







一、决策树
如何从数据集中构造一颗决策树
决策树构造过程:选择不同属性对决策树进行分裂(生长),让叶子节点中更纯
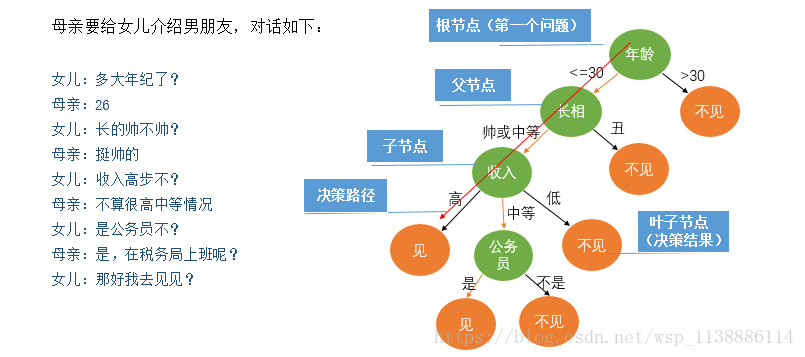
属性分裂-影响
属性类型:
Norminal(类别型)
Ordinal(有序型)
Continiuous(连续型)
分叉数量:
二分叉
多分叉
二、决策树划分依据 –不纯度impurity指标
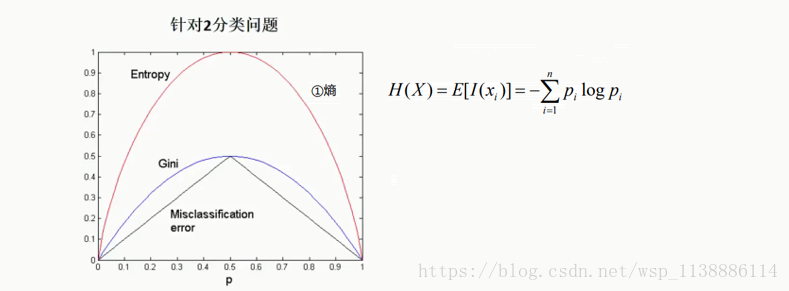
2.1 信息熵
1948年香农(Shannon)提出了信息熵(Entropy)的概念。
假如事件A的分类划分是:(
A1,A2,...,An
A
1
,
A
2
,
.
.
.
,
A
n
),那每部分发生的概率是
pi(i=1,2,3...n
p
i
(
i
=
1
,
2
,
3...
n
),
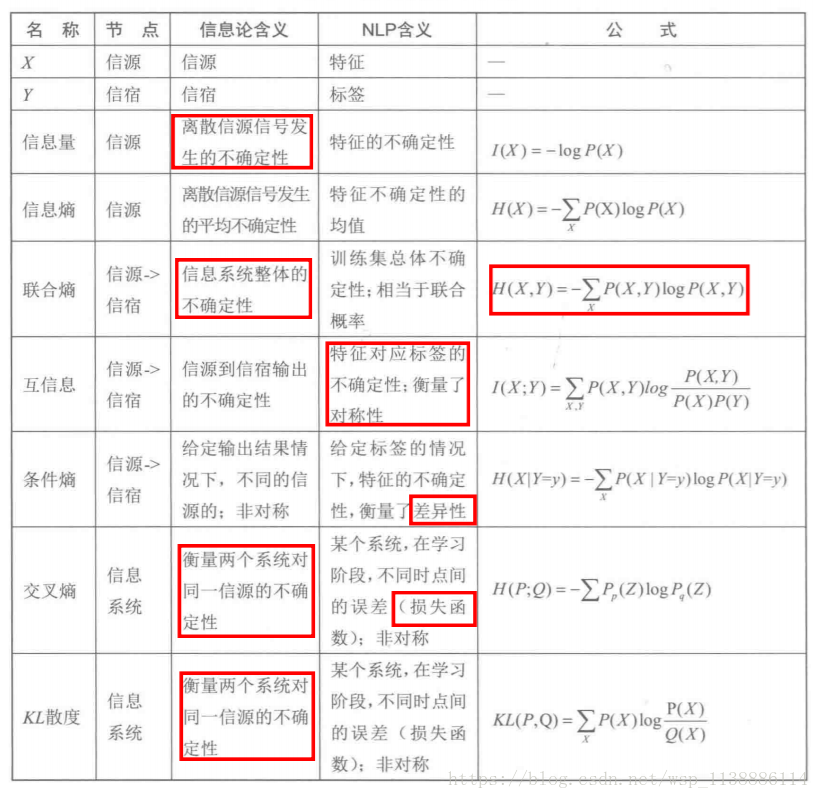
那信息熵Emtropy(A)定义为公式如下:
2.2.条件熵(Conditional Entropy) 与 信息增益(Information Gain)
条件熵
H(Y|X)
H
(
Y
|
X
)
表示在已知随机变量 X 的条件下随机变量 Y 的不确定性。
条件熵 的公式:
当特征变量X被固定后,给系统带来的增益(或者说为系统减少不确定性)为 :
信息增益(information gain)
信息增益Gain缺点:值越多,分叉越多
增益率(GainRatio) :增益比率度量是用前面的增益度量Gain(S,A)和所分离信息度量SplitInformation(如下面例题中的性别,活跃度等)的比值来共同定义的
2.3基尼值Gini(D) 与基尼指数Gini_index
从数据集D中随机抽取两个样本,起类别标记不一致的概率,故,
Gini(D)
G
i
n
i
(
D
)
值越小,数据集 D 的纯度越高。
基尼值Gini(D):
基尼指数Gini_index(D)
一般选择使划分后基尼系数最小的属性作为最优化分属性。
2.4 例题
示例:

三 算法优化
3.1 决策树算法(ID3,C4.5,CART)对比
对比项 ID3 C4.5 CART
目标变量类型 类别型 类别型 类别型,连续型
输入变量类型 类别型 类别型,连续型 类别型,连续型
分叉数量 多叉树 多叉树 二叉树
缺失值处理 不支持 支持 支持
防止过拟合 不支持 支持 支持
| 名称 | 提出时间 | 分支方式 | 是否支持剪枝 | 备注 |
|---|---|---|---|---|
| ID3 | 1975 | 信息增益 | 不支持 | ID3只能对离散属性的数据集构造决策树 |
| CART | 1984 | Gini系数 | 支持 | 可以进行分类和回归,可以处理离散属性,也可以处理连续的。 |
| C4.5 | 1993 | 信息增益率 | 支持 | 优化后解决了ID3分支过程中总喜欢偏向取值较多的属性 |
3.2 DecisionTreeClassifier和DecisionTreeRegressor重要参数对比
| 参数 | DecisionTreeClassifier | DecisionTreeRegressor |
|---|---|---|
| 特征选择标准criterion | “gini”或者”entropy” ,前者代表基尼系 数,后者代表信息增益。一默认”gini” , 即CART算法。 | “mse”或者”mae” ,前者是均方差, 后者是和均值之差的绝对值之和。 默认”mse”比”mae”更加精确。 |
| 特征划分点选择标准splitter | “best”或者”random”。前者在特征的所有划分点中找出最优的划分点。后者 是随机的在部分划分点中找局部最优的划分点。 默认的”best”适合样本量不大的,而如果样本数据量非常大,此时决策树构 建推荐”random”。 | 同 DecisionTreeClassifier |
| 划分时考虑的最大特征数 max_features | 可使用很多种类型的值,默认”None”划分时考虑所有的特征数; “log2”划分 时最多考虑log2N个特征; 如果是”sqrt”或者”auto”意味着划分时最多考虑 | 同 DecisionTreeClassifier |
3.3 决策树剪枝(防止过拟合)
为什么要剪枝:
随着树的增长, 在训练样集上的精度是单调上升的, 然而在独立的测试样例上测出的精度先上升后下降。原因1:噪声、样本冲突,即错误的样本数据。 原因2:特征即属性不能完全作为分类标准。(数据中属性不全) 原因3:巧合的规律性,数据量不够大。预剪枝(Pre-Pruning)
设置规则避免过度生长: 信息增益(率)少于阈值,不再分裂 节点样本少于阈值(例如1%)不再分裂 如果分裂后的叶子节点样本数少于阈值(0.5%例如)就不能分裂 树的深度大于阈值(例如8层)就不再分裂后剪枝(Post-Pruning)
先让决策树生长成一棵大树(过拟合) 从下往上依次判断:如果剪掉子树,能否让验证集误差下降,若可以就剪 主要有四种: (1)REP-错误率降低剪枝 (2)PEP-悲观剪枝 (3)CCP-代价复杂度剪枝 (4)MEP-最小错误剪枝
四 DecisionTree方法 代码演示
sklearn.tree.DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
DecisionTreeClassifier(
criterion = 'gini',
splitter = 'best',
max_depth = None,
mix_samples_split = 2,
mix_samples_leaf = 1,
min_weight_fraction_leaf = 0.0,
max_features = None,
random_sample_leaf = 1,
max_leaf_nodes = None,
min_impurity_split = 1e-07,
class_weight = None,
presort = False
)
一些重要的参数:
criterion --gini,'emtropy' 最佳分类标准
max_depth --树深
min_samples_split --节点继续往下分裂最小样本要求
min_samples_leaf --叶子节点的最小样本数要求
min_impurity_split --预剪枝时节点不纯度'impurity',低于此阈值就不在分裂
#决策树可视化
sklearn.tree.export_graghviz
把决策树模型导出为DOT格式,然后可以可视化查看
from IPython,display import Image
import pydotplus
dot_data = tree.export_graghviz(
dtree,
out_file = None,
feature_names = iris.feature_names,
class_names = iris.target_names,
filled = True,rounded = True,
special_characters = True
)
graph = pydotplus.gragh_from_dot_data(dot_data)
Image(gragh.crate_png())


















 1753
1753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











