接序号为j
eNode.next = vertexNodes[i].firstEdge;
vertexNodes[i].firstEdge = eNode;
eNode = new EdgeNode();
eNode.adjvex = i;//邻接序号为j
eNode.next = vertexNodes[j].firstEdge;
vertexNodes[j].firstEdge = eNode;
}
}
}
//边表结点
class EdgeNode{
int adjvex;//邻接域
int weight;//权值,非网图不需要
EdgeNode next;//链域,指向下一个邻接点
}
//顶点表结构
class VertexNode{
String data;//顶点域,存储顶点信息,数据暂时使用String类型
EdgeNode firstEdge;//边表头指针
}
重点:单链表头插法。
十字链表
时差 安保问题告诉我们,充分利用现有资源,正向思维、逆向思维、整合思维可以创造更大价值。
邻接表缺陷:关心了出度问题,了解入度必须遍历整个图。反之,逆邻接表解决了入度确不了解出度的情况。
有没有能把邻接表和逆邻接表结合起来呢?
有:有向图的一种存储方法:十字链表(Orthogonal List)。
顶点结构:

- firstin:入边表头指针,指向该顶点的入边表中第一个结点
- firstout:出边表头指针,指向该顶点的出边表中的第一个结点
边表结构:

- tailvex:弧起点在顶点表的下标
- headvex:弧终点在顶点表的下标
- headlink:指入边表指针域,指向终点相同的下一条边
- taillink:出边表指针域,指向起点相同的下一条边
十字链表结构:

上图中taillink应该为headlink
十字链表优点:
- 将邻接表与逆邻接表整合到一起,既容易找到以vi为尾的弧,也容易找到以vi为头的弧,因而容易求得顶点的出度和入度。
- 除了结构复杂以外,创建的时间复杂度和邻接表相同
在有向图应用中,十字链表是非常好的数据结构
邻接多重表
无向邻接表存在的弊端:边的操作麻烦,比如对边做标记,删除某一条边等。那就意味着,需要找到这条边的两个边表结点进行操作,比较麻烦

上图若要删除(v0,v2)这条边,需要对邻接表结构中红框标识的两个结点删掉,比较麻烦
边表结点结构:

ivex和jvex是与某条边依附的两个顶点在顶点表中下标。ilink指向依附顶点ivex的下一条边,jlink指向依附顶点jvex的下一条边。这就是邻接多重表结构。

ilink指向的结点的jvex一定要和它本身的ivex的值相同
邻接多重表与邻接表的差别,仅仅是在于同一条边在邻接表中用两个jie
边集数组
边集数组是由两个一维数组构成。一个是存储顶点的信息;另一个是存储边的信息,这个边数组每个数据元素由一条边的起点下标(begin)、终点下标(end)和权(weight)组成。
边集数组关注的是边的集合,但是查找一个顶点的度需要扫描整个边数组,效率比较低。
















 2564
2564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









