






一、Pandas基础
1.pandas的创建
series是一维的带标签的数组;dataframe是二维,series容器。
1)列表创建

2)字典创建

3)series的切片和索引
切片:直接传入平常的切片方法;
索引:选择一个的时候直接传入序号或者index,多个的时候传入序号或者index的列表;




关于对series索引的介绍:利用type查看t.index的类型可以知道是一个可迭代的对象,如此便可以转换成列表的形式进行相关的操作;

关于对series中values的介绍:

Series(带标签的一位数组)主要是通过两个数组构成的,即(index, 索引),一个数组构成的对象的值为values,其中value符合ndarray的很多使用方法。
4)pandas之读取外部数据

二、pandas之dataframe
1.dataframe的创建
1)普通创建方式

其中行索引和列索引可以通过index以及columns参数设置;

如果考虑到dataframe和series之间存在的关系,单独从列和单独从行来看dataframe可以看出,dataframe是由series组成的;这也就是为何说dateframe是series容器的原因。
2)字典创建dataframe

3)列表创建(在读取文档的时候常常会通过此种方式筛选所需维度的数据)

2.dataframe的基础属性
1)关于pd中dataframe索引(index),columns,values的介绍:

2)df.dtypes:列的数据类型;df.ndim:数据的维度;df.shape:数据的形状

3)dataframe整体情况查询
df.head():显示头部的几行信息,其中默认是5行;
![]()
df.tail():显示末尾几行,默认5行;

df.info():显示信息概览:行数,列数,列索引,列非空值个数,列类型,行类型。

df.describe():快速综合统计结果:计数,均值,标准差,最大值,四分位数,最小值:

4)dataframe中的排序
其中在dataframe中排序需要传入by参数(根据那一字段进行排序操作),ascending参数(当False时为降序排列,其中默认为升序排列):

3.pandas之取行或列
pandas取值操作
在方括号中填入数字时表示取行,对行进行操作而在鞋字符串时则是表示取列索引对列进行操作:

df.loc通过标签索引行数据;df.iloc通过位置获取行数据;
1)pandas之loc与iloc


可以看出在对df操作时单独取行操作得到的返回结果为series,而使用行索引列索引一起操作则返回dataframe的结果,在索引时一般不会去最后一个但是在frame当中最后一个值会取到;


在取连续的多行多列的时候并不需要以上的操作保持frame类型,如下操作即可:

2)布尔索引和缺失值处理
‘&’表示且,‘|’表示或:

Pandas中常用的字符串方法:

3)缺失值的处理
首先我们需要介绍pd中的isnull和notnull的方法(判断是否有Nan值):

利用notnull进行取值操作:

Df.dropna的方法(删除Nan所在的行列其中axis参数对行列选中,how参数是any还是all,inplace是否原地操作true或者false):
Df.fillna的方法(对nan的值进行赋值其中的参数可以利用传递的均值中位数df.mean()、df.median()等):

4)Pandas常用统计方法
均值和数量统计:

其中数量统计导演人数的时候还可以使用df.unique()方法:
![]()
当在某一字段中的其中一个字符串包含多种间隔符分割时的统计操作:

利用字典推导式:
![]()
最大值最小值(最大值的位置,最小值的位置):

四、Pandas的分组和聚合
1.字符串的离散化
1)案例展示:


本次案例展示主要是为是的对分类结果的统计直观的陈述。其中最为主要的便是对全为0的df框架进行1的赋值(从8:14段)。
2)数组的合并
首先我们需要构造两个df:

合并之join是利用行索引进行合并的方式(join是连接两个df的常用方式默认为左连接,即以左边连接的df为标准进行连接数据):


合并之merge是利用列索引进行合并的方式(其中merge的默认为交集):

Merge中on参数是选择哪一行进行连接,按照df1的标准如果df1中‘a’列的数字与df3中’a’的内容一样则按照df1的相识数量显示;当然merge中还有一个可选参数how可传递inner(交集),outer(并集),left(左连接:一左边连接为准),right(右连接:以右边连接为准);

3)数据分组
首先读取文件查看文件头信息以及相关数据:



接下来进行分组操作:

通过groupby操作利用by键传递参数获得分组后的分组对象(分组后的对象:1、可以进行迭代操作;2、可以调用聚合方法)
迭代操作:

可以看出每一个分组之后的分组对象的元素是一个元组,而元组当中组成的是分组的组名和组名对应的分组内容;
聚合方法

可以看出使用聚合方法后依旧可以进行df操作;
利用‘Country’分组后找出“CN“并依照省份分组找出每个省份的星巴克数量:

分组聚合的常用方法如下所示:

通过上述了解,如果我们需要对国家和省份进行分组统计的话那样我们又将如何操作呢:其实我们可以:

如下操作为错误(分组后应对series操作):
![]()
因为在选择‘Brand“一列之后属于series操作而此时series中没有country等字段,所以操作分组因如前一幅图所示;

以上所示显示的输出结果是一样的;
4)索引和复合索引
简单的索引操作:
获取index:df.index(可作为一个list迭代对象)
指定index :df.index = ['x','y']
重新设置index : df.reindex(list("abcedf"))
指定某一列作为index :df.set_index("Country",drop=False)(drop参数如果设置成false则会保留原来的df框架)
返回index的唯一值:df.set_index("Country").index.unique()

Swaplevel的应用:

将levels中的前后互换方便取值;
5)Pandas时间序列
时间序列pd.data_range()方法进行时间序列的创作:(参数设置为start(最初开始时间20200526)、end(结束时间)、period(阶段周期),freq(频率即多少次));



以上是创建时间序列的经常使用的频率参数;当然我们也可以使用pd中自带的to_datetime()方法将时间字符串转化成时间序列的形式:
![]()
一般在统计是时间序列的时候经常会用放到df.resample()方法:重采样技术即把一个频次的数据转换成另外一个频次的数据就是重采样,在实践操作过程当中我们往往会使用降采样的方式进行时间序列的统计;

- 总结与实践操作
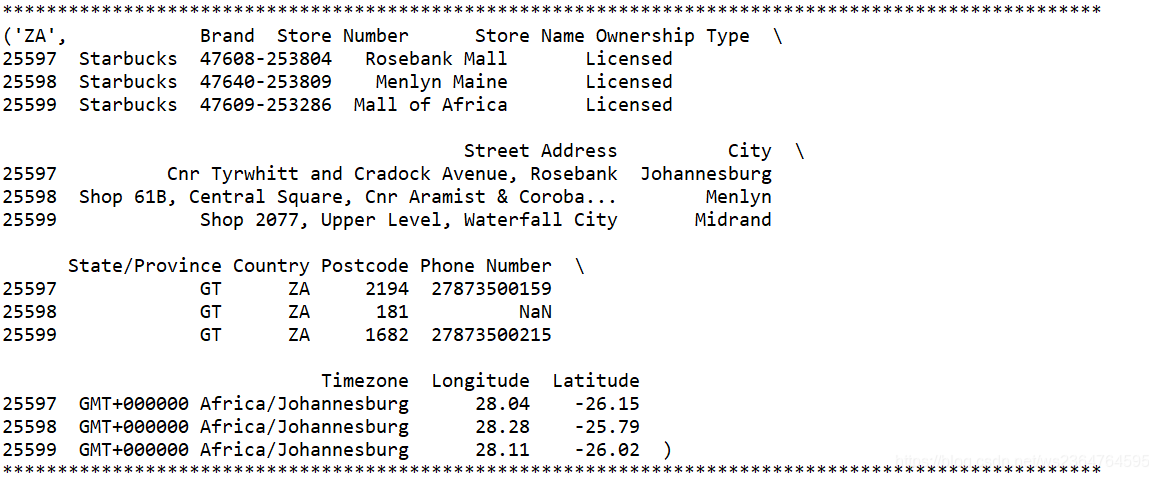
- 案例1(星巴克店铺总数前十排名的国家案例):
- 1)数据结构展示

- 数据分析及图形的绘制


- 案例2(书本每年的平均评分统计)
- 数据展示

- 数据分析及结果展示

















 1526
1526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









