







前言
RT-DETR是百度出品的新一代检测器,属于DETR系列,即基于Transformer的目标检测框架。官方代码是基于Paddle平台的,当然也有Pytorch版本的,对于习惯使用Pytorch平台和YOLO风格的研究人员而言,调试和改进RT-DETR是比较痛苦的。不过,YOLO这么强大的社区,肯定会解决这样的问题,这不在yolov8中已经存在RT-DETR的版本。
一、YOLOv8的安装
参考v10的安装过程;
在conda创建一个名为yolov8的新环境,并在其中安装python3.8,这个环境是独立的不会影响系统中的其他环境:
conda create -n yolov8 python=3.8
然后再激活yolov8的Conda环境:
conda activate yolov8
通过pip命令安装python包及其版本号:
pip install ultralytics
二、RT-DETR的测试
2.1 先测试YOLOv8的效果
如果我们使用yolov8来测试以下图片的话:
0: 640x576 22 cars, 5 trucks, 89.4ms
Speed: 4.7ms preprocess, 89.4ms inference, 497.4ms postprocess per image at shape (1, 3, 640, 576)
Results saved to /home/wqt/Projects/ultralytics/runs/detect/predict
4.7+89.4+497.4=595ms
可以看到效果如下,检测非常精细,很多远方的car都能检测出来,说明YOLOv8在小目标检测中还是有优势的,但是运行速度为:4.7+89.4+497.4≈600ms,这个推理速度着实有点慢,特别是后处理即NMS,耗时太多。

2.2 RT-DETR的使用与检测效果
RT-DETR的使用
from ultralytics import RTDETR
from PIL import Image
import cv2
# 加载预训练的COCO RT-DETR-l模型
model = RTDETR('rtdetr-l.pt')
# 显示模型信息(可选)
model.info()
# from PIL
im1 = Image.open("figures/16pic_6868839_b.jpg")
results = model.predict(source=im1, save=True) # save plotted images
同样的图片检测效果如下:

rt-detr-l summary: 673 layers, 32970476 parameters, 0 gradients, 108.3 GFLOPs
0: 640x640 1 0, 21 2s, 3 7s, 20.6ms
Speed: 2.6ms preprocess, 20.6ms inference, 1.5ms postprocess per image at shape (1, 3, 640, 640)
Results saved to /home/wqt/Projects/ultralytics/runs/detect/predict2
2.6+20.6+1.5=24.7ms
说明RT-DETR优点体现的很明显,无需后处理,识别大物体好,但是对于小目标还是有短板
三、RT-DETR的使用
3.1 RT-DETR的原始结构:
参考它的构造文件/home/wqt/Projects/ultralytics/ultralytics/cfg/models/rt-detr/rtdetr-resnet50.yaml:
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, ResNetLayer, [3, 64, 1, True, 1]] # 0
- [-1, 1, ResNetLayer, [64, 64, 1, False, 3]] # 1
- [-1, 1, ResNetLayer, [256, 128, 2, False, 4]] # 2
- [-1, 1, ResNetLayer, [512, 256, 2, False, 6]] # 3
- [-1, 1, ResNetLayer, [1024, 512, 2, False, 3]] # 4
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 5
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 7
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 9
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256]] # 11
- [-1, 1, Conv, [256, 1, 1]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [2, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (16), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 17, downsample_convs.0
- [[-1, 12], 1, Concat, [1]] # cat Y4
- [-1, 3, RepC3, [256]] # F4 (19), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 20, downsample_convs.1
- [[-1, 7], 1, Concat, [1]] # cat Y5
- [-1, 3, RepC3, [256]] # F5 (22), pan_blocks.1
- [[16, 19, 22], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
3.2 使用RT-DETR任务迁移:在钢板缺陷检测NEU数据集上
from ultralytics import RTDETR
model = RTDETR(model='rtdetr-l.yaml')
model.train(data='NEU.yaml', epochs=120, batch=16, imgsz=640)
需要提前配置好NEU的数据集,转为YOLO对应的格式即可。网上有很多对应版本的数据集可下载!
3.3 使用RT-DETR任务迁移:在PKU-PCB数据集检测PCB表面缺陷
3.3.1 数据集的准备:
相关文件下载:PCB数据集
注意:需要将原本数据集里面的xml文件和图片都要移动到上一级目录中才能读取到文件
(1)训练集划分
主要是将数据集分类成训练代码和测试代码,默认数据集会随机按比例8:1:1分类在train,val,test三个文本文件中,运行代码之后ImageSets/Main会出现四个文件,主要是写入的内容是训练数据集和测试数据集的图片名称
# -*- coding: utf-8 -*-
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 0.8
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
(2)用于yolo训练的txt格式代码
主要是将图片数据集标注后的xml文件中的标注信息读取出来并写入txt文件,运行后在labels文件夹中出现所有图片数据集的标注信息
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val']
classes = ["missing_hole","mouse_bite","open_circuit","short","spur","spurious_copper"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
# Spur Spurious_copper
def conver_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
conver_annotation(image_id)
list_file.close()
3.3.2 模型的配置
使用预训练好的模型,而不是从头开始训练,它会带来更快的拟合;如果从零开始训练RT-DETR,不太容易训练收敛。
Epoch GPU_mem giou_loss cls_loss l1_loss Instances Size
0%| | 0/32 [00:00<?, ?it/s]/home/wqt/anaconda3/envs/yolov8/lib/python3.8/site-packages/torch/autograd/graph.py:744: UserWarning: grid_sampler_2d_backward_cuda does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True, warn_only=True)'. You can file an issue at https://github.com/pytorch/pytorch/issues to help us prioritize adding deterministic support for this operation. (Triggered internally at ../aten/src/ATen/Context.cpp:83.)
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
120/120 13.1G 0.3344 0.3707 0.02792 7 640: 100%|██████████| 32/32 [00:08<00:00, 3.95it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 7.21it/s]
all 125 533 0.959 0.948 0.966 0.499
120 epochs completed in 0.321 hours.
Optimizer stripped from /home/wqt/Projects/ultralytics/runs/detect/train6/weights/last.pt, 66.2MB
Optimizer stripped from /home/wqt/Projects/ultralytics/runs/detect/train6/weights/best.pt, 66.2MB
Validating /home/wqt/Projects/ultralytics/runs/detect/train6/weights/best.pt...
Ultralytics YOLOv8.2.31 🚀 Python-3.8.19 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
rt-detr-l summary: 498 layers, 31996070 parameters, 0 gradients, 103.5 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 5.40it/s]
all 125 533 0.956 0.966 0.971 0.508
missing_hole 18 77 0.989 1 0.995 0.589
mouse_bite 19 84 0.952 0.949 0.967 0.492
open_circuit 22 92 0.956 0.944 0.96 0.508
short 21 86 0.953 0.965 0.959 0.493
spur 22 93 0.927 0.961 0.96 0.471
spurious_copper 23 101 0.961 0.975 0.987 0.495
Speed: 0.1ms preprocess, 3.0ms inference, 0.0ms loss, 0.1ms postprocess per image
Results saved to /home/wqt/Projects/ultralytics/runs/detect/train6
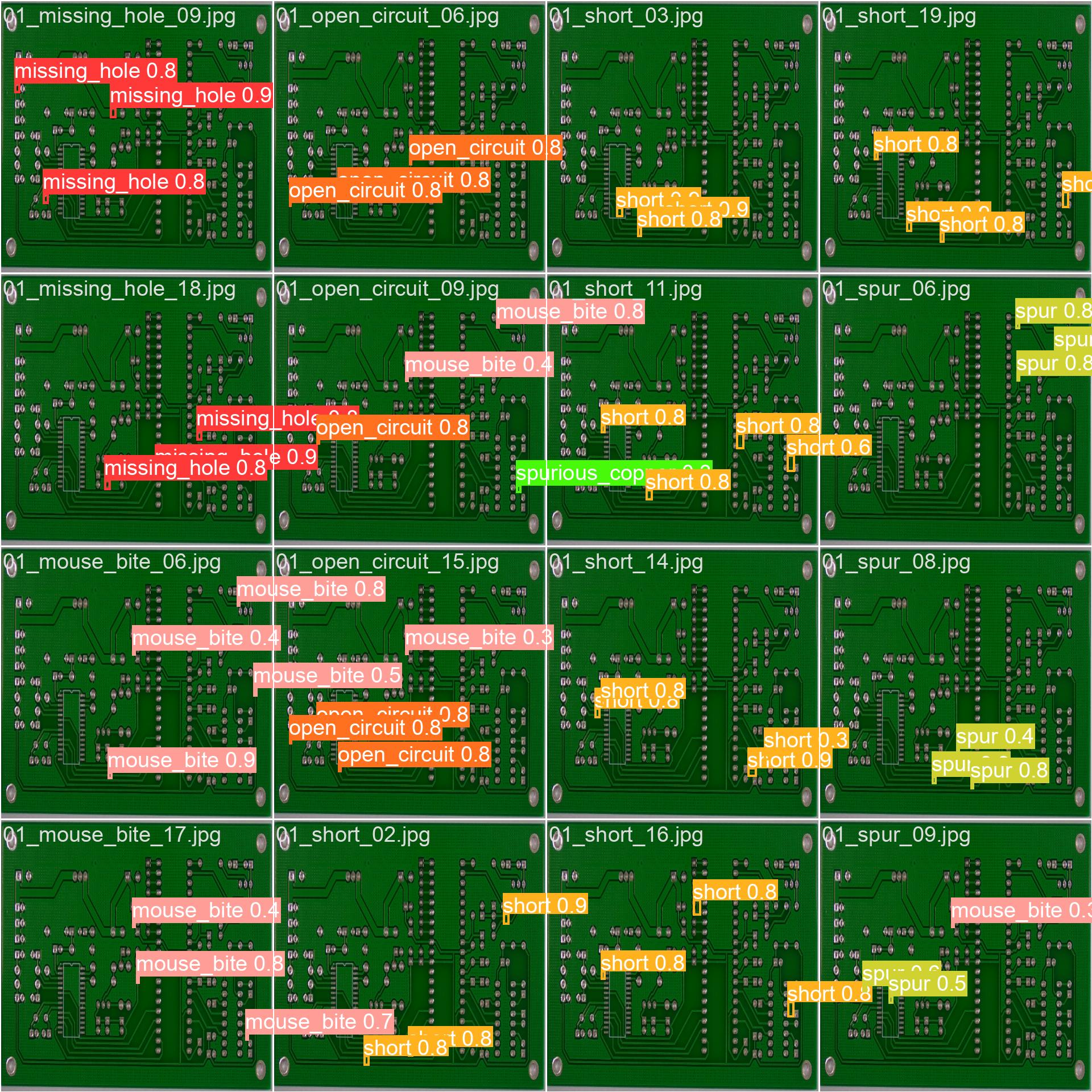
通过上述训练,我们可以在该数据集上获得领先的性能,达到了95.6%的精度;
效果实测:


val性能
rt-detr-l summary: 498 layers, 31996070 parameters, 0 gradients, 103.5 GFLOPs
val: Scanning /home/wqt/Projects/data/PCB_DATASET2YOLO/labels.cache... 125 images, 0 backgrounds, 0 corrupt: 100%|██████████| 125/125 [00:00<?, ?it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 125/125 [00:03<00:00, 41.28it/s]
all 125 533 0.956 0.964 0.969 0.512
missing_hole 18 77 0.99 1 0.995 0.596
mouse_bite 19 84 0.952 0.949 0.967 0.496
open_circuit 22 92 0.956 0.944 0.96 0.514
short 21 86 0.941 0.953 0.947 0.493
spur 22 93 0.927 0.961 0.96 0.472
spurious_copper 23 101 0.97 0.975 0.987 0.502
Speed: 0.2ms preprocess, 21.6ms inference, 0.0ms loss, 0.2ms postprocess per image
Results saved to /home/wqt/Projects/ultralytics/runs/detect/val2
四、如何改进RT-DETR:驾驭这个优秀的检测模型
这里,我们尝试改进RT-DETR的stem模块,原始的Stem模块为HGStem,我们尝试加入RepConv来替换原始的Conv,改进后的模块称之为R额怕HGStem。
4.1 添加RepHGStem
class RepHGStem(nn.Module):
"""
StemBlock of PPHGNetV2 with 5 convolutions and one maxpool2d.
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py
"""
def __init__(self, c1, cm, c2):
"""Initialize the SPP layer with input/output channels and specified kernel sizes for max pooling."""
super().__init__()
self.stem1 = RepConv(c1, cm, 3, 2, act=nn.ReLU())
self.stem2a = Conv(cm, cm // 2, 2, 1, 0, act=nn.ReLU())
self.stem2b = Conv(cm // 2, cm, 2, 1, 0, act=nn.ReLU())
self.stem3 = RepConv(cm * 2, cm, 3, 2, act=nn.ReLU())
self.stem4 = Conv(cm, c2, 1, 1, act=nn.ReLU())
self.pool = nn.MaxPool2d(kernel_size=2, stride=1, padding=0, ceil_mode=True)
def forward(self, x):
"""Forward pass of a PPHGNetV2 backbone layer."""
x = self.stem1(x)
x = F.pad(x, [0, 1, 0, 1])
x2 = self.stem2a(x)
x2 = F.pad(x2, [0, 1, 0, 1])
x2 = self.stem2b(x2)
x1 = self.pool(x)
x = torch.cat([x1, x2], dim=1)
x = self.stem3(x)
x = self.stem4(x)
return x
为了加入这个模块,并且需要加载之前训练好的Pretrain模型,我们需要在源文件中更改,打开ultralytics/engine/model.py,找到train方法,找到如下图这一行,并替换:

这样的作用,既能加载预训练好的权重,又能加入新的模块,也称之为“冻结训练”;
Bug1修复:
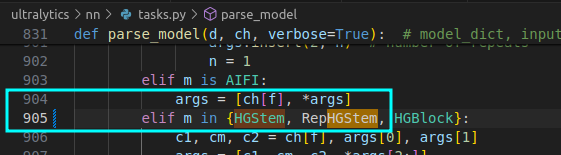
File "/home/wqt/Projects/ultralytics/ultralytics/nn/tasks.py", line 855, in parse_model
m = getattr(torch.nn, m[3:]) if "nn." in m else globals()[m] # get module
KeyError: 'RepHGStem'
解决办法:
BUG 2
File "/home/wqt/Projects/ultralytics/ultralytics/nn/tasks.py", line 10, in <module>
from ultralytics.nn.modules import (
ImportError: cannot import name 'RepHGStem' from 'ultralytics.nn.modules' (/home/wqt/Projects/ultralytics/ultralytics/nn/modules/__init__.py)
开始训练
Overriding model.yaml nc=80 with nc=6
WARNING ⚠️ no model scale passed. Assuming scale='l'.
from n params module arguments
0 -1 1 27520 ultralytics.nn.modules.block.RepHGStem [3, 32, 48]
1 -1 6 155072 ultralytics.nn.modules.block.HGBlock [48, 48, 128, 3, 6]
2 -1 1 1408 ultralytics.nn.modules.conv.DWConv [128, 128, 3, 2, 1, False]
3 -1 6 839296 ultralytics.nn.modules.block.HGBlock [128, 96, 512, 3, 6]
4 -1 1 5632 ultralytics.nn.modules.conv.DWConv [512, 512, 3, 2, 1, False]
5 -1 6 1695360 ultralytics.nn.modules.block.HGBlock [512, 192, 1024, 5, 6, True, False]
6 -1 6 2055808 ultralytics.nn.modules.block.HGBlock [1024, 192, 1024, 5, 6, True, True]
7 -1 6 2055808 ultralytics.nn.modules.block.HGBlock [1024, 192, 1024, 5, 6, True, True]
8 -1 1 11264 ultralytics.nn.modules.conv.DWConv [1024, 1024, 3, 2, 1, False]
9 -1 6 6708480 ultralytics.nn.modules.block.HGBlock [1024, 384, 2048, 5, 6, True, False]
10 -1 1 524800 ultralytics.nn.modules.conv.Conv [2048, 256, 1, 1, None, 1, 1, False]
11 -1 1 789760 ultralytics.nn.modules.transformer.AIFI [256, 1024, 8]
12 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 7 1 262656 ultralytics.nn.modules.conv.Conv [1024, 256, 1, 1, None, 1, 1, False]
15 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
17 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
18 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
19 3 1 131584 ultralytics.nn.modules.conv.Conv [512, 256, 1, 1, None, 1, 1, False]
20 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
22 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
23 [-1, 17] 1 0 ultralytics.nn.modules.conv.Concat [1]
24 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
25 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
26 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
27 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
28 [21, 24, 27] 1 7314182 ultralytics.nn.modules.head.RTDETRDecoder [6, [256, 256, 256]]
rtdetr-l-rep summary: 685 layers, 32820678 parameters, 32820678 gradients, 108.2 GFLOPs
Transferred 914/953 items from pretrained weights
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
AMP: checks passed ✅
train: Scanning /home/wqt/Projects/data/PCB_DATASET2YOLO/labels... 498 images, 0 backgrounds, 0 corrupt: 100%|██████████| 498/498 [00:00<00:00, 674.01it/s]
train: New cache created: /home/wqt/Projects/data/PCB_DATASET2YOLO/labels.cache
val: Scanning /home/wqt/Projects/data/PCB_DATASET2YOLO/labels... 125 images, 0 backgrounds, 0 corrupt: 100%|██████████| 125/125 [00:00<00:00, 1984.77it/s]
val: New cache created: /home/wqt/Projects/data/PCB_DATASET2YOLO/labels.cache
Plotting labels to /home/wqt/Projects/ultralytics/runs/detect/train7/labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.001, momentum=0.9) with parameter groups 145 weight(decay=0.0), 208 weight(decay=0.0005), 228 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to /home/wqt/Projects/ultralytics/runs/detect/train7
Starting training for 230 epochs...
可以从打印内容中看出,RepHGStem已经添加成功,并且成功加载了预训练的模型,即Transferred 914/953 items from pretrained weights。
效果对比:改进后的Rep模型与原始的模型对比
这是改进后模型的测试结果:
0%| | 0/32 [00:00<?, ?it/s]/home/wqt/anaconda3/envs/yolov8/lib/python3.8/site-packages/torch/autograd/graph.py:744: UserWarning: grid_sampler_2d_backward_cuda does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True, warn_only=True)'. You can file an issue at https://github.com/pytorch/pytorch/issues to help us prioritize adding deterministic support for this operation. (Triggered internally at ../aten/src/ATen/Context.cpp:83.)
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
230/230 13.8G 0.3001 0.3589 0.02359 10 640: 100%|██████████| 32/32 [00:08<00:00, 3.85it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 7.08it/s]
all 125 533 0.967 0.956 0.971 0.492
230 epochs completed in 0.630 hours.
Optimizer stripped from /home/wqt/Projects/ultralytics/runs/detect/train7/weights/last.pt, 66.2MB
Optimizer stripped from /home/wqt/Projects/ultralytics/runs/detect/train7/weights/best.pt, 66.2MB
Validating /home/wqt/Projects/ultralytics/runs/detect/train7/weights/best.pt...
Ultralytics YOLOv8.2.31 🚀 Python-3.8.19 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
rtdetr-l-rep summary: 498 layers, 31996070 parameters, 0 gradients, 103.5 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 5.41it/s]
all 125 533 0.972 0.947 0.97 0.503
missing_hole 18 77 0.999 1 0.995 0.57
mouse_bite 19 84 0.937 0.929 0.96 0.5
open_circuit 22 92 0.96 0.935 0.955 0.537
short 21 86 0.988 0.956 0.969 0.478
spur 22 93 0.976 0.889 0.952 0.438
spurious_copper 23 101 0.97 0.976 0.988 0.493
Speed: 0.1ms preprocess, 3.0ms inference, 0.0ms loss, 0.1ms postprocess per image
Results saved to /home/wqt/Projects/ultralytics/runs/detect/train7
比较于原始模型在PKU-PCB上的P%为94.4%,这里达到了97.2%,性能的提升非常明显。
4.2 RepConv替换
将上述模型的Conv3x2都替换为RepConv,可以参考cfg/**.yaml文件。
RepConv一定要制定3x1,此处替换失败;
4.3 数据增强训练
详解cfg/default.yaml
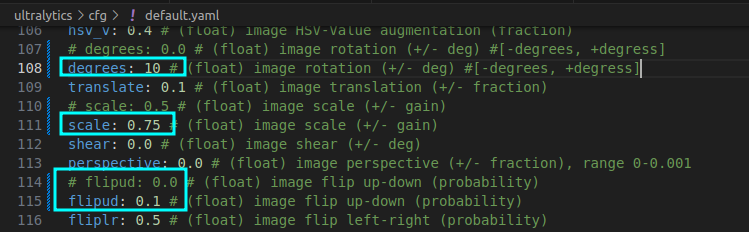
degrees=10, translate=0.1, scale=0.75, shear=0.0, perspective=0.0, flipud=0.1, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=/home/wqt/Projects/ultralytics/runs/detect/train8
Overriding model.yaml nc=80 with nc=6
WARNING ⚠️ no model scale passed. Assuming scale='l'.
from n params module arguments
0 -1 1 27520 ultralytics.nn.modules.block.RepHGStem [3, 32, 48]
1 -1 6 155072 ultralytics.nn.modules.block.HGBlock [48, 48, 128, 3, 6]
2 -1 1 1408 ultralytics.nn.modules.conv.DWConv [128, 128, 3, 2, 1, False]
3 -1 6 839296 ultralytics.nn.modules.block.HGBlock [128, 96, 512, 3, 6]
4 -1 1 5632 ultralytics.nn.modules.conv.DWConv [512, 512, 3, 2, 1, False]
5 -1 6 1695360 ultralytics.nn.modules.block.HGBlock [512, 192, 1024, 5, 6, True, False]
6 -1 6 2055808 ultralytics.nn.modules.block.HGBlock [1024, 192, 1024, 5, 6, True, True]
7 -1 6 2055808 ultralytics.nn.modules.block.HGBlock [1024, 192, 1024, 5, 6, True, True]
8 -1 1 11264 ultralytics.nn.modules.conv.DWConv [1024, 1024, 3, 2, 1, False]
9 -1 6 6708480 ultralytics.nn.modules.block.HGBlock [1024, 384, 2048, 5, 6, True, False]
10 -1 1 524800 ultralytics.nn.modules.conv.Conv [2048, 256, 1, 1, None, 1, 1, False]
11 -1 1 789760 ultralytics.nn.modules.transformer.AIFI [256, 1024, 8]
12 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 7 1 262656 ultralytics.nn.modules.conv.Conv [1024, 256, 1, 1, None, 1, 1, False]
15 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
17 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
18 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
19 3 1 131584 ultralytics.nn.modules.conv.Conv [512, 256, 1, 1, None, 1, 1, False]
20 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
22 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
23 [-1, 17] 1 0 ultralytics.nn.modules.conv.Concat [1]
24 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
25 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
26 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
27 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
28 [21, 24, 27] 1 7314182 ultralytics.nn.modules.head.RTDETRDecoder [6, [256, 256, 256]]
rtdetr-l-rep summary: 685 layers, 32820678 parameters, 32820678 gradients, 108.2 GFLOPs
Transferred 953/953 items from pretrained weights
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
AMP: checks passed ✅
train: Scanning /home/wqt/Projects/data/PCB_DATASET2YOLO/labels... 498 images, 0 backgrounds, 0 corrupt: 100%|██████████| 498/498 [00:00<00:00, 638.33it/s]
train: New cache created: /home/wqt/Projects/data/PCB_DATASET2YOLO/labels.cache
val: Scanning /home/wqt/Projects/data/PCB_DATASET2YOLO/labels... 125 images, 0 backgrounds, 0 corrupt: 100%|██████████| 125/125 [00:00<00:00, 1878.13it/s]
val: New cache created: /home/wqt/Projects/data/PCB_DATASET2YOLO/labels.cache
Plotting labels to /home/wqt/Projects/ultralytics/runs/detect/train8/labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.001, momentum=0.9) with parameter groups 145 weight(decay=0.0), 208 weight(decay=0.0005), 228 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to /home/wqt/Projects/ultralytics/runs/detect/train8
Starting training for 230 epochs...
Epoch GPU_mem giou_loss cls_loss l1_loss Instances Size
0%| | 0/32 [00:00<?, ?it/s]/home/wqt/anaconda3/envs/yolov8/lib/python3.8/site-packages/torch/autograd/graph.py:744: UserWarning: grid_sampler_2d_backward_cuda does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True, warn_only=True)'. You can file an issue at https://github.com/pytorch/pytorch/issues to help us prioritize adding deterministic support for this operation. (Triggered internally at ../aten/src/ATen/Context.cpp:83.)
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
1/230 13.6G 0.8665 0.441 0.05895 19 640: 100%|██████████| 32/32 [00:09<00:00, 3.23it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 5.52it/s]
all 125 533 0.949 0.927 0.932 0.428
训练结果
Validating /home/wqt/Projects/ultralytics/runs/detect/train8/weights/best.pt...
Ultralytics YOLOv8.2.31 🚀 Python-3.8.19 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
rtdetr-l-rep summary: 498 layers, 31996070 parameters, 0 gradients, 103.5 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 5.32it/s]
all 125 533 0.963 0.961 0.964 0.517
missing_hole 18 77 0.975 0.999 0.994 0.602
mouse_bite 19 84 0.964 0.954 0.982 0.515
open_circuit 22 92 0.969 0.957 0.962 0.553
short 21 86 0.958 0.942 0.937 0.463
spur 22 93 0.951 0.946 0.952 0.455
spurious_copper 23 101 0.961 0.971 0.958 0.517
Speed: 0.1ms preprocess, 3.1ms inference, 0.0ms loss, 0.1ms postprocess per image
Results saved to /home/wqt/Projects/ultralytics/runs/detect/train8

策略2:较容易的数据增强
Pretrian model: Train 7/best.model
具体的增强策略如下:缩小的倍数不至于太小,因为我们的检测目标已经非常小了。
degrees=10, translate=0.1, scale=0.25, shear=0.0, perspective=0.0, flipud=0.1, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=/home/wqt/Projects/ultralytics/runs/detect/train9
训练结果:
Epoch GPU_mem giou_loss cls_loss l1_loss Instances Size
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
104/230 13.8G 0.3477 0.4078 0.02984 8 640: 100%|██████████| 32/32 [00:08<00:00, 3.84it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 7.44it/s]
all 125 533 0.947 0.935 0.952 0.474
EarlyStopping: Training stopped early as no improvement observed in last 100 epochs. Best results observed at epoch 4, best model saved as best.pt.
To update EarlyStopping(patience=100) pass a new patience value, i.e. `patience=300` or use `patience=0` to disable EarlyStopping.
104 epochs completed in 0.285 hours.
Optimizer stripped from /home/wqt/Projects/ultralytics/runs/detect/train9/weights/last.pt, 66.2MB
Optimizer stripped from /home/wqt/Projects/ultralytics/runs/detect/train9/weights/best.pt, 66.2MB
Validating /home/wqt/Projects/ultralytics/runs/detect/train9/weights/best.pt...
Ultralytics YOLOv8.2.31 🚀 Python-3.8.19 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
rtdetr-l-rep summary: 498 layers, 31996070 parameters, 0 gradients, 103.5 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 5.40it/s]
all 125 533 0.963 0.927 0.957 0.49
missing_hole 18 77 0.995 0.987 0.985 0.577
mouse_bite 19 84 0.963 0.936 0.959 0.48
open_circuit 22 92 0.956 0.935 0.968 0.51
short 21 86 0.962 0.884 0.943 0.435
spur 22 93 0.951 0.903 0.919 0.451
spurious_copper 23 101 0.949 0.92 0.967 0.487
Speed: 0.1ms preprocess, 3.0ms inference, 0.0ms loss, 0.1ms postprocess per image
Results saved to /home/wqt/Projects/ultralytics/runs/detect/train9
可以观察到,该策略的训练结果不是很理想。
策略3:较容易的数据增强
在策略2的基础上,将预训练的模型替换为Pretrian model: Train 8/best.model
degrees=10, translate=0.1, scale=0.25, shear=0.0, perspective=0.0, flipud=0.1, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=/home/wqt/Projects/ultralytics/runs/detect/train10
Validating /home/wqt/Projects/ultralytics/runs/detect/train10/weights/best.pt...
Ultralytics YOLOv8.2.31 🚀 Python-3.8.19 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
rtdetr-l-rep summary: 498 layers, 31996070 parameters, 0 gradients, 103.5 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 4.85it/s]
all 125 533 0.969 0.949 0.972 0.516
missing_hole 18 77 0.976 1 0.995 0.564
mouse_bite 19 84 0.963 0.94 0.966 0.506
open_circuit 22 92 1 0.952 0.983 0.568
short 21 86 0.987 0.905 0.961 0.486
spur 22 93 0.923 0.957 0.949 0.458
spurious_copper 23 101 0.966 0.941 0.975 0.511
Speed: 0.1ms preprocess, 3.2ms inference, 0.0ms loss, 0.1ms postprocess per image
策略4:更难的数据增强策略
将scale从0.5—>0.9:
degrees=10, translate=0.1, scale=0.9, shear=0.0, perspective=0.0, flipud=0.1, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=/home/wqt/Projects/ultralytics/runs/detect/train11
EarlyStopping: Training stopped early as no improvement observed in last 100 epochs. Best results observed at epoch 25, best model saved as best.pt.
To update EarlyStopping(patience=100) pass a new patience value, i.e. `patience=300` or use `patience=0` to disable EarlyStopping.
125 epochs completed in 0.339 hours.
Optimizer stripped from /home/wqt/Projects/ultralytics/runs/detect/train11/weights/last.pt, 66.2MB
Optimizer stripped from /home/wqt/Projects/ultralytics/runs/detect/train11/weights/best.pt, 66.2MB
Validating /home/wqt/Projects/ultralytics/runs/detect/train11/weights/best.pt...
Ultralytics YOLOv8.2.31 🚀 Python-3.8.19 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
rtdetr-l-rep summary: 498 layers, 31996070 parameters, 0 gradients, 103.5 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 5.43it/s]
all 125 533 0.953 0.939 0.957 0.498
missing_hole 18 77 0.979 1 0.988 0.56
mouse_bite 19 84 0.987 0.917 0.984 0.517
open_circuit 22 92 0.964 0.957 0.973 0.523
short 21 86 0.94 0.914 0.922 0.441
spur 22 93 0.911 0.914 0.911 0.448
spurious_copper 23 101 0.938 0.931 0.963 0.5
Speed: 0.1ms preprocess, 3.0ms inference, 0.0ms loss, 0.1ms postprocess per image
策略5:
scale=0.25
pretrianed model: train10/best.model
scale=0.25, shear=0.0, perspective=0.0, flipud=0.1, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=/home/wqt/Projects/ultralytics/runs/detect/train12
Validating /home/wqt/Projects/ultralytics/runs/detect/train12/weights/best.pt...
Ultralytics YOLOv8.2.31 🚀 Python-3.8.19 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
rtdetr-l-rep summary: 498 layers, 31996070 parameters, 0 gradients, 103.5 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 4.86it/s]
all 125 533 0.97 0.96 0.976 0.516
missing_hole 18 77 1 1 0.995 0.579
mouse_bite 19 84 0.937 0.94 0.979 0.507
open_circuit 22 92 0.983 0.967 0.975 0.553
short 21 86 0.988 0.925 0.962 0.483
spur 22 93 0.944 0.946 0.95 0.45
spurious_copper 23 101 0.969 0.98 0.992 0.526
Speed: 0.2ms preprocess, 2.9ms inference, 0.0ms loss, 0.1ms postprocess per image
Results saved to /home/wqt/Projects/ultralytics/runs/detect/train12
策略6:
scale=0.5
pretrianed model: train7/best.model
degrees=10, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.1, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=/home/wqt/Projects/ultralytics/runs/detect/train13
Validating /home/wqt/Projects/ultralytics/runs/detect/train13/weights/best.pt...
Ultralytics YOLOv8.2.31 🚀 Python-3.8.19 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
rtdetr-l-rep summary: 498 layers, 31996070 parameters, 0 gradients, 103.5 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 5.38it/s]
all 125 533 0.963 0.97 0.973 0.521
missing_hole 18 77 0.991 1 0.995 0.565
mouse_bite 19 84 0.964 0.988 0.99 0.523
open_circuit 22 92 0.978 0.968 0.98 0.582
short 21 86 0.976 0.946 0.949 0.473
spur 22 93 0.917 0.946 0.951 0.463
spurious_copper 23 101 0.951 0.97 0.973 0.523
Speed: 0.1ms preprocess, 3.1ms inference, 0.0ms loss, 0.1ms postprocess per image
Results saved to /home/wqt/Projects/ultralytics/runs/detect/train13
策略7:
scale=0.5
pretrianed model: rtdetr-l.pt
degrees=10, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.1, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=/home/wqt/Projects/ultralytics/runs/detect/train15
Validating /home/wqt/Projects/ultralytics/runs/detect/train15/weights/best.pt...
Ultralytics YOLOv8.2.31 🚀 Python-3.8.19 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
rtdetr-l-rep summary: 498 layers, 31996070 parameters, 0 gradients, 103.5 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 5.26it/s]
all 125 533 0.964 0.961 0.967 0.518
missing_hole 18 77 0.998 1 0.995 0.597
mouse_bite 19 84 0.973 0.952 0.974 0.498
open_circuit 22 92 0.978 0.966 0.977 0.559
short 21 86 0.946 0.942 0.935 0.448
spur 22 93 0.936 0.957 0.942 0.48
spurious_copper 23 101 0.954 0.95 0.981 0.526
Speed: 0.1ms preprocess, 3.0ms inference, 0.0ms loss, 0.1ms postprocess per image
Results saved to /home/wqt/Projects/ultralytics/runs/detect/train15
策略8
degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=/home/wqt/Projects/ultralytics/runs/detect/train18
Overriding model.yaml nc=80 with nc=6
WARNING ⚠️ no model scale passed. Assuming scale='l'.
取得结果如下:
Epoch GPU_mem giou_loss cls_loss l1_loss Instances Size
0%| | 0/32 [00:00<?, ?it/s]/home/wqt/anaconda3/envs/yolov8/lib/python3.8/site-
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
200/230 13.2G 0.2912 0.3492 0.02101 7 640: 100%|██████████| 32/32 [00:07<00:00, 4.02it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 7.81it/s]
all 125 533 0.964 0.948 0.973 0.506
200 epochs completed in 0.524 hours.
Optimizer stripped from /home/wqt/Projects/ultralytics/runs/detect/train18/weights/best.pt, 66.2MB
Validating /home/wqt/Projects/ultralytics/runs/detect/train18/weights/best.pt...
Ultralytics YOLOv8.2.31 🚀 Python-3.8.19 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 4090, 24209MiB)
rt-detr-l summary: 498 layers, 31996070 parameters, 0 gradients, 103.5 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 5.43it/s]
all 125 533 0.972 0.955 0.969 0.518
missing_hole 18 77 0.988 1 0.995 0.611
mouse_bite 19 84 0.975 0.913 0.963 0.551
open_circuit 22 92 0.96 0.978 0.989 0.524
short 21 86 0.976 0.988 0.978 0.492
spur 22 93 0.977 0.9 0.927 0.45
spurious_copper 23 101 0.955 0.95 0.962 0.479
Speed: 0.1ms preprocess, 3.0ms inference, 0.0ms loss, 0.1ms postprocess per image
val性能
rt-detr-l summary: 498 layers, 31996070 parameters, 0 gradients, 103.5 GFLOPs
val: Scanning /home/wqt/Projects/data/PCB_DATASET2YOLO/labels.cache... 125 images, 0 backgrounds, 0 corrupt: 100%|██████████| 125/125 [00:00<?, ?it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 125/125 [00:03<00:00, 41.48it/s]
all 125 533 0.975 0.959 0.974 0.521
missing_hole 18 77 0.992 1 0.995 0.607
mouse_bite 19 84 0.975 0.913 0.966 0.551
open_circuit 22 92 0.96 0.978 0.989 0.531
short 21 86 0.987 1 0.991 0.501
spur 22 93 0.977 0.899 0.927 0.451
spurious_copper 23 101 0.959 0.96 0.975 0.486
Speed: 0.2ms preprocess, 21.5ms inference, 0.0ms loss, 0.2ms postprocess per image
Results saved to /home/wqt/Projects/ultralytics/runs/detect/val
4.3 推理速度
每次输入一张图片,但是在训练一次输入16张(batch=16),
总结
RT-DETR作为新一代的旗舰DETR系列算法模型,使用它,并改造它,提升性能,这是我们所追求的。

















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











