







文章目录
一、自然语言处理
1.1 分词简介
- 自动文本分类:给定分类体系,将文本划分到某一个或者某几个类别中
-
分类模式:
-
二分类模式,属于或不属于(binary)
多分类模式,有多个分类,属于其中某一个分类(multi-class)
可拆分成多个二分类问题
多标签问题,一个文本可以属于多个类别(multi-label)
-
文本分类的应用
垃圾邮件的判定: 垃圾邮件、非垃圾邮件
新闻频道分类(案例):经济、体育、娱乐、政治
词性标注: 动词、名词、形容词
情感识别: 正向评论、负向评论
1.2 分词算法:三大类
- 基于词典、词库匹配的方法: 正向(逆向)最大匹配
- 基于规则、知识理解的方法: 短语结构、文法
- 基于统计、机器学习的分词方法: 隐马尔科夫、最大熵模型、条件随机场
1.3 词特征表示 (Bag of Words----Word2Vec)
-
词袋模型(Bag of Words)
-
从语料库中使用一些方法选择一堆词作为文本的特征(通常用TF-IDF)
所有文章都只保留这些被选中的词
维数很大,数据很稀疏
词嵌入模型(Word2Vec)
-
把文章的词映射到一个固定长度的连续向量
维数较小,通常为100 ~ 500
意义相近的词之间的向量距离较小
1.4 分类算法
使用一般分类问题的分类算法即可:
如:朴素贝叶斯;逻辑回归;支持向量机(SVM);决策树
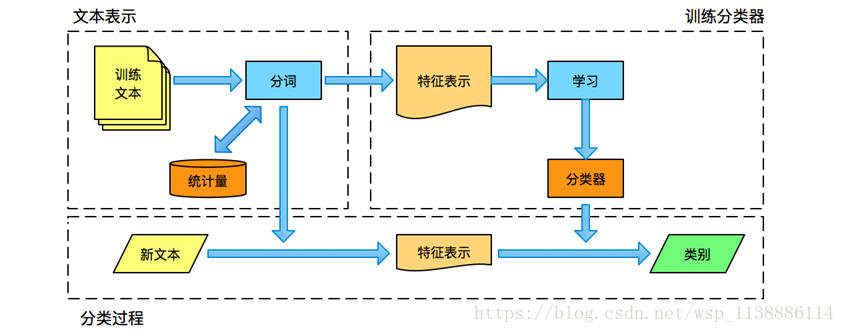
二、文本分词
基于搜狐的新闻的数据,训练一个新闻频道的分类器,可以对新闻进行自动分类
数据详情:12个频道(汽车、财经、文化、健康、房地产、科技、教育、新闻、体育、旅游、女人、娱乐)
每个频道2000篇文章做训练数据,1000篇为测试数据。
2.1 Jieba分词
项目地址:https://github.com/fxsjy/jieba
安装方法:pip install jieba
-
主要功能
-
分词:三种分词模式(精确模式、全模式、搜索引擎模式)
支持自定义词典
基于TF-IDF算法的关键词提取
词性标注
并行分词(不支持windows)
2.2 词袋模型(Bag of Words)
忽略文本的语法和语序等要素,仅仅将其看成是若干个词汇的集合,每个词的出现都是独立的。

词袋模型的问题:不同词语的重要性没有区别,但实际上不同词语提供的信息量不同
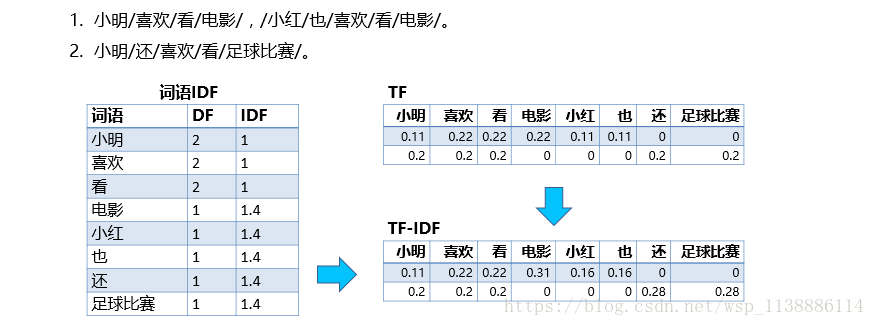
2.3 TF-IDF(词频-逆文档频率)
TF-IDF:全称Term Frequency-Inverse Document Frequency
-
TF(词频)
词语在一篇文章中出现的次数,出现的次数越多表示这个词对这篇文章越重要
通常需要归一化,以防止它偏向于长文章
T F w , d = 词 w 在 文 章 d 中 出 现 的 次 数 文 章 d 中 词 的 总 数 TF_{w,d}=\frac{词~w~在文章~d~中出现的次数}{文章~d~中词的总数} TFw,d=文章 d 中词的总数词 w 在文章 d 中出现的次数 -
IDF(逆文档频率)
如果在所有的语料中,包含某个词语的文章数越多,那么这个词语的区分度就越低,重要长度也就越低
I D F w = log ( 语 料 库 的 文 档 总 数 包 含 词 语 w 的 文 章 数 + 1 ) IDF_w=\log(\frac{语料库的文档总数}{包含词语~w~的文章数+1}) IDFw=log(包含词语 w 的文章数+1语料库的文档总数)
实 际 通 常 使 用 I D F w = log ( 语 料 库 的 文 档 总 数 + 1 包 含 词 语 w 的 文 章 数 + 1 ) + 1 实际通常使用IDF_w=\log(\frac{语料库的文档总数+1}{包含词语~w~的文章数+1})+1 实际通常使用IDFw=log(包含词语 w 的文章数+1语料库的文档总数+1)+1
- 通常,我们需要过滤掉IDF过低和过高的词语
- 在词袋模型中,我们可以使用TF×IDF作为每个词的权重
三、文本表达方式( one_hot编码—word2vec)
为了让计算机能够处理文本,我们需要一些方法把文本编码为数字
-
one-hot 编码:最简单的编码方式是把每个词都表示成一个长向量,向量的长度为词表的大小(还有其他编码方式,比如:哑变量编码)
只有这个词对应位置上为1,其余都为0。
不足:无法表示词和词之间的关系 -
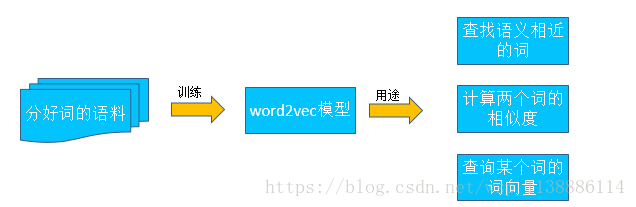
word2vec:把词表示为一个低维向量
基于“具有相似上下文的词,应该具有相似的语义”,这种方式称为分布式表达(Distributed Representation)
每一维表示词语的一个潜在特征,每一维的取值都是连续的
优点:可以使用空间距离或者余弦夹角来表示词和词之间的相似性 -
word2vec 通过预测一个长度为c的窗口内每个词周边词语的概率,来作为这个词的词向量。包含两个神经网络模型:
- CBOW(Continuous Bag of Words)(词袋模型)
利用词的上下文预测当前的词 - Skip-gram
利用当前的词来预测上下文
- CBOW(Continuous Bag of Words)(词袋模型)
-
通过Google开源的工具包gensim实现
安装方法:conda install gensim
使用gensim.models.Word2Vec训练word2vec模型
参数与详解文档:
- Word2vec和Doc2vec原理:https://blog.csdn.net/mpk_no1/article/details/72458003
- Word2vec分布式表达:(NPLM;word2vec(CBOW/Skip-gram)
- https://www.cnblogs.com/Determined22/p/5780305.html
- https://www.cnblogs.com/Determined22/p/5804455.html
四、分类与评估
-
训练分类器 --文本分类这样一个分类任务,可以使用大部分通用分类模型
朴素贝叶斯
逻辑回归
支持向量机(SVM)
决策树 -
模型效果评估
-
评估模型效果应该在测试集上进行(而不是在训练集)
-
混淆矩阵(Confusion Matrix)
-
常用的评估标准有
查全率(Recall)
正确预测为某个类别的文章数 / 这个类别的实际文章数 * 100%
查准率(Precision)
正确预测为某个类别的文章数 / 预测为这个类别的文章数 * 100%
F1值,查全率和查准率的调和均值
2 x Precision x Recall / (Precision + Recall)
F β F_\beta Fβ值: F β = ( 1 + β 2 ) ∙ ( P r e c i s i o n x R e c a l l ) β 2 ∙ P r e c i s i o n + R e c a l l , β > 1 ~~F_\beta=(1+\beta^2 )∙\frac{(PrecisionxRecall)}{\beta^2∙Precision+Recall},~~~\beta>1 Fβ=(1+β2)∙β2∙Precision+Recall(PrecisionxRecall), β>1时,Recall更重要 -
模型持久化
Python中,我们可以使用pickle,把分类器序列化成二进制文件
在另一环境中加载这个文件,进行分类


















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











