









paper:https://arxiv.org/pdf/2004.11795.pdf
code:https://github.com/LeeSureman/Flat- Lattice-Transformer
前言
本文继续之前的NER词汇增强方式,介绍一下复旦邱锡鹏的佳作FLAT,之前介绍的基于Lattice结构的NER模型(比如Lattice LSTM、LR-CNN)动态引入词汇信息,避免了分词错误带来的级联误差,取得了当时的SOTA效果。然而基于RNN或者CNN的模型都存在一些天生的缺陷,RNN不能并行,不能充分利用GPU性能,而CNN无法捕获长依赖。文本提出了基于Transformer来解决Lattice LSTM中词汇损失问题(每个字符只能获取以它为结尾的词汇信息),并且使用相对位置编码来使得Transformer适应NER。
一、FALT模型:
目前处理Lattice结构一般有两种思路:一种是适配Lattice的输入,比如Lattice LSTM和LR-CNN;另一种就是把Lattice转换为graph结构,然而使用GNN去编码,比如LGN和CGN。然而对于NER模型,序列结构是非常重要的;图结构是通用方法,去做NER模型,作者认为存在不可忽视的差距。
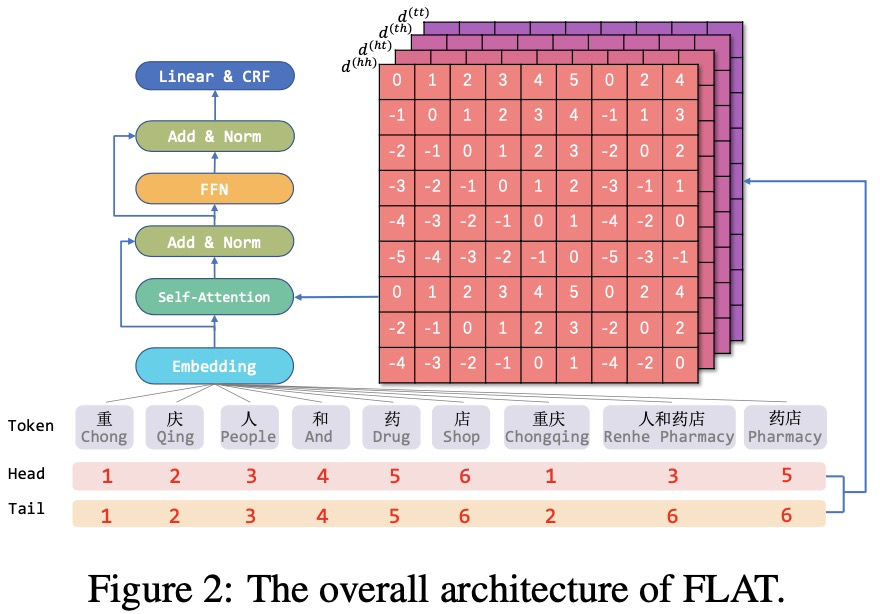
下图Figure1展示了Lattice LSTM和FLAT模型的区别:
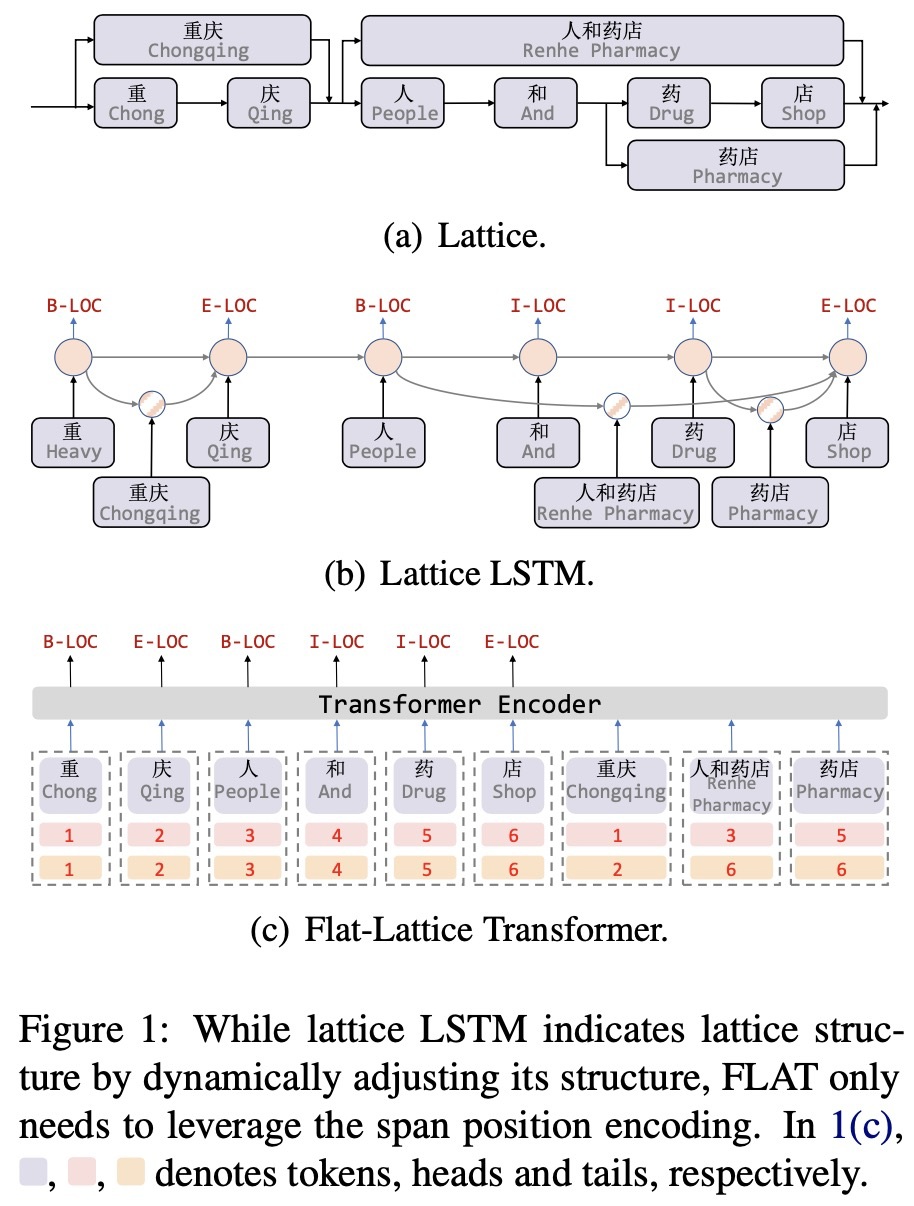
FLAT的结构如上图Figure1(c)所示,每个字符和每个潜在的word使用head和tail两个索引去表示token在输入序列中的绝对位置,head表示开始索引,tail表示结束索引,对于每个字符,head和tail是一样的;每个word是不一样的,比如word“重庆”,head为1,tail为2,说明序列中第一个字符和第二个字符为“重庆”。
二、Transformer子模块
Transformer的encoder模块主要有self-attention,feedforward network(FFN)以及他们之间的residual连接和layer normalization。一般是为了捕获更多的语义信息,会使用Multi-head机制,下面介绍一个head的self-attention机制:
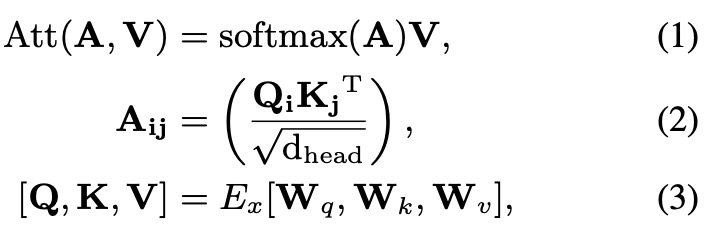
三、FLAT模型的相对位置
每两个span(包括字符和潜在的词)的相对关系有三种:相交intersection、包含inclusion、互斥separation。我们不去直接表示这三种关系,而是使用向量去表示,使用head[i]和tail[i]表示span Xi的开始位置和结束位置,那么对于任意两个span的位置关系就可以表示为如下公式:
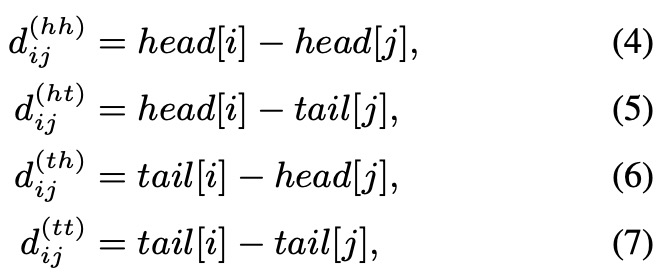
最终的相对位置是把这四个位置向量进行拼接起来,如下:
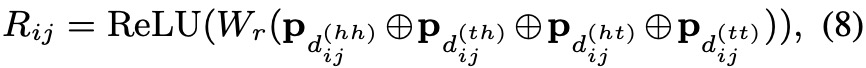
其中

然后根据self-attention计算如下:
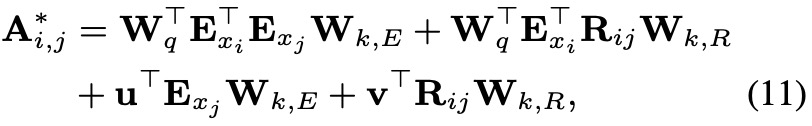
最后使用A∗替换等式(1)的A即可
注意:最后只使用字符向量来作为输出,用于CRF进行解码。
四、FALT完整模型:
五、FALT实验:
5.1、模型实验效果

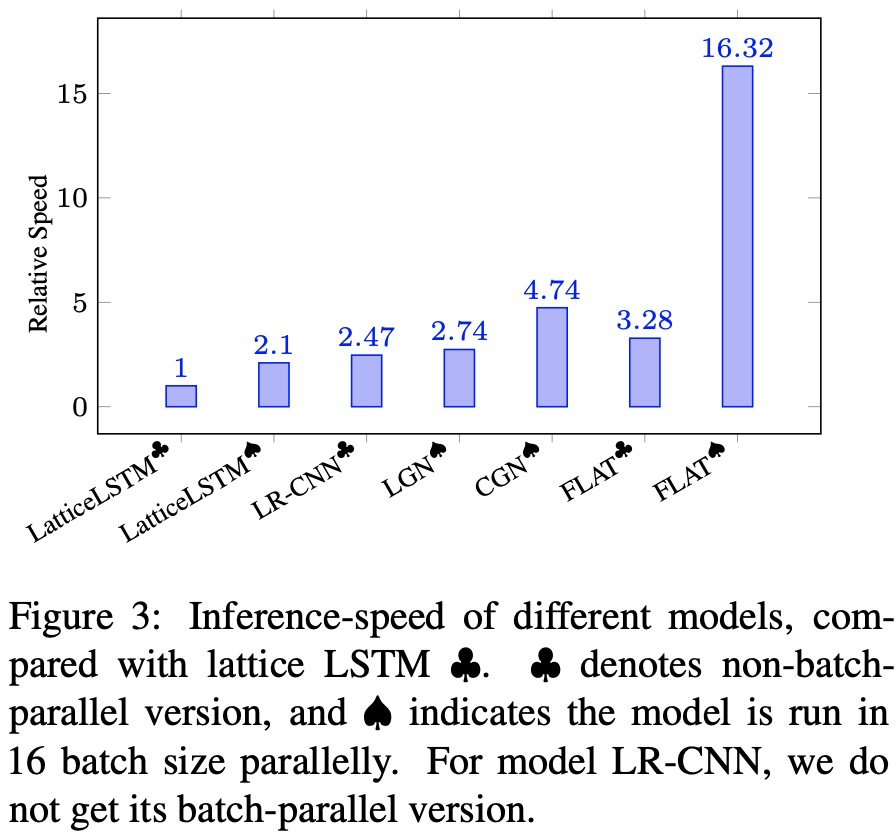
5.2、模型的推理速度
5.3、FLAT与BERT融合
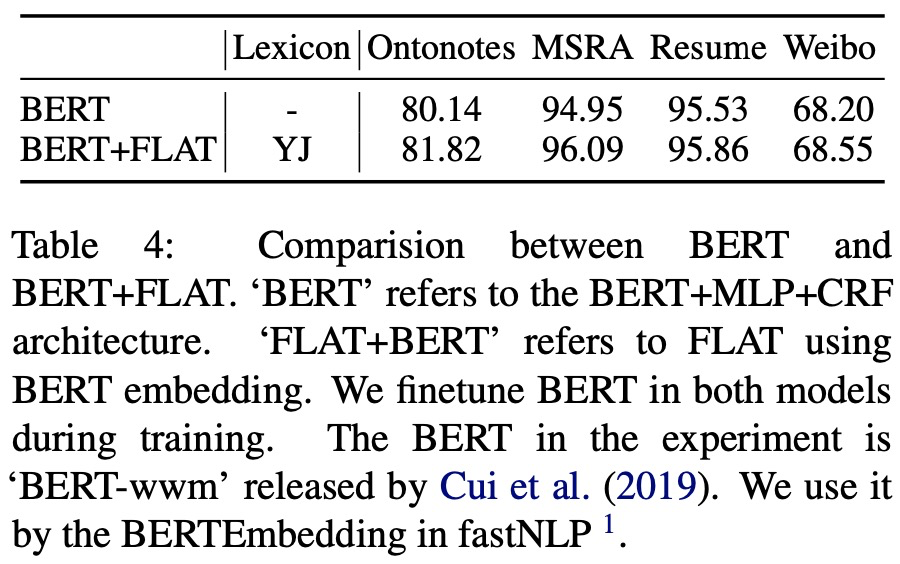
结论:在大数据集上FLAT+BERT优于BERT,小数据集上不太明显。
















 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











