






GPT-SoVITS 是目前市面上最好的语音克隆工具,且开源,虽然用到的所有技术不是最新的,但它开创性的加入了 GPT 模型的机制,并以参考语音作为提示,非常好的解决了语音克隆的声音泄漏问题,生成的语音无论在音质还是真实度上,综合表现都非常不错,也可根据提示语音直接克隆, 就是不需要训练模型,目前支持中、英、日三种语言。特征:
-
零样本 TTS:输入 5 秒语音样本并体验即时文本到语音转换。
-
Few-shot TTS:仅用 1 分钟的训练数据即可微调模型,以提高语音相似度和真实感。
-
跨语言支持:用与训练数据集不同的语言进行推理,目前支持英语、日语和中文。
-
WebUI 工具:集成工具包括语音伴奏分离、自动训练集分割、中文 ASR 和文本标注,帮助初学者创建训练数据集和 GPT/SoVITS 模型。
我们可以克隆自己的声音,减少后续的制作成本,也能克隆一些影视剧角色声音,增加视频的趣味性以及观看性,由于我这台电脑的显卡限制,我导入训练的素材只有四十秒,所以语音的还原度不是很高,但是我看了很多其他博主的测试,如果是原声情况下,自己的声音还原度基本可以以假乱真。
最重要的是,它可以在本地运行,一键部署,在声音训练上面非常简单,几乎可以说是傻瓜式操作,虽然它也有一些弊端和缺点,但是无疑在目前市面上,免费开源能做到这个程度的还是屈指可数!
配置要求
1、Windows系统
需Windows 10/11 系统
支持 CUDA 的 nVIDIA 显卡,每张拥有至少 6G 以上显存
常见的不能使用的显卡:10系以前的所有卡、1060以下,1660以下,2060以下、3050 4G
2、MAC系统
搭载Apple芯片(M系列芯片)或AMD GPU的Mac(如2019款Mac Pro)
macOS 12.3或更高版本
已通过运行xcode-select --install安装Xcode command-line tools
一、下载整合包
打开网址,下载整合包,解压即可用。
网址:https://github.com/RVC-Boss/GPT-SoVITS
下滑到这个选项即可下载:
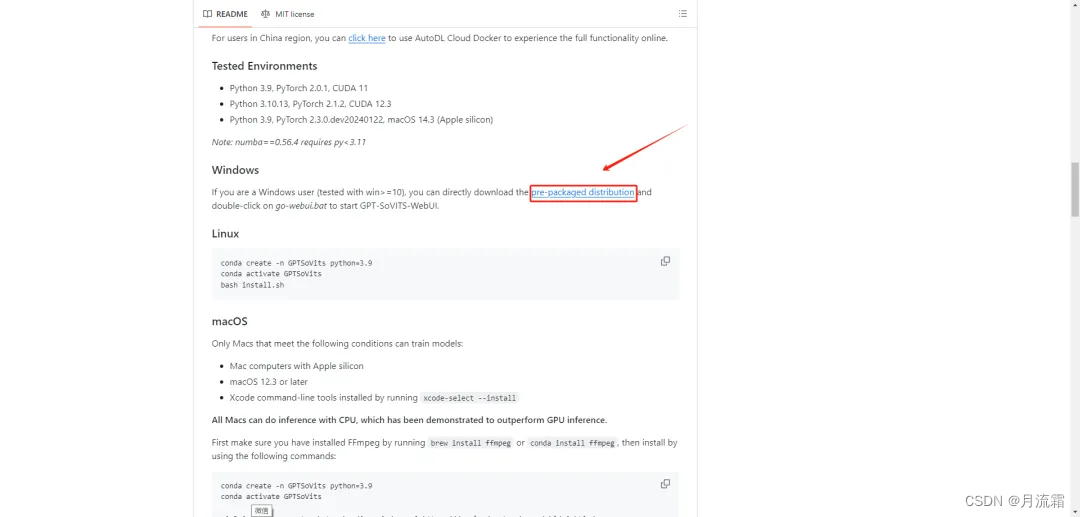
文件大小有 4.3GB,下载好后解压即可,解压后双击这个文件即可运行:
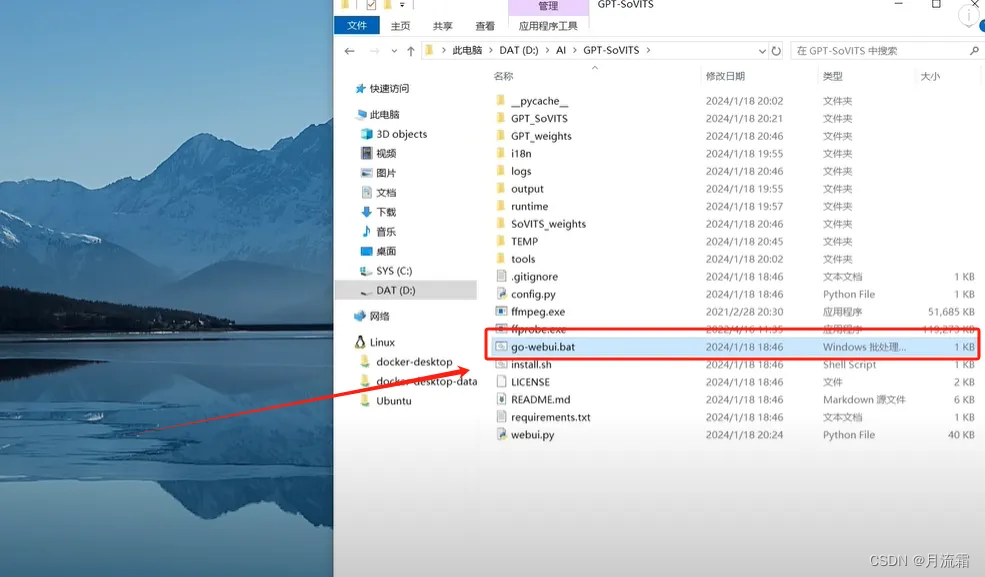
不要关闭运营窗口,保持这个窗口一直运行,你也可以在窗口看到运行的指令以及执行细节:
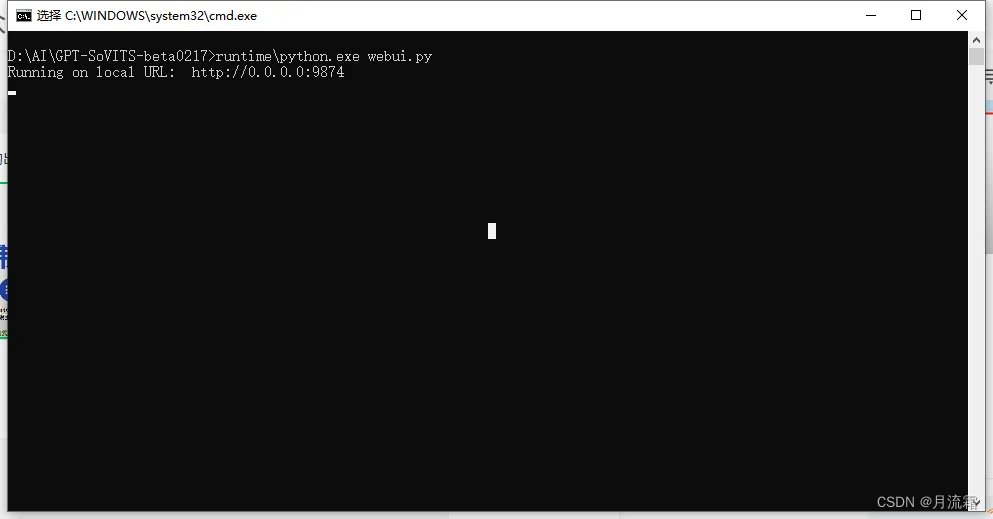
浏览器会自动跳出如下界面,运行界面如下所示:
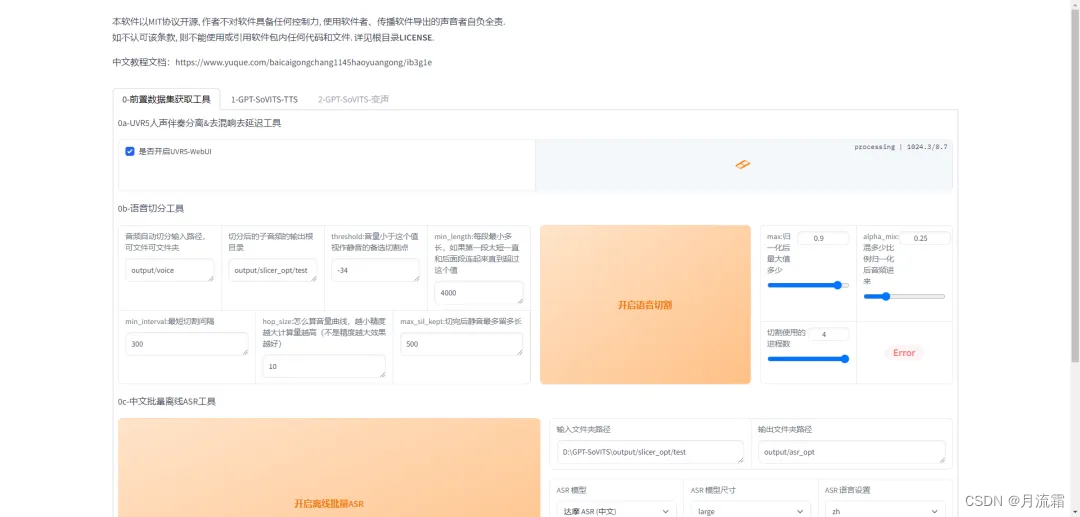
如果你按上面操作无法打开网页界面,那么就是与本地环境冲突,可以尝试手动安装或查看官方的相关文档。
中文教程文档:https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e
二、 声音素材处理
这个环节主要包括声音和背景伴奏声的分离、声音的切片以及声音的标注。
对于声音的剥离他也有对应的工具可以勾选,如果是干声没有背景音乐那么提取处理的效果肯定最好,其次声音切片是将我们上传的素材声音切片成 10 秒左右的短声音片段,然后将我们的声音进行文字识别,最后是完成声音的标注,整体的思路如下:
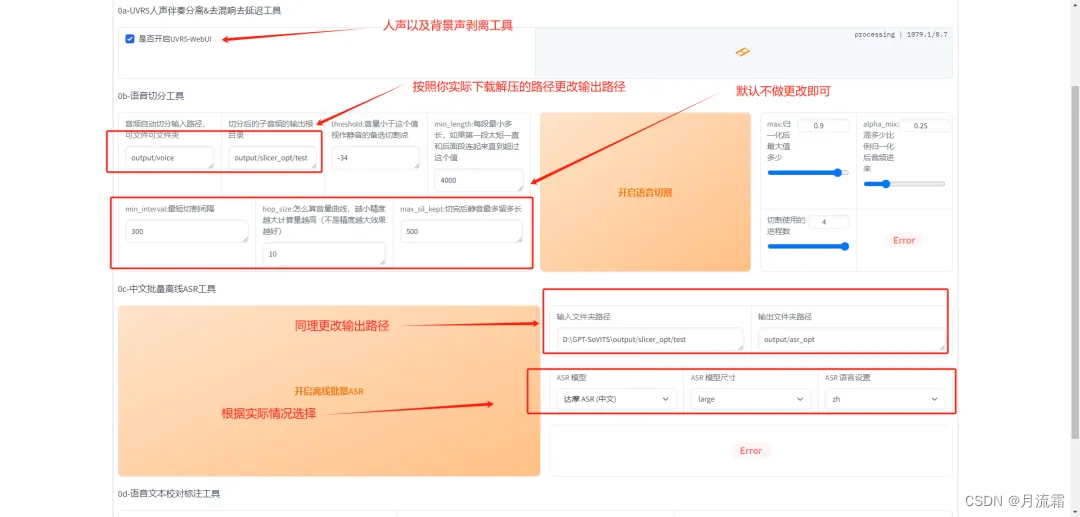
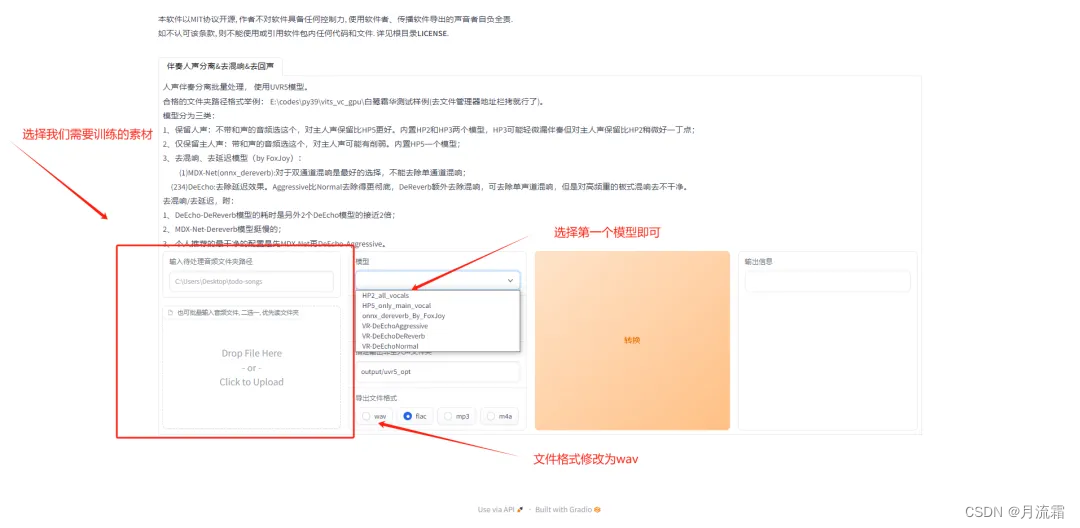
正式步骤:首先:点击第一个开启是否开启 UVR5-WebUI,进入如下界面,因为只支持音频格式,如果是视频,可以先到剪映里面导出音频文件再导入:
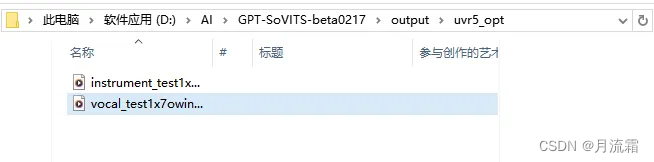
点击转换,等待几分钟或者十几分钟。我们在输出文件夹里面查看这两个文件,一个是背景音乐,一个声音原声:
如果分离出来的声音还是不够清晰,我们再导入,选择第四个为去混响模型,第五个是去延时模型:
最后我们在输出目录里面复制最终的声音文件,名字改短一点。
注意:为避免报错,所有文件名不要包含中文。其次:在语音切割这里,将文件名修改为上述音频的文件夹位置,其他切割的数据都选择默认数值,然后点击“开启语音切割”、“开启离线批量 ASR”:
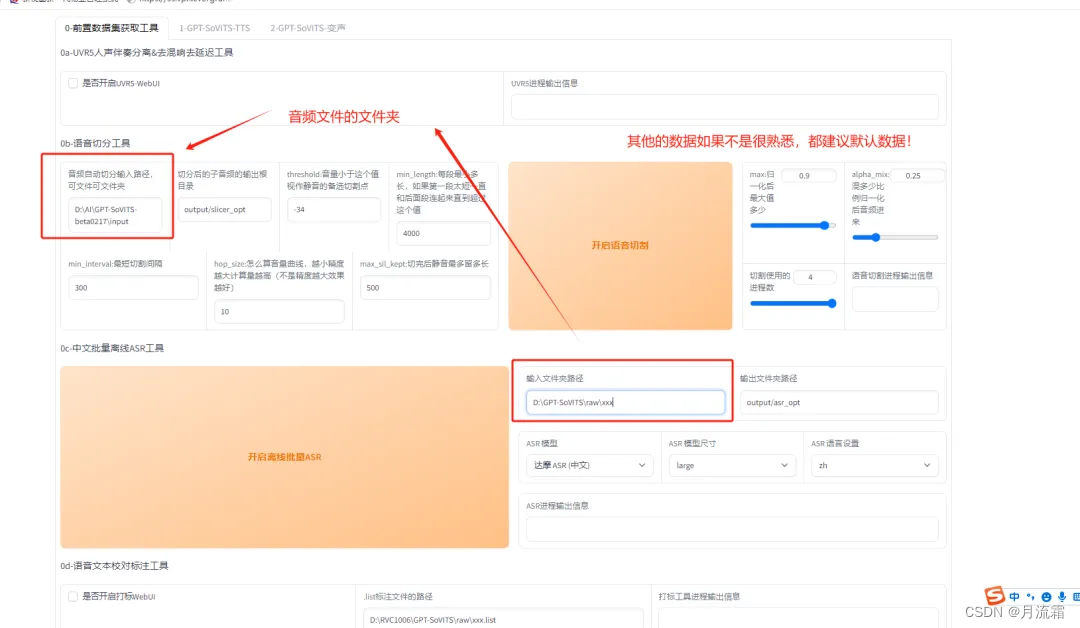
在运行窗口也可以实时看到运行的状况:

最终可以看到一些结束的标志,最后在勾选“开启打标 WebUI”的工具,注意文件名称也要更改为
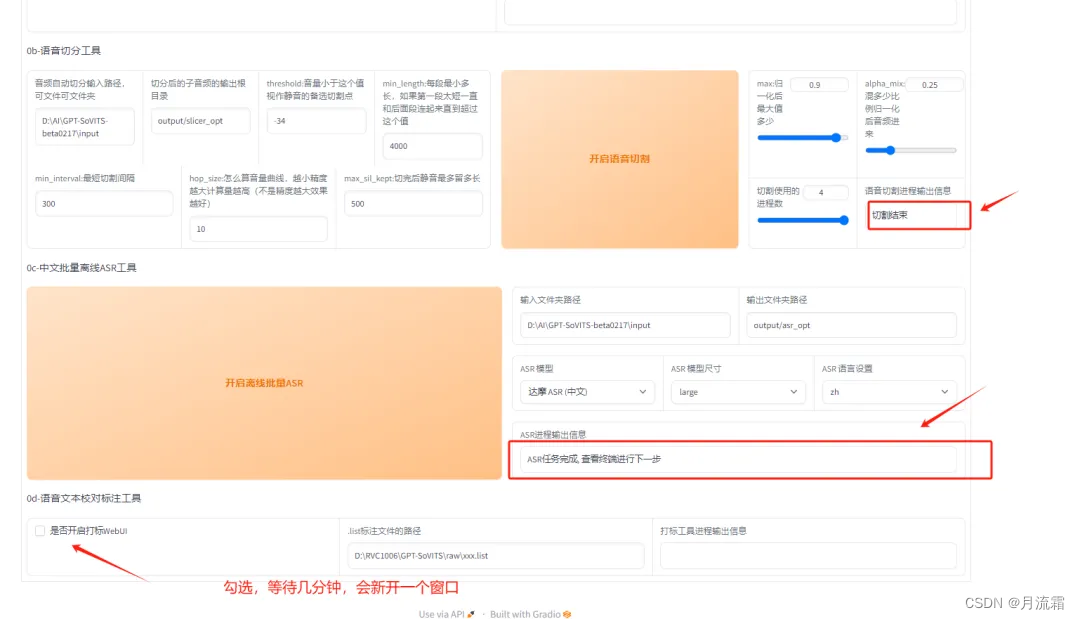
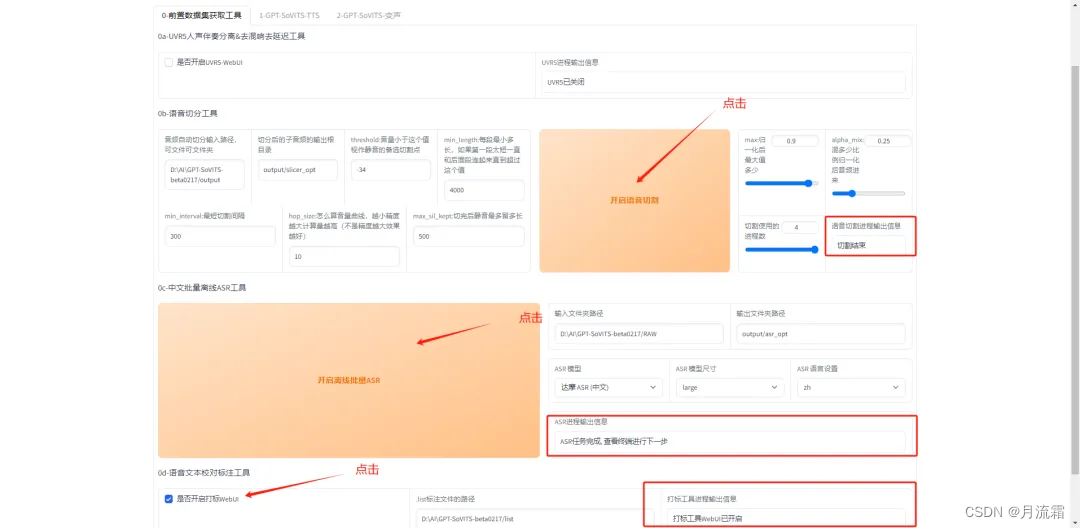
分别点击“开启语音切割”、“开启离线批量 ASR”以及勾选“开启打标 WebUI”的工具:
等待几分钟即可打开新窗口:
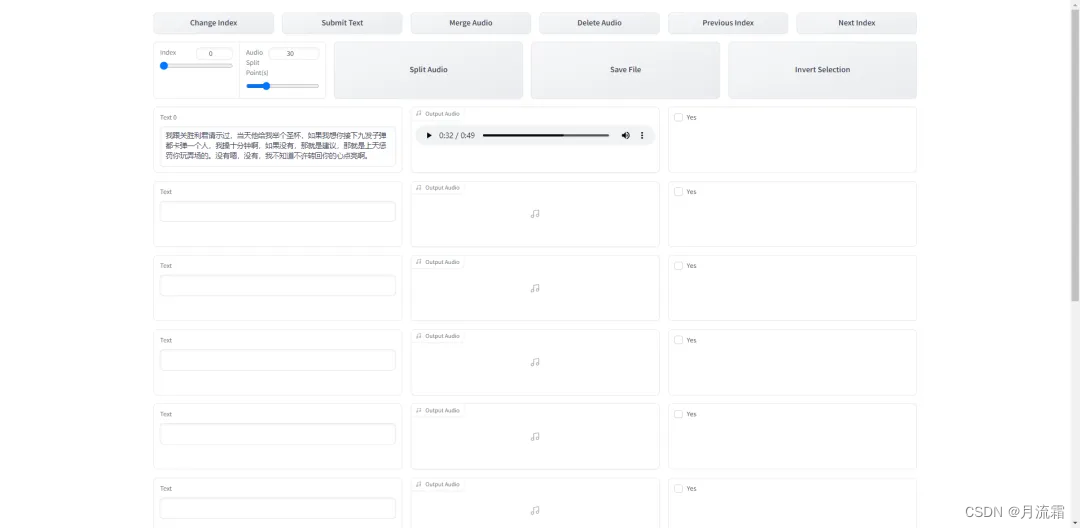
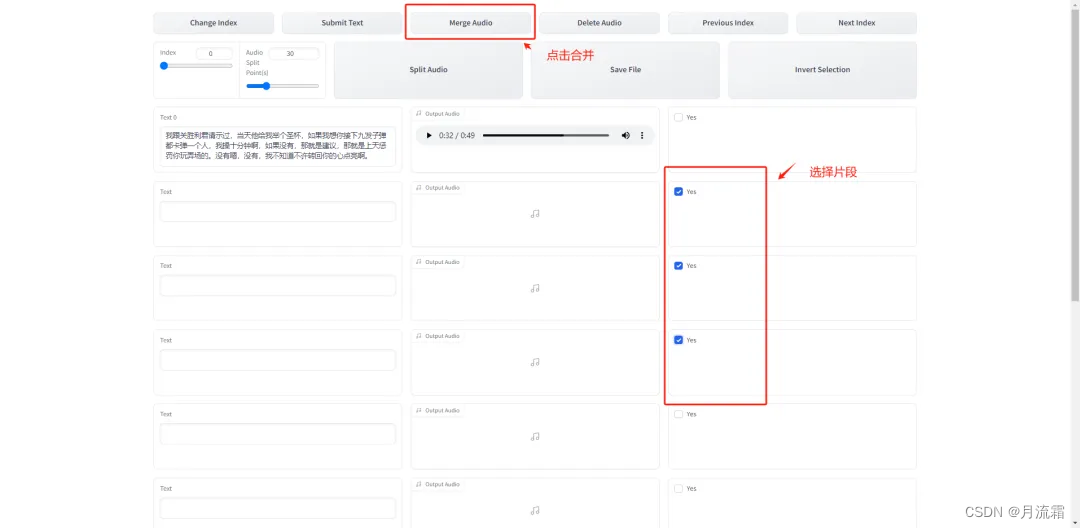
这个窗口实际就是调整每个语段,如果你的输入音频很大,有十几分钟,切割之后可以做一些合并,操作也很简单,选中片段然后点击 Merge Audio,所有调整完之后点击 Save File
接下来进入 GPT-SoVITS-TTS 界面,因为我这台电脑的显卡很一般,所以训练素材选择得很短,且所有的参数调整都是默认,后期你可根据自身的情况,适当改变一些参数,调成生成效果:
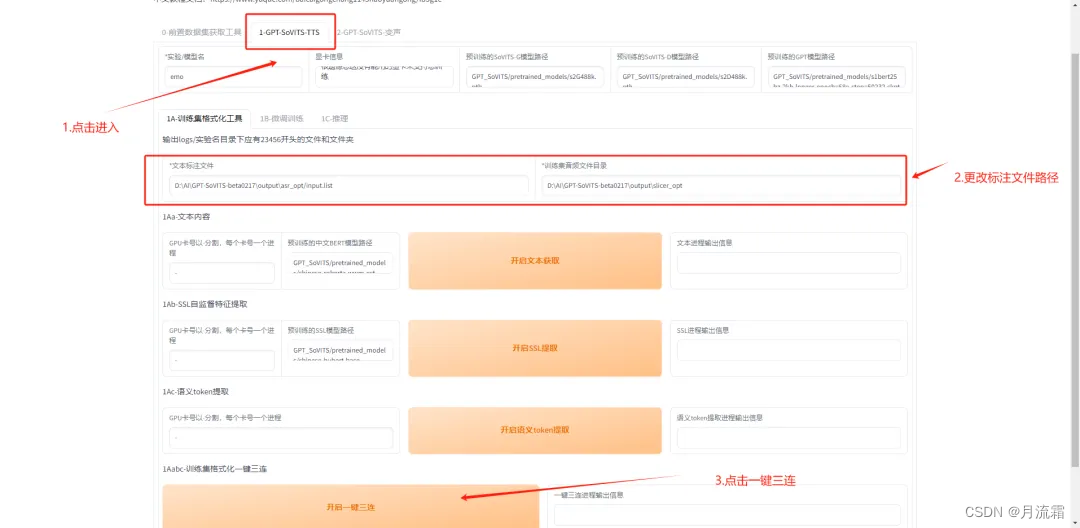
点击微调训练,同理,不熟悉参数的情况下选择默认,然后点击开始训练:

最后用训练好的模型克隆声音,点击推理,并刷新模型:
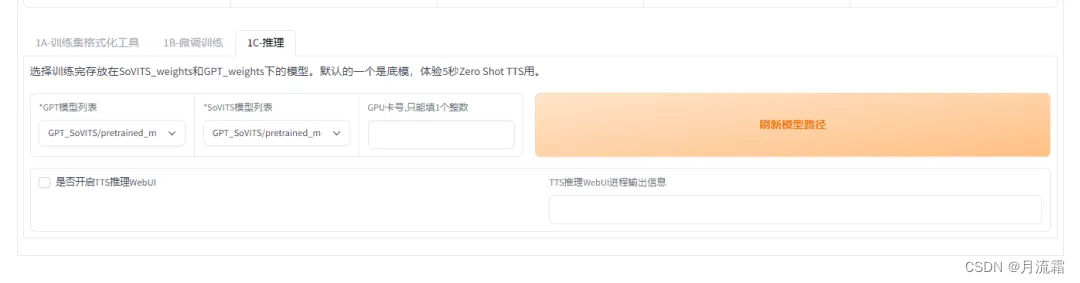
在模型选择下,下拉,选择数值最大的,并勾选下方的是否开启 TTS 推理 WebUI,等待一会儿即可进入新窗口:
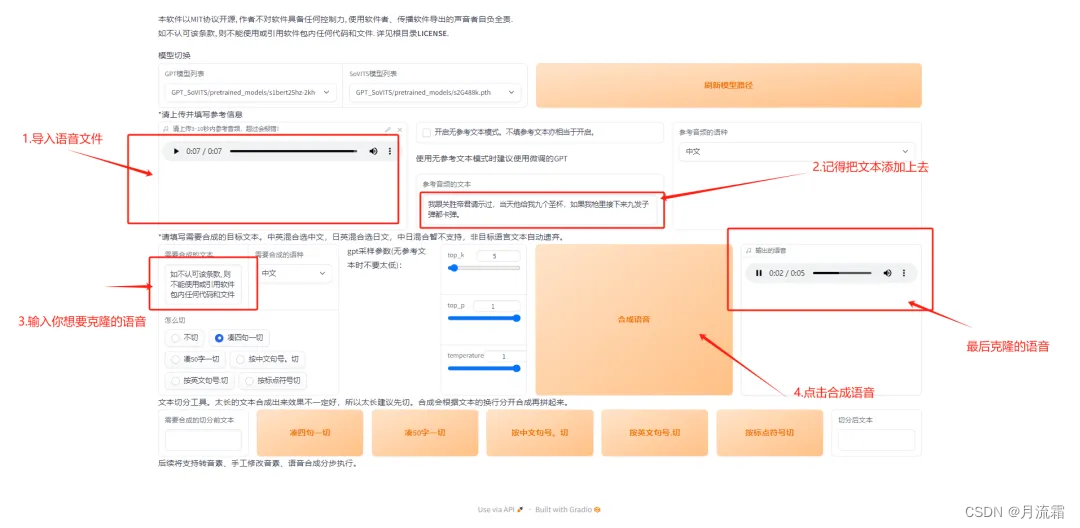
完成
温馨提示:最后生成的语音可直接下载,训练模型期间可能会出现各种报错,记得查看运行窗口,它会记录每一次的运行过程和结果。
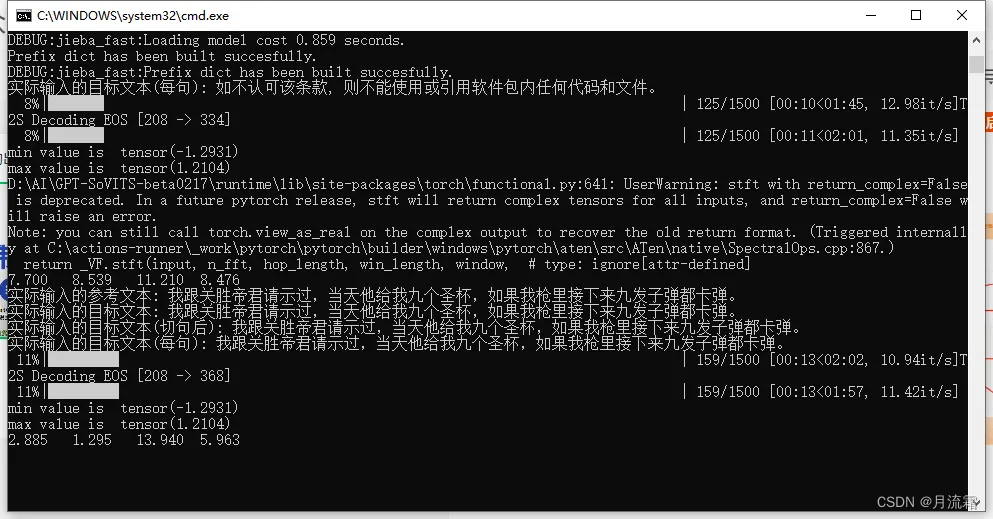
















 2396
2396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











