







目录
前言
“真的太像我了”,此处指的是模仿你的声音太像了。那么,如何实现这样功能呢?这里介绍一个非常好用的声音克隆工具,为talking face generation 做准备。理论上,你想要模仿任何人的声音,都是可行的。
一、GPT-SoVITS是什么?
GPT-SoVITS是一个创新的开源AI语音克隆工具,它通过结合GPT和SoVITS技术,使得用户能够利用极少量的语音样本来训练出模仿特定人声的模型。这个工具支持零样本和少样本的文本到语音转换,并且能够跨英语、日语和中文等多种语言进行语音合成。GPT-SoVITS还提供了一个用户友好的WebUI界面,集成了声音伴奏分离、自动训练集分割、中文ASR和文本标注等工具,以简化训练数据集和模型的创建过程。它的应用场景广泛,包括个性化语音助手、虚拟角色配音、有声读物制作和无障碍服务等。开发者和爱好者可以通过GitHub代码库或社区制作的整合包和教程视频来获取GPT-SoVITS,并开始他们的语音合成和音色克隆项目。
功能:
- 零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
- 少样本 TTS: 仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
- 跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语、韩语、粤语和中文。
- WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
二、使用步骤
1.下载
介绍windows安装(示例):
提供了中国区的安装包下载链接,百度网盘 【提取码:mqpi】
安装包大概有4.0+G的大小,需要下载一会儿;
2.运行工具
双击“go-webui-v1.bat”

然后会自动跳转到UI界面
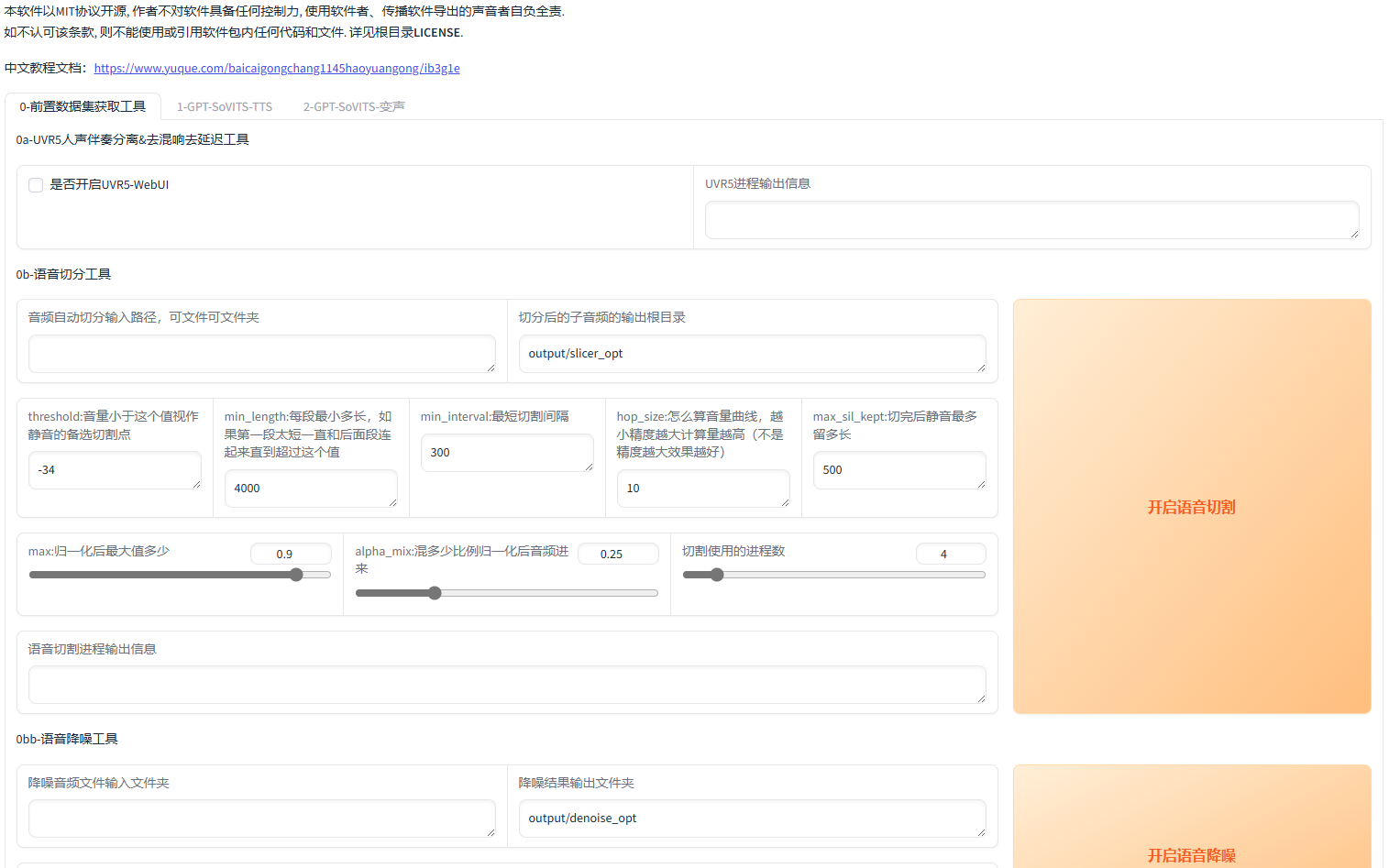
3.音频处理
开启“UVR5-WebUI”界面
会自动跳转到下面这个界面
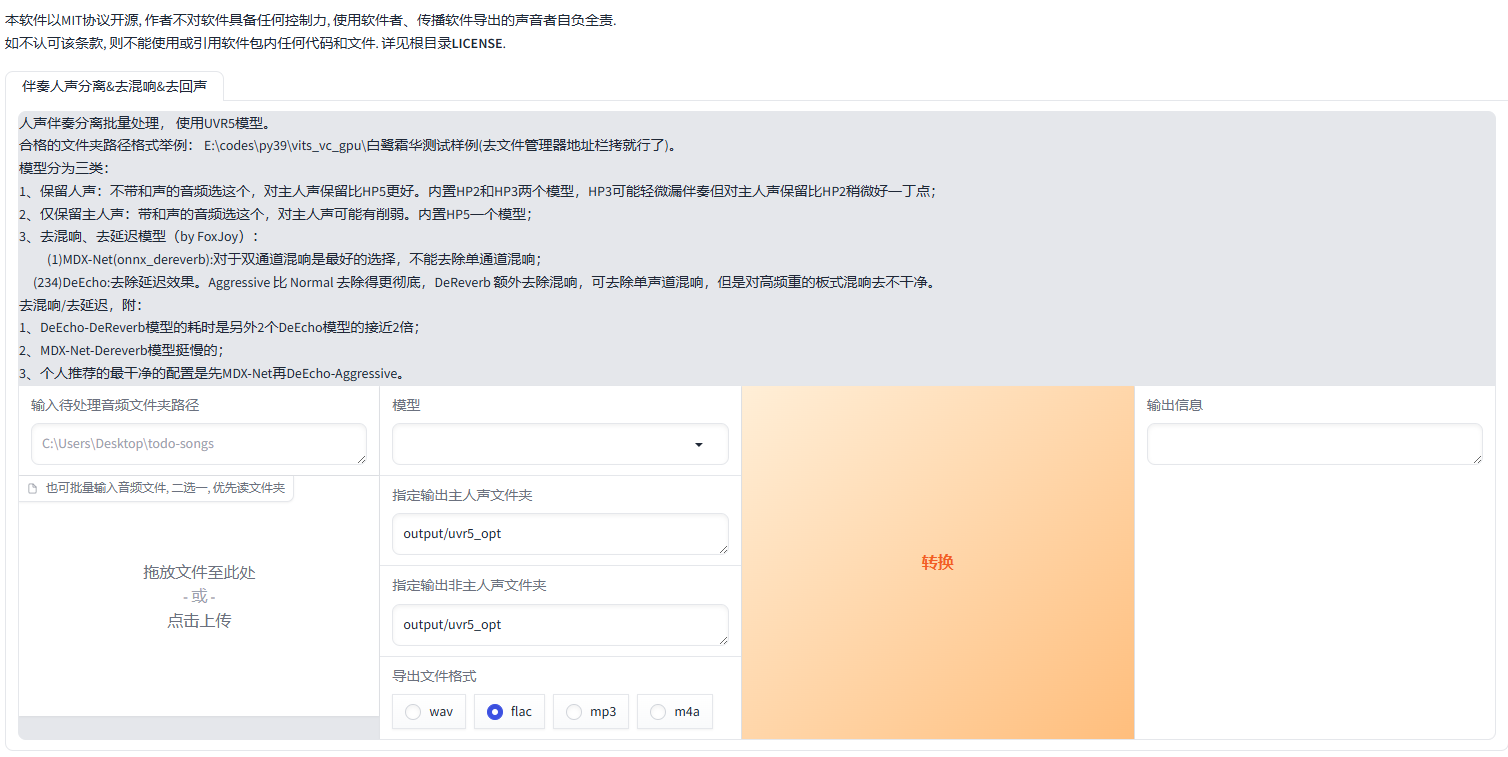
界面功能说明:
人声伴奏分离批量处理, 使用UVR5模型。
合格的文件夹路径格式举例: E:\codes\py39\vits_vc_gpu\白鹭霜华测试样例(去文件管理器地址栏拷就行了)。
模型分为三类:
- 保留人声:不带和声的音频选这个,对主人声保留比HP5更好。内置HP2和HP3两个模型,HP3可能轻微漏伴奏但对主人声保留比HP2稍微好一丁点;
- 仅保留主人声:带和声的音频选这个,对主人声可能有削弱。内置HP5一个模型;
- 去混响、去延迟模型(by FoxJoy):
(1)MDX-Net(onnx_dereverb):对于双通道混响是最好的选择,不能去除单通道混响;
(234)DeEcho:去除延迟效果。Aggressive比Normal去除得更彻底,DeReverb额外去除混响,可去除单声道混响,但是对高频重的板式混响去不干净。
去混响/去延迟,附:
1、DeEcho-DeReverb模型的耗时是另外2个DeEcho模型的接近2倍;
2、MDX-Net-Dereverb模型挺慢的;
3、个人推荐的最干净的配置是先MDX-Net再DeEcho-Aggressive。
当您进入界面为,您可以通过拖放文件或指定文件路径来上传音频。建议选择“HP2_all_vocals”作为模型。对于输出音频的文件夹路径,推荐使用默认设置,这样可以避免潜在的错误。设置完毕后,请点击“转换”按钮开始处理。
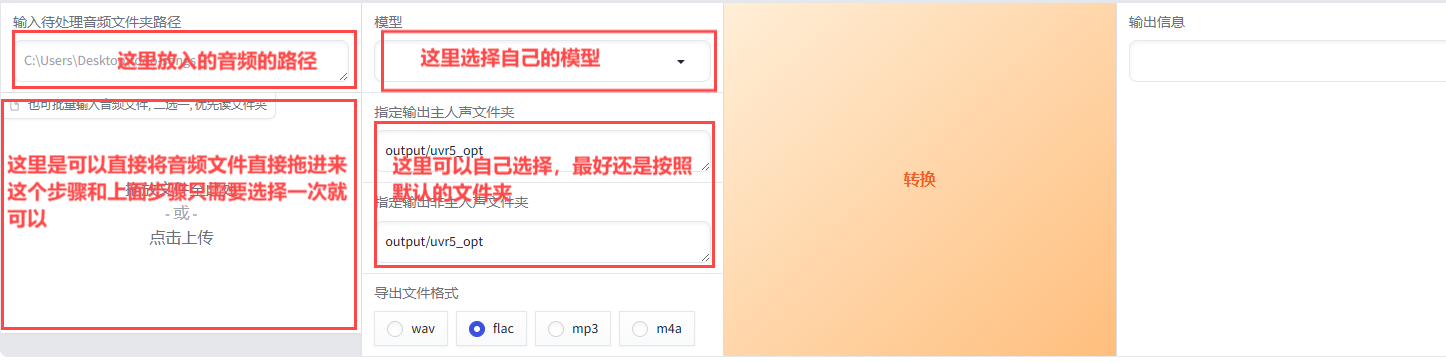
会在对应的目录,比如E:\wuqingtian\Projects\GPT-SoVITS-beta\GPT-SoVITS-beta0706\output\uvr5_opt 生成两端语音,
一个是主人的声音,另外一个是背景声音。
步骤2:分割音频
这个功能主要是对音频进行切割,可以将音频平均分成十几秒的视频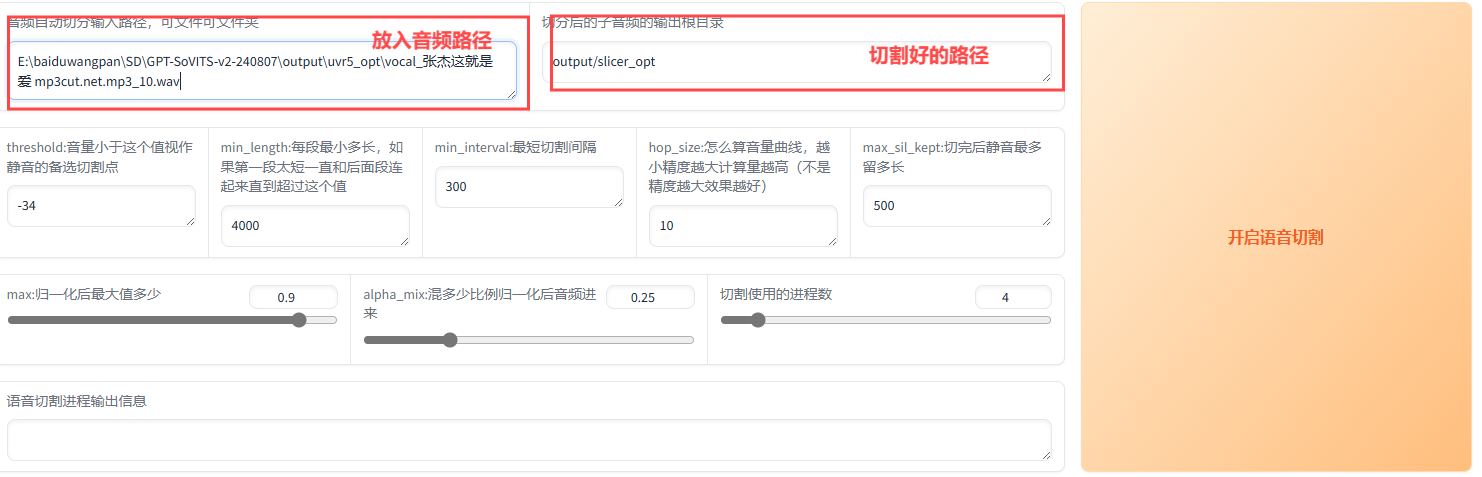
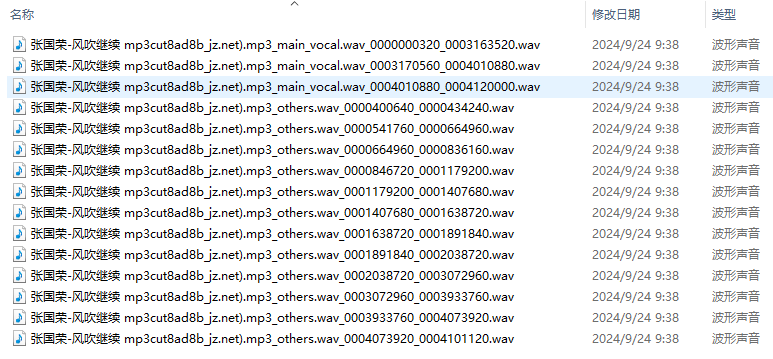
分割好的音频如下:
步骤3:语音降噪

会输出到denoise_opt文件夹下面;
步骤4.语音转文字
进入这个界面,按照要求输入文件路径
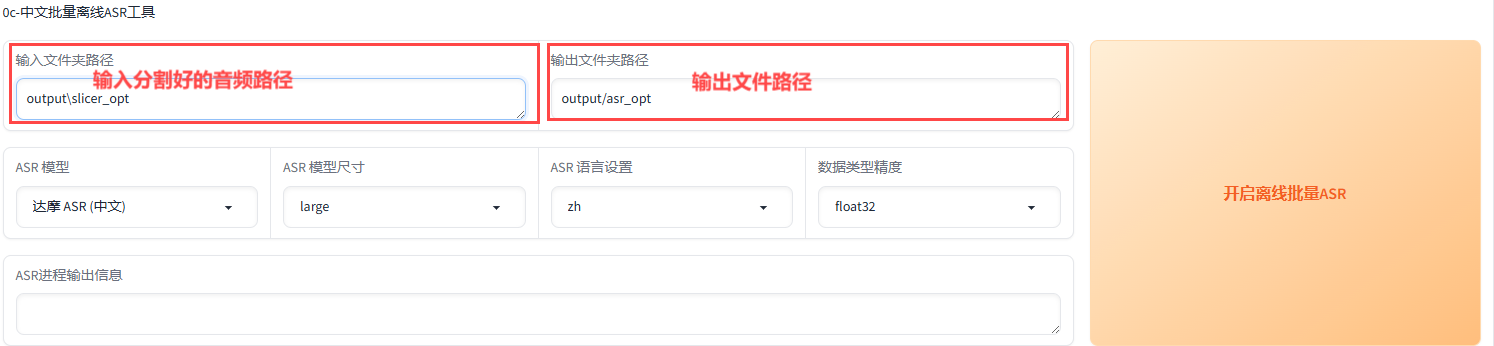
最后输出内容(如果出现文字识别错误直接在记事本里修改即可)
E:\wuqingtian\Projects\GPT-SoVITS-beta\GPT-SoVITS-beta0706\output\denoise_opt\张国荣-风吹继续 mp3cut8ad8b_jz.net).mp3_main_vocal.wav_0000000320_0003163520.wav|denoise_opt|ZH|我劝你早点归去,你说你不想归去,只要我抱着你柔柔海风,轻轻吹冷却摇野火堆。我看见伤心的你,你说我怎舍得去可太幼稚,如何只好只得轻吻你画变,让风继续吹。八将军呢?心里的渴望,希望留下伴着你风继续吹。八、将军呢心里亦有泪,不愿流泪,望着你过去多少快乐给你,何妨与你一起去追。要将忧惑无痛逝去,柔情蜜意,我愿记取。要强硬离情里,没许他向下谁受如伤,未陶醉别离累,始终要下谁。
E:\wuqingtian\Projects\GPT-SoVITS-beta\GPT-SoVITS-beta0706\output\denoise_opt\张国荣-风吹继续 mp3cut8ad8b_jz.net).mp3_main_vocal.wav_0003170560_0004010880.wav|denoise_opt|ZH|我已为你爱哦,你也令我痴痴醉。你在我心不必再问,记着谁流住眼泪。每滴泪为何仍穿着流默墨水的明天?
按照图片要求,最后点击“开启一键三连”
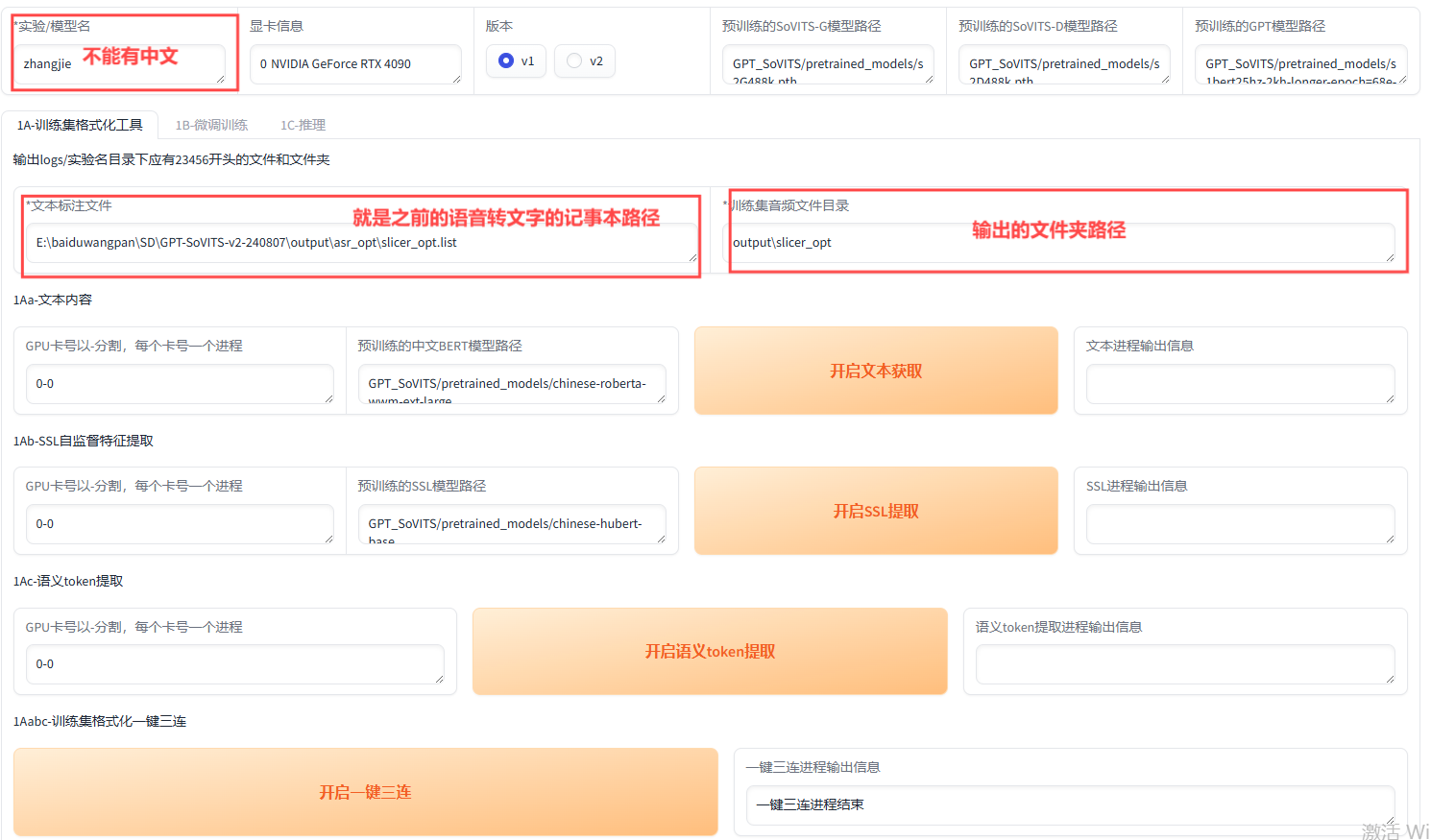
直到提示“一键三连进程结束”,表示1A-训练集格式化工具的过程操作完毕。
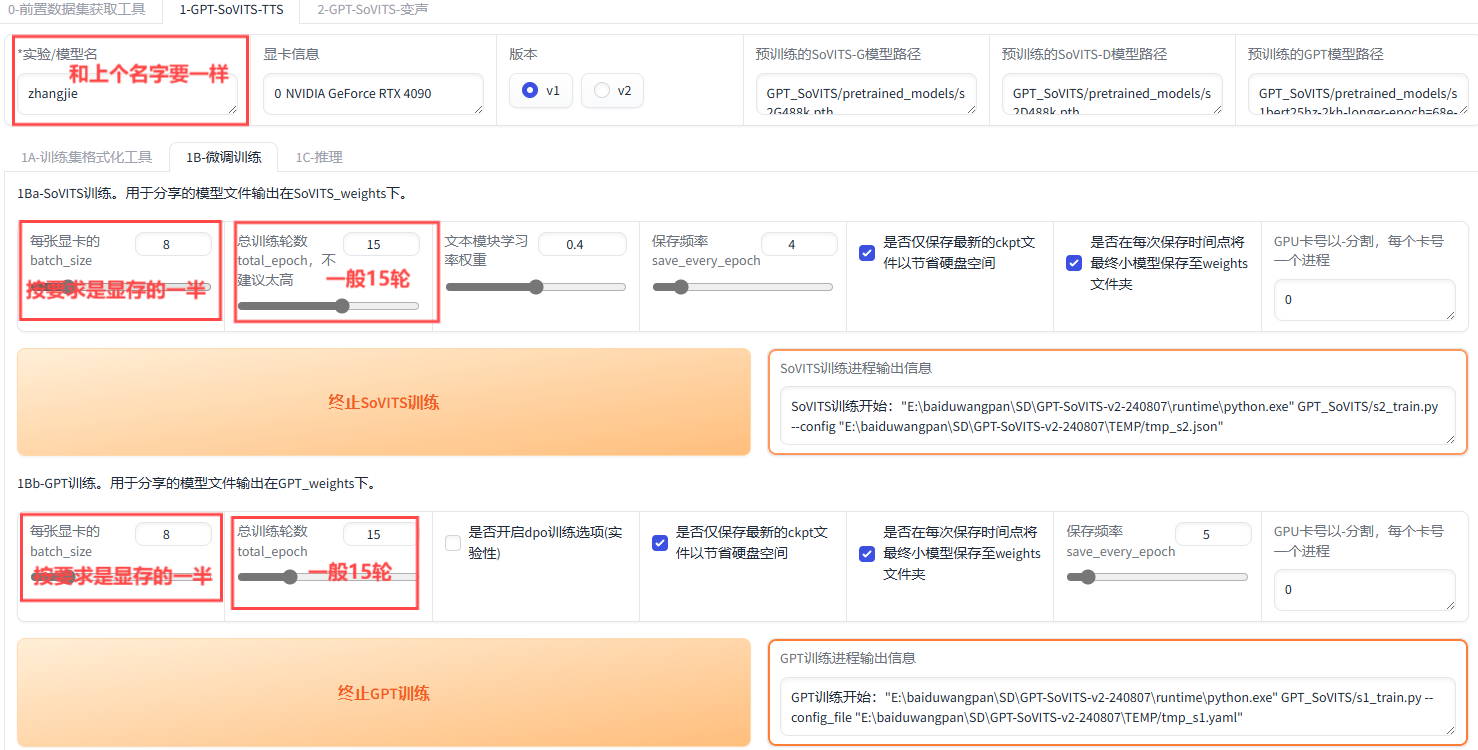
进入1B-微调训练
最后进行训练,点击“开启SoVITS训练”和“开启GPT训练”
5. 1C-推理
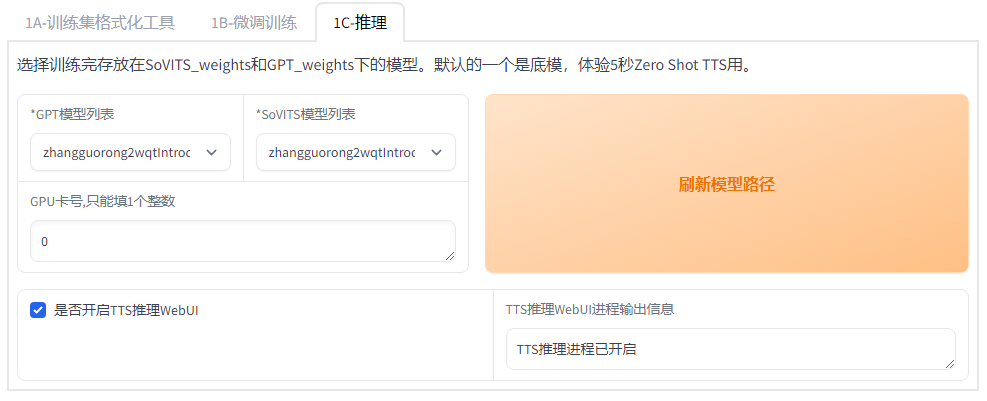
点击“刷新模型路径”,在GPT模型列表下来框会刷新刚才训练好的模型。
勾选“是否开启TTS推理WebUI”,会生成一个新的界面,如果没有弹出新的界面,输入
http://localhost:9872/
即可弹出推理界面。
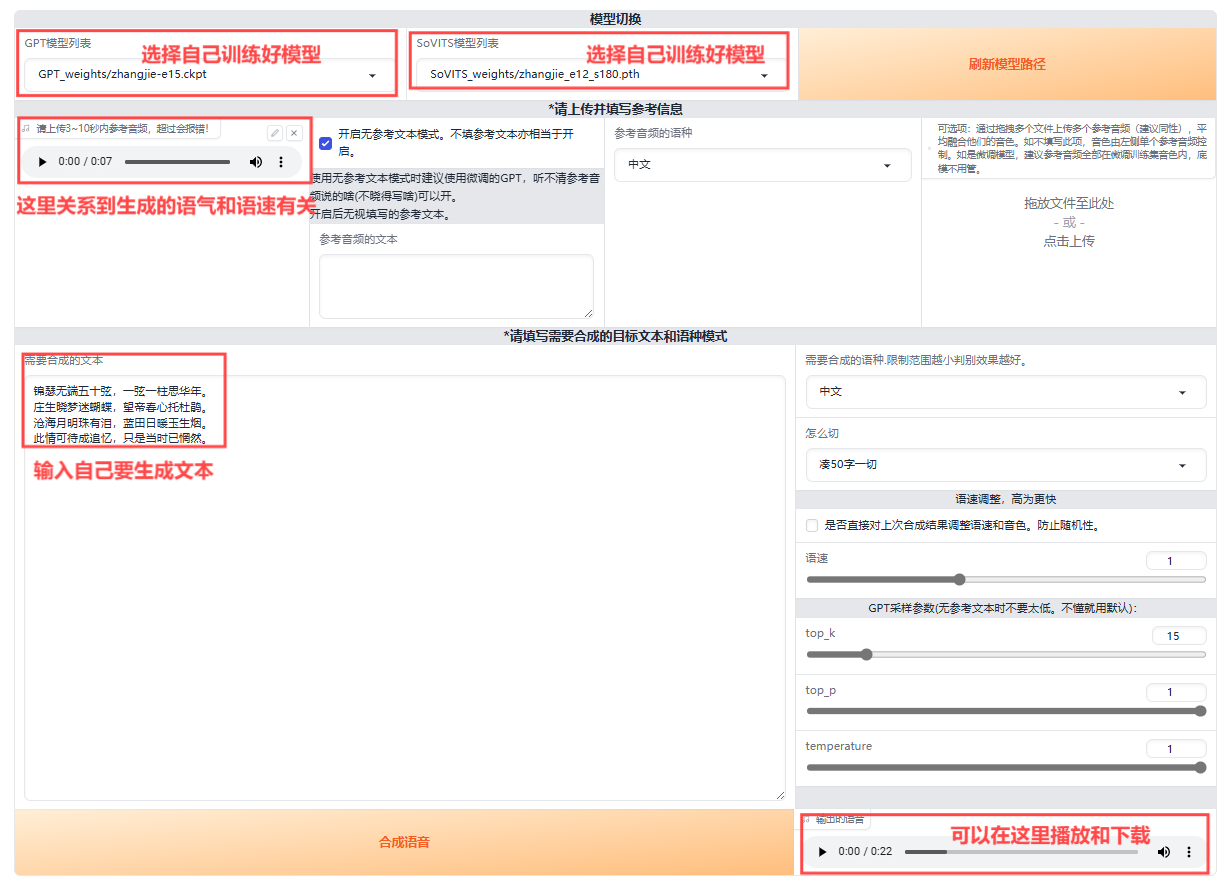
按照图片填充好内容,最后点击“合成语音”
注意:需要上传一段3-10秒的语音,可以通过在线编辑语音:https://vocalremover.org/zh/cutter
三 如何快捷使用
上面的步骤,都是围绕两点展开:
1、如何处理音频,以获得更好的质量;
2、如何训练这个模型;
但是不用训练自己的模型,也是可以快捷使用使用的,直接进入推理界面,采用原始的模型。即:
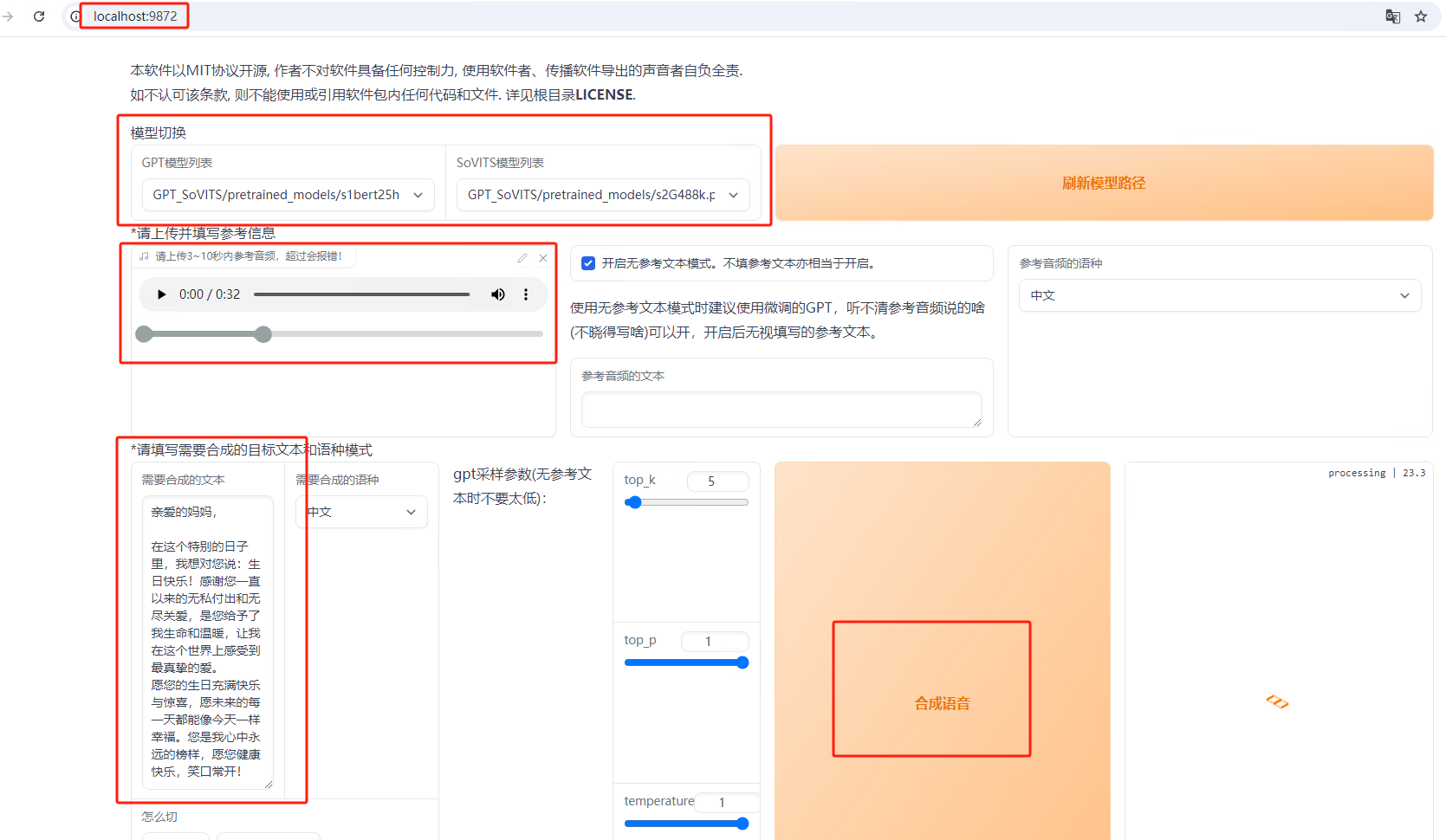
3.1 1C-推理
点击“刷新模型路径”,在GPT模型列表下来框会刷新刚才训练好的模型。
勾选“是否开启TTS推理WebUI”,会生成一个新的界面,如果没有弹出新的界面,输入
http://localhost:9872/
即可弹出推理界面。
总结
至此,由于通过该工具,训练自己的声学模型,并定制文本的播报,这个教程详细做了这方面的说明。该教程,感谢guoqing同学的参与!



















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











