









由于之前做了很多核方法相关的子空间学习算法,本文打算对各种核函数进行一下简要的介绍,希望对大家能够有所帮助。
首先,再对核方法的思想进行描述,核函数的思想是一个伟大的想法,它工作简练巧妙的映射,解决了高维空间中数据量庞大的问题,在机器学习中是对算法进行非线性改进的利器。如下,如果在原空间中,给定的样本数据X是线性不可分的,那么如果我们能够将数据映射到高维空间中,即

那么在高维空间中,样本数据很有可能线性可分,这个特点可以用下图做一个很好的说明:

如左图,红色部分的点为一类数据,黑色部分的点为另一类,在一维空间中,你不可能通过一刀切将两类数据分开,至少需要两刀。OK,这就说明数据分布是非线性的,我们采用高维映射,当然了,例子中只是映射到了二维空间,但已经足够说明问题了,在右图中,完全可以通过沿着X轴方向的一刀切将两类数据分开,说明在二维空间中,数据已经变成线性可分的了。
这个时候,我们就可以采用很多已有的线性算法对数据进行处理,但是问题来了,映射函数具体形式是什么?这个问题的答案是,根本不需要知道映射函数的具体形式,直接对高维数据进行操作吧!
比如说最经典的PCA算法,这部分内容其实是对前一篇帖子的回顾(http://blog.csdn.net/wsj998689aa/article/details/40398777)
PCA在原始空间中的数学模型如下所示:

在高维空间中的形式就是:

我们对其进行简单的变换,我们知道,一个空间中的基向量完全可以用所有的训练样本线性表示出来,即

见证神奇的时刻到了,上式带入上上式,就可以得到如下形式:
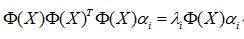
如果你再在等号两侧同时左乘一个东西,就会变成如下形式:
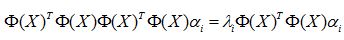
核方法的价值在于如下等式成立,
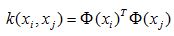
请注意,这个公式表达的意思只是高维空间中向量的内积等于原空间中向量之间的核函数值,根核函数的具体形式没有一毛钱的关系。我们继续,一个样本是这样的,那么矩阵化的形式如下:
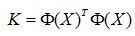
那么PCA就变成了如下形式:
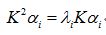
看到没,核方法借用核函数的性质,将高维映射成功的抹掉了。那么什么样的函数才可以被称作为核函数呢?这里大牛们给出了一个著名的定理,称作mercer定理。
Mercer 定理:任何半正定的函数都可以作为核函数。所谓半正定的函数f(xi,xj),是指拥有训练数据集合(x1,x2,...xn),我们定义一个矩阵的元素aij = f(xi,xj),这个矩阵式n*n的,如果这个矩阵是半正定的,那么f(xi,xj)就称为半正定的函数。
请注意,这个mercer定理不是核函数必要条件,只是一个充分条件,即还有不满足mercer定理的函数也可以是核函数。所谓半正定指的就是核矩阵K的特征值均为非负。
本文将遇到的核函数进行收集整理,分享给大家。
线性核是最简单的核函数,核函数的数学公式如下:
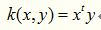
如果我们将线性核函数应用在KPCA中,我们会发现,推导之后和原始PCA算法一模一样,很多童鞋借此说“kernel is shit!!!”,这是不对的,这只是线性核函数偶尔会出现等价的形式罢了。
多项式核实一种非标准核函数,它非常适合于正交归一化后的数据,其具体形式如下:
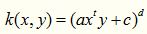
这个核函数是比较好用的,就是参数比较多,但是还算稳定。
这里说一种经典的鲁棒径向基核,即高斯核函数,鲁棒径向基核对于数据中的噪音有着较好的抗干扰能力,其参数决定了函数作用范围,超过了这个范围,数据的作用就“基本消失”。高斯核函数是这一族核函数的优秀代表,也是必须尝试的核函数,其数学形式如下:
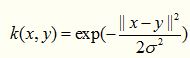
虽然被广泛使用,但是这个核函数的性能对参数十分敏感,以至于有一大把的文献专门对这种核函数展开研究,同样,高斯核函数也有了很多的变种,如指数核,拉普拉斯核等。
指数核函数就是高斯核函数的变种,它仅仅是将向量之间的L2距离调整为L1距离,这样改动会对参数的依赖性降低,但是适用范围相对狭窄。其数学形式如下:
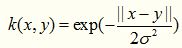
拉普拉斯核完全等价于指数核,唯一的区别在于前者对参数的敏感性降低,也是一种径向基核函数。
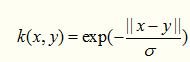
ANOVA 核也属于径向基核函数一族,其适用于多维回归问题,数学形式如下:
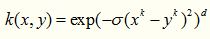
Sigmoid 核来源于神经网络,现在已经大量应用于深度学习,是当今机器学习的宠儿,它是S型的,所以被用作于“激活函数”。关于这个函数的性质可以说好几篇文献,大家可以随便找一篇深度学习的文章看看。
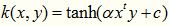
二次有理核完完全全是作为高斯核的替代品出现,如果你觉得高斯核函数很耗时,那么不妨尝试一下这个核函数,顺便说一下,这个核函数作用域虽广,但是对参数十分敏感,慎用!!!!
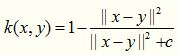
多元二次核可以替代二次有理核,它是一种非正定核函数。
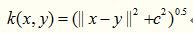
10. Inverse Multiquadric Kernel
顾名思义,逆多元二次核来源于多元二次核,这个核函数我没有用过,但是据说这个基于这个核函数的算法,不会遇到核相关矩阵奇异的情况。
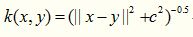
这个核函数没有用过,其数学形式如下所示:
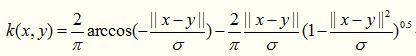
这个核函数是上一个的简化版,形式如下所示
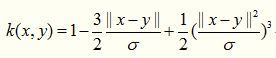
这个核函数没有用过,其适用于语音处理场景。
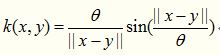
三角核函数感觉就是多元二次核的特例,数学公式如下:
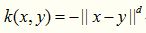
对数核一般在图像分割上经常被使用,数学形式如下:
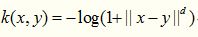
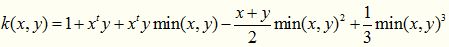
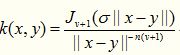
柯西核来源于神奇的柯西分布,与柯西分布相似,函数曲线上有一个长长的尾巴,说明这个核函数的定义域很广泛,言外之意,其可应用于原始维度很高的数据上。
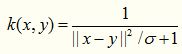
卡方核,这是我最近在使用的核函数,让我欲哭无泪,在多个数据集上都没有用,竟然比原始算法还要差劲,不知道为什么文献作者首推这个核函数,其来源于卡方分布,数学形式如下:
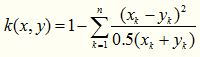
它存在着如下变种:
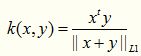
其实就是上式减去一项得到的产物,这个核函数基于的特征不能够带有赋值,否则性能会急剧下降,如果特征有负数,那么就用下面这个形式:
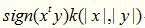
20. Histogram Intersection Kernel
直方图交叉核在图像分类里面经常用到,比如说人脸识别,适用于图像的直方图特征,例如extended LBP特征其数学形式如下,形式非常的简单
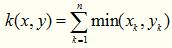
21. Generalized Histogram Intersection
顾名思义,广义直方图交叉核就是上述核函数的拓展,形式如下:
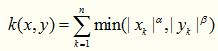
22. Generalized T-Student Kernel
TS核属于mercer核,其数学形式如下,这个核也是经常被使用的
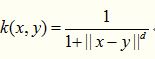















 1165
1165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









