







Hudi 与 Spark 整合
一、向 Hudi 插入数据
默认 Spark 操作 Hudi 使用表类型为 Copy On Write 模式。Hudi 与 Spark 整合时有很多参数配置,可以参照https://hudi.apache.org/docs/configurations.html配置项来查询,此外,整合时有几个需要注意的点,如下:
-
Hudi 这里使用的是 0.8.0 版本,其对应使用的 Spark 版本是 2.4.3+版本
-
Spark2.4.8 使用的 Scala 版本是 2.12 版本,虽然 2.11 也是支持的,建议使用 2.12。
-
maven 导入包中需要保证 httpclient、httpcore 版本与集群中的 Hadoop 使用的版本一致,不然会导致通信有问题。检查 Hadoop 使用以上两个包的版本路径为:$HADOOP_HOME/share/hadoop/common/lib。
-
在编写代码过程中,指定数据写入到 HDFS 路径时直接写“/xxdir”不要写“hdfs://mycluster/xxdir”,后期会报错“java.lang.IllegalArgumentException: Not in marker dir. Marker Path=hdfs://mycluster/hudi_data/.hoodie.temp/2022xxxxxxxxxx/default/c4b854e7-51d3-4a14-9b7e-54e2e88a9701-0_0-22-22_20220509164730.parquet.marker.CREATE, Expected Marker Root=/hudi_data/.hoodie/.temp/2022xxxxxxxxxx”,可以将对应的 hdfs-site.xml、core-site.xml 放在 resources 目录下,直接会找 HDFS 路径。
1、创建项目,修改 pom.xml 为如下内容
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><scala.version>2.12.14</scala.version><spark.version>2.4.8</spark.version></properties><dependencies><!-- 指定Scala版本,这里使用2.12版本 --><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><!-- 指定HttpClient版本为4.5.2,与Hadoop集群中的版本保持一致($HADOOP_HOME/share/hadoop/common/lib/httpcore-4.4.4.jar),不然通信报错 --><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.2</version></dependency><!-- 指定HttpCore版本为4.4.4,与Hadoop集群中的版本保持一致($HADOOP_HOME/share/hadoop/common/lib/httpclient-4.5.2.jar) ,不然通信报错--><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpcore</artifactId><version>4.4.4</version></dependency><!-- Spark 依赖Jar 包 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>${spark.version}</version><exclusions><exclusion><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId></exclusion><exclusion><groupId>org.apache.httpcomponents</groupId><artifactId>httpcore</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-avro_2.12</artifactId><version>${spark.version}</version></dependency><!--连接Hive 需要的包,同时,读取Hudi parquet格式数据,也需要用到这个包中的parqurt相关类 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>${spark.version}</version></dependency><!-- 连接Hive 驱动包--><dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>1.2.1</version></dependency><dependency><groupId>org.apache.hudi</groupId><artifactId>hudi-spark-bundle_2.12</artifactId><version>0.8.0</version></dependency></dependencies><build><plugins><!-- 在maven项目中既有java又有scala代码时配置 maven-scala-plugin 插件打包时可以将两类代码一起打包 --><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><version>2.15.2</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin><!-- maven 打jar包需要插件 --><plugin><artifactId>maven-assembly-plugin</artifactId><version>2.4</version><configuration><!-- 设置false后是去掉 MySpark-1.0-SNAPSHOT-jar-with-dependencies.jar 后的 “-jar-with-dependencies” --><!--<appendAssemblyId>false</appendAssemblyId>--><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs><archive><manifest><mainClass>com.xxx</mainClass></manifest></archive></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>assembly</goal></goals></execution></executions></plugin></plugins></build>
复制代码
2、编写向 Hudi 插入数据代码
val session: SparkSession = SparkSession.builder().master("local").appName("insertDataToHudi").config("spark.serializer", "org.apache.spark.serializer.KryoSerializer").getOrCreate()//关闭日志// session.sparkContext.setLogLevel("Error")//创建DataFrameval insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\jsondata.json")//将结果保存到hudi中insertDF.write.format("org.apache.hudi")//或者直接写hudi//设置主键列名称.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY,"id")//当数据主键相同时,对比的字段,保存该字段大的数据.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY,"data_dt")S//并行度设置,默认1500.option("hoodie.insert.shuffle.parallelism","2").option("hoodie.upsert.shuffle.parallelism", "2")//表名设置.option(HoodieWriteConfig.TABLE_NAME,"person_infos").mode(SaveMode.Overwrite)//注意:这里要选择hdfs路径存储,不要加上hdfs://mycluster//dir//将hdfs 中core-site.xml 、hdfs-site.xml放在resource目录下,直接写/dir路径即可,否则会报错:java.lang.IllegalArgumentException: Not in marker dir. Marker Path=hdfs://mycluster/hudi_data/.hoodie\.temp/20220509164730/default/c4b854e7-51d3-4a14-9b7e-54e2e88a9701-0_0-22-22_20220509164730.parquet.marker.CREATE, Expected Marker Root=/hudi_data/.hoodie/.temp/20220509164730.save("/hudi_data/person_infos")
复制代码
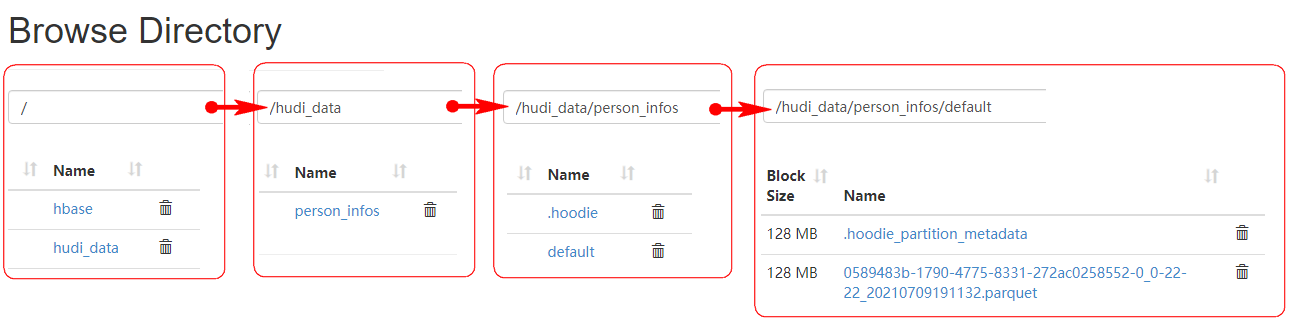
二、指定分区向 hudi 中插入数据
向 Hudi 中存储数据时,如果没有指定分区列,那么默认只有一个 default 分区,我们可以保存数据时指定分区列,可以在写出时指定“DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY”选项来指定分区列,如果涉及到多个分区列,那么需要将多个分区列进行拼接生成新的字段,使用以上参数指定新的字段即可。
1、指定一个分区列
insertDF.write.format("org.apache.hudi").option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id").option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")//指定分区列
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2538
2538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









