








团队:百度(王井东大佬),复旦,瑞士ETH,南大
概要
肖像图像动画领域,由语音音频输入,在生成逼真和动态肖像合成方面取得了重大进展。本研究在基于扩散模型的方法框架内深入研究了同步人脸运动的复杂性,和创造视觉上吸引人的时间上一致性的动画。作者的创新方法摆脱了传统的范式,即依赖参数化的模型用于中间层的面部表示,作者采用了端到端的扩散模型范式并且介绍了一个分层的语音驱动的视觉合成,以提升音频输入和视觉输出之间的对齐精度,包括嘴唇、面部表情和姿态运动。作者提出的网络框架无缝集成了基于扩散的生成模型、基于UNet的去噪器、时间对齐和参考网络。这个提出的分层语音驱动的视觉合成提供了对面部表情和姿态多样性的自适应控制,能够更有效地针对不同身份进行个性化定制。通过结合定性和定量分析的综合评估,我们的方法在图像和视频质量,唇同步精度和运动多样性方面表现出明显的增强。进一步的可视化和源代码访问可以在https://fudan-generative-vision.github.io/hallo上找到。
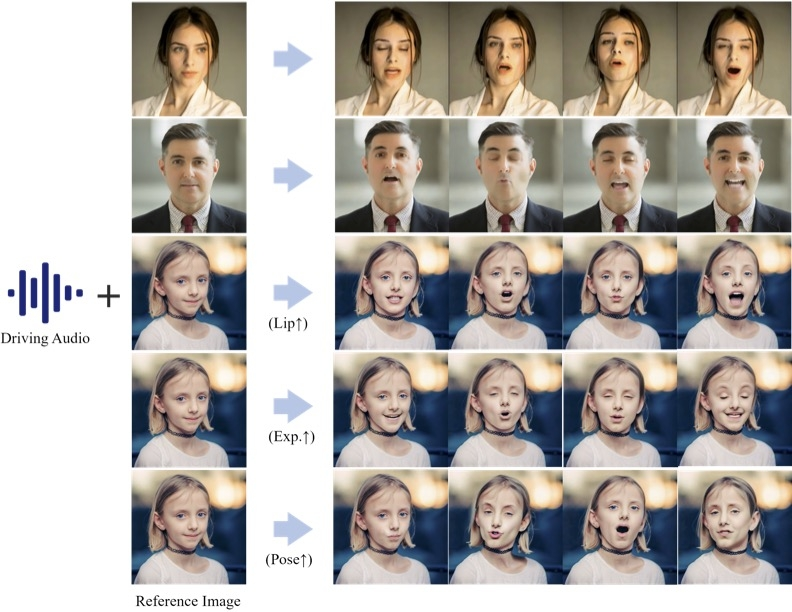
图1:所提出的方法旨在生成时间一致且视觉上高保真的肖像图像动画。这是通过利用参考图像、音频序列和可选的视觉合成权重以及基于分层音频驱动视觉合成方法的扩散模型来实现的。与之前依赖于中间面部表征的方法相比,该方法的结果显示出更高的保真度和视觉质量。此外,该方法提高了唇同步测量的精度,增强了对运动多样性的控制。
介绍
人像动画,又称说话头像动画,旨在从单个静态图像和相应的语音音频中生成一个说话的人像。这项技术在视频游戏和虚拟现实、电影和电视制作、社交媒体和数字营销、在线教育和培训以及人机交互和虚拟助理等各个领域都具有巨大的价值。Stable Diffusion[31]和DiT[27]等作品体现了该领域的重大进展,它们涉及将噪声逐渐纳入潜在空间的训练数据中,然后通过反向过程逐步从该噪声中重建信号。通过利用唇动作[28,52]、面部表情[13,24,34]和头部姿势[24,37,38]的参数化或隐式表示,结合潜在空间中的扩散技术[6,22,39,46,47],是有可能以端到端的方式生成高质量、逼真的动态肖像。
本研究主要针对人像动画的两个主要挑战:(1)音频输入驱动下的唇动、面部表情和头部姿态的同步与协调。(2)创造高保真动画,具有视觉吸引力并保持时间一致性。

图9:现有方法与我们提出的方法之间头部和表情运动多样性的定性比较。
为了解决第一个挑战,基于参数化模型的方法[6,24,28,34,38,46,52]最初依赖于输入音频来获得面部标志序列或参数化运动系数,如3DMM [1], FLAME[19]和HeadNeRF[16],作为中间表示,随后用于视觉生成。然而,这些方法的有效性受到中间表示的准确性和表达性的限制。相比之下,另一种方法涉及潜在空间中的解耦表示学习[13,22,47],该方法将面部特征分离为潜在空间中的身份和非身份组件。这些组件是独立学习和跨框架集成的。这种方法的主要障碍是有效地分离各种肖像因素,同时全面地涵盖静态和动态面部属性。此外,在上述方法的潜在空间中引入中介表示或解耦表示破坏了具有高真实感和多样性的时间一致性视觉输出的产生。
为了生成视觉上吸引人且时间上一致的高质量动画,端到端扩散模型的使用[39]利用了扩散模型的最新进展,直接从图像和音频剪辑合成人像视频。这种方法消除了中间表示或复杂预处理步骤的需要,从而能够产生高分辨率、详细和多样化的视觉输出。然而,实现音频和生成的面部视觉合成(包括嘴唇运动、表情和姿势)之间的精确对齐仍然是一个挑战。在本研究中,我们坚持端到端扩散模型的框架,目的是解决对齐问题,同时结合控制表情和姿势多样性的能力。为了应对这一挑战,我们引入了一个分层音频驱动的视觉合成模块,该模块采用交叉注意机制来建立与嘴唇、表情和姿势相关的音频和视觉特征之间的对应关系。然后,使用自适应加权对这些交叉关注进行融合。在这种分层音频驱动的视觉合成模块的基础上,我们提出了一种网络架构,该架构集成了基于扩散的生成模型、基于unet的去噪器[32]、序列一致性的时间对齐[11]和指导视觉生成的ReferenceNet。如图1所示,这种集成方法增强了嘴唇和表情运动与音频信号的有效同步,并提供了对表情和姿势粒度的自适应控制,从而确保了各种视觉身份的一致性和真实感。
在实验部分,我们从定性和定量的角度对我们提出的方法进行了全面的评估,包括对图像和视频质量、嘴唇同步和运动多样性的评估。具体来说,与之前的方法相比,我们的方法在图像和视频质量上有了显著的提高,这是由FID和FVD指标量化的。此外,与先前的基于扩散的技术相比,我们的方法在唇同步方面显示出有希望的进步。此外,我们的方法还提供了根据具体要求调整表情和姿势多样性的灵活性。值得注意的是,我们致力于向开源社区传播我们的源代码和样本数据,目的是促进相关领域的进一步研究。
相关工作
基于扩散的视频生成。 利用文本到图像扩散模型的基本原理,基于扩散的视频生成的最新进展显示了有希望的结果[2,7,12,15,18,23,48,56]。值得注意的成果包括视频扩散模型(Video Diffusion Models, VDM)[15],它利用时空分解U-Net来同时进行图像和视频数据训练,以及ImagenVideo[14],它通过级联扩散模型来增强VDM,用于高清输出。
Make-A-Video[36]和MagicVideo[54]扩展了这些概念,以促进文本到视频的无缝转换。对于视频编辑,像VideoP2P[21]和vid2video -zero[44]这样的技术可以操纵交叉注意图来优化输出,而Dreamix[25]则采用图像-视频混合微调。
此外,Gen-1[9]通过深度图和交叉注意集成了结构引导,而MCDiff[5]和LaMD[17]则侧重于运动引导视频生成,增强了人类动作的真实感。VideoComposer[45]、AnimateDiff[4]和VideoCrafter[4]进一步探索了通过调节图像的扩散过程和混合图像潜在因素来合成图像到视频的生成。鉴于扩散模型在实现高保真度和时间一致的视觉生成结果方面的显着功效,本研究采用端到端扩散模型。
面部表征学习。 在潜在空间中学习面部表征,特别是从与身份相关的外观和非身份相关的动作(如嘴唇运动、表情和姿势)中解脱出来,是计算机视觉领域的一个重大挑战。

图8:给出不同音频风格的视频生成结果。
与此挑战相关的表征学习通常分为两类:显式和隐式方法。显式方法通常使用面部地标,即面部关键点[35,50],用于嘴巴、眼睛、眉毛、鼻子和下颌线等关键区域的定位和表示。此外,涉及3D参数化模型[10,30,51]的工作,如3D变形模型(3DMM),通过统计形状模型与纹理模型相结合来捕捉人脸的可变性。然而,这些显式方法受其表达能力和重建精度的限制。相反,隐式方法旨在学习2D[3,20,26,41,49,55]或3D[8,43]潜在空间中的解纠缠表征,重点关注外观身份、面部动态和头部姿势等方面。虽然这些方法在面部表达方面取得了令人鼓舞的成果,但它们面临着与显式方法类似的挑战,特别是准确有效地解开各种面部因素仍然是一个相当大的挑战。
肖像图像动画。 近年来,肖像图像动画领域取得了实质性进展,特别是在从静态图像与音频输入配对生成逼真且富有表现力的说话头部动画方面。这一进步始于LipSyncExpert[28],它改进了对语音片段的唇同步,实现了对特定身份的静态图像和视频的高精度。随后出现了SadTalker[52]和DiffTalk[34]等开发,它们集成了3D信息和控制机制,以增强头部运动和表情的自然性。扩散模型(diffusion models)的引入带来了重大转变,特别是Diffused Heads[37]和GAIA[13],它们促进了高保真的谈话头部视频的创建,这些视频具有自然的头部运动和面部表情,而不依赖于额外的参考视频。
这些模型展示了跨各种身份进行个性化和一般化综合的强大能力。在这一演变的基础上,DreamTalk[24]和VividTalk[38]利用扩散模型制作了富有表现力的高质量音频驱动面部动画,强调了改进的唇部同步和多样化的说话风格。Vlogger[6]和AniPortrait[46]取得了进一步的进步,它们分别引入了空间和时间控制,以适应可变的视频长度和可自定义的字符表示。最近的创新,如VASA-1[47]和EMO[39]已经开发了框架,用于从静态图像和音频中创建情感表达和逼真的说话面孔,捕获广泛的面部细微差别和头部运动。最后,AniTalker[22]引入了一个突破性的框架,专注于通过通用运动表示生成详细和逼真的面部运动,最大限度地减少对标记数据的需求,并强调了在实际应用中动态头像创建的潜力。
在本研究中,我们采用了EMO中支持的潜在扩散公式[39],并引入了分层交叉注意机制来增强音频输入与非身份相关动作(如嘴唇运动、表情和姿势)之间的相关性。这样的表述不仅可以对表情和姿态的多样性进行自适应控制,还可以增强所生成动画的整体连贯性和自然性。
整体架构流程
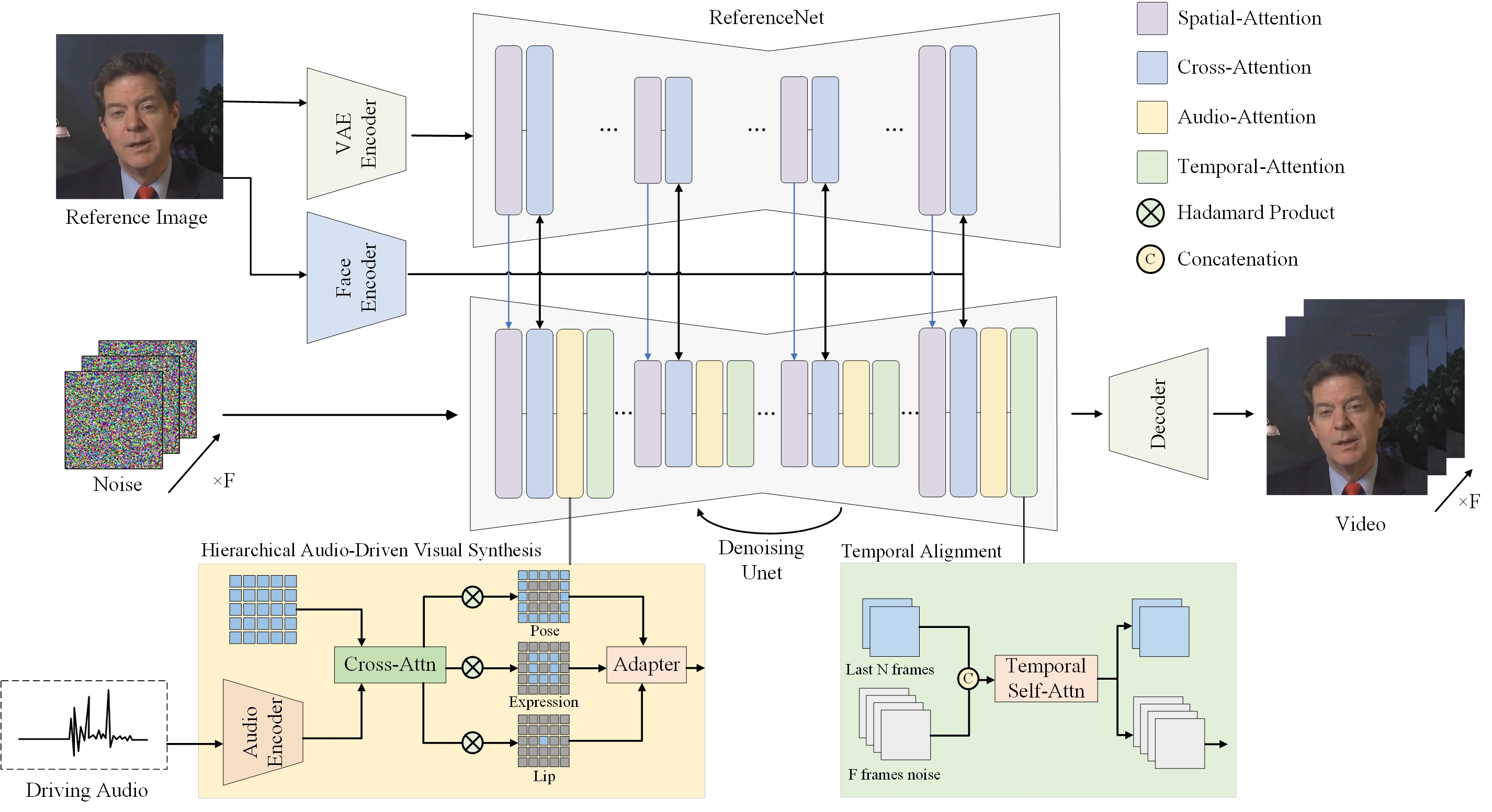
图2 管道概述。具体来说,我们将包含肖像的参考图像与相应的音频输入集成在一起,以驱动肖像动画。可选的视觉合成权重可用于平衡嘴唇,表情和姿势权重。ReferenceNet编码全局视觉纹理信息,以实现一致和可控的角色动画。人脸和音频编码器分别生成高保真人像身份特征,并将音频编码为运动信息。分层音频驱动的视觉合成模块建立了音频和视觉组件(嘴唇、表情、姿势)之间的关系,在扩散过程中使用了UNet去噪器。
技术名词解释
潜在扩散模型。 潜在扩散模型代表了一类在自编码器产生的编码潜在空间内运行的扩散模型,形式化为D(E(·))。潜在扩散模型的一个突出例子是Stable diffusion,它集成了VQ-VAE自编码器[40]和用于噪声估计的时条件U-Net。此外,Stable Diffusion[32]采用CLIP ViT-L/14文本编码器[29]将输入的文本提示转换为相应的文本嵌入,作为扩散过程的条件。在训练阶段,给定一个图像I∈R HI×WI×3及其关联的文本条件cembed∈R Dc,潜表示:
z0 = E(I)∈R Hz×Wz×Dz(1)
经历了一个跨越T个时间步长的扩散过程。该过程被建模为确定性高斯过程,最终以zT ~ N(0,i)结束。稳定扩散的训练目标被以下损失函数封装:L = EE(I),cembed, λ ~ N(0,1),t∥λ−ϵθ(zT,t,cembed)∥2 2 , (2),t均匀地从{1,…T}。这里,ϵθ表示模型的可训练组件,其中包括一个带有残差块和层的去噪U-Net,这些残差块和层可以促进自注意和交叉注意。这些组件的任务是处理有噪声的潜在变量zt和嵌入的条件嵌入。
训练完成后,使用确定性采样方法重构原始潜在zt,如去噪扩散隐式模型(DDIM)[29]。然后由解码器D对潜在的zt进行解码,以生成最终的图像输出。这种方法不仅保留了生成图像的保真度,而且确保它们与输入辅助条件在上下文上一致,证明了在生成模型中集成条件过程的有效性。
交叉注意作为运动指导。 交叉注意是潜在扩散模型框架的关键组成部分,通过指导信息的流动和焦点,显著增强了生成过程。这种机制使模型能够专注于特定的运动引导和潜在图像表示,从而提高生成的视频与运动条件之间的语义一致性。在一般的视频生成任务中,运动条件可能包括文本提示或密集的运动流。在更专业的领域,如人类图像动画,运动条件可能涉及骨架,语义图,和3D参数流。对于人像动画任务,通常使用音频作为运动条件,并使用交叉注意来有效地整合相关条件。在数学上,交叉注意是使用注意层来实现的,这些注意层处理运动条件的嵌入,表示为cembed,以及有噪声的潜在变量zt。这些层计算注意力分数,决定模型在不同输入方面的关注水平。然后使用分数来衡量每个组件的贡献,创建一个加权和,作为后续层的输入。交叉注意机制可以表示为:CrossAttn(zt, cembed) = attention (Q, K, V)。(3)这里,CrossAttn(zt, cembed)使用以下方法计算注意力分数:Q = WQ·zt, WQ∈R De×Dz (4) K = WK·cembed, WK∈R De×Dc (5) V = WV·cembed, WV∈R De×Dc(6)其中WQ、WK和WV是可学习的投影矩阵。
输出是加权表示,它捕获了扩散过程当前阶段输入条件和潜在图像的最相关方面。潜扩散模型通过引入交叉注意,根据潜变量的演化状态和指定的运动条件动态调整焦点。
层次音频驱动的视觉合成
如图2所示,我们的任务是在给定人脸图像和音频片段的情况下生成一个具有S帧的视频。对于每一帧s,我们表示在扩散时间步长t处对应的潜在表示为z (s) t。
面部嵌入。 人脸嵌入的目标是生成高保真的人像身份特征。与之前利用CLIP[29]对大型图像和文本描述数据集进行联合训练进行通用视觉特征编码的方法不同,我们的方法使用预训练的人脸编码器来提取身份特征cexp∈R Df。这些特征被输入到扩散网络的交叉注意模块,即CrossAttn(z (s) t, cexp),与潜在交互,生成忠实于输入字符特征的肖像动画。该方法不仅保证了面部特征提取的泛化,而且准确地保留和再现了面部表情、年龄、性别等个体身份特征。
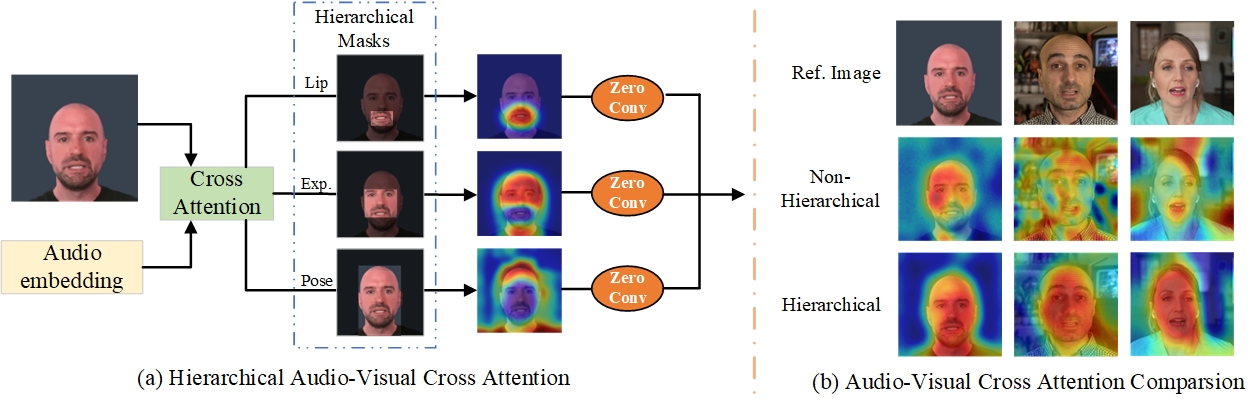
图3:分层音频驱动的视觉合成的可视化,以及原始full方法和我们提出的分层视听交叉注意之间的视听交叉注意的比较分析。
音频嵌入。 为了增强动画中运动驱动信息的音频编码,我们采用wav2vec[33]作为音频特征编码器。具体来说,我们将来自wav2vec网络最后12层的音频嵌入连接起来,以捕获跨不同音频层的更丰富的语义信息。考虑到上下文对序列音频数据的影响,我们为S帧提取了相应的5秒音频片段。利用三个简单的线性层,我们将预训练模型的音频嵌入转换为{c (s) audio} s s=1,其中c (s) audio∈R Da是s帧的音频嵌入。
分层视听交叉注意。 如图3所示,我们引入了一种分层的视听交叉注意机制,以促进模型学习嘴唇、表情和姿势等视听成分之间的关系。
首先,我们对人脸图像进行预处理,得到蒙版Mlip, Mexp, Mpose∈{0,1}Hz×Wz,分别代表唇区、表情区和姿态区。具体来说,我们使用现成的工具箱MediaPipe来预测面部图像i的地标。MediaPipe预测嘴唇和表情的多个地标的坐标。如果(i, j)在BoundingBox® 0内,则由Yr(i, j) = 1得到边界框掩码Ylip, Yexp∈{0,1}Hz×Wz,(7)其中r∈{lip, exp},并且BoundingBox®表示r的所有标志的边界框。我们计算Mlip = Ylip, (8) Mexp =(1−Mlip)⊙Yexp, (9) Mpose = 1−Mexp,(10)其中⊙为Hadamard积。
接下来,我们在潜在表征和音频嵌入之间应用交叉注意机制:0 (s) t = CrossAttn(z (s) t, c (s)音频)。(11)我们应用掩模,通过b (s) t = o (s) t⊙Mpose, (12) f (s) t = o (s) t⊙Mlip, (13) l (s) t = o (s) t⊙Mlip得到不同尺度的潜在表示。(14)最后,为了有效地合并这些输出,我们增加了一个自适应模块来处理分层音频引导。具体来说,卷积层得到的输出是:X u Convu(u), u∈{a (s) t, f(s) t, l(s) t}。(15)
训练和推理训练
训练过程包括两个不同的阶段:(1)在第一个训练阶段,利用参考图像和目标视频帧对生成单个视频帧。VAE编解码器和人脸图像编码器的参数是固定的,同时允许对ReferenceNet和去噪UNet的空间交叉注意模块的权重进行优化,提高单帧生成能力。提取包含14帧的视频片段作为输入数据,从面部视频片段中随机选取一帧作为参考帧,另一帧作为目标图像。(2)在第二个训练阶段,使用参考图像、输入音频和目标视频数据对视频序列进行训练。参考网和去噪网的空间模块保持不变,重点是增强视频序列生成能力。这一阶段主要侧重于训练分层的视听交叉注意,以建立作为运动指导的音频与嘴唇、表情和姿势的视觉信息之间的关系。此外,还引入了运动模块来改善模型的时效性、一致性和平滑性,用AnimateDiff[11]中已有的权重初始化。在此阶段,从视频剪辑中随机选择一帧作为参考图像。
推理。在推理阶段,网络以单个参考图像和驱动音频作为输入,产生一个视频序列,该视频序列根据相应的音频使参考图像动画化。为了产生视觉上一致的长视频,我们利用前一个视频片段的最后2帧作为下一个视频片段的初始k帧,从而实现视频片段生成的增量推理。
实验设置
实现细节。 实验包括训练和推理在一个具有8个NVIDIA A100 gpu的计算平台上进行。初始和后续阶段分别包含30,000个训练步骤,批处理大小为4,视频尺寸设置为512 × 512。
第二阶段的每个训练实例产生14个视频帧,运动模块的电位与视频连续性的前2个ground truth帧相连接。在这两个训练阶段,学习率为1e-5,运动模块初始化的权值来自Animatediff。为了增强视频的生成,在训练过程中,参考图像、引导音频和运动帧以0.05的概率被丢弃。在推理中,通过将噪声潜伏与运动模块中前一步的最后2个运动帧的特征映射连接起来,确保了序列之间的连续性。
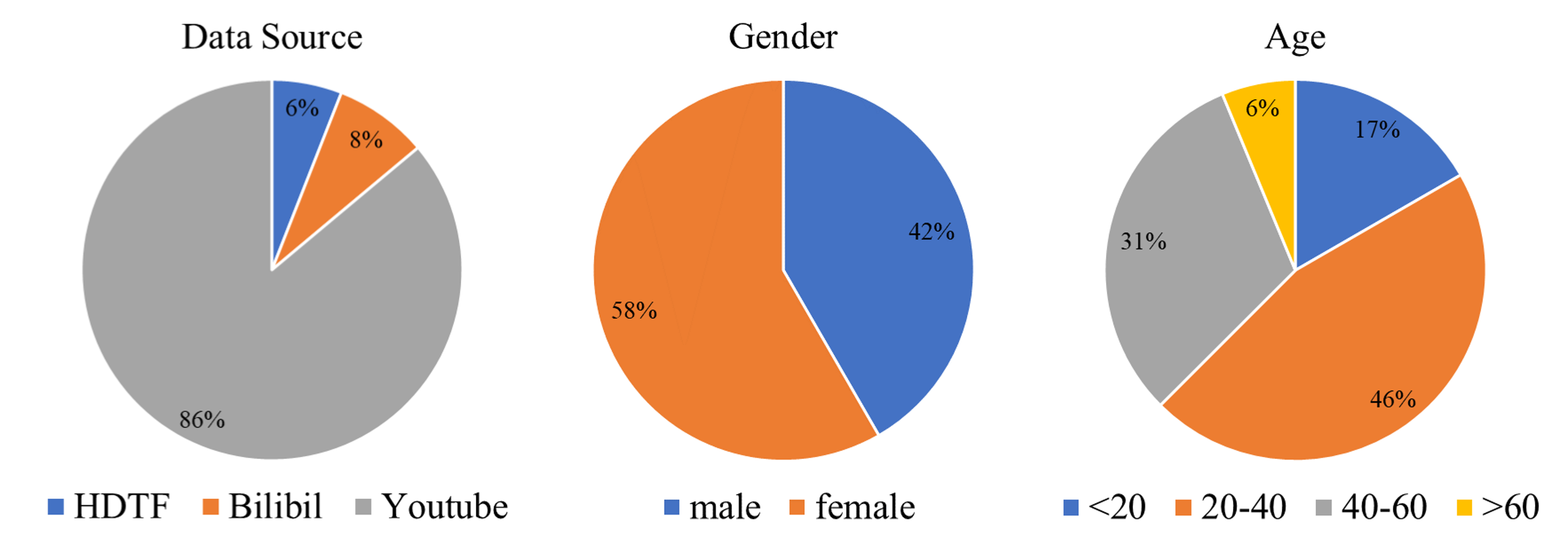
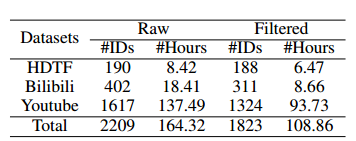
数据集。 如图4所示,我们的数据集包括HDTF(190个片段,8.42小时)和额外的互联网来源数据(2019个片段,155.90小时)。如图4所示,这些视频是由不同年龄、种族、性别的个体在不同的室内和室外背景下拍摄的半身像或特写镜头。为了确保高质量的训练数据,我们进行了数据清洗过程,重点是保留具有强烈嘴唇和音频一致性的单人演讲视频,同时排除场景变化,重大摄像机移动,过度的面部动作,以及完全面向侧面的镜头。利用Mediapipe确定训练视频中的表情和嘴唇活动范围,为构建训练和推理中使用的表情和嘴唇面具奠定基础。经过数据清洗后,我们的训练数据集包括HDTF(188个片段,6.47小时)和互联网来源的数据(1635个片段,102.39小时),每个训练视频片段包括15帧,分辨率为512 × 512。
评价指标。 在肖像图像动画方法中使用的评估指标包括:Frechet起始距离(FID)、Frechet视频距离(FVD)、同步- c (SyncC)、同步- d (Sync-D)和E-FID。具体来说,FID和FVD测量生成的图像与真实数据之间的相似性,值越低表示性能越好,因此输出越真实。Sync-C和Sync-D从内容和动态方面评估生成视频的唇形同步,Sync-C得分越高,Sync-D得分越低,表示与音频的一致性越好。E-FID基于从Inception网络中提取的特征评估生成图像的质量,提供精细的保真度评估。
基线。 在我们的定量实验中,我们将我们提出的方法与公开可用的SadTalker[53]、DreamTalk[24]、Audio2Head[42]和AniPortrait[46]进行了比较分析。评估是在HDTF、CelebV和提议的数据集上进行的,利用训练和测试分割,其中90%的身份数据被分配用于训练目的。定性比较包括对我们的方法与这些选定方法的评估,考虑到参考图像、音频输入以及每种方法提供的最终动画输出。这一定性评估旨在深入了解我们的方法在生成逼真和富有表现力的说话头部动画方面的性能和能力。

图6:在CelebV数据集上与现有方法的定性比较。
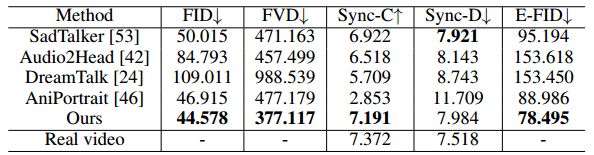
表2:在CelebV数据集上与现有人像动画方法的定量比较。

图7:在不同的肖像风格下,提出的方法的视频生成结果。
讨论
尽管本研究提出了关于肖像动画的进展,但仍存在一些需要进一步探索和考虑的局限性。这些限制强调了未来的研究努力可以对所提出的方法的改进和增强做出贡献的领域:(1)增强的视音频同步。未来的研究可以深入研究更先进的同步技术,潜在地集成复杂的音频分析方法或利用更深层次的跨模式学习策略。这些进步有可能改善面部运动与音频输入的一致性,特别是在以复杂的语音模式或微妙的情感表达为特征的环境中。(2)稳健的时间相干性。需要进一步探索先进的时间相干机制,以解决具有快速或复杂运动的序列的不一致性。开发健壮的对齐策略,可能以序列数据的长期依赖关系或利用循环神经网络模型为指导,可以增强帧对帧的稳定性。(3)计算效率。优化基于扩散的生成模型和基于unet的去噪算法的计算效率势在必行。对轻量级体系结构、模型修剪或高效并行化技术的研究有望使该方法更适用于实时应用程序,同时将资源利用率降至最低。(4)加强多样性控制。在表达和姿势的多样性和保持视觉身份完整性之间的平衡仍然是一个关键的挑战。
未来的努力可能集中在改进自适应控制机制上,可能通过整合更细微的控制参数或复杂的多样性指标。这样的改进将确保更自然和多样化的动画输出,同时保持面部身份的真实性。
社会风险和缓解措施
在本文提出的研究背景下,音频输入驱动的人像动画技术的开发和实施存在社会风险。一个潜在的风险是,创建高度逼真和动态的肖像可能会被滥用于欺骗或恶意目的,比如深度造假。为了减轻这种风险,必须建立道德准则和负责任的技术使用实践。
此外,在动画肖像创作中使用个人图像和声音可能会涉及隐私和同意问题。缓解这些担忧涉及确保透明的数据使用政策、获得知情同意和保护个人隐私权。通过解决这些社会风险并实施适当的缓解措施,该研究旨在促进社会背景下肖像图像动画技术的负责任和道德发展。
小结
本文介绍了一种基于端到端扩散模型的人像动画新方法,解决了音频驱动的面部动态同步和具有时间一致性的高质量动画生成的挑战。提出的分层视听合成模块通过交叉注意机制和自适应加权增强视听对齐。该方法通过集成基于扩散的生成建模、UNet去噪、时间对齐和ReferenceNet,提高了动画质量和真实感。实验评估表明,该系统具有更好的图像和视频质量,增强了唇部同步,增加了运动多样性,并得到了更好的FID和FVD指标的验证。这种方法可以灵活地控制表情和姿势的多样性,以适应不同的视觉身份

















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











