









前面在Generative Adversarial Nets(译)一文中对2014年Ian J. Goodfellow这位大牛关于GAN的文章进行了全文的翻译,在翻译的过程中,遇到的不少的问题,也有一些自己的理解,在这里本人对这篇文章与大家进行交流,并对在TensorFlow上GAN的实现源码进行解析。
论文地址:Generative Adversarial Networks
源码地址:GAN in Tensorflow
Generative Adversarial Networks
文章的题目为Generative Adversarial Networks,简单明了。
首先Generative,我们知道在机器学习中含有两种模型,生成式模型(Generative Model)和判别式模型(Discriminative Model)。生成式模型研究的是联合分布概率,主要用来生成具有和训练样本分布一致的样本;判别式模型研究的是条件分布概率,主要用来对训练样本分类,两者具体的区别在这里不再赘述。判别式模型因其多方面的优势,在以往的研究和应用中占了很大的比例,尤其是在目标识别和分类等方面;而生成式模型则只有很少的研究和发展,而且模型的计算量也很大很复杂,实际上的应用也就比判别式模型要少很多。而本文就是一篇对生成式模型的研究,并且这个研究一提出来便在整个机器学习界掀起了轩然大波,连深度学习的鼻祖Yann LeCun都说生成对抗网络是让他最激动的深度学习进展,也可见这项研究的伟大,当然也说明了这篇文章做描述的生成式模型是和传统的生成式模型是很不同的,那么不同之处在哪里呢?
然后Adversarial,这边是这篇文章与传统的生成式模型的不同之处;对抗,谁与之对抗呢?当然就是判别式模型,那么,如何对抗呢?这也就是这篇文章主要的研究内容。在原文中,作者说了这么一段话:“The generative model can be thought of as analogous to a team of counterfeiters, trying to produce fake currency and use it without detection, while the discriminative model is analogous to the police, trying to detect the counterfeit currency.”大意就是,生成式模型就像是罪犯,专门造假币,判别式模型就像是警察,专门辨别假币,那生成式模型就要努力提高自己的造假技术使造的假币不被发现,而判别式模型就要努力提高自己辨别假币的能力。这就类似于一个二人博弈问题。最终的结果就是两人达到一个平衡的状态,这就是对抗。
那么这样的对抗在机器里是怎样实现的呢?
在论文中,真实数据x的分布为1维的高斯分布p(data),生成器G为一个多层感知机,它从随机噪声中随机挑选数据z输入,输出为G(z),G的分布为p(g)。判别器D也是一个多层感知机,它的输出D(x)代表着判定判别器的输入x属于真实数据而不是来自于生成器的概率。再回到博弈问题,G的目的是让p(g)和p(data)足够像,那么D就无法将来自于G的数据鉴别出来,即D(G(z))足够大;而D的目的是能够正确的将G(z)鉴别出来,即使D(x)足够大,且D(G(z))足够小,即(D(x)+(1-D(G(z))))足够大。
那么模型的目标函数就出来了,对于生成器G,目标函数为(梯度下降):
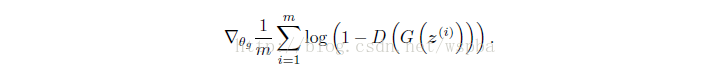
而对于判别器D,目标函数为(梯度上升):
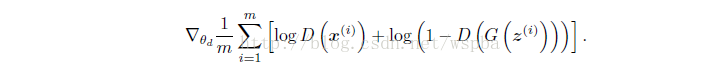
于是模型就成了优化这两个目标函数的问题了。这样的话就只需要反向传播来对模型训练就好了,没有像传统的生成式模型的最大似然函数的计算、马尔科夫链或其他推理等运算了。
这就是这篇文章大概的思路,具体的内容细节以及一些数学公式的推导可以仔细阅读论文原文以及本人的译文,在这篇文章的开头给出了链接,应该都是比较好理解的。
GAN in TensorFlow
参考:An introduction to Generative Adversarial Networks (with code in TensorFlow)
该代码在TensorFlow上利用生成对抗网络来近似1维的高斯分布。
在代码的开头便定义了这个均值为4,方差为0.5的高斯分布:
class DataDistribution(object):
def __init__(self):
self.mu = 4
self.sigma = 0.5
def sample(self, N):
samples = np.random.normal(self.mu, self.sigma, N)
samples.sort()
return samples以及一个初始的生成器分布:
class GeneratorDistribution(object):
def __init__(self, range):
self.range = range
def sample(self, N):
return np.linspace(-self.range, self.range, N) + \
np.random.random(N) * 0.01然后定义了一个线性运算:
def linear(input, output_dim, scope=None, stddev=1.0):
norm = tf.random_normal_initializer(stddev=stddev)
const = tf.constant_initializer(0.0)
with tf.variable_scope(scope or 'linear'):
w = tf.get_variable('w', [input.get_shape()[1], output_dim], initializer=norm) #输入的第二维作为数据维度
b = tf.get_variable('b', [output_dim], initializer=const)
return tf.matmul(input, w) + b即简单的y=wx+b的运算,代码中使用了tf.variable_scope(),实际上这是使用了一个名为scope的变量空间,再通过tf.get_variable()定义该空间下的变量,变量的名字为“scope/w”和“scope/b”,这在很复杂的模型中有利于简化代码,并且方便用来共享变量,在后面也用到了共享变量。
接下来,定义了生成器运算:
def generator(input, h_dim):
h0 = tf.nn.softplus(linear(input, h_dim, 'g0'))
h1 = linear(h0, 1, 'g1')
return h1判别器运算:
def discriminator(input, h_dim, minibatch_layer=True):
h0 = tf.tanh(linear(input, h_dim * 2, 'd0'))
h1 = tf.tanh(linear(h0, h_dim * 2, 'd1'))
# without the minibatch layer, the discriminator needs an additional layer
# to have enough capacity to separate the two distributions correctly
if minibatch_layer:
h2 = minibatch(h1)
else:
h2 = tf.tanh(linear(h1, h_dim * 2, scope='d2'))
h3 = tf.sigmoid(linear(h2, 1, scope='d3'))
return h3这里有一个minibatch,minibatch的内容在原始论文中并没有提到,在后面我们会说到这个。总的来说生成器和判别器都是很简单的模型。
def optimizer(loss, var_list, initial_learning_rate):
decay = 0.95
num_decay_steps = 150
batch = tf.Variable(0)
learning_rate = tf.train.exponential_decay(
initial_learning_rate,
batch,
num_decay_steps,
decay,
staircase=True
)
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(
loss,
global_step=batch,
var_list=var_list
)
return optimizer定义了模型的优化器,模型的学习率使用指数型衰减,模型使用梯度下降来进行损失函数的优化。
接下来定义了GAN类,在GAN类中主要介绍以下几个部分:
def _create_model(self):
# In order to make sure that the discriminator is providing useful gradient
# information to the generator from the start, we're going to pretrain the
# discriminator using a maximum likelihood objective. We define the network
# for this pretraining step scoped as D_pre.
with tf.variable_scope('D_pre'):
self.pre_input = tf.placeholder(tf.float32, shape=(self.batch_size, 1))
self.pre_labels = tf.placeholder(tf.float32, shape=(self.batch_size, 1))
D_pre = discriminator(self.pre_input, self.mlp_hidden_size, self.minibatch)
self.pre_loss = tf.reduce_mean(tf.square(D_pre - self.pre_labels))
self.pre_opt = optimizer(self.pre_loss, None, self.learning_rate)
# This defines the generator network - it takes samples from a noise
# distribution as input, and passes them through an MLP.
with tf.variable_scope('G'):
self.z = tf.placeholder(tf.float32, shape=(self.batch_size, 1))
self.G = generator(self.z, self.mlp_hidden_size)
# The discriminator tries to tell the difference between samples from the
# true data distribution (self.x) and the generated samples (self.z).
#
# Here we create two copies of the discriminator network (that share parameters),
# as you cannot use the same network with different inputs in TensorFlow.
with tf.variable_scope('D') as scope:
self.x = tf.placeholder(tf.float32, shape=(self.batch_size, 1))
self.D1 = discriminator(self.x, self.mlp_hidden_size, self.minibatch)
scope.reuse_variables()
self.D2 = discriminator(self.G, self.mlp_hidden_size, self.minibatch)
# Define the loss for discriminator and generator networks (see the original
# paper for details), and create optimizers for both
self.loss_d = tf.reduce_mean(-tf.log(self.D1) - tf.log(1 - self.D2))
self.loss_g = tf.reduce_mean(-tf.log(self.D2))
vars = tf.trainable_variables()
self.d_pre_params = [v for v in vars if v.name.startswith('D_pre/')]
self.d_params = [v for v in vars if v.name.startswith('D/')]
self.g_params = [v for v in vars if v.name.startswith('G/')]
self.opt_d = optimizer(self.loss_d, self.d_params, self.learning_rate)
self.opt_g = optimizer(self.loss_g, self.g_params, self.learning_rate)与文章中不同的是,这里使用了三种模型:D_pre、G和D。
D_pre是在训练G之前,对D先进行一个预训练,这样能够在训练初期为G提供足够的梯度来进行更新。
G是生成器模型,通过将一个噪声数据输入到这个多层感知机,输出一个具有p(g)分布的数据。
D是判别器模型,代码中用到了scope.reuse_variables(),目的是共享变量,因为真实数据和来自生成器的数据均输入到了判别器中,使用同一个变量,如果不共享,那么将会出现严重的问题,模型的输出代表着输入来自于真是数据的概率。
然后是两个损失函数,三个模型的参数集以及两个优化器。
def train(self):
with tf.Session() as session:
tf.global_variables_initializer().run()
# pretraining discriminator
num_pretrain_steps = 1000
for step in range(num_pretrain_steps):
d = (np.random.random(self.batch_size) - 0.5) * 10.0
labels = norm.pdf(d, loc=self.data.mu, scale=self.data.sigma)
pretrain_loss, _ = session.run([self.pre_loss, self.pre_opt], {
self.pre_input: np.reshape(d, (self.batch_size, 1)),
self.pre_labels: np.reshape(labels, (self.batch_size, 1))
})
self.weightsD = session.run(self.d_pre_params)
# copy weights from pre-training over to new D network
for i, v in enumerate(self.d_params):
session.run(v.assign(self.weightsD[i]))
for step in range(self.num_steps):
# update discriminator
x = self.data.sample(self.batch_size)
z = self.gen.sample(self.batch_size)
loss_d, _ = session.run([self.loss_d, self.opt_d], {
self.x: np.reshape(x, (self.batch_size, 1)),
self.z: np.reshape(z, (self.batch_size, 1))
})
# update generator
z = self.gen.sample(self.batch_size)
loss_g, _ = session.run([self.loss_g, self.opt_g], {
self.z: np.reshape(z, (self.batch_size, 1))
})
if step % self.log_every == 0:
print('{}: {}\t{}'.format(step, loss_d, loss_g))
self._plot_distributions(session)训练过程包含了先前三个模型的训练,先进行1000步的D_pre预训练,预训练利用随机数作为训练样本,随机数字对应的正态分布的值作为训练标签,损失函数为军方误差,训练完成后,将D_pre的参数传递给D,然后在同时对G和D进行更新。
之后还有一些从训练完成的模型中采样、打印等函数操作,代码也比较简单,这里就不进行解析了。
然后我们可以运行代码来看看效果,在cmd中输入:
python gan.py稍等一会,就可以在显示屏上看到打印信息,代表的含义是:(步数,D的loss,G的loss)。然后会看到一个这样的图:
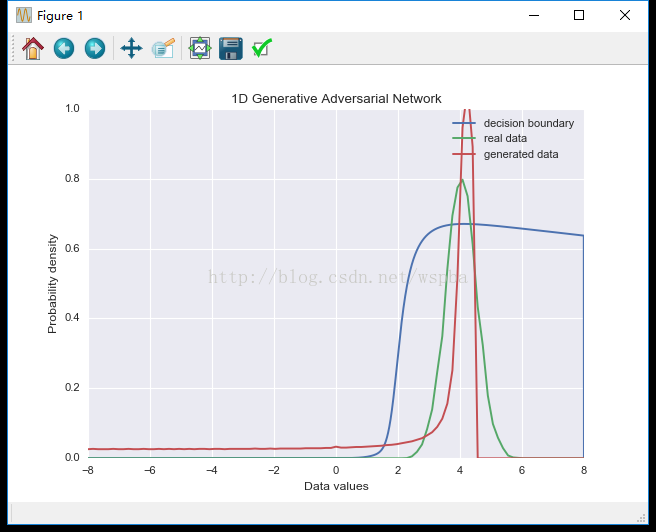
其中绿线代表真实数据分布,红线代表生成数据分布,蓝线代表判别情况,数值上为判别器将真实数据判定为真实数据的概率。从分布上我们可以看到,生成数据在真实数据的平均值附近分布密集,并且比较窄,而且判别器的概率也高于百分之50。并没有达到一个很好的效果。这是因为判别器只能同时对单一的数据进行处理,并不能很好的反应数据集的分布情况。
2016年Tim Salimans发表了一篇文章:Improved Techniques for Training GANs,在文章中使用了minibatch的判别器,也就是在代码中出现的minibatch():
def minibatch(input, num_kernels=5, kernel_dim=3):
x = linear(input, num_kernels * kernel_dim, scope='minibatch', stddev=0.02)
activation = tf.reshape(x, (-1, num_kernels, kernel_dim))
diffs = tf.expand_dims(activation, 3) - tf.expand_dims(tf.transpose(activation, [1, 2, 0]), 0)
abs_diffs = tf.reduce_sum(tf.abs(diffs), 2)
minibatch_features = tf.reduce_sum(tf.exp(-abs_diffs), 2)
return tf.concat(1, [input, minibatch_features])将一个batch的输入变成一个三维的张量,然后计算batch中所有样本的行之间的L1距离,再进行负指数运算并求和,来表示这个batch的联合特征,再与输入拼接起来作为输出。这样就可以很好的利用到一个batch中所有样本的信息。这个minibatch可以添加在判别器的每一个中间层中,正如先前的代码所示。
我们再试试使用minibatch的效果,在cmd中输入:
python gan.py --minibatch True输出的分布情况为:
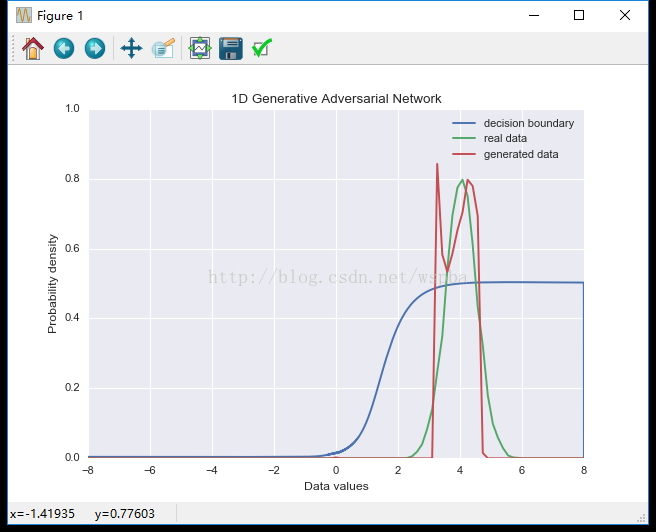
虽然生成数据的分布依然不是很好,但是分布明显变宽了,不再是单一的集中在均值附近,并且判别器的判别概率也达到了0.5左右,效果应该是得到了明显的提升。















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









