







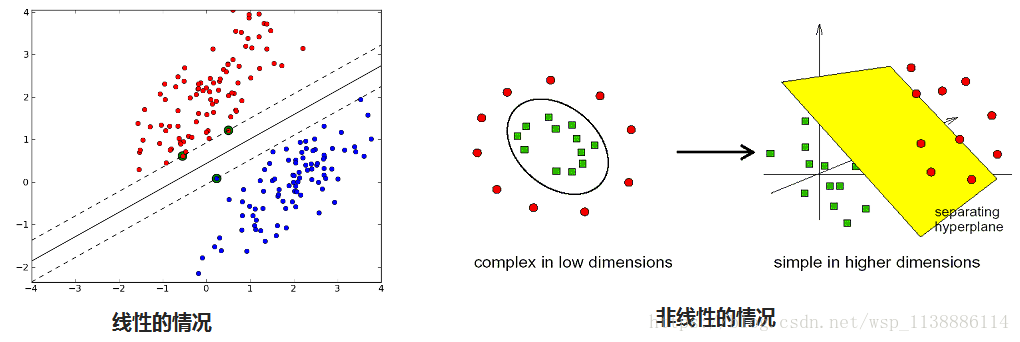
一、SVM 概念
- 将样本的两种特征用 一条直线或者超平面分开,并且间隔最大。
- 非线性问题,因为其复杂性,需要使用复杂模型,参数多,容易过拟合,而 SVM既能解决复杂问题,又不容易过拟合(但不能保证不会过拟合)
二、支持向量机算法基本原理
2.1 线性 SVM
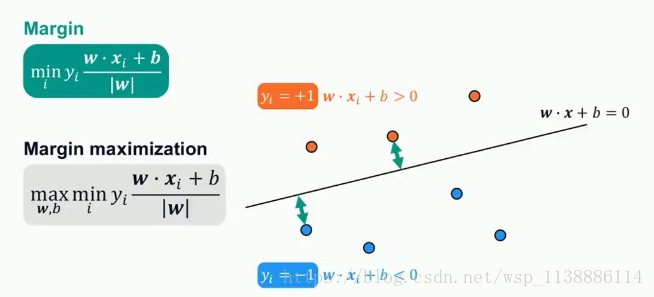
线性(SVM):找到最好的决策边界
最大化 Margin: 决策边界最近的距离
最小的Margin之和最大化
2.1 非线性(SVM)超平面
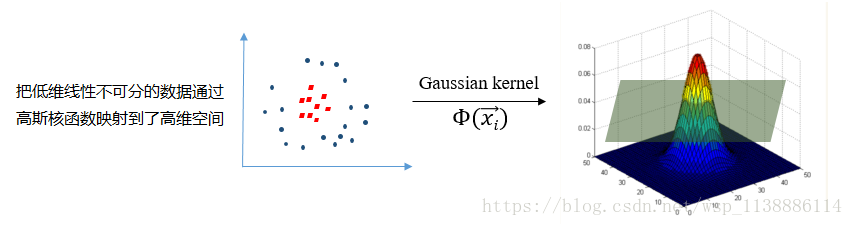
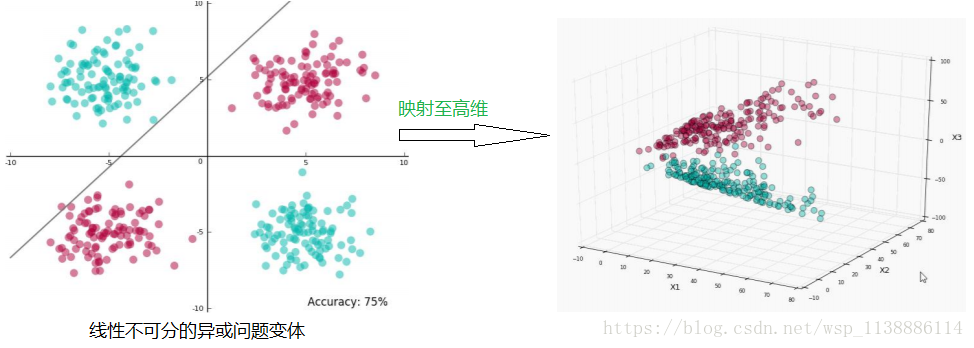
低维映射到高维再处理,找到最优的(核方法)
一条直线方程,其中m是斜率,c是直线在y轴的截距:y= mx +c
二维空间里面,一条直线的方程可以表示为:Ax+By+C=0
三维空间里面,平面的方程可以表示为:Ax+By+Cz+D=0
那么超平面方程:
其中 w 和 x 是向量,w^T是两个向量的点积。向量w通常被称为权重。
w , x皆为向量, wx+b=0就是a1*x1+a2*x2+...an*xn+b=0
2.2 超平面公式推导
超平面之间的距离

样本点到超平面之间的距离
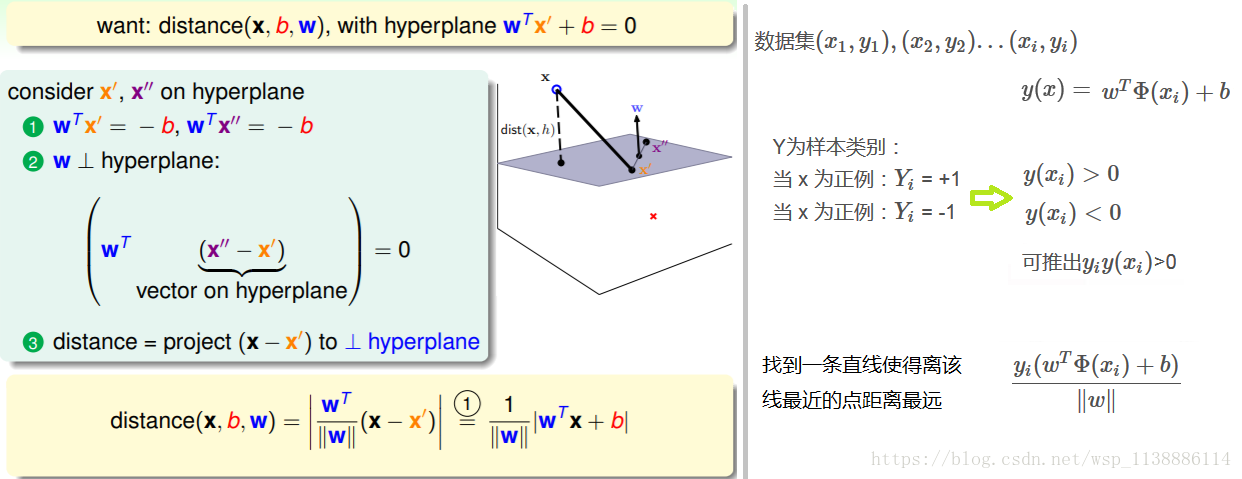
样本的正确分类 - 拉格朗日方法(对偶算法):
- 约束最优化问题
对于线(w,b)可以通过缩放使得其结果值|y|>=1 yi(wTΦ(xi)+b)⩾1 y i ( w T Φ ( x i ) + b ) ⩾ 1
argmaxw,b{1∥w∥mini[yi(wTΦ(xi)+b)]} a r g m a x w , b { 1 ‖ w ‖ m i n i [ y i ( w T Φ ( x i ) + b ) ] }
即(目标函数): argmaxw,b1∥w∥ a r g m a x w , b 1 ‖ w ‖ 且 yi(wTΦ(xi)+b)⩾1 y i ( w T Φ ( x i ) + b ) ⩾ 1
转换成求最小值:argminw,b12w2 转 换 成 求 最 小 值 : a r g m i n w , b 1 2 w 2 且 yi(wTΦ(xi)+b)⩾1 y i ( w T Φ ( x i ) + b ) ⩾ 1
- 拉格朗日乘子法标准格式:
minf(x) m i n f ( x )
s.tgi(x)⩽0,i=1,2...m s . t g i ( x ) ⩽ 0 , i = 1 , 2... m - 样本正确分类(拉格朗日方法):
- f(x)=wTx+b f ( x ) = w T x + b
- 构造拉格朗日方程:
s.t.yi(wTx+b)≥1, i=1,2,3...m s . t . y i ( w T x + b ) ≥ 1 , i = 1 , 2 , 3... m
gi(x)=1−yi(wTxi+b)≤0, i=1,2,3...m g i ( x ) = 1 − y i ( w T x i + b ) ≤ 0 , i = 1 , 2 , 3... m
L(w,b,α)=12||w||2+∑mi=1αi(1−yi(wTxi+b)) L ( w , b , α ) = 1 2 | | w | | 2 + ∑ i = 1 m α i ( 1 − y i ( w T x i + b ) )
2.3 拉格朗日乘子法-超平面推论





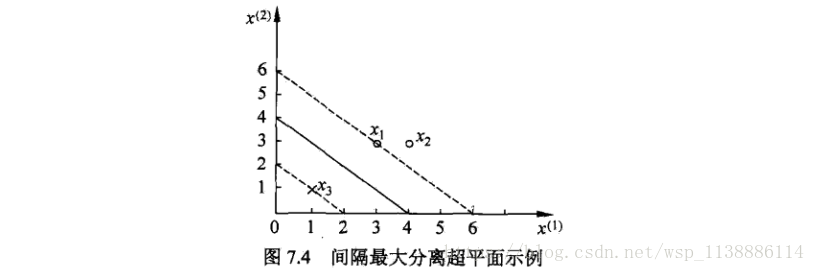
2.4 示例:拉格朗日乘子法求超平面
例题:已知如图训练集:
正例点
x1=(3,3)T,x2=(4,3)T,负例点x3=(1,1)T
x
1
=
(
3
,
3
)
T
,
x
2
=
(
4
,
3
)
T
,
负
例
点
x
3
=
(
1
,
1
)
T
。
试求最大间隔分离超平面。


2.5 松弛因子



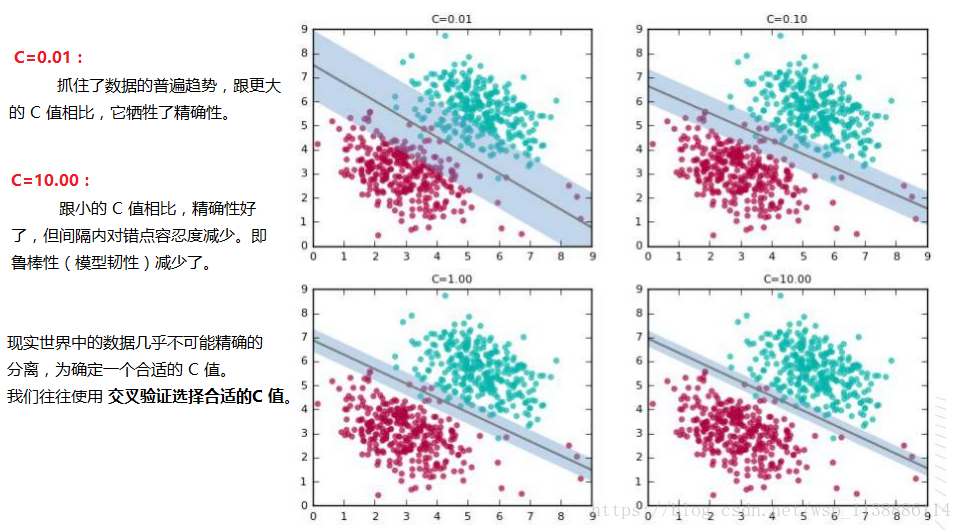
在 SVM 中设定一个参数「C」;从而你可以在两种结果中权衡:
1. 拥有很宽的间隔;
2. 精确分离训练数据;
C 的值越大,意味着在训练数据中允许的误差越少。
必需强调一下这是一个权衡的过程。如果想要更好地分类训练数据,那么代价就是间隔会更宽。
以下几个图展示了在不同的 C 值中分类器和间隔的变化(未显示支持向量)。
三、核函数
-
核函数特点
-
如果数据集中有 n 个点,SVM 只需要将所有点两两配对的点积以寻找分类器。仅此而已。
当我们需要将数据映射到高维空间的时候也是这样, 不需要向 SVM 提供准确的映射,
而是提供映射空间中所有点两两配对的点积。
3.1 核函数定义
假设X是输入空间,H是特征空间,存在一个映射ϕ使得X中的点x能够计算得到H空间中的点h ,对于所有的X中的点都成立:
若x,z是X空间中的点,函数k(x,z)满足下述条件,那么都成立,则称k为核函数,而ϕ为映射函数:
3.2 常用核函数
-
线性核
-
线性核,主要用于线性可分的情况,我们可以看到特征空间到输入空间的维度是
一样的,其参数少速度快,对于线性可分数据,其分类效果很理想。
K(xi,xj)=xTi,xj K ( x i , x j ) = x i T , x j
多项式核
-
将低维的输入空间映射到高纬的特征空间,但是多项式核函数的参数多,当多项式的阶数比较高的时候,核矩阵的元素值将趋于无穷大,计算复杂度会大到无法计算。(d≥1为多项式的次数)
K(xi,xj)=(xTi,xj)d K ( x i , x j ) = ( x i T , x j ) d
高斯(RBF)核函数
-
高斯径向基函数是一种局部性强的核函数,可以将一个样本映射到一个更高维的空间内,该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能,(相对于多项式核函数参数要少)。
因此大多数情况下在不知道用什么核函数的时候,优先使用高斯核函数多项式核。
(σ ( σ >0 为高斯核的宽带)
K(xi,xj)=exp(−||xTi,xj||22σ2) K ( x i , x j ) = e x p ( − | | x i T , x j | | 2 2 σ 2 )
sigmoid核函数
-
采用sigmoid核函数,支持向量机实现的就是一种多层神经网络。
(tanh为双曲正切函数,β>0,θ<0)
K(xi,xj)=tanh(βxTixj+θ) K ( x i , x j ) = t a n h ( β x i T x j + θ )
核函数选择依据
-
如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM;
如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数;
如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。
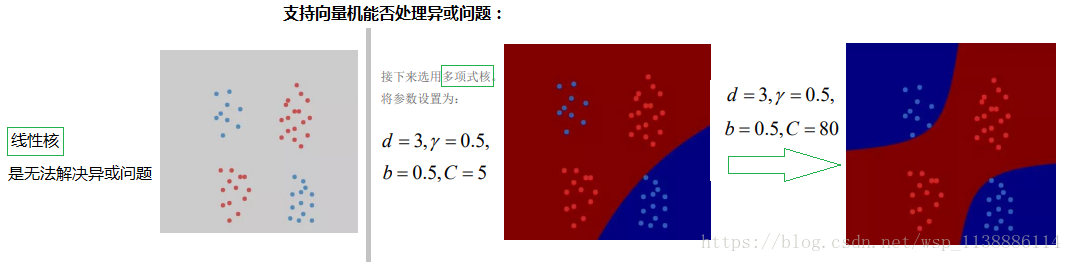
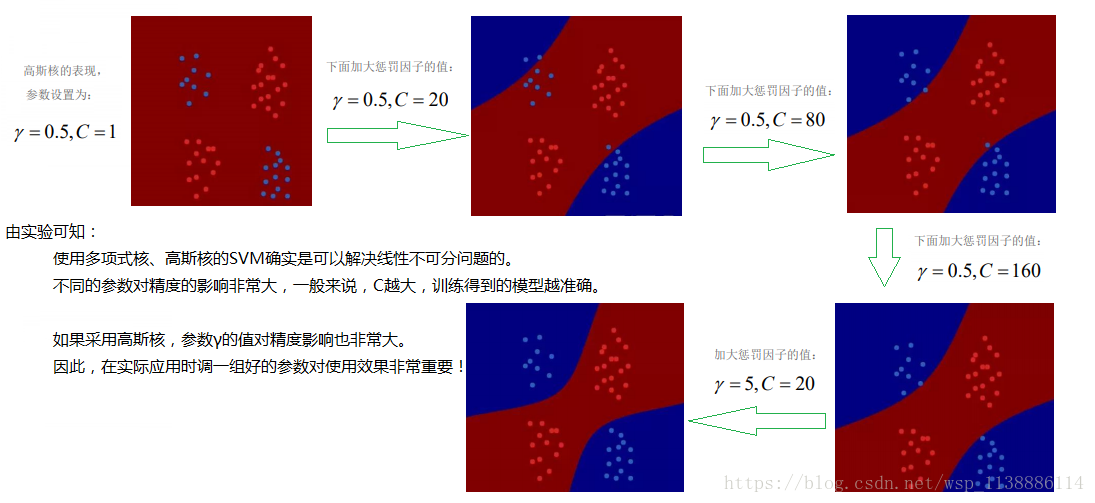
3.3 核矩阵

对于一个二位空间 映射到 三维空间:
P(x,y)=(x2,2–√xy,y2)
P
(
x
,
y
)
=
(
x
2
,
2
x
y
,
y
2
)
考虑到核函数:
K(v1,v2)=<v1,v2>2,
K
(
v
1
,
v
2
)
=<
v
1
,
v
2
>
2
,
即“内积平方”
设二维空间存在:
v1=(x1,y1),v2=(x2,y2)
v
1
=
(
x
1
,
y
1
)
,
v
2
=
(
x
2
,
y
2
)
两点:
可证
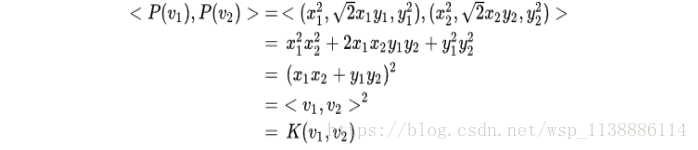
三、支持向量机代码演示
from sklearn.svm.import SVC
svc = SVC(
C = 1.0,
lernel = 'rbf',
degree = 3,
gamma = 'auto',
coef0 = 0.0,
shrinking = True,
probability = False,
tol = 0.001,
cache_size = 200,
class_weight = None,
verbose = False,
max_iter = -1,
decision_function_shape = None,
random_state = None
)
一些重要的参数:
C --误差项惩罚参数,C越大,越容易过拟合
kernel --核参数,'linear','poly','rbf','sigmoid'
gamma --当kernel为'poly','rbf','sigmoid'时,默认1/n_feature四、支持向量机参数优化
parameters = {
'C':[0.001,0.01,0.1,1,10,1000],
'kernel':['linear','poly','rbf','sigmoid']
'gamma':[0.0001,0.001]
}
svm= SVC()
grid_search = GridSearchCV(svm,parameters,scoring = 'accuracy',cv = 5)
grid_search.fit(x,y)五、支持向量机总结
支持向量机是一个‘超平面分类算法’
最佳超平面-->支持向量Margin(间隔)最大的超平面
支持向量就是离超平面最近的数据点
数据低维--kernel() -->高维,使其线性分开
SVM 主要参数调优:C,gamma,kernel
SVM只支持数值型变量,分类型变量-->onehot编码
SVM对缺失值敏感,需提取处理
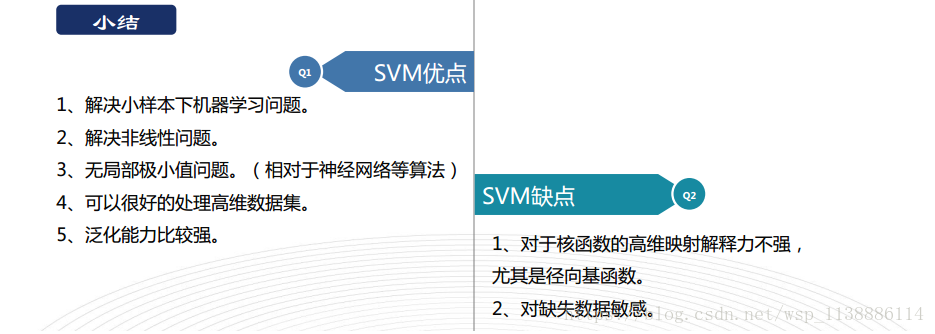
SVM没有处理缺失值的策略(决策树有)。而SVM希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要。缺失特征数据将影响训练结果的好坏。















 738
738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











